
개요
진행중인 COVID-19 전염병은 위생 비접촉 생체 인식 시스템의 중요성을 더욱 강조했습니다. 정맥 기반 장치는 일상 생활에 완전히 통합되지는 않았지만 훌륭한 비접촉 옵션입니다. 이 연구에서는 이러한 장치의 연구 및 개발에 기여하기 위해 실제 적용되는 비접촉 손목 정맥 인식 시스템을 공개합니다. VBR(Vascular Biometric Recognition)을 위한 다양한 Deep Convolutional Neural Networks 아키텍처를 기반으로 하는 Transfer Learning(TL) 방법이 연구 접근 방식에서 처음으로 스마트폰에서 설계 및 테스트되었습니다. TL은 특징 추출기로 네트워크로 나눌 수 있는 딥 러닝(DL) 기술입니다. 사전 훈련된(다른 대규모 데이터 세트) CNN(Convolutional Neural Network)을 사용하여 고유한 기능을 얻은 다음 기존 머신 러닝 알고리즘으로 분류하고 가중치로 초기화된 CNN을 미세 조정하는 것 사전 훈련된(다른 대규모 데이터 세트) CNN의 본 연구에서는 특징 추출기 기반 방법을 사용하였다. 여러 아키텍처 네트워크가 UC3M-CV1, UC3M-CV2 및 PUT과 같은 다양한 손목 정맥 데이터 세트에서 테스트되었습니다. DL 모델은 Xiaomi© Pocophone F1 및 Xiaomi© Mi 8 스마트폰에 통합되어 UC3M-CV2에서 50–50% 기차 테스트를 통해 최대 98%의 정확도 및 0.4% 미만의 EER을 달성하는 높은 생체 인식 성능을 얻습니다.
서론
SARS-CoV-2 바이러스로 인한 현재 전 세계적인 대유행에서 COVID-19 질병의 전파는 감염되지 않은 사람과 감염된 사람이 사용하는 물건 사이의 간접적인 접촉을 통해서도 발생할 수 있습니다 [1] . 이러한 의미에서 비접촉 다중 사용자 시스템은 위생적인 대안을 제공하여 이 질병의 전파를 방지하는 데 도움이 됩니다.
보안 세계에서 액세스 제어 및 지불을 위한 비접촉 생체 인식 시스템은 신뢰성, 견고성, 편안함, 그러나 훨씬 더 중요한 위생 측면에서 효과적인 솔루션입니다. 얼굴, 홍채, 비접촉 지문, 보행, 혈관 등 여러 비접촉 생체 인식 방식이 있습니다.
두 가지 주요 시스템이 혈관 또는 정맥 생체 인식(VBR) 산업을 정의합니다. Fujitsu© PalmSecure, 특허 US 2005/0148876 A1 [2] 및 Hitachi© Finger Vein Authentication, 특허 US 2011/0222740 A1 [3] . 전자는 비접촉 손바닥 정맥 시스템이고 후자는 접촉 손가락 시스템입니다. 이러한 특허에 비추어 볼 때 연구 세계에는 손등 정맥과 손목 정맥의 두 가지 다른 VBR 양식이 있습니다. 후자를 고려하여, 이전 연구 [4] 는 접근 제어 및 법의학 애플리케이션에 적합한 완전한 비접촉식 손목 VBR 시스템을 설명했습니다. 추가의 시스템이보고되어있다 [5] 및 [6] , 그러나, 사용자 및 디바이스 간의 물리적 접촉을 필요로한다.
이 경우 스마트폰에 내장된 비접촉식 손목 VBR의 또 다른 예는 미래의 온라인 결제, 은행 계좌 액세스 및 화면 잠금 해제에 사용하기 위해 최근 [7] 에 언급되었습니다 .
본 연구의 동기
VBR(Vascular or Vein Biometric Recognition)은 사용자 개인 정보 보호 측면에서 비접촉식 생체 인식 변형 중에서 가장 존경받는 방법 중 하나이지만(예: 얼굴 또는 홍채 인식과 대조됨) 불행히도 아직 일상 생활에 제대로 통합되지 않았습니다. 또한 스푸핑 공격을 방지하는 데 유용한 강력한 인식 기술뿐만 아니라 편안한 사용자-장치 상호 작용을 제공합니다. 정맥은 비협조적인 방법으로 포획하거나 훔칠 수 없는 내부 조직입니다.
위의 요인들이 현재 COVID-19 전파의 위험과 실제 VBR 솔루션의 부족으로 인해 증가하는 비접촉 시스템에 대한 수요와 결합되어 이 작업의 동기입니다.
본 연구의 기여사항
이 연구에서는 비접촉식 VBR을 위한 새로운 Transfer-Learning 기반 손목 시스템을 연구 접근 방식으로 처음으로 스마트폰에 내장했습니다.
손목 혈관을 기반으로 사람을 확인하고 식별하도록 설계된 지도 학습된 딥 러닝(DL) 모델은 사전 훈련된 CNN(Convolutional Neural Network)을 사용하여 고유한 기능을 얻은 다음 기존 머신 러닝 알고리즘으로 분류합니다. 신경망(NN)을 특징 추출기로만 사용하는 TL(Transfer Learning)로 알려진 이 기술은 CNN을 처음부터 훈련하는 현재의 생체 인식 DL 추세를 따르는 대신 공개되었습니다. 후자는 일반적으로 인식 성능 측면에서 TL과 유사한 결과를 얻는 더 복잡하고 시간 소모적인 연구 프로세스입니다. 또한 CNN을 특징 추출기로 사용하는 것은 혈관 생체 인식 최첨단 데이터 세트에서 사용자 클래스당 감소된 이미지 수를 위한 솔루션입니다.
이 가설을 입증하기 위해 임의의 특징 추출기인 네트워크 기반의 새로운 알고리즘이 공개되었을 뿐만 아니라 이 모델을 두 대의 스마트폰 장치에 통합하여 실제 적용을 증명하고 혈관 생체 인식 및 처리 성능을 평가했습니다.
Xiaomi Inc.©, Xiaomi© Pocophone F1( 그림 1a ) 및 Xiaomi© Mi 8( 그림 1b )에서 설계한 스마트폰 은 VBR 시스템을 완성하기 위한 전체 캡처, 처리 및 저장 하드웨어로 사용됩니다. 두 장치 모두 원래 얼굴 인식으로 잠금을 해제하는 데 사용된 근적외선 카메라를 탑재하고 있습니다.
