1. 데이터 선정
실습하면서 배웠던 의약품 중 한 종류를 선정할지, 새로운 데이터를 찾아서 연습해볼지(코시스 데이터셋을 사용할지, 다른 데이터셋을 찾아볼지) 고민을 많이 했다.
연습에 도전해볼만하면서 제주도 관광 특성을 알아볼 수 있을 것 같아 BC카드 사용 데이터를 분석해보기로 결정했다.
< 제주특별자치도_개별관광(FIT)_증가에_따른_제주_관광객_소비패턴_변화_분석_BC카드_빅데이터_내국인관광객_20170216 >
https://www.data.go.kr/data/15046091/fileData.do
2. 수도코드 작성
제주특별자치도 BC카드 사용 데이터 EDA분석 연습 (2014~2016)
1. 라이브러리 로드, 데이터 파일 불러오기
- 한글 폰트 사용
- glob, read_csv
2. 데이터 파악
- shape, info, describe
- sample, head, tail 통해 재확인
2. 전처리
- 결측치 확인(결측치 없음)
*nunique 는 어떤 컬럼을 할지 의논 필요
- 기준년월 : 년과 월을 나눈다. -> 년별, 월별 비교가 가능
- "데이터 기준 일자" 컬럼 제거
*관광객 유형은 외국인은 없나? 컬럼을 삭제할지, '관광객'이라는 단어를 전처리할지
*제주 대분류만 활용할지, 중분류만 활용할지?
3. 파생변수
- 전처리 한 년, 월 파생변수 생성
*연습삼아 성별인 (여, 남)을 (1,2)란 코드로 바꿔볼까
4. 기술통계 (수치 기술통계, 범주형 기술통계)
- describe
- corr / heatmap 상관관계 파악
5. 시각화(seaborn, pandas, plotly 라이브러리 당 3개 이상)
* 내국인, 외국인 비교 위해 정규화?
6. 결론3. 분석
3.1 라이브러리 로드
- pandas, numpy, matplotlib.pyplot, seaborn, plotly.express
- 한글 폰트 사용을 위해 koreanize_matplotlib
- glob를 import해 파일 경로 찾기
- pd.read_csv로 데이터셋 불러오기
encoding을 안하면 파일이 깨지기 때문에 꼭 넣어줘야 했다.
3.2 데이터 파악
- df.shape, df.info
- 이 때 바로
df.describe를 했었는데, 기술통계를 알아보면서 다시 하게 되니 여기서는 head, tail로 간단하게 체크했어도 되었을 것 같다. - "관광객 유형" 컬럼에서 내국인 관광객 말고 외국인 관광객도 있는지 확인 : 다시 생각해보니 BC카드 데이터기 때문에
외국인 데이터가 있기 힘들었다.
df.describe(include="object")
# 결과, 관광객 유형의 unique 값이 1개였다.
df[df["관광객 유형"]=="외국인 관광객"]
# 때문에 외국인 관광객을 찾아본 결과, 출력되는 데이터가 없었다.
# 관광객 유형 컬럼은 삭제해도 되겠다는 결론을 얻었다.3.3 전처리
결측치
- isnull().sum() : 결측치가 없다.
컬럼 제거
관광객 유형, 데이터기준일자 컬럼 제거
# 아래와 같은 방법으로 관광객 유형 컬럼을 전처리 가능하다.
# 하지만 필요 없는 컬럼이기 때문에 삭제한다.
# df["유형"] = df["관광객 유형"].str.replace("관광객", "").str.strip()
df = df.drop(columns=["데이터기준일자", "관광객 유형"])파생변수 만들기-연, 월
- 판다스의 datetime을 이용해 object 타입이던 "기준년월" 컬럼을 datetime 자료형으로 바꿈
하지만 포맷을 %Y-%m으로 지정해줬음에도 %Y-%m-%d형식으로 고정되어 출력이 되어 map과 split을 사용하여 파생변수를 생성했다.
