Sequential Data Structure(순차적 자료구조)
순차적 자료구조에서는 data들이 순차적으로 나열되어있다. 각 원소가 줄지어 저장되어 있기 때문에, 한 번의 순차적인 접근으로 모든 원소를 순회할 수 있다는 것이 하나의 특징이다. 또, 모든 원소들은 단일 level에 있다. (용어는 아래에 열거되어 있다.)
이러한 순차적 자료구조에는 배열(혹은 리스트), 스택, 큐, 링크드 리스트 등이 있다. 하나씩 알아보도록 하겠다.
📌Array vs List
index로 임의의 원소를 접근할 수 있다.
Array(배열)
배열은 대표적으로 C언어에서의 자료구조라고 할 수 있는데, 연속된 저장 공간 안에 덩어리로 저장되어 있어 시작 주소부터 한 원소씩 들어있다.
int A[4] = {3, 9, 2, 60};List(리스트)
리스트는 파이썬에서 사용되는 자료구조인데, 각 객체의 주소를 가리키는 리스트가 있고, 객체들은 메모리 내에 개별적으로 저장되어 있는 형태이다.
A = [3, 9, 2, 60]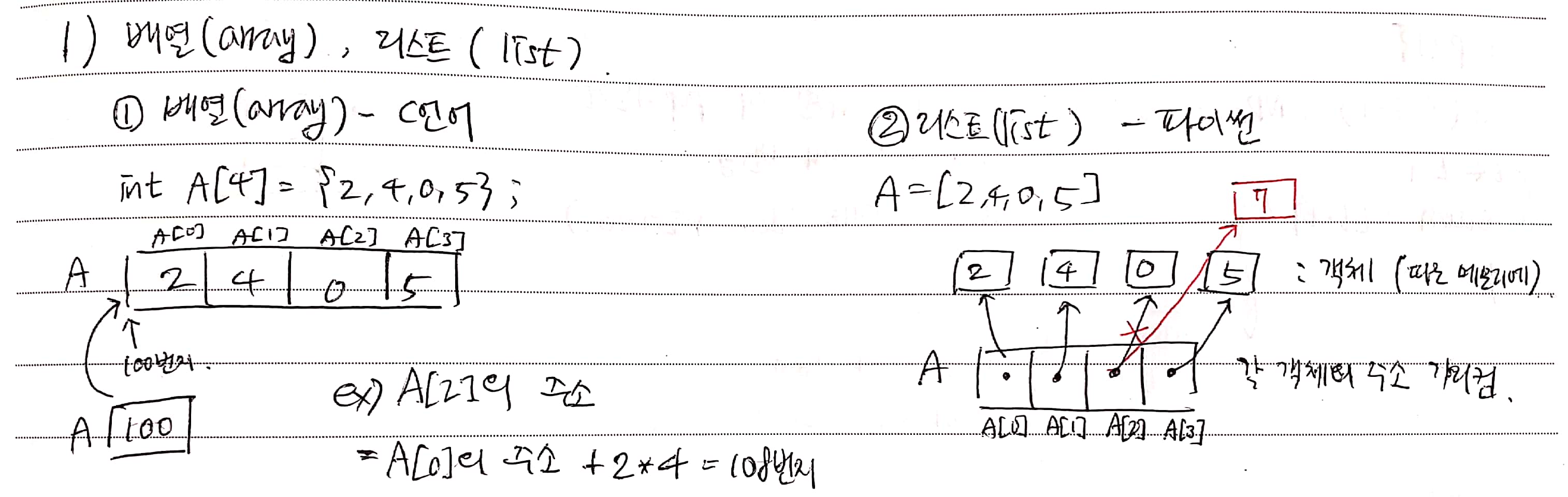
배열과 리스트 등 선형 자료구조에 대해서는 각 컴퓨터 언어를 공부하면서 자세히 알아보도록 하고, 이번에는 간단하게만 살펴보았다.
*참고 - Chan-Su Shin Data Structures with Python
📌Stack vs Queue
제한된 접근 방식을 가진다.