ISO/IEC 19795–1 표준 [8] 에 따라 논의된 결과 는 스마트폰에 캡처된 고유한 비접촉 손목 데이터베이스인 UC3M-CV2 [7] 에서 얻습니다 . 현재의 최신 기술과 비교하기 위해 다른 비접촉 및 접촉 데이터 세트인 UC3M-CV1 [4] 및 PUT [9] 가 각각 사용되었습니다.
관련 연구
이 연구는 손목 솔루션을 제시하지만, 가장 최근의 적외선 이미지 기반 연구에 의존하는 현재 VBR State-of-the-Art는 손목 정맥 양식뿐만 아니라 손바닥, 손가락 및 손가락으로 강화된 것으로 분석되었습니다. 손 등 정맥 변이 연구. 이 섹션은 획득, 저장 및 처리 하드웨어로 구분됩니다.
획득, 저장, 하드웨어 처리
작년 2020년에는 감소된 수의 비접촉 획득 시스템이 제시되었습니다. "Wrist vascular biometric recognition using a portable contactless system" [4] 및 "On-the-fly finger-vein-based biometric recognition using deep neural networks" [10] . 전자는 수정된 근적외선 카메라, 저자가 설계한 근적외선 조명, 축소된 컴퓨터로 구성된 휴대용 손목 기반 시스템이다. 여기에는 사용자 안내를 위한 고정 위치 지정 알고리즘인 TGS-CVBR®이 포함됩니다. 이 시스템을 사용하여 각 사용자 상호 작용에 대해 이미지를 획득합니다.
후자는 4대의 저가형 근적외선 상용 카메라, 직사각형 격자 LED 조명 및 지정맥 인식을 위한 확산 유리를 사용하여 즉석 획득 방법을 보여줍니다. 시스템에서 사용자의 빠른 손 움직임(1-3초)과 비디오 캡처는 올바른 획득을 보장합니다.
"An automated biometric identification system using CNN-based palm vein recognition"[11] 은 다음 섹션에서 언급하는 CNN 인식 알고리즘을 기반으로 한 비접촉 손바닥 정맥 솔루션을 제시합니다.
이러한 시스템의 하드웨어 세부 정보는 표 1 에 나와 있습니다.
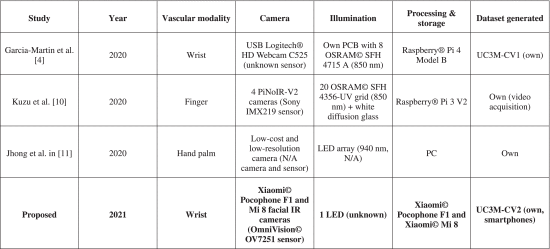
2020년 후반에는 비접촉 손목 VBR을 위해 캡처, 저장 및 처리 시스템이 스마트폰 "Vein biometric recognition on a smartphone" [7] 에 내장되었습니다 . 사용된 기기는 앞서 언급한 바와 같이 원래 안면 인식에 사용되던 근적외선 및 LED 조명을 탑재했습니다. "Wrist vascular biometric recognition using a portable contactless system" [4] 에 언급된 것과 동일한 정적 위치 지정 알고리즘 이 구현되었습니다.
현재 작업은 수집, 저장 및 인식 알고리즘(이 경우 새로운 딥 러닝 모델)을 동일한 장치에 통합할 수 있는 이 비접촉식 하드웨어 연구 라인을 따릅니다.
이 작업의 동기를 고려하고 이러한 연구와 현재 산업 동향을 분석하면 비접촉식 상호 작용이 유지될 것이라고 결론/예측하는 것이 틀리지 않을 것입니다.
인식 알고리즘
패턴 인식을 위한 딥 러닝 알고리즘이 등장한 후 지난 5-10년 동안 VBR에 대한 대부분의 연구 연구는 DL 알고리즘에 의존했으며 종종 기존 머신 러닝을 대체했습니다. 그러나 손목 정맥 인식 변형에는 DL이 적용되지 않았습니다. 따라서 손목 연구 접근법에서 이러한 알고리즘을 처음으로 도입하기 위해서는 다른 혈관 양상에 대한 DL 기법 분석이 필요했습니다.
이전 연구 "On-the-fly finger-vein-based biometric recognition using deep neural networks" [10]에서 알 수 있듯이 Deep Convolutional Neural Networks는 지정맥 인식의 주요 연구 대상입니다. VGG16 [12] , ResNet50 및 ResNet101 "DeepVein: Novel finger vein verification methods based on deep convolutional neural networks" [ 12] 과 같이 높은 인증(동일 오류율, EER, 5% 미만) 및 식별(Correct Identification Rates, CIR, 95% 이상) 성능 모델로 다양한 CNN 아키텍처가 처음부터 구현 및 교육되었습니다. "W. Kim, J. M. Song and K. R. Park, "Multimodal biometric recognition based on convolutional neural network by the fusion of finger-vein and finger shape using near-infrared (NIR) camera sensor" [13] , DenseNet "Finger-vein recognition based on deep DenseNet using composite image" [14] , 저자 "Deep representation for finger-vein image-quality assessment" [15] 등이 설계 했습니다.
"DeepVein: Novel finger vein verification methods based on deep convolutional neural networks" [12] VGG16 CNN에서 영감을 얻은 모델을 지정맥 이미지 크기(Region Of Interest= 128 × 128 ) 이 잘 알려진 아키텍처를 기반으로 하기 때문에 3 × 3 ReLU(Convolutional + Activation) 레이어 블록은 224 × 224 입력 레이어.
표 2에 요약된 바와 같이 Kim et al. 은 ResNet50/ResNet101 또는 DenseNet161과 같은 마이크로 아키텍처에 의존하는 더 깊은 아키텍처를 적용했습니다 . "Multimodal biometric recognition based on convolutional neural network by the fusion of finger-vein and finger shape using near-infrared (NIR) camera sensor" [13] 및 "Finger-vein recognition based on deep DenseNet using composite image" [14] 각각. ResNet은 이전 convolutional(연속적이지 않음) 레이어에서 정보(참조)를 얻는 잔여 모듈을 사용하여 더 깊은 훈련(따라서 더 높은 분류 정확도)을 허용합니다. 유사한 아키텍처 목표이지만 다른 참조 구성이 "Densely connected convolutional networks"에 의해 도입되었습니다 .