import datetime
df["기준년월"]=pd.to_datetime(df["기준년월"], format="%Y-%m")
df["연"]=df["기준년월"].dt.year
df["월"]=df["기준년월"].dt.month- map과 lambda, split을 사용하여 파생변수 생성
df["연"]=df["기준년월"].map(lambda x : int(x.split("-")[0]))
df["월"]=df["기준년월"].map(lambda x: int(x.split("-")[1]))
# df["기준연월"].str.split("-", expand=True)[0].astype(int)- 성별 컬럼의 남, 여를 1, 2로 바꿔보는 연습
gender_dict={"남" : 1, "여" : 2}
df["gender"] = df["성별"].map(gender_dict)
# 성별 여, 남을 여자, 남자로 바꿔보는 연습
# df["gender_2"] = df["성별"].str.replace("여", "여자")
# df["gender_2"] = df["성별"].str.replace("남", "남자")
# df = df.drop(columns=["gender", "gender_2"])3.4 기술통계
- df.describe() / df.describe().T
- df.describe(include="object")
- 제주 중분류의 top 값인 연동과 관련하여 조건 찾기
# 연동에서 제일 많이 찾은 업종명 찾기
df.loc[df["제주 중분류"]=="연동", "업종명"].value_counts()- 업종명으로 그룹화, 카드이용금액이 상위 5개인 결과(팀원 코드)
df.groupby(by="업종명")["카드이용금액"].sum().sort_values(ascending=False).iloc[:5]- 카드 이용이 가장 큰 사람
