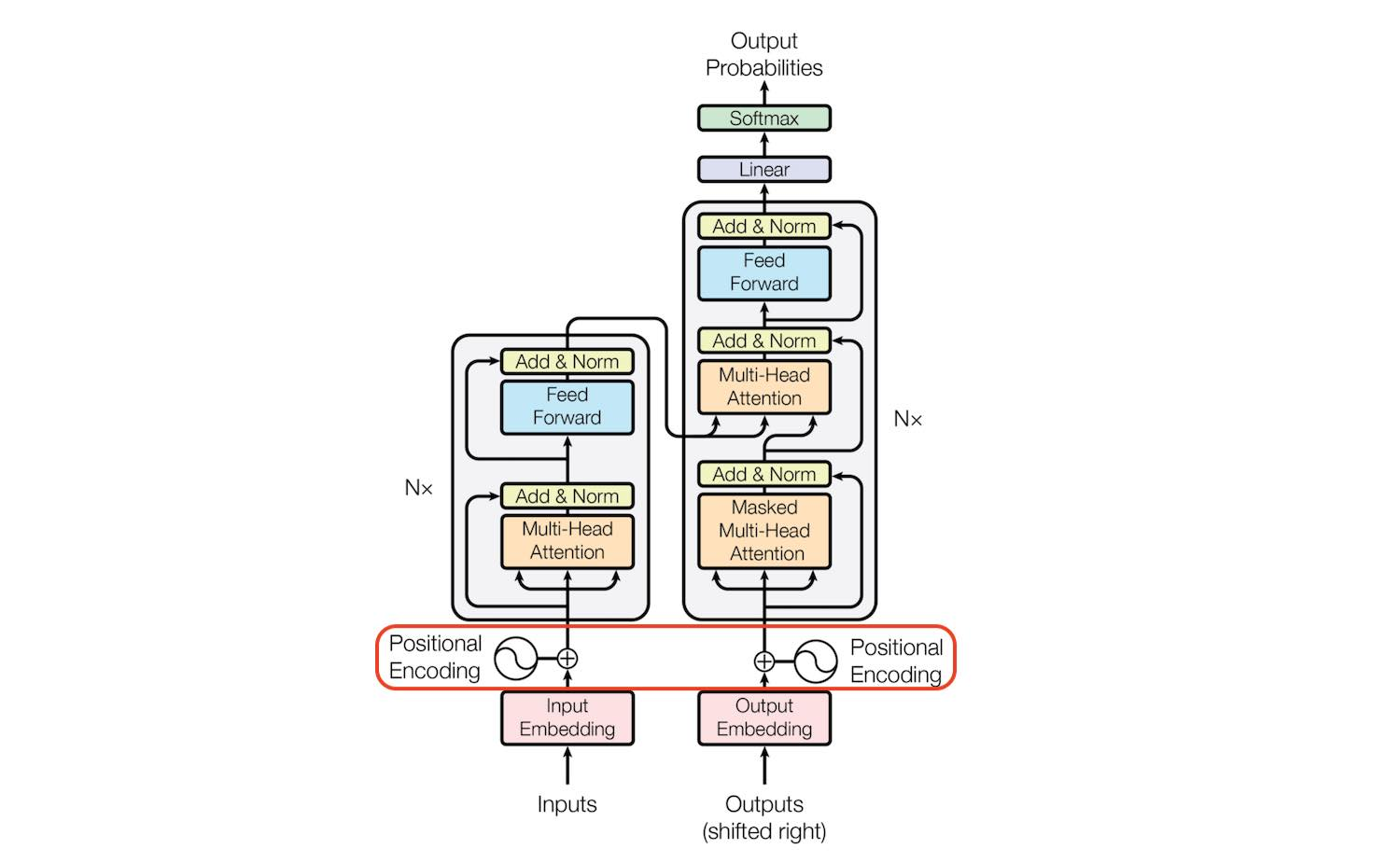
트랜스포머 아키텍처는 attention으로만 구성된 새로운 seq2seq 아키텍처로서 Vaswani et al.에 의해 제안되었다. 이 구조는 병렬로 학습이 가능한 것과 전반적으로 성능이 향상된 부분 때문에 NLP 연구자들에게 유명해졌다.