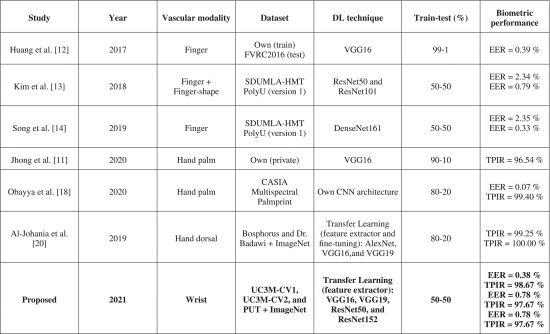
손바닥 정맥에 있어서는 DL 기반 솔루션을 발견하는 것이 더 어렵습니다(손등 정맥에서는 훨씬 더 어렵습니다). 적은 수의 CNN 아키텍처가 테스트되었습니다. "An automated biometric identification system using CNN-based palm vein recognition" [11] 은 이전에 CLAHE(Contrast Limited Adaptive Histogram Equalization) 알고리즘으로 개선된 비접촉 이미지(저자가 획득)를 사용하여 VGG16에서 영감을 받은 솔루션을 제시했습니다 "Adaptive histogram equalization and its variations" [17] . 전처리 단계(ROI 추출 제외)는 원시 이미지로 달성된 높은 인식 성능으로 인해 CNN 솔루션에서 그리 일반적이지 않지만 이미지의 품질이 낮거나 ROI의 크기가 축소된 경우 최적일 수 있습니다. 현재 작업에서 CLAHE 알고리즘도 테스트되고 원시 이미지와 비교됩니다. "Contactless palm vein authentication using deep learning with Bayesian optimization"[18]은 CNN 학습 및 테스트 를 위해 CASIA Multispectral Palmprint Image 데이터베이스 (http://biometrics.idealtest.org/) [19] 를 사용하여 비접촉식 손바닥 솔루션을 제시합니다. CNN 아키텍처는 최적의 네트워크 구조와 매개변수를 찾기 위해 베이지안 최적화를 사용하여 작성자가 설계하고 훈련했습니다.
마지막으로 손목 VBR에서는 현재 연구 이전에 DL 솔루션이 공개되지 않았습니다. 손목 연구에 대한 기여 측면에서 이전에 기여 섹션에서 지적한 바와 같이(기여 섹션), 딥러닝 기술이 처음으로 공개되었습니다. 이 DL 알고리즘은 이 양식뿐만 아니라 전체 VBR 연구에 있어서도 새로운 것입니다. 왜냐하면 현재 분석에서 추출할 수 있듯이 CNN 아키텍처는 Transfer Learning을 사용하는 대신 처음부터 훈련되기 때문입니다. 정맥 인식 최첨단 네트워크는 적외선 이미지로 교육되어 고유한 기능을 추출하고 원하는 사용자 레이블을 적용하여 분류할 수 있습니다. TL이 생체 인식 알고리즘의 개발을 위해 이전에 연구 세계에서 사용되어 왔음에도 불구하고, 알려진 바로는 [20]에 불과합니다. 핸드도어 베인 연구는 (두 변형 모두, CNN은 기능 추출기로서, CNN 미세 조정) 사전 교육(ImageNet 데이터 세트 [21])을 통해) Transfer Learning 솔루션을 공개합니다. AlexNet, VGG16 및 VGG19 아키텍처입니다. Kuzu [22]는 사전 훈련된 DenseNet161 아키텍처를 통해 [23]의 Rosebrock에 의해 명확하게 정의된 미세 조정(TL) 기술과 유사한 기능을 제공합니다.
TL 개념은 "다른 교육 패러다임을 제안"[23]하며 특히 섹션 II에서 본 연구에서 자세히 설명되고 논의됩니다.
마지막으로, 최첨단 분석을 마무리하기 위해 표 3은 기존의 손목 정맥 데이터베이스와 그 주요 특징을 나타냅니다. 생체 인식 성능을 비교하기 위해 나머지 VBR 양식을 고려하지 않고 기존 손목 데이터 세트만 표시하고 분석합니다.
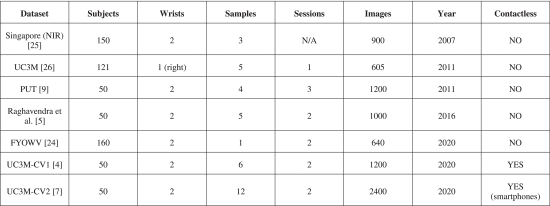
알려진 바로는 PUT [9] 및 FYO [24](FYOWV 부분)만이 현존하는 공개 데이터 세트입니다. 싱가포르[25]와 UC3M[26]은 각각 2007년과 2011년에 수집되었으며, [5], UC3M-CV1[4] 및 UC3M-CV2[7]는 현재 비공개 데이터 세트입니다.
표 3은 2020년 최신 데이터베이스인 UC3M-CV1[4] 및 UC3M-CV2[7]에만 비접촉식 이미지가 포함되어 있음을 암시합니다.
2011년에 PUT 데이터 세트가 수집되었기 때문에 이전 데이터 세트를 고려할 때 클래스당 이미지 수(고유 손목 사용자)는 허용되지만 로즈브록의 [23]에서 설명한 클래스당 1000-5000개의 예제를 적용하는 일반적인 DL 규칙은 매우 작습니다. UC3M-CV2에는 고유 손목 사용자 이미지 수가 가장 많은 24개 샘플(6개 샘플 ×2개 세션 = 24개 이미지)과 총 2400개 이미지(50개 피험자 ×2개 손목 ×6개 샘플 = 2400개 이미지)가 포함되어 있습니다. DL 솔루션의 제한된 교육 데이터(클래스당 샘플)는 클래스 간 기능이 매우 유사하여 구별하기 어렵기 때문에 모든 VBR 변형에서 가장 어렵고 지속적인 문제를 가정하고 있습니다. 이런 점에서, 이 문제는 다음 섹션에서 분석되며, 제안된 인식 전송 학습 CNN 알고리즘은 UC3M-CV2 데이터 세트뿐만 아니라 UC3M-CV1 및 PUT에도 적용되었습니다.