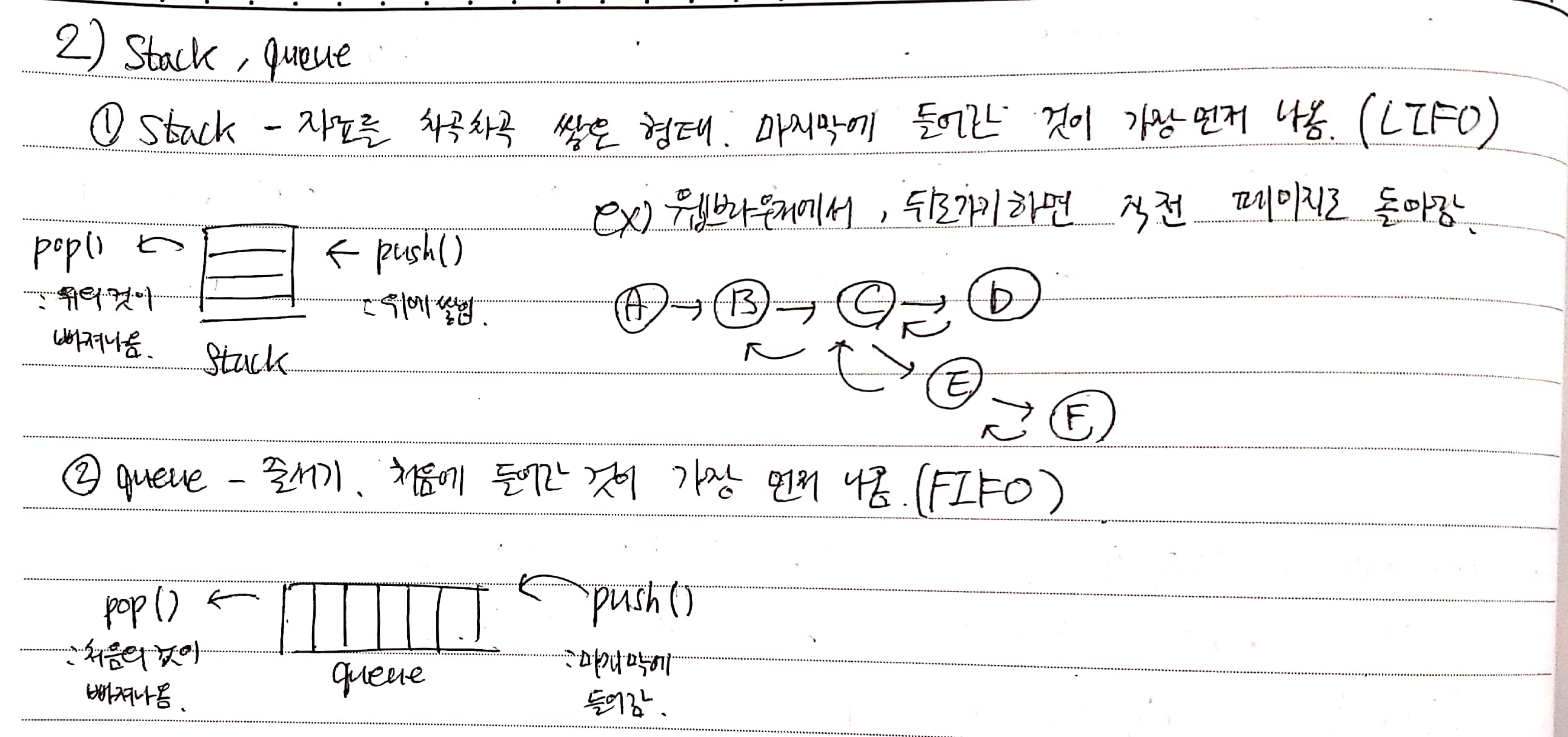
Stack(스택)
자료를 차곡차곡 쌓은 형태이다. (stack은 물건이 차곡차곡 쌓인 더미를 말한다.) 마지막에 들어간 것이 가장 먼저 나오는 LIFO(Last In First Out)방식이다. 코인들이 쌓여 있을 때, 맨위에 새 코인을 쌓고 맨위에서 코인을 가져가는 모습을 생각하면 된다.