딥러닝 프레임워크의 몇가지 구현체 덕분에 저를 포함한 많은 학습자들이 실험하기가 쉬워졌다. 그러나 접근성은 좋은 일이지만 모델의 밑부분에 대해서는 무시하게 되는 부분은 부정적인 면이다.
이 문서에서는 몇몇 훌륭한 튜토리얼에서 설명하는 것처럼 아키텍처를 깊이 설명할 생각은 없다. 다만, 트랜스포머 구조의 특정 파트인 Positional Encoding에 대해 다루어 보려고 한다.
논문의 이 부분을 읽었을 때, 저자가 대답을 제공하고 있지 않은 몇가지 질문들이 내 머리속에 일어났다. 그래서 이 글에서 나는 이 모듈이 어떻게 동작하는지를 쪼개어 보려고 한다.
Positional Encoding은 무엇인가
단어의 위치와 순서는 어떤 언어든 기초적인 부분이다. 이것들이 문법과 문장의 실제 의미를 만든다. RNN은 본질적으로 단어의 순서를 고려한다. 순차적인 방법으로 단어에 의해 문장을 분석한다. 이것은 RNN의 backbone 안에서 단어의 순서를 통합한다.
그러나 트랜스포머 아키텍처는 multi-head self-attention 매커니즘을 사용하여 순환신경망 구조를 버렸다. RNN의 순환구조를 제거함으로 학습속도가 엄청나게 상승했다.
트랜스포머의 인코더/디코더 스택에 문장의 단어들을 동시에 흘러보내기 때문에, 모델은 각 단어의 순서와 위치를 알 수 없다. 그렇기 때문에 모델에 단어들의 순서정보를 포함하기 위한 방법이 여전히 필요하다.
모델에 순서정보를 인식시키기 위한 한가지 해결책은 각 단어에 그 단어의 문장에서의 위치정보를 추가하는 것이다. 우리는 이것을 positional encoding이라고 부른다.
마음에 떠오르는 첫번째 아이디어는 각 타입스텝에 0~1사이의 범위의 숫자를 부여하는 것이다. 여기서 0은 문장의 가장 첫번째 단어를 의미하고 1은 마지막 단어를 의미한다. 이 방법이 어떤 이슈를 유발할까? 한가지 문제는 특정 범위 내에 얼마나 많은 단어가 존재하는지 파악할 수 없다는 것이다. 타임스탭 delta는 각 문장들 마다 의미가 다르다.
다른 아이디어는 각 타임스텝에 선형적으로 숫자를 부여하는 것이다. 첫번째 단어는 "1", 두번째 단어는 "2"가 부여되는 것이다. 이 방식의 문제는 값이 매우 커질 수 있다는 것 뿐 아니라, 학습시 더 긴 문장을 만날 수 있다는 것이다. 추가로, 우리 모델은 모델의 일반화를 저해할 수 있는 정해진 길이의 문장들을 학습시키진 않을 것이다.
이상적으로 다음의 기준들이 충족되어야 할 것이다.
각 타임스텝(문장에서의 단어의 위치)마다 고유한 인코딩이 출력되어야 함
어떠한 두 타입스텝 간의 거리가 길이에 따라 달라져야 함
긴 문장을 일반화시키는 것에 추가적인 cost가 들어가지 않아야 함. 그 값은 제한되어야 함.
deterministic해야 함(한 계산에 대해 유일하게 하나의 값만을 갖는 개념)
제안된 방법
논문 저자에 의해 제안된 인코딩은 간단하면서도 천재적인 테크닉으로 위의 모든 기준들을 만족시켰다. 첫째로, 이것은 하나짜리 숫자가 아닌, 문장의 특정 위치 정보가 포함된 d-dimensional vector이다. 둘째로, 이 인코딩은 모델 자체에 통합되는 대신, 각 단어에 문장에서의 위치정보를 장착된다. 다르게 말하면 모델의 입력에 단어의 순서를 삽입하는 것이다.
t는 입력 문장에서 원하는 위치라하고 pt∈Rd를 관련 인코딩이라 하고, d를 인코딩 차원(where d≡20 {차원은 짝수로 제한})이라 하면 f:N→Rd은 vector pt를 출력하는 함수가 될 것이다. 이것은 다음과 같이 정의할 수 있다.