전이학습
TL은 사전 훈련된 신경 네트워크 모델을 출발점으로 삼는 딥러닝 기술입니다. 그런 다음 사전 학습된 NN은 사전 학습에 사용된 데이터와 완전히 다를 수 있는 관심 데이터를 사용하여 수정 및 훈련됩니다.
CNN의 경우 TL을 적용하는 두 가지 방법이 있습니다.
- CNN으로 특징을 추출
- Fine-tuning
CNN을 특징추출기로 사용
이 TL 변형은 이미지에서 고유한 특징을 얻기 위해 CNN 아키텍처의 가장 얕은 계층에서 사전 훈련된 가중치를 사용하는 데 의존합니다. 그런 다음 이미지를 정확하게 분류/인식하기 위해 기존의 기계 학습 알고리즘이 이러한 기능에 적용됩니다. 120만 개 이상의 이미지를 가진 1000개의 오브젝트 클래스로 구성된 ImageNet과 같은 대규모 데이터 세트를 사용한 사전 교육은 컴퓨터 비전 세계에서 우수한 결과를 얻어 이 TL 기술의 생존 가능성을 입증했습니다.
이러한 방식으로 "기능 추출 + 기능 비교"라는 기존의 생체 인식 체계는 CNN을 엔드 투 엔드 이미지 분류기로 사용하는 DL 손상 전과 동일하게 유지됩니다.
그림 2는 기능 추출기로서의 CNN과 엔드 투 엔드 분류기로서의 CNN의 비교를 보여줍니다. 표시된 CNN 아키텍처는 VGG16으로, 본 연구에서 연구된 구조 중 하나입니다.
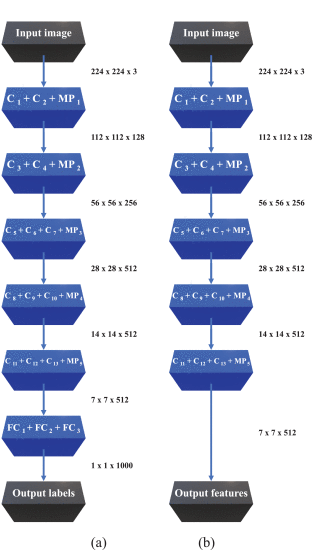
Transfer learning using the VGG16 network architecture as feature extractor: (a) Original VGG16 end-to-end image classifier with the 1000 ImageNet output class labels. (b) VGG16 as feature extractor (7 × 7 ×512=25088 unique features).
The VGG16 original architecture (Fig. 2 a) consists of:
- 2 blocks of 2 convolutional layers (3×3 ) +1 max pooling layer (C1 + C2 + MP1 and C3 + C4 + MP2).
- 3 blocks of 3 convolutional layers (3×3 ) +1 max pooling layer (C5 + C6 + C7 + MP3, C8 + C9 + C10 + MP4 and C11 + C12 + C13 + MP5).
- 3 fully-connected layers (FC1 + FC2 + FC3).
CNN 기능 추출기로서의 VGG16 네트워크(그림 2 b)는 동일한 구조를 따르지만 완전히 연결된 마지막 3개 레이어 전에 전파가 중지되어 각 클래스 레이블에 대한 확률 대신 7×7×1200=25088의 고유한 특징을 얻습니다. ImageNet과 같은 대규모 데이터 세트에서 이 CNN 아키텍처를 사전 교육할 때 이전에 얻은 가중치를 직접 사용하여 원하는 데이터 세트의 이미지 기능을 추출합니다. 그런 다음 인식 모델을 완성하는 전통적인 기계 학습 알고리즘으로 분류됩니다.
Fine-tuning
CNN을 기능 추출기로 사용하는 대신 TL 방법으로 미세 조정하면 CNN을 엔드 투 엔드 분류기로 유지할 수 있습니다. 이를 위해 사전 학습된 CNN을 수정하고(네트워크의 한 층 또는 "헤드") 원하는 이미지를 사용하여 파트별로 다시 학습합니다.
이 기법을 구현하기 위해 보통 다음 단계를 따릅니다.
- 완전히 연결된 최종 레이어("네트워크의 헤드")를 단순화된 다른 완전히 연결된 레이어로 교체합니다. 이러한 새 계층은 임의로 초기화됩니다(새 네트워크의 다른 계층과 마찬가지로). 그림 3에 표시된 VGG16 네트워크의 경우 이전 레이어인 최대 폴링 MP5는 형상 추출기의 출력으로 처리됩니다.
- 이전에 학습한 풍부한 기능 필터를 파괴하지 않기 위해 이러한 레이어를 통해 역 전파하는 것이 아니라 이전 레이어(이하 "본체")의 매개변수를 "동결"시킴으로써 새로운 아키텍처를 교육합니다. 완전히 연결된 새로운 계층은 임의로 초기화되므로 이 단계에서 네트워크의 이 부분이 "멍청이" 됩니다.
- 네트워크 "헤드"가 관심 데이터 세트의 패턴을 학습하기 시작한 후, 교육은 일시 중지되고, "본체"는 전체 네트워크 역방향 전파를 허용하도록 동결되지 않으며, 학습 속도가 저하된 상태로 훈련을 재개합니다(일반적으로 사전 훈련된 컨볼루션 필터를 극적으로 수정하는 것은 바람직하지 않음). 더 높은 정확도로 필요합니다.
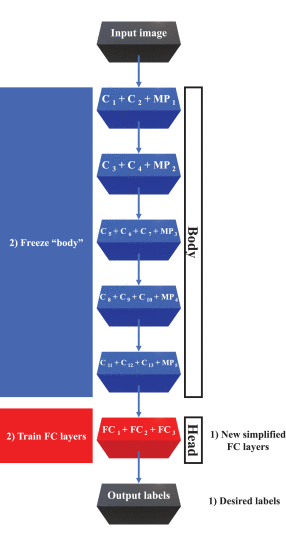
VGG16 아키텍처에 대한 미세 조정 프로세스를 사용한 전이 학습, 1단계 및 2단계: 새로운 단순화된 FC 레이어를 추가하고 CNN "본문" 훈련을 고정하여 새로운 FC 레이어만 학습합니다.
