- Cross Validation
머신러닝은 모델의 일반화 성능을 향상==테스트 오류를 최소화하는 것이 주된 목표이다. cross validation은 모델 학습 시 데이터를 train, validation, test 세트로 나누어 교차 검증하는 방법으로, validation error의 평균을 내어 validation variance가 커서 모델 성능 결과가 변동되지 않도록 한다. CV를 통해 과적합, 과소적합을 방지할 수 있지만, 반복 학습 횟수가 증가함에 따라 시간 소요가 오래걸린다는 단점이 있다.
K-Fold Cross Validation이 일반적으로 많이 사용된다. 빠르게 모델의 성능을 확인하고 싶다면 hold-out cross validation을 사용하기도 한다.
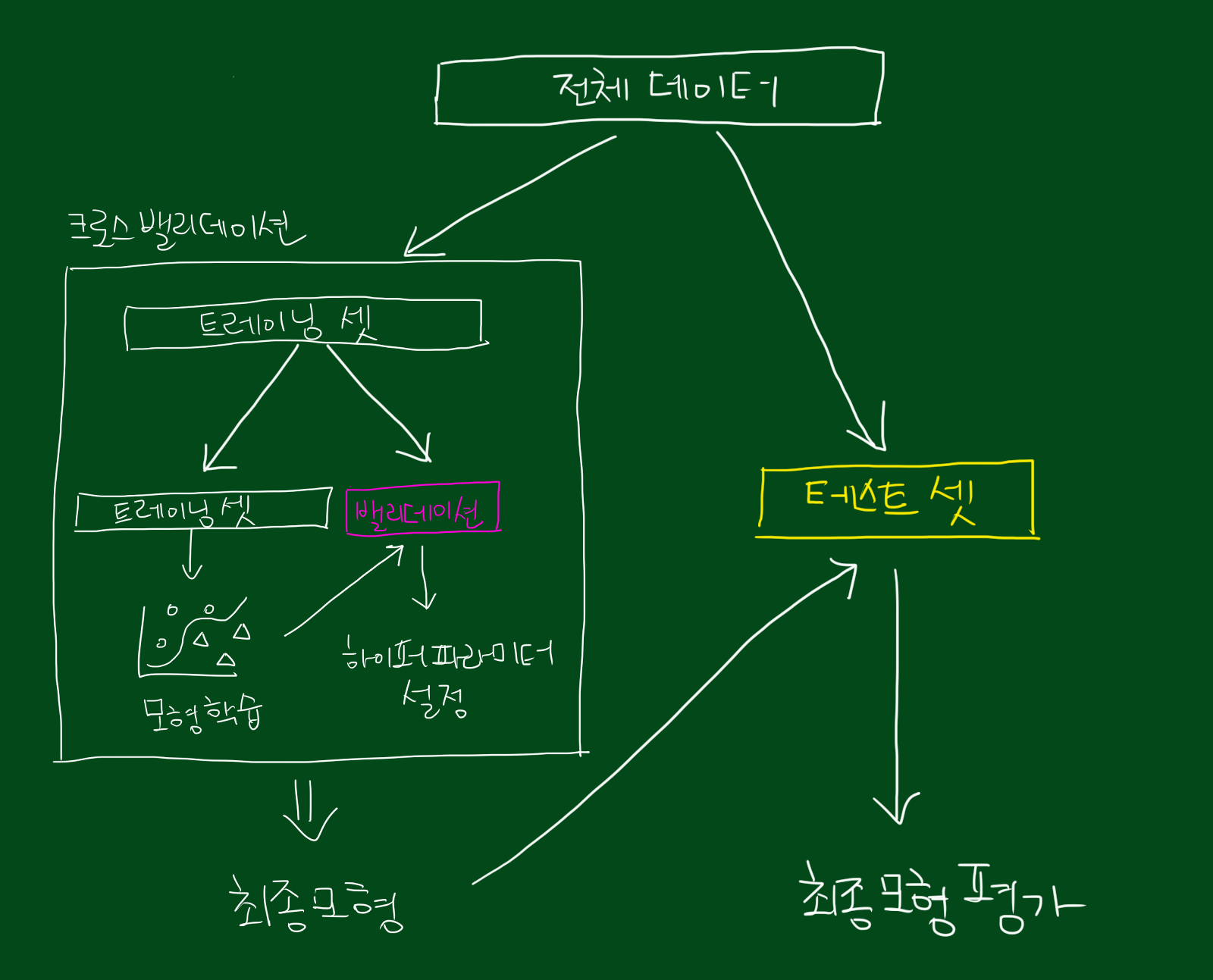
1-1. K-Fold Cross Validation
전체 데이터셋을 동일한 크기의 k개의 그룹으로 분할하여 한 그룹은 validation set, 나머지는 train set으로 사용한다. 분할된 fold 중 test data로 할당된 적 없는 fold 하나를 test data로 할당한다.