분석 중 key 에러가 계속 발생하였다. 팀원들이 "카드이용내역", "카드이용건수"컬럼명에 공백이 있다는 것을 발견하여, 도움을 받았다.
# 컬럼명 확인
df.columns
# 공백 제거
df.columns = df.columns.str.replace(" ", "")
df.columns
# 카드이용금액이 가장 큰 사람의 카드이용건수 찾기
card_max = df.loc[df["카드이용금액"]==df["카드이용금액"].max(), "카드이용건수"]
df[df["카드이용건수"].isin(card_max)].sort_values(["카드이용건수", "카드이용금액"])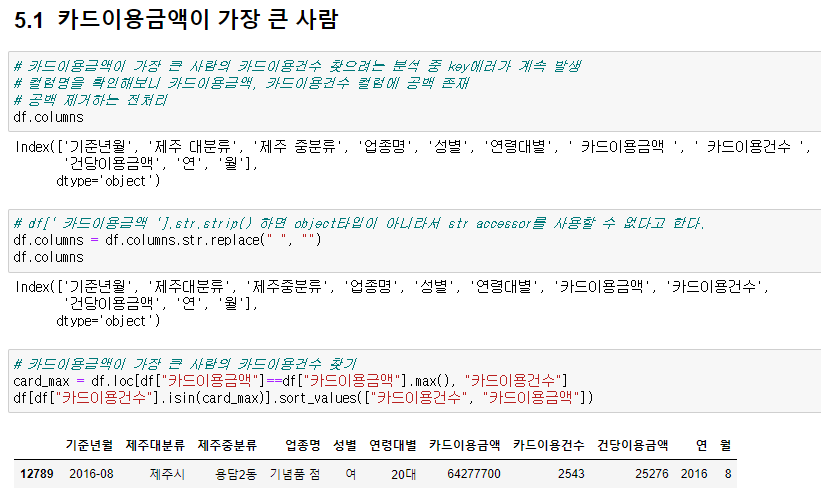
3.5 상관분석
- df.corr()
- 히트맵으로 그려서 확인
- 역시 카드이용건수와 카드 이용금액은
강한 양의 상관관계, 건당이용금액과 카드이용금액도 약간의 양의 상관관계
corr=df.corr()
mask=np.triu(np.ones_like(corr))
plt.figure(figsize=(10,5))
sns.heatmap(df.corr(), cmap="coolwarm", annot=True, vmax=1, mask=mask)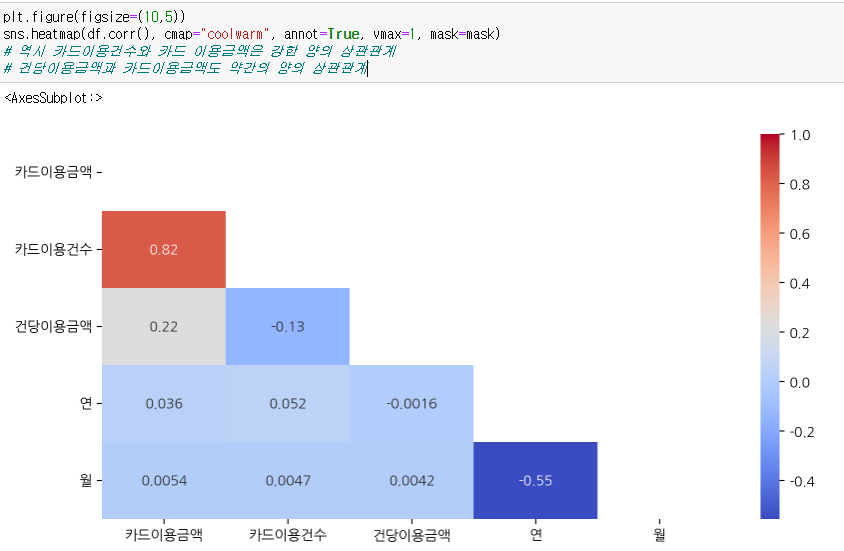
regplot으로 양의 상관 관계 확인
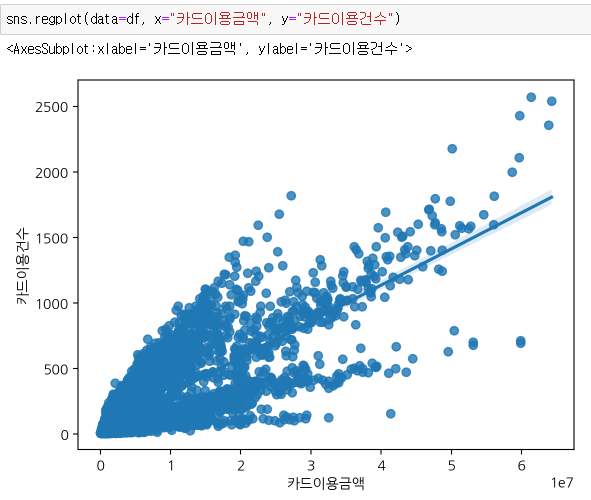
3.6 시각화
- df.hist(bins=20, figsize=(10,5));
- sns.pairplot(df, hue="제주중분류")
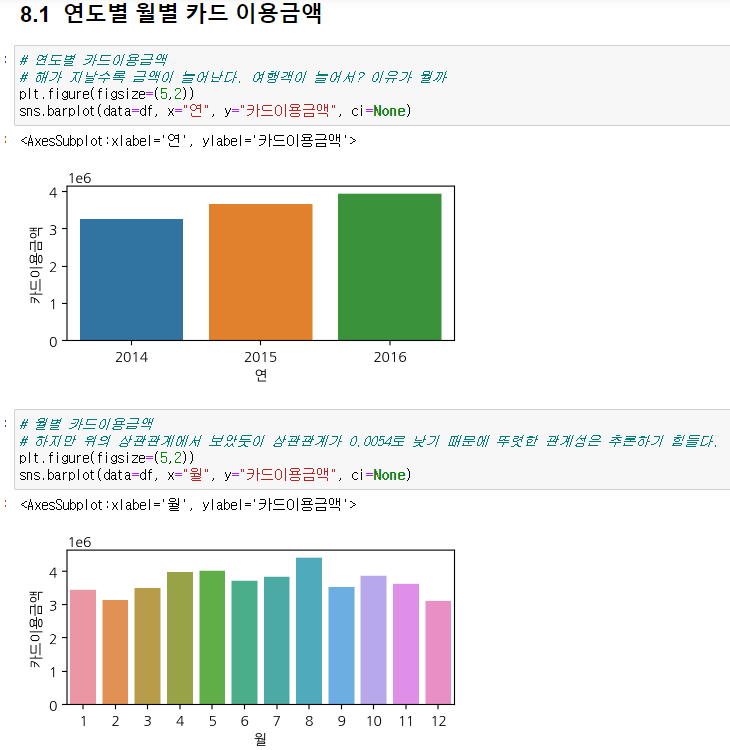
- 연도별, 월별 카드이용금액
2015년은 1~12월까지의 데이터이고 2016년은 1~8월까지의 데이터임에도 카드이용금액이 높다.