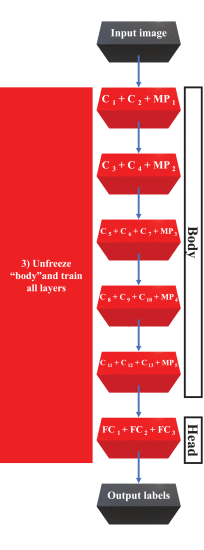
VGG16 아키텍처에 대한 미세 조정 프로세스를 사용한 전이 학습, 3단계: 전체 아키텍처를 훈련하는 CNN "본체" 고정 해제.
손목 생체 인식 시스템
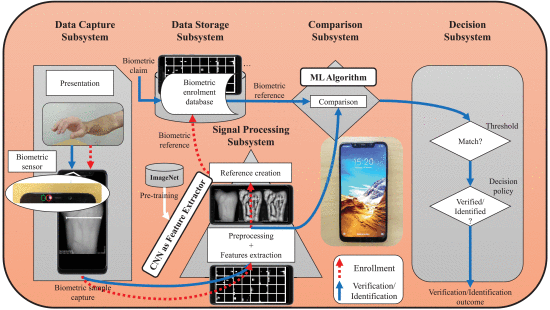
그림 5는 전송 학습 모델을 스마트폰에 완전히 내장하고 ISO/IEC 19795-1 표준을 따르는 구현된 DL 시스템을 보여줍니다[8]. 5개의 하위 시스템으로 나뉩니다.
- 데이터 캡처 하위 시스템 : 검증/식별 작업의 첫 번째 단계는 생체 샘플을 제시하고 캡처하는 것입니다. 손목 혈관 프레젠테이션은 생체인식 센서인 근적외선 카메라와 근적외선을 사용하여 획득되며, 두 가지 모두 원래 얼굴 인식을 위해 스마트폰에 통합되어 있습니다. [7]에 제시된 캡처 및 안내 알고리즘 소프트웨어 TGS-CVBR®가 이 작업을 담당합니다.
- 신호 처리 하위 시스템 : 캡처된 이미지는 사전 처리되거나 처리되지 않으며(두 경우 모두 테스트됨) 설계된 TL 모델은 4개의 서로 다른 CNN 구조를 사용하여 고유한 식별 기능을 획득합니다. 그림 5는 ImageNet 데이터 세트로 사전 훈련된 기능 추출기로 CNN을 보여줍니다.
- 데이터 스토리지 서브시스템 : 시스템이 등록 모드에서 작동하는 경우 기능은 스마트폰의 내장 메모리인 데이터 스토리지 하위 시스템에 저장됩니다.
- 비교 서브 시스템 : 앞서 설명한 바와 같이, 이 TL 솔루션을 적용한 후에는 기계 학습 알고리즘이 기능 비교를 담당합니다. 처음부터 훈련된 CNN의 경우 이 블록은 네트워크의 일부입니다(완전히 연결된 계층).
- 의사 결정 하위 시스템 : 이전 하위 시스템에서 얻은 값에 따라 확인/식별이 수행됩니다.
Feature Extraction: Deep CNN Transfer Learning
CNN 아키텍처는 VGG16, VGG19, ResNet50 및 ResNet152의 고유한 기능을 추출하고 TL 모델을 만들기 위해 독립적으로 수행되었습니다. 모든 가중치 값이 ImagenNet 데이터 세트의 사전 학습 네트워크에서 엉켜 있습니다. 네트워크의 "헤드"인 섹션 II-A에서 설명한 바와 같이 VGG16 및 VGG19의 최종 완전 연결 계층 3개와 ResNet50의 최종 완전 연결 계층이 제거되었습니다.
1) VGG16
그림 8 a와 표 4는 네트워크 아키텍처를 보여주고 그림 8 b는 각 계층에 대한 출력 기능 맵을 보여줍니다. 앞에서 언급하고 보여 주었듯이, VGG 제품군 아키텍처는 볼륨 크기를 줄이기 위해 최대 풀링 레이어로 끝나는 연속적인 3×3 컨볼루션 + 활성화(ReLU) 레이어 블록을 기반으로 합니다.
VGG16 Architecture for TL
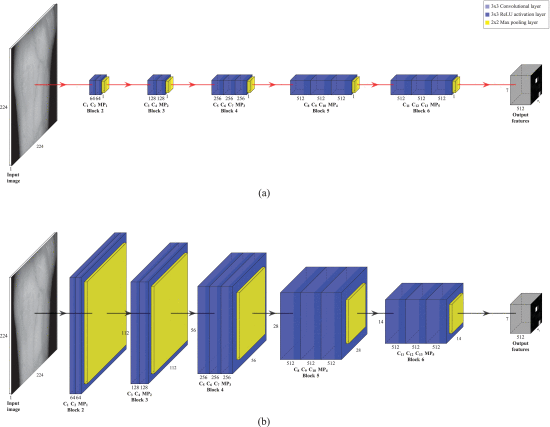
Original VGG16 architecture applied for TL. (a) VGG16 architecture as a feature extractor. (b) Output feature map for each layer of VGG16 as a feature extractor.
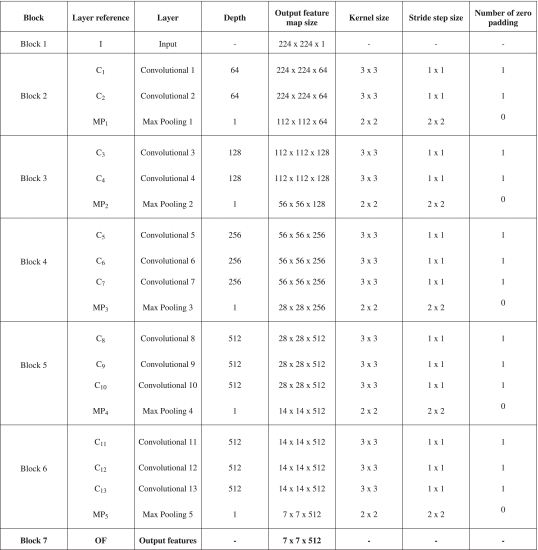
고유한 이미지 기능(및 원본)을 추출하기 위해 제안된 VGG16 구조는 다음과 같은 7개의 레이어 블록으로 구성됩니다.
- 블록 1(I 레이어) : 이것은 정사각형 그레이스케일(단 하나의 채널) 이미지가 도입되는 입력 레이어입니다. 입력 영상의 크기는 224×224이므로 테스트한 정맥 데이터 세트의 영상이 가장 가까운 이웃 보간법을 사용하여 원래 가로 세로 비율을 유지하는 필요한 정사각형 크기로 축소되었습니다.
