[기본 숙제]
p.344의 손코딩(맷플롯립)의 컬러맵으로 산점도 그리기)을 코랩에서 그래프 출력하고 화면 캡쳐하기
code# 노트북이 코랩에서 실행 중인지 체크합니다. import sys if 'google.colab' in sys.modules: !echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections # 나눔 폰트를 설치합니다. !sudo apt-get -qq -y install fonts-nanum import matplotlib.font_manager as fm font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum']) for fpath in font_files: fm.fontManager.addfont(fpath) # 맷플롯립 임포트하고 DPI 기본값 변경 import matplotlib.pyplot as plt plt.rcParams['figure.dpi'] = 100 # 폰트 지정: 나눔고딕, 크기 11 plt.rc('font', family='NanumBarunGothic', size=11) # 폰트 확인 print(plt.rcParams['font.family'], plt.rcParams['font.size']) import gdown gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False) import pandas as pd ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False) ns_book7.head() # 고유한 출판사 목록 만들기 top30_pubs = ns_book7['출판사'].value_counts()[:30] top30_pubs # 발행 도서 개수 기준으로 상위 30개 출판사 목록 top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index) top30_pubs_idx # 산점도 중 1,000개만 선택 ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42) ns_book8.head() # 산점도 그리기 fig, ax = plt.subplots(figsize=(10, 8)) sc = ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], # 마커 테두리 선 두께 변경, 마커 테두리 색 변경, 투명도 조절 linewidths=0.5, edgecolors='k', alpha=0.3, # 마커의 크기가 눈에 더 잘 띄도록, 산점도 색 지정, 값에 따른 색상 표현 s=ns_book8['대출건수']**1.3, c=ns_book8['대출건수'], cmap='jet') ax.set_title('출판사별 발행도서') fig.colorbar(sc) fig.show()
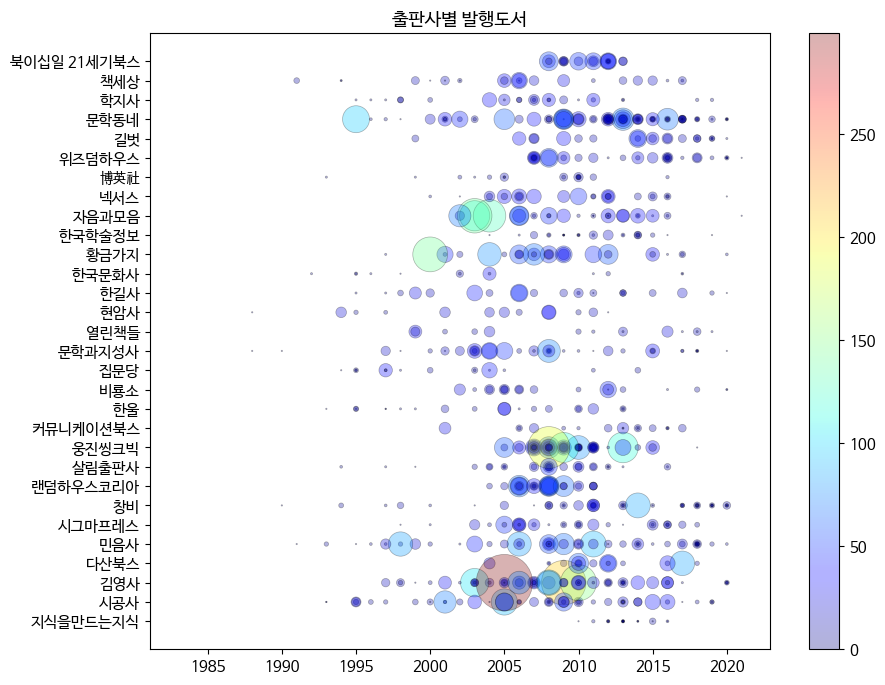
[추가 숙제]
p. 356~359의 스택 영역 그래프를 그리는 과정을 정리하기
codeimport sys if 'google.colab' in sys.modules: !echo 'debconf debconf/frontend select Noninteractive' | debconf-set-selections !sudo apt-get -qq -y install fonts-nanum import matplotlib.font_manager as fm font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum']) for fpath in font_files: fm.fontManager.addfont(fpath) import matplotlib.pyplot as plt plt.rc('font', family='NanumBarunGothic') plt.rcParams['figure.dpi'] = 100 import gdown gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False) import pandas as pd ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False) ns_book7.head() top30_pubs = ns_book7['출판사'].value_counts()[:30] top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index) ns_book9 = ns_book7[top30_pubs_idx][['출판사', '발행년도', '대출건수']] ns_book9 = ns_book9.groupby(by=['출판사', '발행년도']).sum() ns_book9 = ns_book9.reset_index() ns_book9[ns_book9['출판사'] == '황금가지'].head() ns_book10 = ns_book9.pivot_table(index='출판사', columns='발행년도') ns_book10.head() top10_pubs = top30_pubs.index[:10] year_cols = ns_book10.columns.get_level_values(1) fig, ax = plt.subplots(figsize=(8, 6)) ax.stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0), labels=top10_pubs) ax.set_title('년도별 대출건수') ax.legend(loc='upper left') ax.set_xlim(1985, 2025) fig.show()
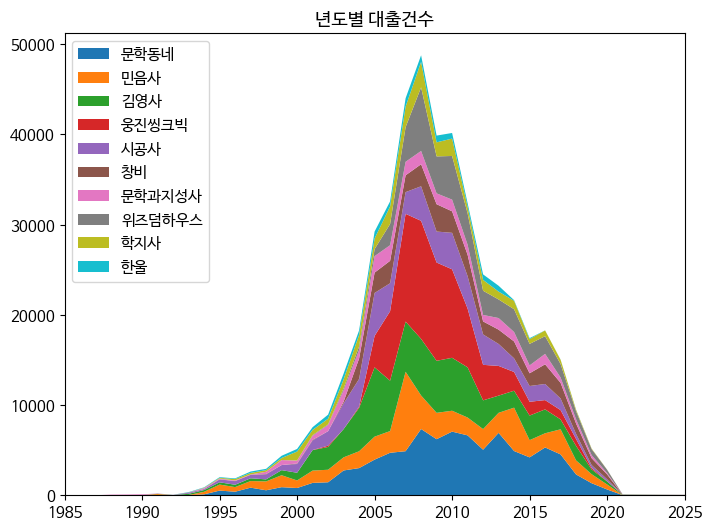

42 Gyeongsan Learner