본 문서는 “Learning Data Augmentation Strategies for Object Detection” 논문을 리뷰합니다.
논문 링크 : https://arxiv.org/pdf/1906.11172.pdf
개요
데이터 증강은 딥러닝 모델 학습에 아주 중요한 부분입니다. 데이터 증강이 이미지 분류 모델을 눈의 띄게 향상 시키긴 했지만 그 잠재된 가능성은 아직 다 연구되지 않은 상태입니다. 객체 검출 모델의 데이터 라벨링 작업에 더 많은 자원이 소모되는 것을 볼 때, 데이터 증강은 컴퓨터 비전 분야에 있어 훨씬 더 중요해 보입니다. 이미지 분류 모델로부터 데이터 증강 연산들을 차용한 결과, 성능은 향상 되지만 한계가 있었습니다. 그리하여 우리는 어떻게 학습되고 전문화 된 데이터 증강 정책이 검출 모델의 일반화 성능을 향상 시키는지를 연구했습니다. COCO 데이터셋에 대한 최적화 된 데이터 증강 정책은 mAP를 2.3 이상 증가시켜 mAP라는 SOTA 성능을 달성했습니다.
도입
객체 검출은 바운딩 박스 위치와 변형된 이미지 사이의 일관성을 유지시켜야 하는 복잡성을 야기합니다. 따라서 데이터 증강에 바운딩 박스를 사용하여 바운딩 박스 내의 이미지에만 데이터 증강 작업을 할 수도 있습니다. 추가로 이미지가 변환될 때 바운딩 박스를 그에 맞게 변경시키는 방법에 대해서도 연구했습니다.

우리는 정렬되지 않은 5개의 정책 세트들로 데이터 증강 정책을 규정합니다. 하나의 정책 세트를 훈련하는 동안 세트 중 랜덤하게 선택하여 현재의 이미지에 적용하도록 합니다. 하나의 정책은 2개의 이미지 변환 동작을 순차적으로 수행합니다. 이를 검색 공간을 생성하여 최적의 증강 정책을 찾도록 합니다.
몇가지 예비 실험에서 우리는 객체 검출에 효과적인 것으로 보이는 22개의 변형 작업을 정의했습니다. 이 작업은 Tensorflow로 구현했습니다. 이 변형 작업의 정의는 다음과 같습니다.
- 색상 변환
- 바운딩 박스 위치 이동 없이 컬러 채널들을 왜곡(Equalize, Contrast, Brightness)
- PIL 사용
- 형태 변환
- 위치 이동, 사이즈 변경 (Rotate, ShearX, TranslationY 등)
- 바운딩 박스 데이터도 수정
- 바운딩 박스 변환
- 바운딩 박스 내의 픽셀에 대한 왜곡 (Equalize, Rotate, FlipLR)
우리는 강화학습 알고리즘을 사용하여 정의된 22개의 변환 작업 중 최적의 5개의 세트를 찾았습니다.
증강할 데이터를 학습하여 최적의 알고리즘을 학습한 것이다. 따라서 유사한 결과를 얻기 위해서는 동일한 알고리즘을 사용하여 사용자 데이터에 대해 여기서 제공하는 알고리즘을 사용하여 학습을 진행해야 한다.
결과
우리는 COCO 데이터셋을 대상으로 실험하여 발견된 최상위 변환 정책들을 다른 데이터셋과 아키텍쳐에 적용하여 어떻게 수행되는지 연구하였습니다.
데이터 증강 정책 학습
좋은 정책에서 가장 일반적으로 사용되는 연산은 전체 이미지와 바운딩 박스를 회전시키는 Rotate입니다. 바운딩 박스는 회전 후에 더 커지게 되어 모든 회전된 객체를 포함합니다. 회전 작동의 이러한 효과에도 불구하고, 그것은 매우 유익한 것 같습니다. 그것은 좋은 정책에서 가장 자주 사용되는 작동입니다. 일반적으로 Equalize와 BBox_Only_TranslateY이 사용됩니다. Equalize는 픽셀 값의 히스토그램을 편형하게 하고 바운딩 박스의 크기나 위치를 변경하지 않습니다. BoxOnlyTranslateY는 바운딩 박스의 객체만 수직으로, 동일한 확률로 위아래로 변환합니다.
