Data Structure
파이썬의 기본적인 자료 구조에는 시퀀스(sequence)가 있다. 시퀀스는 원소로 구성되어 있고 원소에는 순서가 있는데, 이를 인덱스로 번호 매긴다. 파이썬의 시퀀스에는 str, bytes, bytearray, list, tuple, range가 있다. 시퀀스 자료구조들은 인덱싱, 슬라이싱, 덧셈 연산, 곱셈 연산과 같은 동일한 연산을 지원하며 내장 함수도 공통으로 사용할 수 있다.
Tuple
튜플은 리스트와 유사하지만 내용이 변경될 수 없다는 차이점이 있다. 다음과 같이 소괄호로 원소들을 묶는다.

튜플도 리스트와 마찬가지로 여러 자료형의 데이터를 섞어 저장할 수 있으며, 내부에 다른 튜플을 가질 수 있다.
공백 튜플은 t = ()와 같이 생성할 수 있다.
tuple()와 list()를 사용해 튜플과 리스트 간 변환이 가능하다.
t = tuple([1, 2, 3])
l = list((1, 2, 3))
print(t)
print(l)(1, 2, 3)
[1, 2, 3]
튜플은 모든 시퀀스 연산이 가능하고 len(), min(), max()와 같은 함수를 사용할 수 있다.
❗하나의 값을 가진 튜플 생성 시 값 뒤에 쉼표를 작성해주어야 한다. 그렇지 않으면 튜플이 아닌 단순 값으로 인식된다.
t = (1) #t는 정수 1
t = (1, ) #t는 튜플괄호가 없이 값이 나열된 경우 튜플로 간주된다.
n = 1, 2, 3, 4, 5 #n = (1, 2, 3, 4, 5)와 동일
a = 'a', 'b', 'c' #a = ('a', 'b', 'c')와 동일튜플은 값의 변경이 불가한 객체로 원소를 변경할 수 없다. 하지만 2개의 튜플을 연결해 새로운 튜플을 만드는 것은 가능하다.

기본적인 튜플 연산
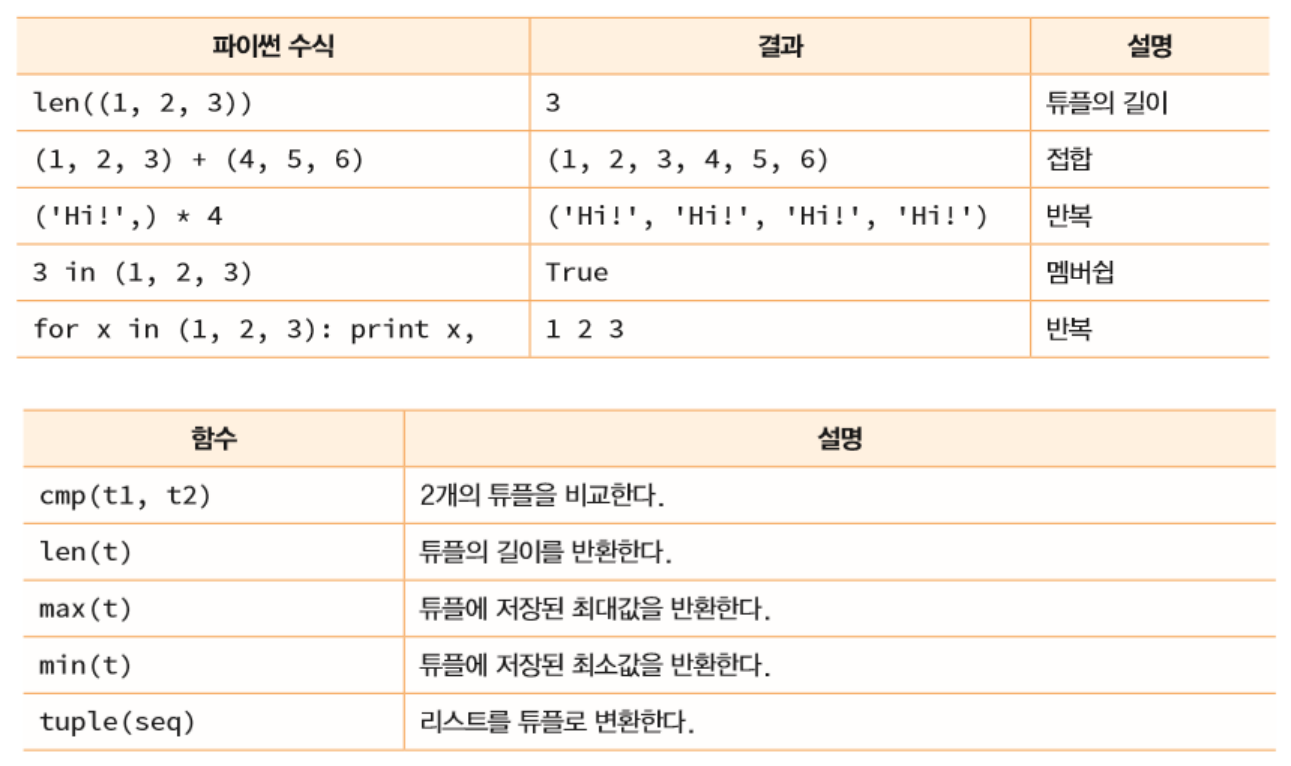
인덱싱, 슬라이싱이 가능하다.
튜플 대입 연산
튜플을 이용해 여러 개의 변수에 값을 한번에 대입할 수 있다.

