
본 문서는 불균형 클래스 문제 해결을 위해 상대적으로 갯수가 적은 클래스를 데이터 증강 기법으로 생성한 후 모델 성능지표를 분석하기 위해 작성되었습니다.
이슈
현재 작업 중인 프로젝트는 Class-Imbalanced 데이터셋(참조 : https://stans.atlassian.net/wiki/spaces/SMST/pages/13795347)으로 학습된 상태입니다. 따라서 상대적으로 데이터 수가 적은 모델의 경우 검출 성능이 좋지 않을 수 있습니다. 현재 데이터가 가장 적은 클래스 상위 5개를 추려보니 데이터 추가 확보가 가장 시급한 상황입니다.
그러나 데이터 확보 작업이 간단한 일은 아닙니다. 따라서 데이터 증강기법을 통해 데이터셋 수를 늘리는 방식으로 성능을 향상 시킬 수 있는지, 세부적인 지표는 어떻게 변화하는지를 실험하여 다양한 성능향상 방안을 모색하고자 합니다.
여기서 말하는 데이터 증강이란, 학습시에 이미지에 변화를 주어 일반화에 기여하는 방식이 아닌, 이미지 데이터 수 자체를 증가시키는 작업을 의미합니다.
데이터 증강 라이브러리 선정
데이터셋 증강에 있어 고려해야 할 부분은 라벨링 된 데이터셋의 바운딩 박스 정보도 함께 변경이 일어나야 한다는 점입니다. 이미지 분류기의 경우 이미지에 변형이 발생해도 학습될 Ground-Truth 정보는 동일하므로 문제가 되지 않지만, 객체 검출기의 경우 이미지의 형태가 변형되는 경우 바운딩 박스 데이터도 함께 변형되어야 하는데 이 작업은 기존 Keras, Pytorch 등의 framework에서 제공하는 Data Augmentation 모듈에서 지원하는 내용은 아닙니다. 따라서 해당 기능을 지원하는 라이브러리를 리서치하거나 직접 구현해야 합니다.
여러가지 증강 라이브러리 중 https://github.com/aleju/imgaug 이 가장 적합하다고 판단하여 이를 활용하였습니다.
증강 기법
“Learning Data Augmentation Strategies for Object Detection” 논문을 참고하여 가장 효과적으로 판단되는 증강 기법을 목록화 하였습니다. 해당 논문에 등장하는 기법은 아래 그림과 같습니다.

imgaug 라이브러리를 통해 위의 연산기법과 유사한 형태로 4가지 증강 연산 작업 시퀀스를 생성하였습니다.
[iaa.Sequential([
iaa.Crop(percent=(0, 0.1)),
iaa.pillike.Equalize(),
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
shear=(-16, 16),
)
]),
iaa.Sequential([
iaa.Crop(percent=(0, 0.1)),
iaa.pillike.Equalize(),
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
rotate=(-25, 25),
)
]),
iaa.Sequential([
iaa.Fliplr(1.0),
iaa.AddToBrightness((-30, 30)),
]),
iaa.Sequential([
iaa.Fliplr(1.0),
iaa.MultiplyHueAndSaturation(mul_hue=(0.8, 1.2))
])]클래스 선정 및 증강
자체 데이터셋에서 이미지 수, 객체 수를 기준으로 내림차순 후, 가장 적은 양의 데이터 셋을 목록화 합니다. 다음은 가장 적은 수 클래스 A, B, C를 증강하였습니다.
- class A : 760장
- class B : 2588장
- class C : 4196장
증강데이터 학습 결과 및 분석
위의 증강 이미지를 추가 학습한 후, 다양한 성능지표를 추출하여 비교 분석합니다. 본 지표 분석은 https://github.com/Cartucho/mAP 를 사용하였습니다.
