리스트 (list)
타 프로그래밍 언어에서의
배열과 같다.
변형이 가능한 mutable object 이다.
리스트의 크기를 제한하여 선언하지 않는다. 자료형을 제한하지 않는다.
// Java
String[] arr = new String[5];# Python
arr = []
arr2 = [1, "3", True, datetime.datetime.now(), (5, 1), {"a":"A", "b":"B"}]요소 추가하기 .append() .extend() .insert()
-
.append()
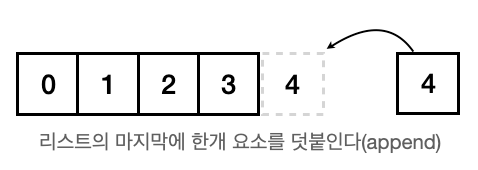
a = [1, 2, 3]
a.append(5)
print(a)
>>> Output
[1, 2, 3, 5]파이썬의 리스트는 길이를 제한하여 선언하지 않으니 인덱스 형식으로 덧붙일 순 없을까?
→ No!
a = [1, 2, 3]
# 다음번 추가 될 인덱스는 a[3] 이다.
a[3] = 4
>>> Output
IndexError: list assignment index out of range
# 대신, 아래 방법으로 대체가 가능하다.
a[3:] = [4]파이썬에서 배열에 집어넣을 때(치환이 아니라면) .append()를 활용하자!
-
extend()
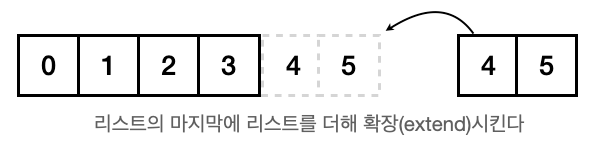
a = [1, 2, 3]
a.extend([4, 5]) # a += [4, 5] 도 같은 효과
print(a)
>>> Output
[1, 2, 3, 4, 5]Tip!
+ 연산도 .extend()와 동일한 결과를 만든다.
a, b = [1, 2, 3], [4, 5]
print(a + b) → [1, 2, 3, 4, 5]
+= 도 역시 먹힌다.
a += b
print(a) → [1, 2, 3, 4, 5]
-
insert()
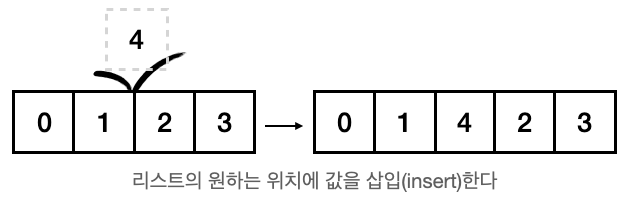
a = [0, 1, 2]
a.insert(1, 10)
print(a)
>>> Output
[0, 10, 1, 2]그럼 하나만 삽입하는게 아니라 extend 처럼 많은 요소를 덧붙일 순 없을까?
a.insert(1, [6, 7, 8])
a.insert(1, [6, 7, 8])
# 기대값: a = [0, 10, 1, 2] 였으므로, [0, 6, 7, 8, 10, 1, 2] 이지 않을까?
print(a)
>>> Output
[0, [6, 7, 8], 10, 1, 2]그럴 땐 리스트 슬라이싱을 활용해서 더해버리자.
# CASE 1
a = [0, 1, 2]
b = a[0:1] + [6, 7, 8] + a[1:]
print(b)
# CASE 2
c = [0, 1, 2]
c[1:1] = [6, 7, 8]
print(c)
>>> Output
[0, 6, 7, 8, 1, 2]
[0, 6, 7, 8, 1, 2]
"""
b = a[0:1]
b.extend([6, 7, 8])
b.extend(a[1:])
위 extend 방식보다 +가 훨씬 간결하다.
"""요소 삭제하기 .pop() 과 del 키워드
- .pop()
대상 데이터를 리스트에서 지우고 어떤 값이었는지 리턴한다.
