1. Prefix tuning
논문링크: Prefix-Tuning: Optimizing Continuous Prompts for Generation
기존의 전통적인 학습방식인 Fine-tuning은 대용량의 일반적인 corpus로 모델을 학습시킨 후(Pre-trained Language Model, PLM), downstream task에 맞는 corpus로 PLM의 전체 파라미터를 조금씩 조정(FIne-tuning)해서 task specific한 모델을 만든다. 하지만 PLM은 매우 큰 모델을 사용하고, 그 크기가 나날이 커지고 있기 때문에 task마다 PLM의 전체 파라미터를 fine-tuning하는 것은 매우 비효율적이라고 말한다.
Methodology
이에 따라 Prefix tuning이 등장했다. PLM layer마다 later 앞에 prefix를 붙이고, prefix만 학습시키는 것이다. 이는 task마다 task-specific prefix가 존재하고, PLM의 파라미터는 학습시키지 않는다.
아래 그림으로 자세히 살펴보면 하얀 박스 부분이 인풋 임베딩을 나타내는 것이고, 두 그림에서 모두 분홍색 부분만 학습시킨다. 그림으로만 봐도 fine-tuning에 비해 학습시킬 파라미터가 많이 줄어든 것을 볼 수 있다.
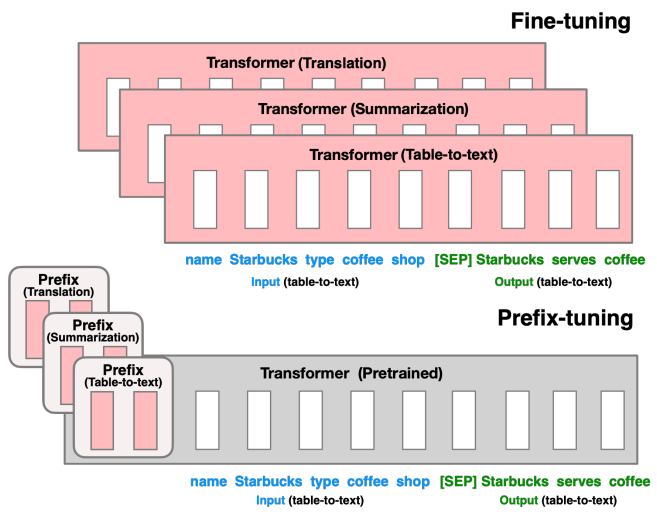
layer마다 prefix가 하나씩 붙으므로 파라미터가 적지 않다.
2. Prompt tuning
논문링크: The Power of Scale for Parameter-Efficient Prompt Tuning
프롬프트는 입력 형태에 따라 두 가지로 나눌 수 있다.
- soft prompt: 벡터 형태로 표현된 프롬프트 (continous)
- hard prompt: 사람이 이해할 수 있는 자연어 형태로 이루어진 프롬프트(discrete)
PLM모델에 downstream task를 적용하는 것은 기존의 수많은 방법론들과 동일하다. doenstream task를 어떻게 하면 효율적이고 효과적으로 수행할 수 있을지에 대한 여러 방법론들이 존재한다. prompt tuning은 그 중 하나의 방법론이다.
Methodology
각 downstream task에 대한 데이터셋이 존재할 것이다. 각각의 데이터셋마다 앞에 벡터 형태의 prompt를 붙이고, PLM에 넣어 학습시킨다. 이 과정에서 prompt는 업데이트가 이루어질 것이다. 하지만 학습 과정에서 PLM의 파라미터들은 freeze시켜서 학습시키지 않고, prompt만 학습시킨다.
이때, 데이터셋은 task마다 여러개가 존재할 수 있지만, prompt는 task 당 하나만 존재한다. 아래 그림을 보면 쉽게 이해할 수 있을 것이다.
- A, B, C는 Task A, B, C에 대한 각각의 prompt를 나타낸다. 각 prompt는 임베딩된 형태이다.
- a1, a2, b1, c1, c2는 task A에 대한 데이터셋 a1, a2를 나타내고 나머지도 마찬가지이다. 이때 각 데이터셋들은 임베딩된 형태로 되어있다. 때문에 prompt 또한 임베딩된 형태인 것이다.
- prompt를 각 임베딩된 데이터셋 앞에 붙여주어서 인풋 데이터를 만들고, 이를 이용하여 PLM으로 학습을 진행한다.
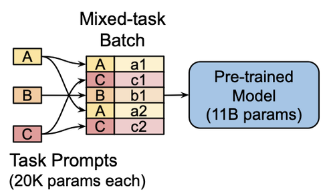
각 task에 대해 하나의 prompt만 업데이트 하면 되기 때문에 학습시킬 파라미터가 매우 적다.
3. P-tunig
논문링크: GPT Understands, Too
prompt tuning에서는 prompt가 manually하게 생성되기 때문에 prompt 구성에 따라 모델의 성능 차이가 크다는 큰 단점이 있다. 이에 따라 continuous prompt(벡터 형태의 prompt)를 각 task에 맞게 최적화시키는 p-tuning이 등장했다.
Methodology
prompt를 안정적(프롬프트 구성을 최적화)이고 효과적(핵심 단어들은 보존)으로 구성하기 위해서 prompt에서 중요한 핵심 단어들을 따로 빼두고, 그 이외의 단어들을 잘 구성하도록 하는 인코더인 "Prompt Encoder"를 만들어준다.
아래 그림을 통해 더 간단히 이해할 수 있다. 그림에서 보이는 빨간색 [MASK]토큰을 잘 예측하기 위해서는 인풋 임베딩을 어떻게 구성하느냐가 중요하다. 예를 들어, "Britain의 capital은 [MASK]이다"의 임베딩 형태가 인풋일 때 여기서의 키워드는 Britain이라고 볼 수 있다.
- 해당 키워드를 제외한 다른 단어들의 구성을 Prompt Encoder를 거친 후, 키워드와 합쳐져서 인풋 임베딩을 형성한다.
- PLM에 인풋을 넣어주고 prediction을 하도록 한 후, Prompt Encoder에 Backpropagation을 진행한다.
- 이를 반복한다.
이때 마찬가지로 PLM은 freeze하여 학습시키지 않으며, Prompt Encoder의 파라미터들만 학습시킨다.
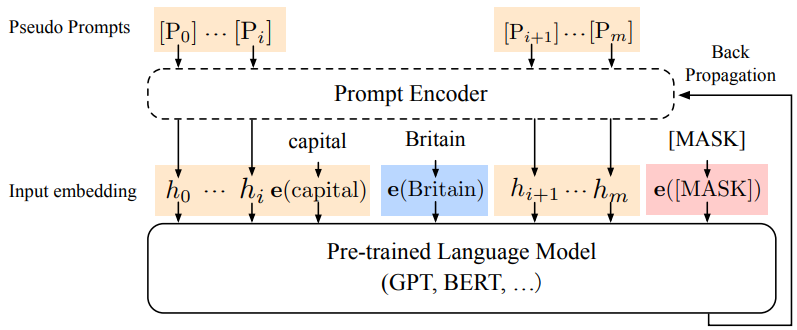
키워드를 골라내는 것 & Prompt Encoder의 아키텍쳐 설계를 직접해야한다. 이때 수작업이 많이 들어간다는 점에서 manually한 부분이 많다는 단점이 있다.
Prompt Encoder는 하나의 모델로 볼 수 있기 때문에 업데이트할 때, 업데이트할 파라미터가 적지 않다.