웹브라우저에서 뒤로가기를 했을 때, 바로 직전의 페이지로 돌아가는 것을 생각해도 된다.
Queue(큐)
일렬로 나열된 줄 형태이다. (영국 영어에서는 줄을 queue라고 한다.) 처음에 들어간 것이 가장 먼저 나오는 FIFO(First In First Out)방식이다. 우리가 흔히 아는 줄서기와 동일하다. 맨 처음에 줄을 선 사람이 가장 먼저 불리게 된다.
배열을 가지고 스택과 큐를 구현하기 위한 Pseudo-code이다.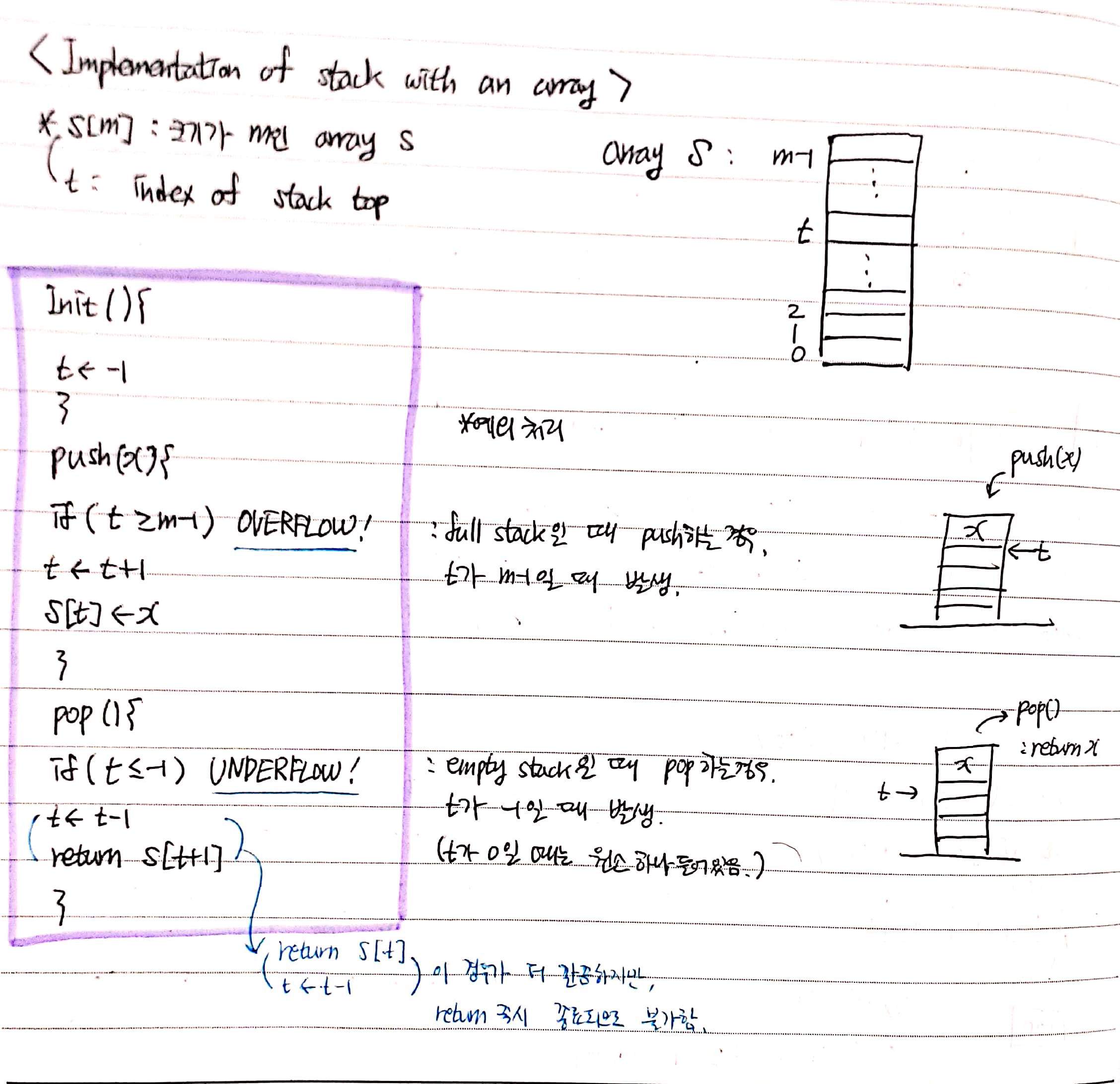
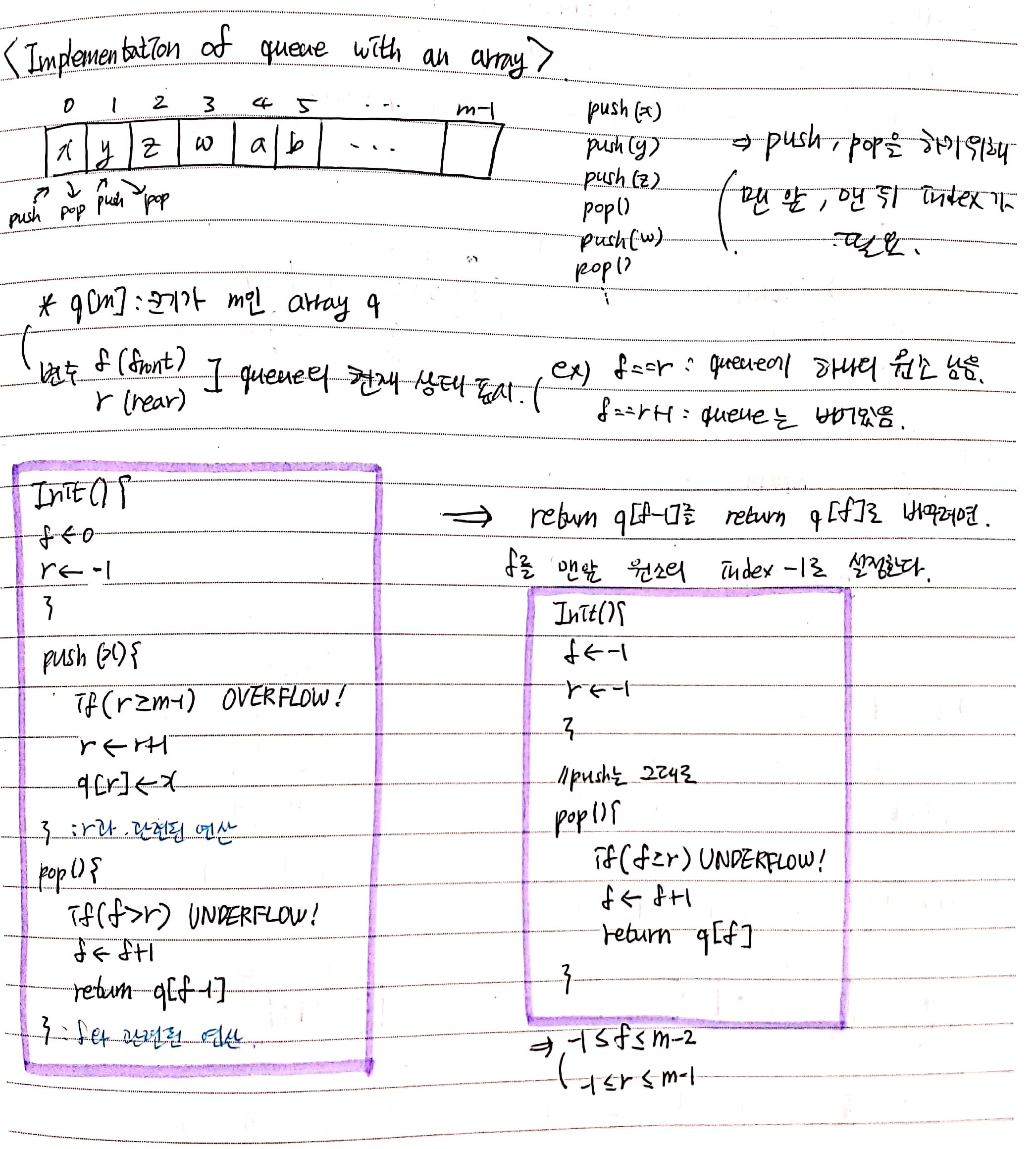
Circular Queue
큐는 앞에서부터 pop하고 뒤에서 push하게 되어있다. 일반적인 형태의 큐라면 앞에 있던 원소들을 전부 pop하게 되면 앞에 많은 빈 공간이 생기게 되고 뒤에서만 push할 수 있으므로 이 공간들을 사용할 수 없다. 이렇게 낭비되는 공간을 사용하기 위해 고안한 것이 원형 큐이다.