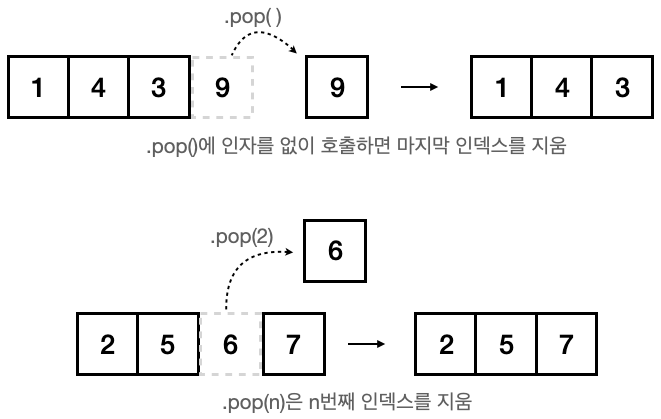
# .pop()에 인자가 없으면 마지막걸 지운다
a = [1, 4, 3, 9]
a.pop()
print(a)
# .pop(n)은 n번째 인덱스를 지운다.
b = [2, 5, 6, 7]
b.pop(2)
print(b)
>>> Output
[1, 4, 3]
[2, 5, 7]- del
리스트에서 대상 데이터를 어떠한 리턴 없이 지운다
a = [1, 4, 3, 9]
del a[-1] # 맨 마지막
print(a)
b = [2, 5, 6, 7]
del b[2]
print(b)
c = [7, 8, 9, 0]
del c[1:2] # 범위 지정해서 제거도 가능!
print(c)
>>> Output
[1, 4, 3]
[2, 5, 7]
[7, 0]- 두가지는 언제 쓰이나?(리턴 유무가 다르다)
# 1~ 45까지 숫자가 적힌 종이가 통안에 있다.
# 이때, 무작위로 한장을 뽑아 발표하고 뽑은 종이는 통에서 제거한다.
import random
numbers = list(range(1, 46))
random.shuffle(numbers)
# Case 1) del 사용
# 범위 삭제 가능!
# 딕셔너리에서도 사용 가능!
pop_num = numbers[0] # 값을 사전에 할당하고
del numbers[0] # 지워야 한다.
print(f"첫 당첨번호는 {pop_num} 입니다!")
# Case 2) .pop() 사용
# 두줄보단 한줄이 간결하니까..!
# 한번에 하나씩만 삭제 가능!
pop_num = numbers.pop() # 통에서 제거한 당첨번호 리턴
print(f"다음 당첨번호는 {pop_num} 입니다!")
print(pop_num in numbers) # 뽑은 번호는 통에 없다
>>> Output
첫 당첨번호는 32 입니다!
다음 당첨번호는 11 입니다!
False특정 값의 인덱스 찾기 .index()
a = [5, 10, 15, 10, 35, 20]
print(a.index(10))
>>> Output
1리스트에 찾으려는 값이 여러 개 있더라도 가장 처음 찾은 인덱스를 반환(작은 수)
- 타겟숫자 모두 삭제시키기(0 제거)
arr = [0, 10, 0, 13, 10, 15, 0, 0, 7]
del_target = 0
find_index = False
while del_target in arr:
del arr[arr.index(del_target)] # or arr.pop(a.index(del_target))
print(arr)
>>> Output
[10, 13, 10, 15, 7]특정 값의 갯수 구하기 .count()
arr = [10, 20, 30, 15, 20, 40]
print(arr.count(20))
>>> Output
2정렬하기 .sort()
a = [10, 20, 30, 15, 20, 40]
a.sort()
print(a)
>>> Output
[10, 15, 20, 20, 30, 40]순서 뒤집기 .reverse()
a = [10, 20, 30, 15, 20, 40]
a.reverse()
print(a)
>>> Output
[40, 30, 20, 20, 15, 10]반복문에서 range() 와 함께 역순으로 값을 받기위해 사용한 reversed() 와 다르다!
[ list ].reverse() < > reversed(range(10))
개인적으론..