- 블록 2 (C1 + C2 + MP1): 이 아키텍처에서 학습된 모든 컨볼루션 계층인 C1 및 C2 계층은 3×3 필터에 이어 ReLU 활성화 계층입니다. 이 잘 알려진 비선형 함수는 방정식 (4)로 설명됩니다.
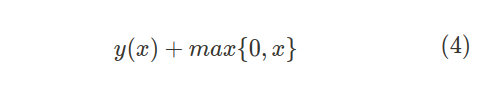
이러한 각 레이어 C1 및 C2는 스트라이드(컨볼루션 매트릭스의 각 이동 사이의 픽셀 단계)가 1인 64개의 필터(깊이)와 원래 입력 볼륨 크기를 유지하기 위해 제로 패딩(추가 매트릭스 테두리를 0으로 채우기)으로 구성됩니다. 최대 풀링 레이어 MP1은 2×2 커널과 스트라이드 2로 입력 볼륨의 공간 크기(즉, 폭과 높이)를 줄여 다음과 같은 출력 기능 맵 볼륨 크기를 얻습니다.
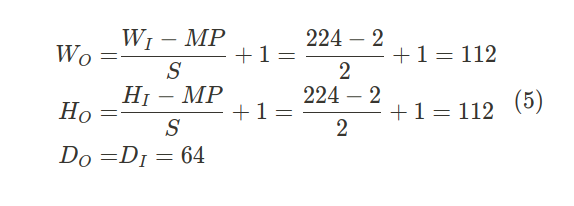
- and : weight of the input and output volume.
- and : height of the input and output volume.
- and : depth of the input and output volume.
- MP: size of the max polling filter because it has a square shape.
- S: stride
- 블록 3(C3 + C4 z MP2) : 이 블록은 이전 블록과 동일하지만 이 경우 컨볼루션 레이어의 깊이는 128입니다. 최대 풀링 계층인 MP2는 56 × 56 × 128 출력 피처 맵을 얻는 것과 같은 방식으로 출력 볼륨을 줄입니다.
- 블록 4(C5 + C6 + C7 + MP3) : 이 블록에는 컨볼루션 레이어가 추가됩니다. 3개의 컨볼루션 층의 깊이는 256입니다. 최대 풀링 계층인 MP3는 동일한 방식으로 출력 볼륨을 줄여 28×28×256 출력 기능 맵을 얻습니다.
- 블록 5(C8 + C9 + C10 + MP4) : 이 블록은 이전 블록과 동일하지만 이 경우 컨볼루션 레이어의 깊이는 512입니다. 최대 풀링 계층인 MP4는 14×14×512 출력 피처 맵을 획득하여 동일한 방식으로 출력 볼륨을 줄입니다.
- 블록 6(C11 + C12 + C13 + MP5) : 이 블록에는 컨볼루션 레이어가 추가됩니다. 3개의 컨볼루션 층의 깊이는 256입니다. 최대 풀링 계층인 MP5는 동일한 방식으로 출력 볼륨을 줄여 최종 7×7×512 출력 기능을 얻습니다.
- 블록 7(OF 레이어) : 출력 기능 계층입니다. ImageNet 데이터 세트와 함께 사전 훈련된 CNN을 기능 추출기로 사용하기 위해 언급한 바와 같이, 이 아키텍처의 완전히 연결된 계층은 생략됩니다. CNN은 사전 교육된 네트워크를 통과하는 각 데이터 세트 이미지에 대해 7×7×128=25.088의 고유한 기능을 제공합니다. 예를 들어 UC3M-CV2 데이터 세트의 경우 얻은 기능은 방정식 (6)을 따릅니다.

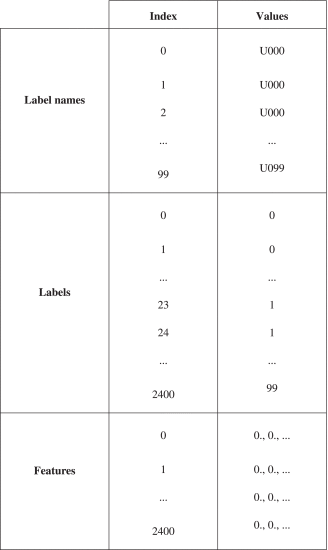
대량의 output feature은 쉽게 액세스할 수 있도록 HDF5® 파일(계층적 데이터 형식 버전 5)[31]에 이진 형식으로 저장됩니다. 파일은 세 개의 하위 데이터 세트로 다이빙됩니다.
- 레이블 이름: 스터디 데이터 세트의 기존 이미지 클래스 레이블 이름입니다. UC3M-CV2에서는 U000(사용자 0), U001(사용자 1), U002(사용자 2), U099(사용자 99)를 사용합니다.
- 레이블 : 각 클래스와 연결되고 모든 데이터 세트 이미지에 해당하는 정수입니다. UC3M-CV2에는 0이 24개(사용자 0, 24개 샘플), 1이 24개(사용자 1, 24개 샘플), 2가 24개(사용자 2, 24개 샘플), 90나인 24개(사용자 99, 24개 샘플)가 있습니다.
- 기능 : 각 이미지에 대해 추출된 피쳐입니다.
표 5에는 UC3M-CV2용 HDF5 파일 구조가 요약되어 있습니다.
기능 추출기로 사전 훈련된 이 아키텍처는 파이썬 3.7.9 프로그래밍 언어, 텐서플로우© 2.0(2.3.0 버전) 오픈 소스 라이브러리 및 해당 Keras©(1.1.2 버전) API를 사용하여 구현되었습니다.
이 프로세싱은 Windows 10이 설치된 Dell© Alienware Oura R8 컴퓨터의 NVIDIA® GeForce® RTX 2080Ti(11GB GDDR6 메모리) GPU와 9세대 Intel® Core i9k(64비트, 16GB RAM, 3.6GHz) CPU를 사용하여 수행되었습니다.
Cuda® 병렬 컴퓨팅 플랫폼(버전 11.1)은 컴퓨팅 병렬화를 위해 CPU-GPU 통신을 광범위하게 수행해 왔습니다.
다음 세션(섹션 III-D)에서 설명될 TL 모델 전체가 스마트폰에 통합되어 TensorFlow© Lite 라이브러리 및 안드로이드 프로그래밍 언어를 사용하여 실시간 확인/식별을 할 수 있습니다.
