김선비 Tensorflow 101 강의
Neural Network = 인공신경망 = Deep learning
라이브러리 : TensorFlow, PyTorch, Caffe2, theano
variable, 변수
- ex) X=1
- 표에서 컬럼은 변수. ex) 온도=20, 온도=21, 온도=22
- 원인이 되는 변수 : 독립변수 / 결과가 되는 변수 : 종속변수
epochs = 1000 : 1000번 반복 학습해라
loss : 학습이 얼마나 진행되었는지 알려준다.
- (예측-결과)^2
- 0에 가까워질수록 학습이 잘 된 모델
- 분류에 사용하는 loss는 crossentropy
- 회귀에 사용하는 loss는 mse
퍼셉트론, 가중치, b=편향
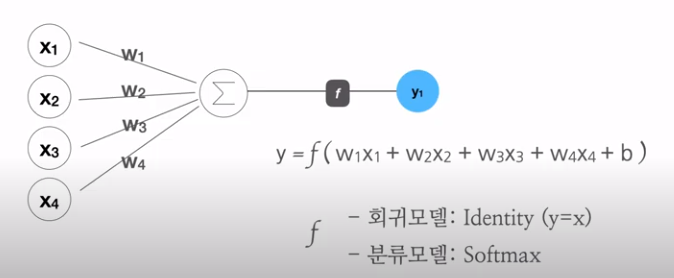
출처 : 봉수골 개발자 이선비 Tensorflow 유튜브 강의
분류 예측 : 0~100% 사이의 확률값
- Sigmoid
- Softmax : 비율을 예측하기 위해 Softmax를 사용
인코딩 시 문제 해결
- 타입
- .dtypes로 타입 확인
- 원핫인코딩은 object나 category만 인코딩 해주기 때문에, .astype('category')로 변경해주어야 한다.
- 결측치
- NA값에 평균값을 넣는다. .fillna()
loss값을 더 낮추고 싶을 때
- .BatchNormalizaion()
복습질문 1) Cross Validation은 무엇이고 어떻게 해야하나요?
머신러닝은 모델의 일반화 성능을 향상==테스트 오류를 최소화하는 것이 주된 목표입니다. cross validation은 모델 학습 시 데이터를 train, validation, test 세트로 나누어 교차 검증하는 방법으로, validation variance가 커서 모델 성능 결과가 변동 되지 않도록 합니다.
K-Fold Cross Validation이 일반적으로 많이 사용되고, 빠르게 모델의 성능을 확인하고 싶다면 hold-out cross validation을 사용하기도 합니다.
복습질문 2) 회귀 / 분류시 알맞은 metric은 무엇일까요?
머신러닝에서는 학습이 잘 되었는지 확인하기 위한 성능 평가 metrics가 존재합니다. 연속형 변수를 분석하는 예측, 회귀 시에는 MSE, RMSE, MAE, MAPE 등이 있습니다. 범주형 변수를 다루는 분유 분석에서는 accuracy, precision, recall, f1-score가 있습니다.
복습질문 3) 알고 있는 metric에 대해 설명해주세요.
Precision은 Positive라고 예측한 값들 중 실제로 Positive인 비율을 말합니다. 정답이 아닌데 정답이라고 예측한 것이 있는지 확인하기 위한 지표로, 스팸메일과 같이 Negative 데이터를 Positive로 잘못 예측하면 큰 피해가 발생하는 경우를 예로 들 수 있습니다.
Recall은 실제값 중에서 모델이 맞게 검출한 실제값의 비율을 말합니다. 정답인데도 정답을 못찾는 것이 있는지 확인하기 위한 지표로, 암환자 예측과 같이 Positive 데이터를 Negative로 잘못 예측하면 큰 피해가 발생하는 경우가 예가 됩니다.
복습질문 4) 정규화를 왜 해야할까요? 정규화의 방법은 무엇이 있나요?
부동산을 예로, 부잣집과 일반 집 가격을 비교하게 되면 범위가 다르기 때문에 직접적인 비교가 어렵습니다. 이처럼 feature를 동일한 정도의 스케일(중요도)로 비교할 수 있도록 정규화, 표준화를 진행합니다. 이를 feature scaling이라고도 합니다.
정규화 방법은 표준화(Z-score), Min-Max scaling, robust scaling이 있습니다. 표준화는 표준편차로 조정, min-max는 최소를 0, 최대를 1로 조정, robust는 중간값을 뺀 후 IQR값을 나눠주는 방식으로 조정합니다.
복습질문 5) 부스팅 3대장 모델의 특징에 대해 설명해 주세요.
부스팅 3대장은 XGBoost, LightGBM, CatBoost입니다.
XGBoost는 level-wise로 깊이를 줄이고 수평성장하는 방식을 사용하며, learning rate와 n_estimator을 조절하여 과적합을 방지합니다.
LightGBM은 leaf-wise로 비대칭적인 트리를 생성하지만, 예측 오류 손실이 작거나 빠르게 도달할 수 있으며, 결측치 처리를 할 필요가 없습니다. XG부스트보다 빠르지만, 다중 분류나 회귀가 안되는 치명적인 단점이 있습니다.
CatBoost는 범주형 기능에 대한 처리를 제공합니다. 대칭 트리를 형성하며, 희소 행렬을 지원하지 않습니다. 수치형 타입이 많을 때, LightGBM보다 훈련 시간이 오래 걸립니다
