[AI스쿨 7기, 12주차] 튤립 분류, 이미지 사이즈, padding valid, same, 접돌땡, Flip, Rotation, RandomZoom, 말라리아 데이터, wget, cv2, imread, subset, Datagen
멋쟁이사자처럼
221206 멋쟁이 사자처럼 AI스쿨 7기, 박조은 강사님 강의
✅ 복습
❓ relu를 통과한 피처맵을 무엇이라 부를까?
◼ 액티베이션맵
❓ MaxPooling 을 하게 되면 어떻게 될까?
◼ "Max, Average, Min 등 방법이 있는데, 보통 MaxPooling 을 주로 사용. 흑백이미지에서는 MinPooling 을 사용하기도 한다.
MaxPooling 은 가장 큰 값을 반환,
AveragePooling 은 평균 값 반환,
MinPooling 은 최솟값 반환
Pooling => 이미지 크기를 줄여 계산을 효율적으로 하고 데이터를 압축하는 효과가 있기 때문에 오버피팅을 방지해 주기도 합니다. 이미지를 추상화 해주기 때문에 너무 자세히 학습하지 않도록해서 오버피팅이 방지되게 됩니다."
❓ 마지막에 softmax 는 어떻게 결과를 처리할까?
◼ 멀티클래스 분류에 주로 사용하고, 가장 큰 확률값을 클래스의 답으로 사용한다. 합이 1
❓ 가장 큰 확률값을 찾는 방법은 무엇일까?
◼ np.argmax() 를 사용하면 가장 큰 확률값에 대한 인덱스를 반환한다. 가장 큰 값의 인덱스를 답으로 사용한다.
❓ binary 분류에는 출력 activation으로 무엇을 사용할까?
◼ 시그모이드. 0-1 사이의 확률값을 반환하며 임계값(보통 0.5) 기준으로 분류
✅ 이미지 분류 Classification
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] 를 분류
❓ 튤립 이미지를 미리 보기했는데 이 이미지를 학습했을 때 어떤 문제가 있을까?
◼ 이미지데이터를 분류할때도 전처리가 중요하다. 좋은 데이터를 넣어주어야 학습결과가 좋게 나온다.
데이터 세트 만들기
배열이 다른 값이 들어가면(==이미지 사이즈가 다 다르면) 계산을 할 수 없기 때문에, 높이와 너비를 고정
❓ 어떤 사이즈로 만들어주는게 좋을까?
◼ PIL, OpenCV 등을 내부에서 사용하고 있는데, 포토샵에서 이미지 사이즈를 줄이는 것처럼 이미지 사이즈를 조정해준다.
❓ 이미지 사이즈를 작게 만들면 어떤 결과가 나올까?
◼ 원래 이미지가 왜곡이 될 수도 있다. 하지만 크게 만들어도 같은 문제가 발생한다. 작은 사이즈를 늘리면 픽셀이 깨져보일 수 있다.
◼ 사이즈를 작게 하면 계산이 빠르다.
◼ 사이즈를 크게하면 오래 걸리지만 분류 모델이라면 정확도가 더 높아진다.
모델
- filters : 컨볼루션 필터의 수 == 특징맵 수
- kernel_size : 컨볼루션 커널의 (행, 열) => 필터 사이즈
- padding : 경계 처리 방법
- ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
시각화
❓ 시각화를 통해서 본 훈련결과를 어떻게 해석할 수 있을까?
◼ 과대적합
❓ 왜 과대적합이 되었을까?
◼ 한 가지 이유로 단정하기는 어렵지만 가장 성능이 안 좋게 나온 중점적인 이유를 찾는다면 이미지 전처리가 제대로 되어있지 않다. 노이즈 데이터가 많다.
데이터증강
훈련 과정에서 과대적합을 막는 여러 가지 방법들이 있습다. 이 튜토리얼에서는 데이터 증강을 사용하고 모델에 드롭아웃을 추가한다.
❓
tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom 이런 전처리 기능을 사용하면 이미지를 어떻게 변환할까?