2) VGG19
잘 알려진 이 VGG 아키텍처는 이전 아키텍처와 유사하지만 이 경우 최종 컨볼루션 블록 3개는 3개가 아닌 4개의 컨볼루션 레이어로 구성됩니다. 또한 완전히 연결된 3개의 최종 레이어가 제거되어 7×7×128=25.088의 고유 기능이 추출됩니다.
3) ResNet50
He 등이 2015년 작업인 이미지 인식을 위한 심층 잔차 학습[32]에서 소개한 이 아키텍처는 VGG 제품군 아키텍처보다 상당히 깊으며, 깊이가 50-100 계층 이상인 네트워크를 교육할 수 있습니다. ResNet CNN은 잔여 모듈 미세 구조에 의존합니다. 그림 9는 가장 일반적인 잔여 모듈인 병목 현상을 보여줍니다.
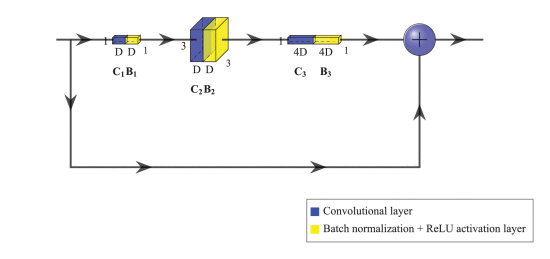
ResNet 모듈, Bottleneck : 제안된 TL 구성과 가장 일반적인 Residual 모듈에 적용되는 Residual 미세 구조입니다. 마지막 ReLU 활성화 계층은 추가 작업 후에 수행됩니다.
보시다시피 Residual Bottleneck 모델은 3개의 컨볼루션 레이어와 배치 정규화 레이어 및 ReLU 활성화 레이어로 구성됩니다. 출력은 "skip-connection"를 통해 추가 노드의 블록 입력(identity 또는 residual input)에 추가됩니다. 기존 레이어를 방정식(7)으로 정의하면 다음과 같습니다.
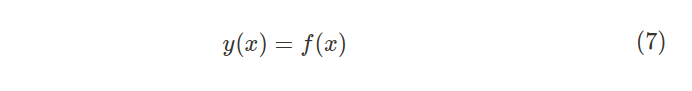
Residual 모듈은 (8)로 나타낼 수 있습니다.
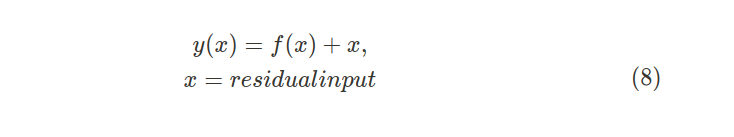
3개의 컨볼루션 레이어의 크기는 각각 1×1, 3×3, 1×1이며, 깊이는 D = DC 1= DC 2= DC3 / 4입니다. 이러한 볼륨 깊이 증가 때문에 이 모듈을 "병목"이라고 합니다. ResNet50 아키텍처(그림 10)는 4개의 다른 단계 또는 잔여 모듈(블록 3, 4, 5, 6)로 구성됩니다. 다음 단계의 입력 또는 아이덴티티인 각 잔여 단계의 출력은 그림 10과 같이 DC 3=DC4의 또 다른 1×1 컨볼루션 레이어(+1×1 배치 정규화 레이어)를 통과하고 스트라이드 2를 통과하여 볼륨 크기를 줄입니다. 이 비식별성 바로 가기는 단계 간에만 적용됩니다. ResNet50 버전 1은 사전 활성화(버전 2) 대신 사후 활성화를 제공하는 구현 아키텍처입니다. 즉, 병목 현상의 컨볼루션 레이어 뒤에 배치 정규화 및 ReLU 활성화 레이어가 적용됩니다.
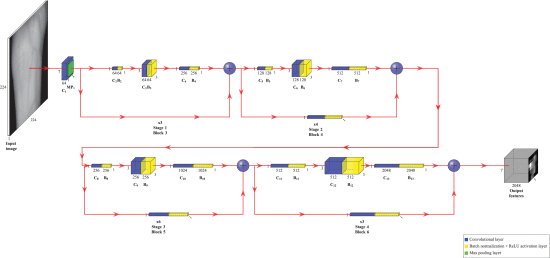
TL에는 원래 단순화된 ResNet50 아키텍처가 적용되었습니다.
VGG 계열과 대조적으로 이 아키텍처가 feature map의 weight, height를 줄이기 위해 풀링 레이어를 사용하지 않고 strides > 2를 적용하는 자체 컨볼루션 레이어를 사용한다는 것을 나타내는 것이 매우 중요합니다(첫 번째 단계의 레이어는 제외).그렇기 때문에 ResNet 네트워크에는 MP(최대 풀링)와 AP(평균 풀링)라는 두 개의 풀링 계층만 있습니다. CNN 상단 또는 헤드(FC + AP 레이어)가 TL을 적용하고 7×7×2048 feature output 볼륨을 얻기 위해 제거되었기 때문에 평균 풀링 레이어는 그림 10에 나와 있지 않습니다.
표 6에서 보듯이 이 아키텍처는 7개의 블록으로 구성됩니다. 첫 번째는 224×224 입력 계층(I)입니다. 이전에 크기가 조정된 정맥 데이터 세트 이미지(640×480~224×224 또는 1024×768~224×224)가 입력됩니다. 블록 2는 하나의 컨볼루션 레이어(C1)와 하나의 최대 풀링(MP)으로 구성됩니다. 스트라이드가 2인 두 블록 모두 112×112로 피처맵 출력을 줄입니다. 블록 3, 4, 5, 6(4단계)은 각각 3, 4, 6, 3개의 잔여 블록(C2 + C3 C4 + C13 + C12)으로 구성됩니다.
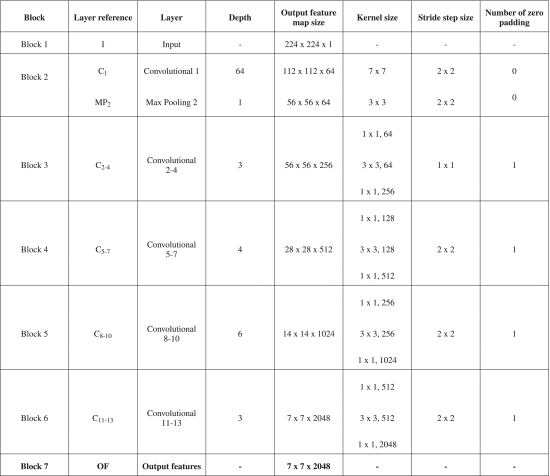
ResNet50 (버전 1) 아키텍처가 TL에 적용되었습니다.