(x, y) = (y, x)]👉🏻함수에서 여러개의 반환값을 가질 때, 튜플로 묶어 반환한다.
Set
세트는 집합으로, 원소 간 순서가 존재하지 않고 중복된 항목이 없다. 중괄호로 감싼다.
중복된 요소가 들어오면 자동으로 중복 원소는 제거되고 하나만 남는다. 비어있는 세트를 생성하려면 set() 함수를 이용한다.
nums = set()세트의 원소에는 순서가 없으므로 인덱스를 통해 항목에 접근할 수 없다. 항목이 세트 안에 있는지 검사할 때에는 in 연산자를, 각 항목에 접근할 때에는 for문을 이용한다.
이 때, 출력되는 순서는 입력된 순서와 다를 수 있다.

정렬된 순서로 출력하고 싶은 경우, for x in sorted(numbers):와 같이 sorted() 함수를 이용하면 된다.
❗세트는 원소를 해싱을 이용해 관리한다. 따라서 원소들은 hashable해야 한다. 이는 모든 원소들이 해시코드를 가져야 하고 값이 변경 불가해야된다는 의미이다. 변경 가능한 항목을 가지면 안되므로 세트는 리스트를 원소로 가질 수 없다.
하지만 set()를 통해 리스트로부터 세트를 생성하는 것은 가능하다.
원소 추가, 삭제
세트는 변경 가능한 객체이므로 세트에 원소를 추가하거나 삭제할 수 있다. 인덱스가 없으므로 인덱싱이나 슬라이싱은 불가하다.
- add() : 원소 추가
- update() : 여러개의 원소 추가. 중복된 요소는 추가되지 않음
- discard() : 원소 삭제
- remove() : 원소 삭제. 세트에 없는 원소 삭제 시 예외 발생
- clear() : 세트의 전체 요소 삭제. 세트의 크기는 0이 됨.
부분 집합 연산
=, != 연산자를 통해 두 세트가 같은지 검사할 수 있다. >, <, >=,<=연산자를 통해 부분집합, 상위 집합을 검사할 수 있다.
부분집합인지 검사하는 메서드는 issubset()이고, 상위 집합인지 검사하는 메서드는 issuperset()이며, 원소가 집합에 포함되어 있는지 검사하려면 in 키워드를 사용한다.
집합연산
- 합집합 : | 연산자 또는 union() 함수
- 교집합 : & 연산자 또는 intersection() 함수
- 차집합 : - 연산자 또는 difference() 함수
세트에 대해서 all(), any(), enumerate(), len(), max(), min(), sorted(), sum() 등의 메서드를 사용할 수 있다.
Dictionary
딕셔너리는 키와 값의 쌍을 저장할 수 있는 객체이다. 키는 해시 가능한 객체여야 하며 중복될 수 없다. 값은 어떤 객체도 될 수 있으나 키는 문자열이나 숫자와 같이 변경불가능한 객체여야 한다.