◼ 접고 돌리고 땡기고
summary
1) 지금 실습은 TF 공식 예제의 이미지 분류 튜토리얼을 진행
2) 해당 튜토리얼은 꽃 5가지의 이미지를 학습하고 분류하는 예제
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] 5가지 꽃을 분류해 보는 예제
3) 이미지 데이터를 불러와서 train, valid set 을 나누어주었다.
4) 리소스를 효율적으로 사용하기 위해 캐시 사용하는 예제를 보았다.
5) 0-1 사이로 정규화하는 예제를 봤다. Rescaling 레이어에 추가해 줄 수도 있다.
6) 기본 레이어로 학습했더니 성능이 안좋게 나왔다. : 이미지에 노이즈가 너무 많았다.
7) 훈련 과정에서 과대적합을 막는 여러 가지 방법들이 있다. 이 튜토리얼에서는 데이터 증강을 사용하고 모델에 드롭아웃을 추가한다.
8) tf.keras.layers.RandomFlip, tf.keras.layers.RandomRotation, tf.keras.layers.RandomZoom 이런 전처리 기능을 사용하면 데이터 증강기법을 통해 이미지를 다양하게 생성해서 학습을 진행할 수 있다.
9) 데이터 증강기법을 통해 오버피팅이 줄어든 것을 확인해 볼 수 있다.
MNIST(손글씨 이미지로 0~9 숫자), FMNIST(의류 10가지 이미지) 는 전처리가 잘 되어 있기 때문에 기본 모델로 만들어도 99% 까지의 Accuracy.
꽃 이미지에는 노이즈가 많기 때문에 Accuracy 가 데이터 증강, Dropout 을 했을 때 0.6대에서 0.7 정도로 정확도가 높아졌다.
✅ 1001 실습파일
방글라데시의 Chittagong Medical College Hospital에서 150명의 P. vivax 감염 환자와 50명의 감염되지 않은 환자로부터 Giemsa로 염색된 두꺼운 혈액 도말 슬라이드를 수집하여 촬영했습니다. 350명의 말라리아 환자 데이터 세트를 기반으로 환자를 감염되지 않은 환자, P. vivax 감염 또는 P. falciparum 감염으로 진단하기 위해 PlasmodiumVF-Net을 제안했습니다. 이 데이터는 간행물과 함께 게시되었습니다.
도메인 정보 : https://blog.naver.com/hyouncho2/60137403047
이미지 로드
1) matplotlib.pyplot imread()
2) PIL(Pillow) 로 접고, 돌리고, 땡기고가 다 가능. TF 내부에서도 PIL 이나 OpenCV 를 사용해서 접고, 돌리고, 땡기고를 한다. => 이미지 편집기를 만들 수도 있다.
3) OpenCV 로 불러오는 방법(Computer Vision)에 주로 사용하는 도구로 동영상처리 등에 주로 사용한다.
✅ 1002 실습
1002 실습에서는 TF.Keras 의 전처리 기능을 사용하고,
1004 실습부터 다른 데이터셋으로 직접 이미지 배열을 만드는 실습을 할 예정
1002 번 파일 실습
=>(주제) 말라리아 혈액도말 이미지 분류 실습
=>(목적) TF 공식 문서의 이미지 분류를 다른 이미지를 사용해서 응용해보는 것
1) 이미지 데이터 불러오기 wget 을 사용하면 온라인 URL 에 있는 파일을 불러올 수 있다. 논문(혈액도말 이미지로 말라리아 감염여부를 판단하는 논문) 에 사용한 데이터셋을 불러왔다.
2) plt.imread 와 cv2(OpenCV) 의 imread 를 통해 array 형태로 데이터를 불러와서 시각화. 감염된 이미지와 아닌 이미지를 비교
3) tf.keras 의 전처리 도구를 사용해 train, valid set 을 나눠주었다. => 레이블 값을 폴더명으로 생성해 준다.
4) CNN 레이어를 구성, 컴파일하고 학습하고 정확도(Accuracy) 성능을 비교해 볼 예정
학습세트, 검증세트
- class_mode 에는 이진분류이기 때문에 binary 를 넣어줍니다. -> 감염되었다, 아니다 둘 중 하나
- class_mode: One of "categorical", "binary", "sparse", "input", or None. Default: "categorical".