K번 fit을 진행하여 k개의 MSE를 평균내어 최종 MSE를 계산한다.
(참고 : https://deep-learning-study.tistory.com/623)
https://blog.naver.com/hsj2864/222215638480 글에서 cross validation을 사용할 때 🔥validation set이 검증으로 사용되는지, 평가로 사용되는지 차이🔥에 대해 잘 설명이 되어 있다.
1-2. GridSearchCV, RandomizedSearchCV
하이퍼파라미터를 정하고 조합을 검증하는 방법. searchCV는 CV의 데이터를 여러번 사용해서 비교하는 개념을 빌려와 최적의 hp를 찾아내는 것이고, CV는 비교하여 모델의 일반화 성능을 파악하는 것이기 때문에 목적이 다르다. (https://blog.naver.com/khjj929/222727842404)
- 회귀, 분류 시 알맞은 metric
머신러닝에서는 학습이 잘 되었는지 확인하기 위한 Metircs가 존재한다. 성능 평가란, 실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이(오차)를 구하는 것이다. (실제값-예측값)=0이면 오차가 없는 것이며, 현실적으로 오차가 없기는 힘들기 때문에 어느 정도까지 오차를 허용할 지 결정한다.
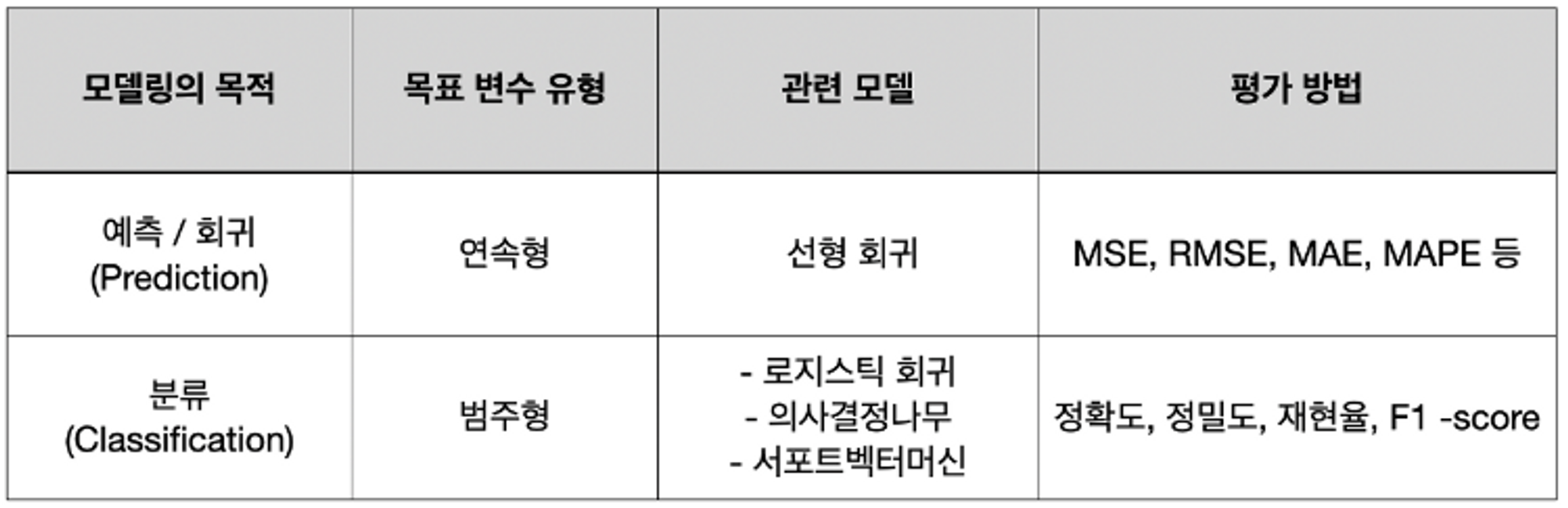

아직 고쳐나가는 중.