📌Linked List
index로 원소에 임의접근할 수 없다. link를 따라가며 접근해야 한다.
배열의 경우 연속된 메모리 공간에 순차적으로 저장하지만, 링크드 리스트의 경우 연속된 공간에 저장되어있지 않을 수도 있다. 각 원소가 되는 구조체를 node(노드)라고 부르고, 노드는 data부와 link부로 이루어져있다. 링크 부분에는 다음 노드의 주소를 담고 있다. 이러한 방식으로 연결되어있어 링크드 리스트는 첫 번째 노드의 주소를 이용해 모든 노드를 순차적으로 접근하게 된다.
링크드 리스트는 많은 장점을 가지고 있으나 약간의 단점도 있다.
장점
- delete & insert가 쉽다.
배열의 경우 중간의 원소를 삭제하면 빈 공간이 생기므로 공간의 낭비가 발생하거나 뒤의 원소들을 모두 앞으로 당겨야하는 반복 연산이 필요하다. 중간에 원소를 넣고 싶을 때도 넣을 공간을 만들기 위해 많은 원소들을 뒤로 밀어야 한다. - 리스트의 join이 쉽다.
삽입, 삭제와 비슷한 맥락으로, 리스트를 덩어리 째 분리하고 합치기가 용이하다. - 연속된 메모리 공간이 필요하지 않다.
배열의 경우 연속된 공간에 통째로 저장해야 하는데, 연속된 커다란 공간이 없더라도 링크드 리스트를 생성하고 늘릴 수 있다.
단점
- link를 저장하기 위한 추가 저장 공간 필요
다음 노드의 주소를 저장하기 위해 노드에 공간이 필요하다. - random access가 불가하다.
다음 노드의 주소는 그 이전 노드만 알 수 있다. 따라서 앞에서부터 차근차근 따라가야만 원하는 노드에 접근할 수 있고, 최악의 경우 모든 노드를 전부 순회해야 한다.
이번에는 링크드 리스트를 순회하고 원소를 삽입, 삭제하려면 어떻게 해야 하는지 생각해보자.