정렬을 하는 경우가 list, dictionary 에서 많은데, sorted() 함수로 통일해서 쓰는 편.
sorted(a) # 오름차순
sorted(a, reverse=True) # 내림차순
sorted({ ... dict }, key=lambda x: x[1], reverse=True)
초기화 .clear()
a = [10, 20, 30, 15, 20, 40]
a.clear()
print(a)
b = [10, 20, 30, 15, 20, 40]
del b[:] # [(처음부터):(끝까지)]
print(b)
>>> Output
[]
[]기타
- 리스트가 비어있는지 판단?
arr = [1, 2, 3]
if arr:
print("arr은 비어있지 않네요")
"""
if len(arr) > 0: 와 동치이다.
대상 리스트의 원소갯수를 세고, 갯수가 0 초과이면(비어있지 않다면?)
"""
arr2 = []
if not arr:
print("arr은 비어있군요")
>>> Output
arr은 비어있지 않네요
arr은 비어있군요- 리스트 내에 n 이 있는지 확인
arr = [1, 2, 3]
# Case 1) .index() 활용
# .index()는 찾을 대상이 없으면 Exception 발생
try:
if arr.index(1):
print("리스트에 '1'이 있어요")
except ValueError:
print("리스트에 '1'은 없어요")
# Case 2) in 활용
# 찾을 대상이 리스트에 없어도 예외가 발생하지 않는다.
if 1 in arr:
print("리스트에 '1'이 있어요")
else:
print("리스트에 '1'은 없어요")- 리스트 내 중복제거
arr = [10, 20, 10, 15, 20, 40]
arr = list(set(arr)) # [40, 10, 20, 15]mutable object의 복사에 대해
mutable 객체는 재 할당 시 주의해야 한다. a를 b에 대입하여 선언하면 값만 복사되는게 아니다.
실제로 흔하게 하는 실수!!!!
예를 들면
"""
1~10 까지 숫자를 가지는 numbers1, numbers2를 만든다
단, numbers2 의 앞 5개 원소는 2배씩 증가시켜 저장한다. 이때, numbers1 은 보존되어야 한다.
"""
numbers1 = list(range(1, 11)) # 1. 1~10까지 리스트에 할당
numbers2 = numbers1 # 2. numbers2에 numbers1의 사본이 생겼겠지?
for i in range(5):
numbers2[i] *= 2
print(numbers1)
print(numbers2)
>>> Guess
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # numbers1
[2, 4, 6, 8, 10, 6, 7, 8, 9, 10] # numbers2
>>> Output
[2, 4, 6, 8, 10, 6, 7, 8, 9, 10] # numbers1도 같이 변해버렸다?
[2, 4, 6, 8, 10, 6, 7, 8, 9, 10]각 변수의 id를 확인해보면 같은 값이다.
print(f"numbers1의 id는 {id(numbers1)} 입니다")
print(f"numbers2의 id는 {id(numbers2)} 입니다")
>>> Output
numbers1의 id는 140573167644800 입니다
numbers2의 id는 140573167644800 입니다이런 상황이 발생하지 않으려면? .copy() 메소드로 복사하자
numbers1 = list(range(1, 11)) # 1. 1~10까지 리스트에 할당
numbers2 = numbers1.copy() # 2. numbers2에 numbers1과 같은 값이지만 다른 id를 가진다
"""
아니면 또 쓰기..
numbers2 = list(range(1, 11))
"""
for i in range(5):
numbers2[i] *= 2
print(f"id: {id(numbers1)}, {numbers1}")
print(f"id: {id(numbers2)}, {numbers2}")
>>> Output
id: 140704004809600, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
id: 140704004809536, [2, 4, 6, 8, 10, 6, 7, 8, 9, 10] # id도 다르고 numbers2만 바뀌었다.리스트 표현식(List comprehension)
[ ] 리스트 괄호 안에 요소들이 열거되지 않고 for 와 if 가 쓰여있다면 리스트 표현식이 사용된 것
# 1) for만 이용한 표현법
arr = [i for i in range(10)] # arr = [0, 1, 2, ... 9]