공백 딕셔너리는 d = {}와 같이 생성한다.
항목 접근
딕셔너리에서 항목 접근 시 키를 사용한다. [ ]안에 키를 지정하거나 get() 함수를 이용한다.
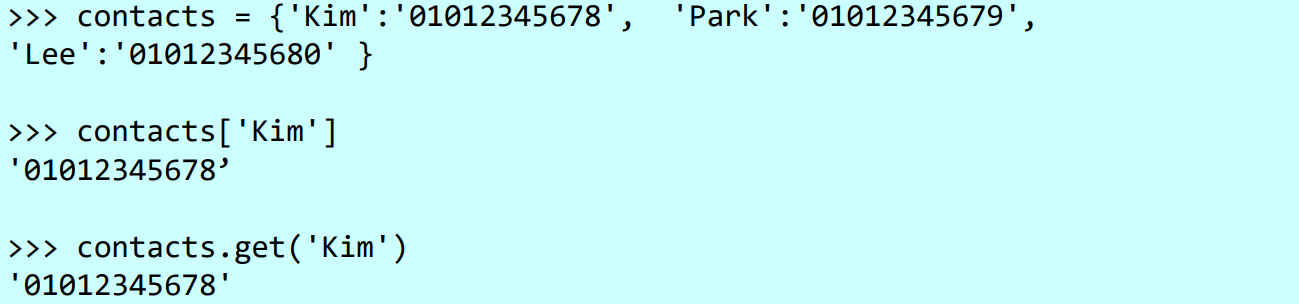
키가 딕셔너리에 있는지 알고 싶은 경우 in 연산자를 이용한다.
항목 추가, 삭제
딕셔너리는 변경 가능하므로 항목을 추가/삭제 가능하다.
삭제할 때에는 pop()을 호출하거나 del 키워드를 이용한다. pop() 함수 호출 시 해당 항목의 값을 반환한다.
딕셔너리의 모든 항목 삭제 시 clear()를 사용한다.


#del 키워드 사용
del contacts["Kim"]항목 순회
items() 메서드를 사용하면 키와 값을 함께 반환한다. items() 메서드 없이 작성하면 키만 반환한다.


👉🏻keys() 메서드는 키값을, values() 메서드는 값을 반환한다.
딕셔너리 함축
딕셔너리 함축을 통해 새 딕셔너리를 생성할 수 있다.
square = {x : x * x for x in range(6)}
print(square){0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
정렬
sorted() 함수는 딕셔너리 객체를 받아 정렬된 키의 리스트를 반환한다.
값을 정렬하려는 경우, sorted(dict.value())와 같이 작성하면 된다.
String
문자열은 문자의 시퀀스로, str 클래스의 객체로 표현된다. 문자열은 변경 불가능한 객체로, 변경이 필요한 경우 문자열이 변경되지 않고 새로운 문자열 객체가 생성된다. 문자열은 시퀀스이므로 인덱싱, 슬라이싱과 그 밖의 함수들을 사용할 수 있다.
각 문자를 접근하려는 경우 인덱스를 이용하면 되고 인덱스로 접근하여 문자를 변경하는 것은 불가하다.
in 연산자를 통해문자열 안에 문자나 다른 문자열이 포함되어 있는지를 확인할 수 있다.
==, !=, <, >를 통해 문자열을 비교할 수 있다.
단어 분리
split() 메서드는 문자열에서 단어를 분리하여 단어의 리스트를 생성해 반환한다. 기본 분리자는 스페이스 문자이며, 분리자를 지정하는 경우 s.split(',')와 같이 인자로 전달한다.

문자열 검사
- isalpha() : 문자열이 알파벳으로만 이루어져있는지 검사한다.
- isdigit() : 문자열이 숫자로만 구성되어있는지 검사한다.
- isalnum() : 문자열이 알파벳과 숫자로만 이루어져있는지 검사한다.
- isspace() : 문자열이 공백문자로만 이루어져있는지 검사한다.
- islower() : 문자열이 소문자로만 이루어져있는지 검사한다.
- isupper() : 문자열이 대문자로만 이루어져있는지 검사한다.
부분 검색
문자열에 포함된 부분 문자열을 검색하는 메서드로는 startwith(), endwith(), find(), rfind(), count()가 있다.
startwith(), endwith()는 True, False를 반환하고, find(), rfind()는 전달된 문자열이 문자열 내에 존재하는지 검사 후 위치를 반환한다. 각각 왼쪽, 오른쪽부터 탐색한다.
count()는 전달된 문자열이 해당 문자열에 몇 번 존재하는지 횟수를 반환하는데, 이 때 대소문자를 구분하며 범위를 지정할 수 있다. count(검색 문자열, start, end)와 같이 작성하면 된다.
문자열 변환
upper()와 lower()는 문자열의 모든 문자를 대문자/소문자로 변환한다.
capitalize()는 문자열의 첫 번째 문자만 대문자로 변환한다.
replace(s1, s2)는 하나의 문자를 다른 문자로 변경한다.
공백 제거
문자열에서 공백 문자인 스페이스, 탭, 줄바꿈 문자를 제거하려면 strip(), lstrip(), rstrip()을 사용한다.
lstrip()과 rstrip()은 각각 왼쪽, 오른쪽 공백 문자만을 제거하고 strip()은 왼쪽과 오른쪽 공백 문자를 제거한다.