- subset : Subset of data ('training' or 'validation')
- 클래스가 어떻게 나뉘었는지 보려면
trainDatagen.class_indices - validation 은 class_mode는 같게, subset은 validation으로 설정
- 클래스 나뉜거 확인하려면 valDatagen.class_indices
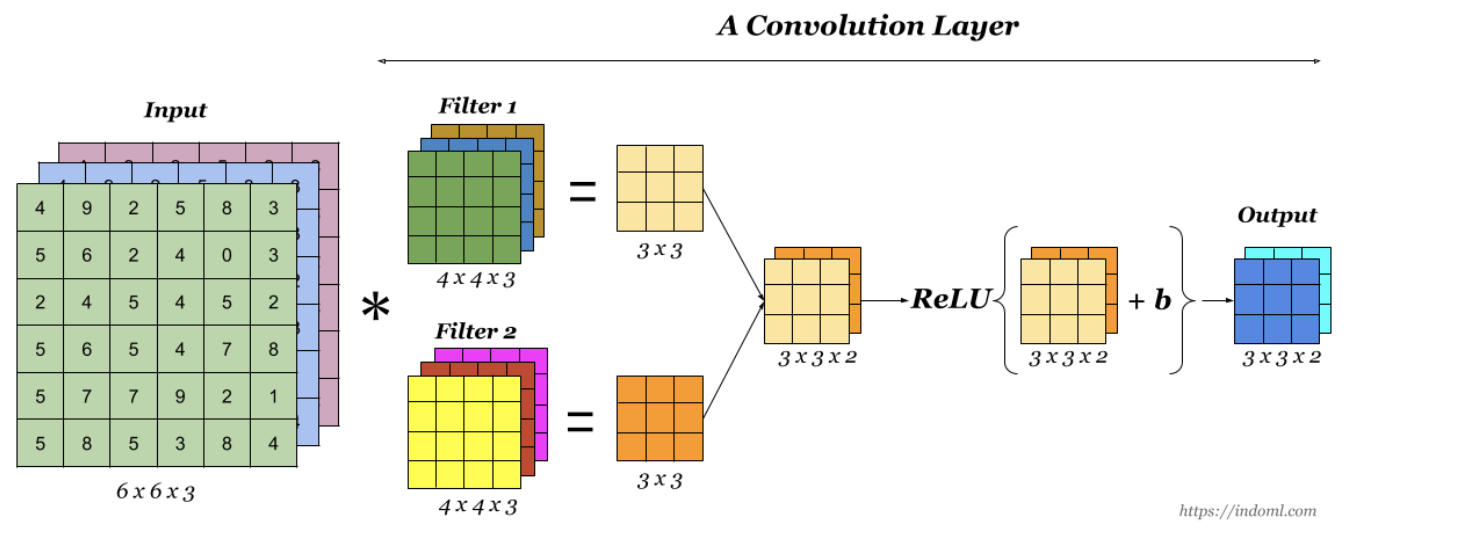
❓ 피처맵은 몇개?
◼ 2개
❓ 커널 사이즈는?
◼ (44) / output 사이즈는 33
레이어 설정
- padding : 경계 처리 방법
- ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
퀴즈
9/10문제
1. CNN의 기반을 구성(최초의 CNN)하였고 당시 MNIST Dataset을 기준으로 99.05% 정확도를 달성한 손글씨 인식을 위한 아키텍쳐는 무엇일까? LeNet
7.아래 코드를 실행했을 때 피처맵의 수는 몇 개가 나올까?
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3),
activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
- 32개
📌 책 추천
📚케라스 창시자에게 배우는 딥러닝 개정 2판 - YES24
=> 내용이 많고 초보자가 보기에는 조금 어려울 수도 있습니다.
📚핸즈온머신러닝 => 사이킷런과 TF를 다룹니다. 두껍고 자세합니다.
📚Introduction to Machine Learning with Python 사이킷런 개발자가 썼고 공식문서 기반입니다. 공식문서에 가장 가까운 책입니다.
📚파이썬 머신러닝 완벽가이드
📌 내가 답할 수 있는 질문은 뭐가 있을까?