# for 에서 반복되며 생성된 i가 배열에 대입된다.
# 2) 그럼 여기에서 가중치를 줄 수 있나?
arr2 = [i+1 for i in range(10)] # arr2 = [1, 2, 3, ... 10]
# 3) 여기에서 혹시 조건을 줄 수 있나? 짝수만 담을래
arr3 = [i for i in range(10) if i % 2 == 0]
# 주의)
arr4 = [i+1 for i in range(10) if i % 2 == 0]
# 여기에서 i+1이 대입되지만, if에서 비교하는 i 와는 다르다. (i <> i+1)
# 타이핑 상 대입부를 먼저 기록하다보면 햇갈릴 수 있음!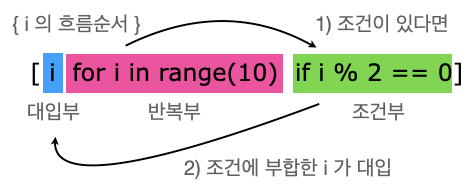
- 리스트 표현식을 안쓴것과 얼마나 다르지?
# Case 1: 리스트 표현식
arr1 = [i+1 for i in range(10) if i % 2 == 0]
# Case 2: 상세 기술
arr2 = []
for i in range(10):
if i % 2 == 0:
arr2.append(i+1)조건이 복잡해지면 리스트 표현식으로는 한계가 있다. 가급적 단순한 것들만!
- 반복문 중첩
gugudan = [f"{x}x{y}={x*y}" for x in range(2, 10) for y in range(1, 10)]
print(gugudan)
"""
gugu = []
for x in range(2, 10):
for y in range(1, 10):
gugu.append(f"{x}x{y}={x*y}")
"""
>>> Output
['2x1=2', '2x2=4', ... '9x9=81']- 반복문 중첩에서 조건은?
# m x n 일때, m은 짝수, n은 홀수만 기록하면?
gugudan = [
f"{x}x{y}={x*y}"
for x in range(2, 10)
for y in range(1, 10)
if x % 2 == 0 and y % 2 == 1
]
# 마지막 조건부에서 중첩 for의 x, y 모두 가져와 비교할 수 있다.
print(gugudan)
>>> Output
['2x1=2', '2x3=6', '2x5=10', '2x7=14', '2x9=18', '4x1=4', '4x3=12', '4x5=20', '4x7=28', '4x9=36', '6x1=6', '6x3=18', '6x5=30', '6x7=42', '6x9=54', '8x1=8', '8x3=24', '8x5=40', '8x7=56', '8x9=72']- 리스트 표현식이 만능은 아님
# 0 ~ 9 까지 수를 가지는 리스트
x = [i for i in range(10)]
y = list(range(10))
print(x, y)
# "hello world" 를 Hello World로 출력하기 위해 "Hello", "World" 로 전처리 해두기
x = [i.capitalize() for i in "hello world".split()]
y = list(map(lambda i: i.capitalize(), "hello world".split()))
print(x, y)튜플(tuple)
리스트와 유사하지만 변형이 불가능한 immutable object 이다.
리스트가 [ ] 대괄호 였다면, 튜플은 ( ) 괄호 이다.
기본적으로 튜플은 선언 후 변형할 수 없다.
a = (1, 2, 3)
print(a[2]) # Output >> 2
a[2] = 5 # 대입할 수 없다.
>>> Output
TypeError: 'tuple' object does not support item assignment위 리스트와 다른 점만 살펴본다면, 이해가 빠르지 않을까..?