객체 검출을 향상 시키는 데이터 증강 정책
베이스라인 RetinaNet 아키텍쳐는 주로 이미지 분류기에서 사용하는 표준 데이터 증강 기술을 사용합니다. 이것은 좌우 반전을 50% 확률로 수행하고 이미지 크기를 512 ~ 786 사이로 리사이즈 하는 동안 다중 스케일 지터링(임의의 색상 변환)을 수행하고 640x640으로 크롭합니다.
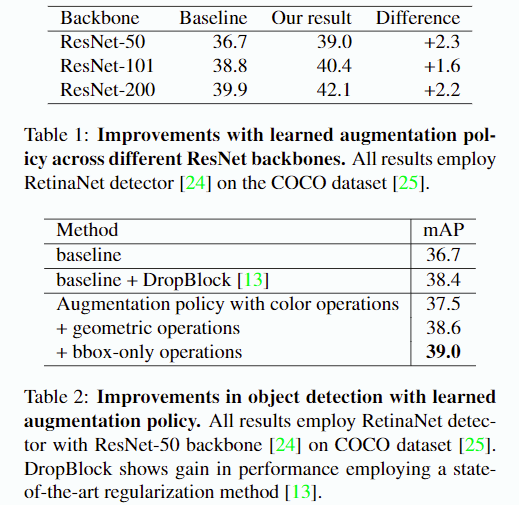
위의 절차에 대한 결과는 표1, 표2에서 확인할 수 있습니다. 표1에서 수행한 증강 정책은 여러 백본 아키텍쳐에 걸쳐 +1.6 ~ +2.3까지 향상을 달성합니다. 정확히 어떤 연산에 의해 얼마만큼의 향상이 이루어졌는지 표2를 통해 확인할 수 있습니다. 색상 연산을 통한 데이터 증강은 +0.8 mAP만을 가져왔습니다. 그런데 여기서 기하학적 연산(형태 변환)을 더했을 때 베이스라인으로 부터 +1.9 mAP를 일으켰고, 바운딩 박스 영역 내의 연산으로 최종적으로 +2.3mAP가 일어났습니다.
데이터 증강 정책을 통한 SOTA 달성
좋은 데이터 증강 정책은 다른 모델, 다른 데이터 세트 간에도 적용될 수 있고 잘 작동할 수 있어야 합니다. 따라서 우리는 서로 다른 백본 아키텍처와 검출 모델에 대해 증강정책을 실험하였습니다. ResNet-50 백본은 AmoebaNet-D로, RetinaNet은 NAS-FPN으로 변경하였습니다.
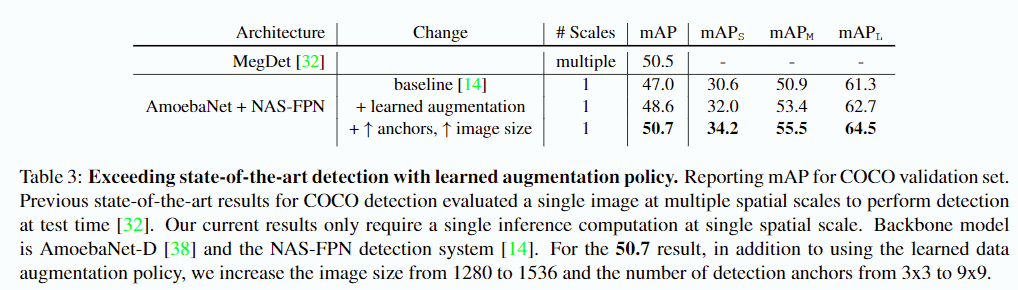
이 경우에도 +1.6 mAP가 향상되어 다른 백본 아키텍처에서도 잘 동작하는 것을 확인할 수 있었습니다. 이 결과는 COCO 데이터셋에서 최초로 50.7 mAP 결과를 달성한 1-stage 객체 검출 모델입니다. 이 결과는 이미지 해상도를 높이고 앵커의 수를 증가시킴으로 달성되었습니다.
많은 양의 데이터 셋에서의 결과
이 섹션에서는 학습 데이터가 더 많거나 적은 경우 증강 정책이 어떻게 수행되는지를 실험하였습니다. 이 실험을 위해 5000, 9000, 14000, 23000 장의 데이터셋을 만들었고, ResNet-50 백본을 사용하여 사전학습 없이 150 epoch을 학습하였습니다.