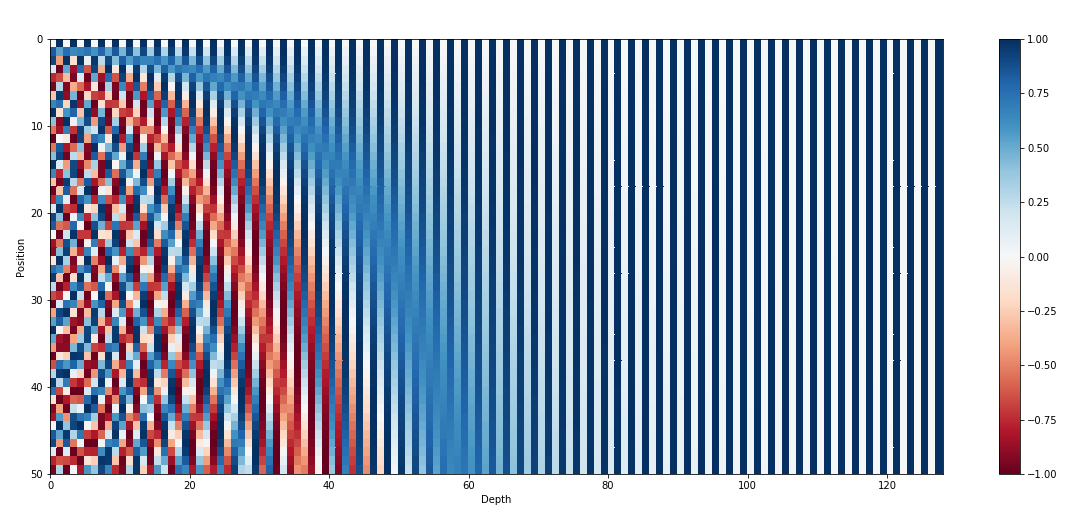
서로 다른 비트 사이의 변화율을 확인할 수 있다. LSB bit는 매 숫자마다 번갈아가며 1이 등장한다. 그 다음 자리는 두 숫자마다 반복된다.
역자 노트
LSB(Least Significant Bit)는 이진수 표현에서 가장 낮은(오른쪽 끝) 자릿수 비트를 나타냅니다. 이진수는 0과 1로 이루어진 숫자 체계이며, 각 자릿수는 2의 거듭제곱을 나타냅니다. LSB는 그 중에서 가장 작은 자릿수를 의미합니다.
그러나 binary value를 사용하는 것은 실수 공간에서 너무 많은 낭비가 된다. 그래서 그 대신 실수의 연속 공간에 대응하기 위한 sin 함수를 사용할 수 있다. 그것은 비트가 반복되는 것이 동일하다. 게다가 그들의 주파수를 줄임으로서, 아래 그림에서 빨간 색으로부터 오렌지로 변경될 수 있다.
다른 디테일..
이 글 서두에 positional embedding이 입력 단어들에 위치 정보가 장착되는데 사용된다고 언급했다. 그러나 어떻게 가능한가? 팩트는, 원본 논문은 실제 임베딩 위에 위치 인코딩을 추가했다. 다음처럼 문장에서 각 단어wt마다 임베딩을 계산하는 것이다.
ψ′(wt)=ψ(wt)+pt
더하기가 가능하려면 positional embedding의 차원이 단어의 임베딩과 같아야 한다.
상대 위치
다른 sinusoidal positional encoding의 특징은 모델로 하여금 상대 위치에 쉽게 접근할 수 있게 한다는 것이다.
논문 발췌
우리가 이 함수를 선택한 이유는 상대 위치에 대한 접근을 쉽게 학습할 것이라 가정했기 때문이다. 어떤 고정된 offset k이든 PEpos+k는 PEpos의 선형함수로 표현될 수 있기 때문이다.