리스트와 비교표
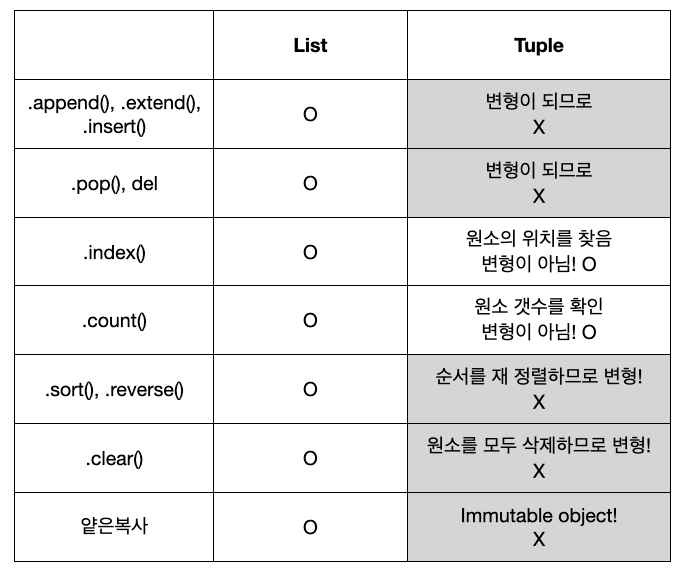
부득이하게 새 값을 추가해야 할 경우
매번 새로 선언할 순 없으니..
# 기존 리스트와 비교를 위해
list_a = [1, 2, 3]
print(f"더하기 전 id: {id(list_a)}")
list_a.append(5)
print(f"더한 후 id: {id(list_a)}") # 동일한 id가 찍힌다.
print(list_a) # [1, 2, 3, 5]
# 튜플은?
tuple_a = (1, 2, 3)
print(f"더하기 전 id: {id(tuple_a)}") # 140573721050432
tuple_a += (5,) # tuple_b = tuple_a + (5, 6, 7)
print(f"더한 후 id: {id(tuple_a)}") # 140573718939184. 다른 id가 찍힌다
print(tuple_a) # (1, 2, 3, 5)Tip!
튜플은 무조건 새로 생성된다고 보면 된다.
이때, 덧붙일 원소가 하나만 있을 수 있다. 위처럼 (5,) 로 표현되어 있는데 이는 (5)가 일반 괄호인지 튜플표현인지 구분이 힘들어서인데, 원소가 하나일 땐 꼭 콤마를 찍어주자!
튜플의 표현식
튜플도 리스트 표현식과 동일한 방법으로 사용할 수 있다.
다만 몇가지 주의사항이 있는데
- 단순 괄호( )만 사용하면 안된다.
list_comp = [i+1 for i in range(10) if i % 2 == 0]
print(list_comp) # [1, 3, 5, 7, 9]
# [] 를 () 로만 치환하면 되겠지?
tuple_comp = (i+1 for i in range(10) if i % 2 == 0)
print(tuple_comp) # <generator object <genexpr> at 0x7fabf6377e40>웬 처음보는 generator가 나오는데, 나중에 배울 개념이므로 pass..
아무튼, 단순괄호는 제너레이터 표현식이 되어버린다.
- 괄호가 아니라 tuple() 이다
tuple_comp = tuple(i+1 for i in range(10) if i % 2 == 0)
print(tuple_comp) # (1, 3, 5, 7, 9)map([함수], [이터레이터]) 이해
이터레이터에서 발생한 원소를 함수에 대입하여 이터레이터로 반환한다.
# date란 문자열이 있습니다.
# 년 월 일에 해당하는 숫자를 모두 더해 출력하세요
date_str = "2021. 12. 30"
# Case 1. for문 활용하기
total = 0
for i in date_str.split(". "):
total += int(i)
print(total)
# Case 2. map 활용하기
total = sum(map(int, date_str.split(". ")))
print(total)해설
1. .split() 에서 뽑히는 2021, 12, 30 각 문자를
2. int 함수에 대입하여준다.
→ sum( [ int(”2021”), int(”12”), int(”30”) ] )
max(), min(), sum()
리스트와 튜플 모두 사용할 수 있다.
원소들 중 가장 큰 값, 가장 작은 값, 전체 합을 구할 수 있는 기본 함수를 제공하고 있다.
list_ = [10, 20, 30, 40, 50]
tuple_ = (20, 10, 40, 30, 50)
max(list_) # 50
min(tuple_) # 10
sum(list_) + sum(tuple_). # 300파이썬 기본함수엔 avg() 같은 평균을 구하는 함수는 없다.
avg = sum(list) / len(list)