월별 카드 이용금액은 히트맵에서 그렸듯이 상관관계가 0.0054로 낮기 때문에 뚜렷한 관계성의 결론을 추론하기에는 힘들다.
그룹바이, 피봇테이블
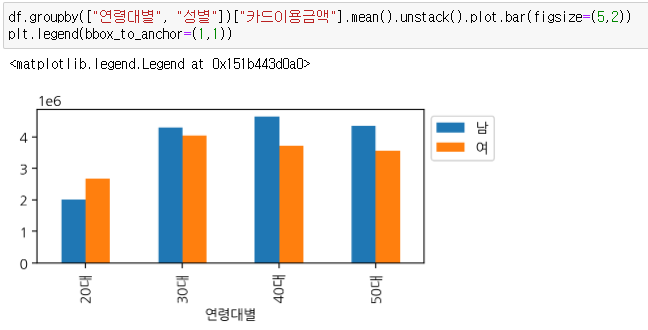
- 연령대별, 성별을 기준으로 카드이용금액을 시각화
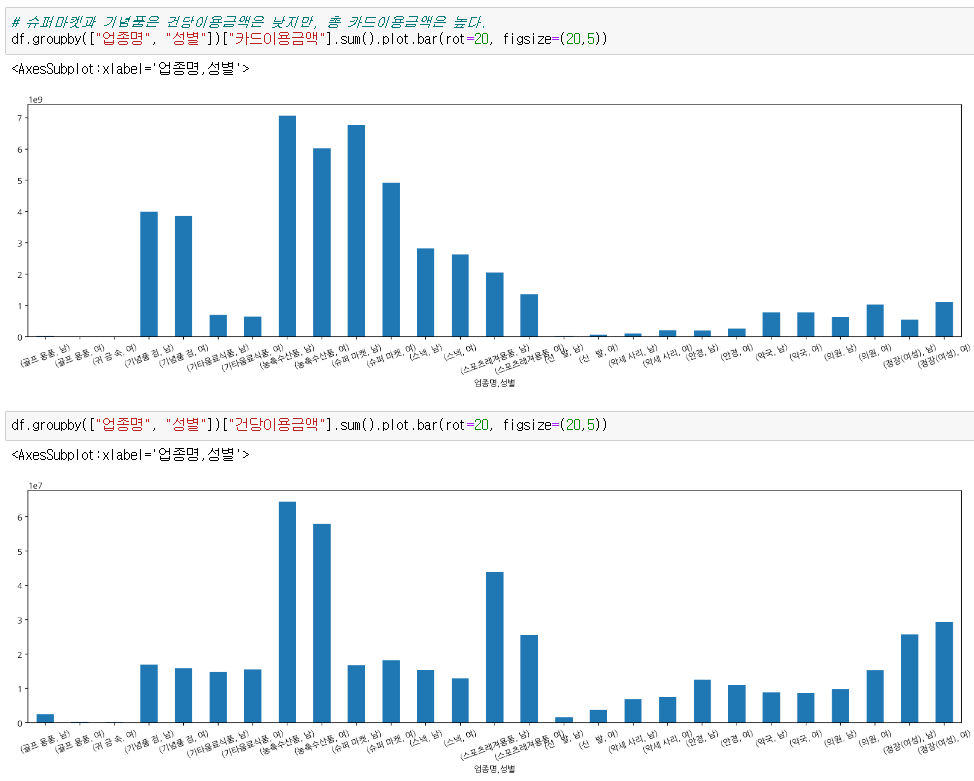
슈퍼마켓과 기념품은 건당이용금액은 낮지만, 총 카드이용금액은 높다.