AP 비교
| 클래스 | 증강 전(AP) | 증강 후(AP) |
|---|---|---|
| A | 0.88 | 0.91 |
| B | 0.72 | 0.89 |
| C | 0.29 | 0.52 |
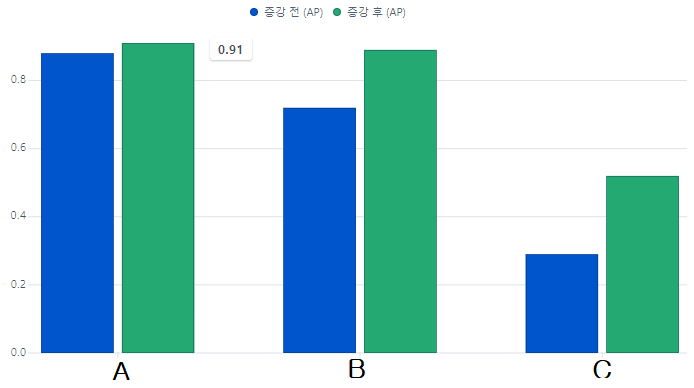
각 클래스 마다 모두 AP가 증가한 것을 확인할 수 있습니다. 그 증가폭은 클래스 별로 다르지만 공동점은 모두 향상했다는 것입니다.
AP 증가율
| 클래스 | 증가 율 |
|---|---|
| A | 3% |
| B | 24% |
| C | 79% |
데이터 증강 후, 증가율은 가장 증강 수가 적은 A번 클래스가 가장 적게 증가하였습니다. 증강 숫자가 가장 많은 B 클래스보다 C번 클래스가 더 크게 성능이 증가한 부분은 인상적입니다.
TP, FP 비교
| 클래스(객체 수) | 증강 전 | 증강 후 |
|---|---|---|
| A(39) | TP=35, FP=6 | TP=36, FP=6 |
| B(353) | TP=260, FP=48 | TP=323, FP=68 |
| C(154) | TP=87, FP=91 | TP=139, FP=138 |
Recall, Precision 비교
| 클래스(객체 수) | 증강 전 | 증강 후 |
|---|---|---|
| A(39) | Recall=0.89, Precision=0.85 | Recall=0.92, Precision=0.85 |
| B(353) | Recall=0.73, Precision=0.84 | Recall=0.91, Precision=0.83 |
| C(154) | Recall=0.56, Precision=0.49 | Recall=0.90, Precision=0.50 |
전반적으로 정밀도는 유지된 채로, 재현율이 상승하는 방식으로 성능이 개선되었습니다. C 클래스의 경우 다른 클래스보다 크게 증가한 부분이 눈에 띕니다.
C 클래스의 재현율이 큰 폭으로 증가한 원인 분석
C 클래스가 B 클래스보다 증강 데이터가 더 적음에도 AP, Recall 등의 지표가 상대적으로 큰 폭으로 상승한 원인을 분석하고 대응합니다.
C 클래스는 클래스 자체를 검출하기 위해 지정한 것이 아닙니다. C 클래스와 유사한 형태이지만 실제로는 다른 객체와 분리될 수 있도록 D 클래스로 지정하여 네거티브 데이터셋으로 학습하고 있습니다. 따라서 D 클래스의 지표 변화를 확인하는 것이 필요합니다.
| 클래스(객체 수) | 증강 전 | 증강 후 |
|---|---|---|
| C(154) | AP=0.29, TP=87, FP=91, Recall=0.56, Precision=0.49 | AP=0.52, TP=139, FP=138, Recall=0.90, Precision=0.50 |
| D(1446) | AP=0.89, TP=1321, FP=309, Recall=0.91, Precision=0.81 | AP=0.86, TP=1263, FP=249, Recall=0.87, Precision=0.83 |
이 표를 볼 때, 클래스 D의 TP+FP는 118 감소했고, 클래스 C의 TP+FP는 99 증가했습니다. 즉 클래스 D라고 추론한 갯수가 줄어든 만큼 대부분 클래스 C로 추론된 것을 알 수 있습니다. 이에 더하여 클래스 C의 객체 수가 상대적으로 많이 적고 Recall은 실제 객체 후를 나누는 작업이다보니, 클래스 C의 Recall은 클래스 1이 줄어든 양보다 더 큰 폭으로 상승할 수 밖에 없었습니다.
결론
데이터 증강은 성능향상에 도움이 되는 것을 확인했습니다. 증강된 데이터 양이 많은 클래스일 수록 성능지표도 향상하는 결과를 확인할 수 있었습니다. 정밀도보다는 재현율이 상승하는 효과가 있었습니다.
