
# 서론
'Today I Learned' 로 '오늘 내가 배운 것' 이 맞지만
'Today, I Learned'로 '오늘도 나는 배웠다' 로 작성 하려고 한다.
매일 내가 배운 것을 작성 하는 것도 좋지만 매일 무언가를 배웠다는 자체에 의의를 두기 위해서다.
첫 작성에 앞서, 항상 오늘 같은 마음가짐으로 컴퓨터 앞에 앉아 있었으면 좋겠다. 나에게 하는 말이다.
# 학원 등록 ~ 현재
국비지원교육 학원을 상담하고 등록한건 6월, 개강은 7월 6일부터였다.
7월은 HTML5, CSS3 기본적인 문법, 웹 접근성에 대한 교육을 듣고
8월 초반에는 디자인 강의(포토샵, 일러스트, 피그마)도 들었다.
8월 중반부터 Javascript를 시작했고, DOM(문서객체조작)을 배우고 나서부터는 죽어라 간단한 예제(간단하지 않았다)만 만들었다.
학원 등록 할 때 Javascript의 중요성을 많이 들어서 학원 개강 시작 전에 자바스크립트를 예습하고 가서 수업을 듣는데에는 무리가 없었다.
9월부터 포트폴리오에 넣을 기업 사이트 제작을 시작했고, 지난주 금요일까지 [삼성전기] 사이트를 웹 접근성 표준에 맞춰 제작했다.
HTML 마크업과 CSS 작성 까지는 크게 어려운 점이 없는데, 자바스크립트로 오토배너, 풀다운메뉴 등 객체를 조작하는 것에 있어 아직 미숙하다.
# 학원 강의 ( 09:30 - 18:20 )
1) Fetch API로 다른 문서 불러오기
기존에는 주로 메인페이지만 만들어서 HTML/CSS/Javascript 파일 각 한 개씩 밖에 없었지만, 기업사이트 제작은 서브페이지도 제작하다보니 HTML과 CSS에서 header 나 footer 같이 중복되는 코드가 많았다.
그래서 오늘은 파일을 분할 해서 스크립트로 각각의 파일을 불러와 적용하는 법을 배웠다.
// AJAX의 최신 fetch API
// html문서 내에 다른 html문서 불러오기
// 자바스크립트 비동기 방식 async - await
async function fetchHtmlAsText(url) {
const response = await fetch(url);
return await response.text();
}
async function importPage(target) {
document.querySelector('#' + target).innerHTML = await fetchHtmlAsText(target + '.html');
}
importPage('header');
importPage('footer');
자세한 내용은 나중에 리액트 할 때 다시 알려주신다고 하셨고, 오늘은 간단하게 원리에 대해서만 설명해주셨다.
AJAX의 최신 API인 Fetch 기능을 사용해서 url링크를 통해 다른 파일에 있는 내용을 innerHTML 로 넣는 방식이였다.
그리고 자바스크립트는 html내용의 로드를 위해 addEventListener('load') 로 코드를 감쌌다.
자세한 설명에 대한 링크이다.
https://developer.mozilla.org/ko/docs/Web/Guide/AJAX/Getting_Started
CSS는 import.css를 만들어 layout header footer 와 같은 공용 스타일을 따로 관리한다.
html에서 import.css를 먼저 불러오고 해당페이지의 CSS를 불러온다.
/* import.css */
@import url(reset.css);
@import url(layout.css);
@import url(header.css);
@import url(footer.css);2) 반응형 웹에서는 시맨틱 태그 사용
모바일 환경이나, 웹 앱 환경의 경우에는 div태그 대신 header main footer 와 같은 시맨틱 태그를 사용하는 것이 맞다.
시멘틱 구조란 HTML 문서에서 의미있는 부분을 의미에 맞는 태그를 사용하는 것을 뜻한다.
- non-semntic 요소
divspan등이 있으며 이들 태그는 content에 대하여 어떤 설명도 하지 않는다. - semantic 요소
formtableimg등이 있으며 이들 태그는 content의 의미를 명확히 설명한다,
대부분의 인터넷 사용자는 원하는 정보를 취득하기 위해 Google이나 Naver와 같은 검색사이트를 이용한다.
검색엔진은 로봇(Robot)이라는 프로그램을 이용해 매일 전세계의 웹사이트 정보를 수집한다.
(이것을 크롤링 이라 하며 검색엔진의 크롤러가 이를 수행한다.)
그리고 검색 사이트 이용자가 검색할 만한 키워드를 미리 예상하여 검색 키워드에 대응하는 인덱스(색인)을 만들어 둔다.
(이것을 인덱싱 이라 하며 검색엔진의 인덱서가 이를 수행한다.)
인덱스를 생성할 때 사용되는 정보는 검색 로봇이 수집한 정보인데 결국 웹사이트의 HTML코드이다.
즉, 검색 엔진은 HTML 코드 만으로 그 의미를 인지하여야 하는데 이때 시맨틱 요소를 해석하게 된다.
주로 아래와 같이 작성한다.
<header> : 웹 문서 맨 윗부분, 웹 사이트 로고, 로그인, 회원가입, 사이트맵, 언어 선택
<nav> : 문서의 navigation , 메뉴 , 리스트와 링크(ul, li, a)
<section> : 문서에서 관련 있는 내용을 묶음
<article> : 독립적인 내용, 뉴스 기사나 블로그 내용 등
<aside> : 본문 글과 연관성 없는 내용 (배너 광고, 위젯등)
<footer> : 주소, 연락처, 저작권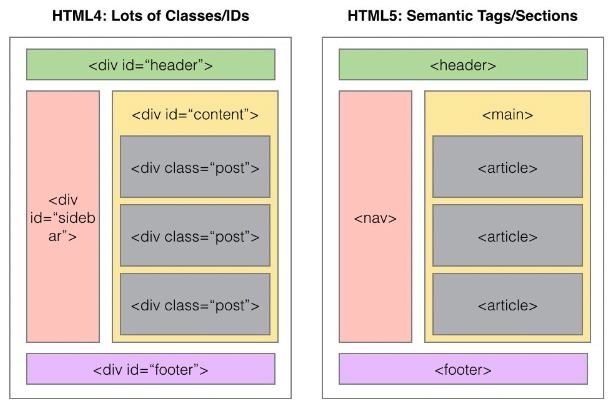
그러므로 앞으로 작성할 HTML마크업은 아래와 같이 개선 해서 작성해야 한다.
<!--개선 전-->
<div id="header">
<div id="container">
<div id="footer">
<!--개선 후-->
<header id="header">
<main id="container">
<footer id="footer"># 백준 & 프로그래머스 알고리즘
1일 1코딩 테스트를 위해 하루에 백준과 프로그래머스 단계별로 한 문제씩 풀고 있다.
지금은 HTML/CSS 웹 퍼블리싱이나 Javascript 의 문서객체 조작에 우선 순위를 두고 공부하고 있지만, 결국 취업을 위해서는 코딩 역량도 조금씩은 높여놔야 할 것 같다.
오늘도 각 1문제 씩 완료했다.
# 체력관리
학원 강의가 09:30-18:30 로 길다보니 하루 종일 앉아 있는 시간이 많다.
계속 저녁에 웨이트는 다녔지만 아침에 일어나서 산책도 나가고 스트레칭도 자주 해야 몸이 망가지지 않고 버틸 수 있을 것 같다.
오늘 끝, 내일 안녕