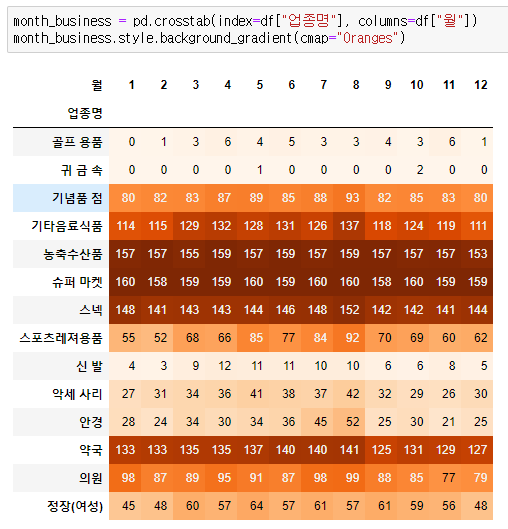
크로스탭
크로스탭으로 어떤 업종을 많이 이용했는지 볼 수 있다.
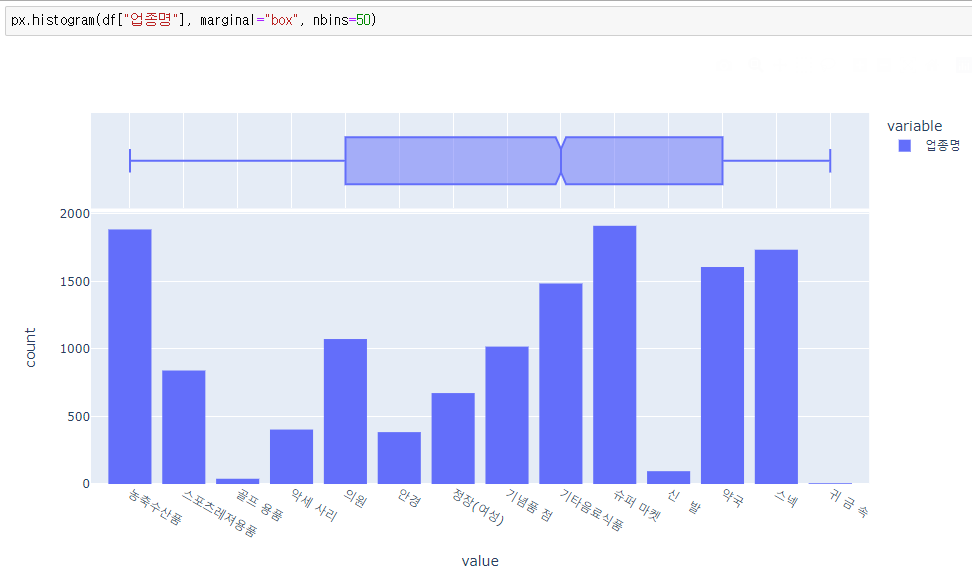
plotly
크로스탭에서 기념품, 기타음료식품, 농축수산품, 슈퍼마켓, 스넥, 약국 등이 높게 나오는 것을 볼 수 있다.
4. 느낀점
4.1 놓쳤지만 팀원들을 통해 배운 점
- 2014년 9월~ 2016년 8월까지의 데이터로 연도별 데이터 양이 다르다는 것을 보고 온전한 비교가 되지 않겠다고 배웠다.
- 컬럼명을 확인해보는 것을 놓쳤다가, key값 에러가 나서 뭐가 문제지 하면서 컬럼명을 그대로 복사 붙여넣기도 해보고 했었다. 공백이 있었다는 것을 듣고 전처리를 꼼꼼하게 해야겠다고 생각했다.
4.2 실패한 부분
- datetime을 이용해서 파생변수를 만드는 부분을 실패했다. 기준년-월로 구성되어 있기 때문에 format도 그렇게 바꿔주면 되는 줄 알았는데, 자동으로 day까지 추가가 되었다. 결국 replace를 사용했는데, 해결방법을 공부해보고 싶다.
4.3 어려웠던 부분
- 여전히 범주형, 수치형 데이터의 구분이 어렵다.
- seaborn 사이트의 relplot, displot, catplot 사진을 보면서 그래프를 그려보았지만, 결국에는 다 그려보고 실패하면 barplot으로만 그리게 되는 나의 모습을 발견했다.