마지막으로, 블록 7은 완전히 연결된 계층 누락으로 인해 제안된 ImageNet TL ResNet50 (버전 1) 네트워크에서 7×7×2048=100.352의 고유한 기능을 얻는 출력 계층입니다. 예를 들어 UC3M-CV2 데이터 세트의 경우 얻은 기능은 방정식 (9)을 따릅니다.

4) ResNet152
ResNet 계열에 속하는 아키텍처인 ResNet152(버전 1)는 더 깊긴 하지만 ResNet50(버전 1)과 유사한 구조를 제공합니다. 그러나 이 경우 동일한 크기의 병목현상 잔존 모듈이 각각 3, 8, 36 및 3의 깊이로 반복되어 152개의 계층에 도달합니다. 이 공개된 ImageNet 사전 교육 ResNet152 네트워크를 기능 추출기로 사용하여 7×7×2048=100.352의 고유한 기능을 얻을 수 있습니다.
특징 비교 : 머신러닝 방법
CNN 사전 학습 아키텍처를 사용하여 각 혈관 이미지에 대해 고유한 특징을 추출한 후, 그림 11의 체계에 표시된 대로 검증/식별하기 위해 ML 알고리즘을 적용합니다. 이 그림에는 설계된 완성된 소프트웨어 TL 알고리즘 모델이 요약되어 있습니다. 첫째, 모델은 두 가지 경로(파란색 블록)로 시작합니다. 하나는 입력 이미지를 PIS-CVBR®로 사전 처리하여 224×244(사전 처리된 CNN의 경우 입력 사각 크기)로 크기를 조정하는 경로이고 두 번째 경로는 224×244로 크기를 조정하는 경로입니다. 두 가지 모두 실험 및 결과 섹션에서 비교됩니다.
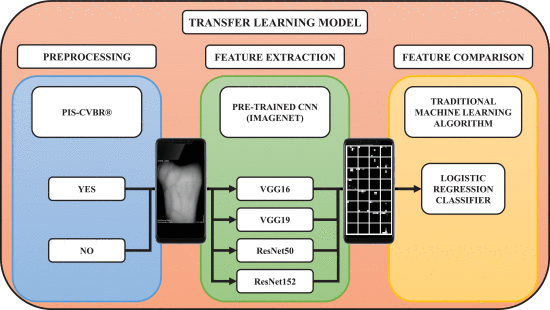
TL 제안 모델 : ImageNet 사전 교육 CNN(VGG16, VGG19, ResNet50 또는 ResNet152)은 기능 추출기로, 로지스틱 회귀 분류기는 기계 학습 기능 비교기로서 사용됩니다. 스마트폰 스크린샷은 VGG16 ImageNet 네트워크를 통과하는 하나의 원시 이미지에 대한 중간 단계를 보여줍니다. TL 기능 추출 프로세스의 처음 32개 기능 맵(7×7)이 표시됩니다.
그런 다음 크기가 조정된 이러한 이미지는 사전 훈련된 CNN 아키텍처 중 하나를 통과하고 고유한 기능을 추출합니다. 마지막으로, 이러한 특이점을 기존의 ML 알고리즘과 비교합니다.
적용된 전통적인 기계 학습 알고리즘은 Sigmoid 함수(10)에 의존하는 로지스틱 회귀 분석입니다.
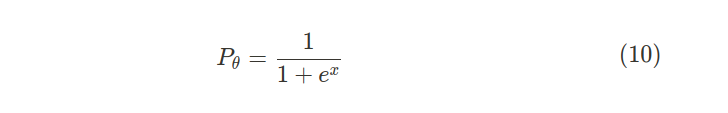
- Pθ : Prediction function, is the probability estimated (between 0 and 1).
- x: is the input function learned by the model.
각 사용자의 고유한 정맥 특징을 분리하기 위한 의사 결정 경계를 찾는 데 사용되는 해결사 또는 최적화 알고리즘은 대규모 경계 제한 최적화 소프트웨어(L-BFGS-B)[33]입니다. 수렴에 소요되는 최대 반복 횟수는 1000회이며 오류를 평가하기 위해 적용되는 비용 함수는 교차 엔트로피 손실입니다.
다양한 이미지 정맥 특징 벡터는 다음과 같은 열차 테스트 백분율로 분할되었습니다. 예를 들어 UC3M-CV2 데이터 세트에서 이 백분율은 훈련을 위한 1800개의 이미지와 테스트를 위한 600개의 이미지(각 사용자 클래스 18-6개의 이미지), 1200개의 교육 이미지 및 1200개의 테스트 이미지(각 사용자 클래스 12-12개의 이미지)를 나타냅니다. 또한 결과 섹션에서 언급했듯이, 본 연구에서는 50-50% 비율이 생체 인식 솔루션에 적용되어야 하는 최소 제한값으로 간주되고 있습니다.
실제 애플리케이션 시스템의 개념 증명을 얻기 위한 시도로, 전체 모델은 TensorFlow© Lite (0.0.0-186 버전) 라이브러리 프레임워크와 개발된 안드로이드 애플리케이션을 통해 스마트폰에서 실행됩니다. 이 모델은 TensorFlow© 2.0(2.3.0 버전) 오픈 소스 라이브러리, Keras©(1.1.2 버전) API 및 앞서 설명한 처리 컴퓨터 장비(CPU + GPU)를 사용하여 교육 및 생성되었습니다. 고유 형상을 추출하고 로지스틱 회귀 분석 분류기를 교육한 후 모델은 이진 HDF5 파일로 저장된 다음 TensorFlow©Lite를 사용하여 이진 TFLITE 파일로 변환됩니다. 이 프레임워크를 통해 제안된 스마트폰처럼 임베디드 장치에서 DL 모델을 실시간으로 해석할 수 있습니다.
섹션 IV-B에서는 이러한 실시간 처리 비디오 테스트의 계산 시간을 수집합니다.