Traversing a linked list
Inserting
Deleting
아래는 링크드 리스트 연산의 Pseudo-code이다.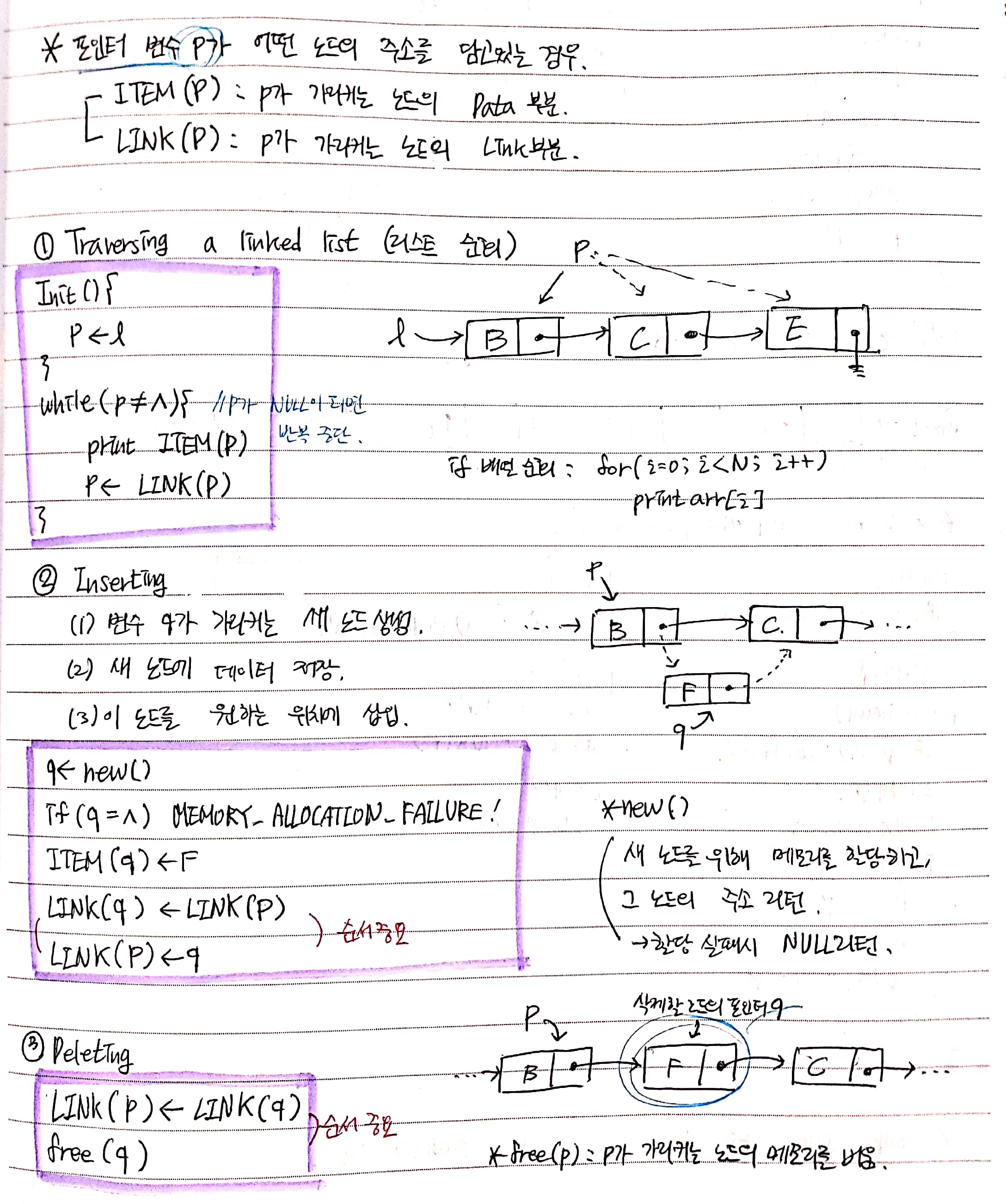
링크드 리스트를 가지고 스택과 큐를 구현하는 수도 코드도 있으나 이는 후에 C언어로 구현해보는 것으로 하겠다.
양방향 연결 리스트에 대해서 공부한 부분은 첨부하지 않았다.
C언어 실습이 공부와 훈련을 위해 가장 중요한 부분이므로 조만간 C언어 공부와 함께 포스팅하도록 해야겠다. 실습이 너무 어려웠던 기억이 있어 걱정되지만, 진작에 완벽히 끝내고도 남았어야 되는 부분이다. 마음을 조급하게 먹지 말고 집중해서 열심히 해보자.