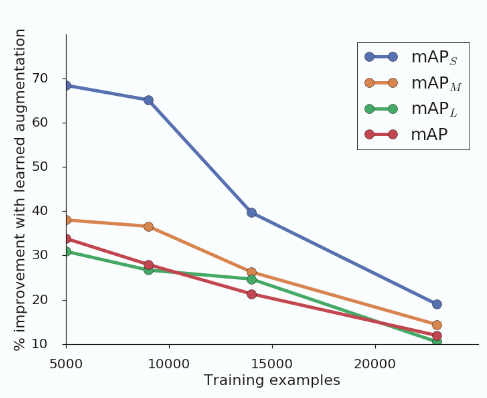
예상대로, 증강 정책으로 인한 성능 향상은 더 작은 데이터 세트에 대해 학습될 때 더 컸습니다. 우리는 5,000 개의 학습 샘플에 대해 학습된 모델의 경우, 증강 정책이 베이스라인에 비하여 mAP를 70% 이상 향상 시킬 수 있음을 확인하였습니다. 학습데이터 수가 증가함에 따라 증강 정책의 효과는 감소하지만 개선은 여전히 이루어지고 있습니다.
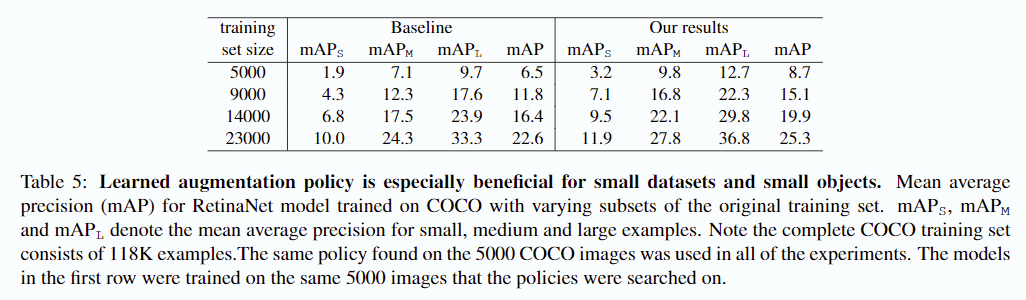
흥미로운 사실은 이 증강 정책으로 학습된 모델은 특히 적은 데이터셋에 대해 더 작은 객체를 더 잘 감지하도록 한다는 것입니다. 예를 들어, 작은 개체의 경우 학습된 증강 정책을 적용하는 것이 데이터 수를 50% 증가시키는 것 보다 더 효율적이라는 것입니다.
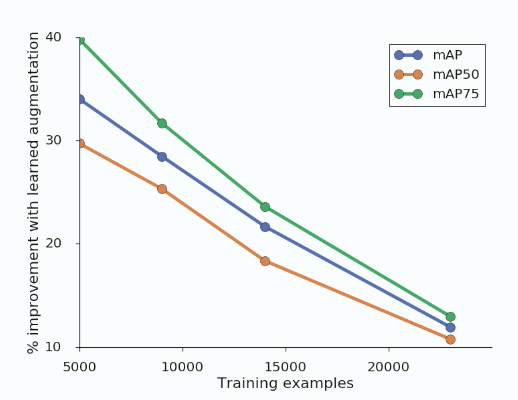
또 다른 흥미로운 사실은 mAP(@0.75)의 어려운 작업에서 상대적으로 성능향상이 더 많이 이루어졌다는 사실입니다. 이는 데이터 증강 정책이 바운딩 박스 위치의 공간적인 세부 사항을 잘 학습하는데 도움을 준다는 것을 의미하며, 이는 작은 객체에서 관찰된 이점과 일치합니다.
결론
본 연구에서는 객체 감지 성능에 대한 학습된 데이터 확대 정책의 적용을 조사한다.학습된 데이터 확대 정책은 고려된 모든 데이터 크기에 걸쳐 효과적이며, 훈련 세트가 작을 때 더 크게 개선된다. 우리는 또한 학습된 데이터 확대 정책으로 인한 개선이 더 작은 물체를 감지하고 더 정확하게 탐지하는 어려운 작업에서 더 크다는 것을 관찰한다.