- seaborn, pandas, plotly 마다 코드 형식이 조금씩 바뀌고, 넣어야 되는 축도 다양해서 hue에 뭘 넣을지, index와 column 또는 x와 y축에 어떤 것을 설정해줄지 등등 손에 익지 않아서 고민을 많이 했다.
4.4 아쉬운 점
조금 옛날 데이터라 와닿지 않았던 부분이 아쉽다.
(+BC카드 사용 데이터니까 관광객 유형에 내국인 관광객 밖에 없었구나! 외국인 데이터가 없을 수 밖에 없었다.)
+)노션 팀 자료 추가
팀이 이번 프로젝트에서 Pandas에 사용한 기능
- 라이브러리 로드 및 데이터 파일 불러오기
- Library Load : pandas, numpy, seaborn, matplotlib.pyplot, plotly.express
- 한글 폰트 설정 : koreanize_matplotlib
- 데이터 파일 불러오기 : glob(), read_csv()
- 데이터 파악
- 데이터 전체 정보 : shape, info()
- 데이터 미리보기 : head(), tail(), sample()
- 데이터 전처리
- 결측치 확인 : isnull()
- "연도", "월" 파생변수 생성 : split(), strip(), map()
- 불필요한 데이터 삭제 : drop()
* "데이터기준일자", ("기준년월"), "관광객 유형" column 삭제 - 컬럼명 "카드이용금액", "카드이용건수" 전 후 공백 제거
(+ "업종" column의 데이터 전처리 : replace(), regex) - 이용금액 Top 40 데이터 프레임 생성 : sort_values(), isin()
- 기술통계 (수치 기술통계, 범주형 기술통계)
- describe()
- 상관관계 파악 : corr(), sns.heatmap()
- 시각화를 통해 corr 관계 확인 : sns.regplot()
(+ 조건에 맞는 데이터 구하기
카드이용금액이 500만원 이상인 데이터의 성별
슈퍼마켓에서 연령대별로 사용한 건당이용금액의 평균
카드이용금액이 가장 큰 사람의 카드이용건수 등)
- 시각화
5.1 Seaborn
- barplot
- 연별 카드이용금액
- 월별 카드이용금액
- 연령대별 건당이용금액, 성별별로
- countplot
- 연별 횟수
- catplot
- 제주 중분류 별 카드이용금액을 나타낸 barplot을 업종명 별로 시각화
- 월별 카드이용금액을 나타낸 pointplot을 업종명별로 시각화
- 업종명별 카드이용건수를 violin plot으로 그리는 것은 적합하지 않다.
- pointplot
- 월별 카드이용금액 - regplot
- 카드이용금액, 카드이용건수
5.2 plotly
- histogram
- x=카드이용금액, y=업종명, facet_col=연령대별, color=성별, barmode=group - bar
- 제주 중분류 별 건당이용금액
- 업종명별 bax plot까지
5.3 pandas
- groupby
- 연령대별, 성별별 카드이용금액(barplot)
- 업종명, 성별별 건당이용금액의 합(barplot)
- 업종명, 성별별 카드이용금액의 합(barplot)
- 월, 제주 중분류 별 건당이용금액의 평균 - pivot table
- 연령대별, 성별별 건당이용금액 - crosstab
- 월별, 업종명별
- 월별, 제주중분류
분석 결론
- 2014년 9월~2016년 8월까지의 데이터 : 연도에 따른 데이터의 양이 다르기 때문에 연도별로 나눈 데이터 시각화는 신뢰성이 떨어진다.
- 카드이용건수와 카드이용금액은 강한 양의 상관관계를 가진다.
- 20대에 비해 30~50대의 카드이용금액이 높다.
- 기념품과 슈퍼마켓은 건당 이용금액은 낮지만, 총 카드이용금액은 높다.
- 제주 중분류 중 “제주시 연동”의 결제 건수가 가장 많다. 그 중에서도 슈퍼마켓이 이용 건수가 많은데, 제주공항과 가장 가까운 시내이기 때문에 방문객이 많았을 거라고 예상된다.
- 용담 2동에서의 기념품점 소비가 월등히 높다. 용담2동에 제주공항이 있기 때문이라고 생각된다.

아직 고쳐나가는 중.