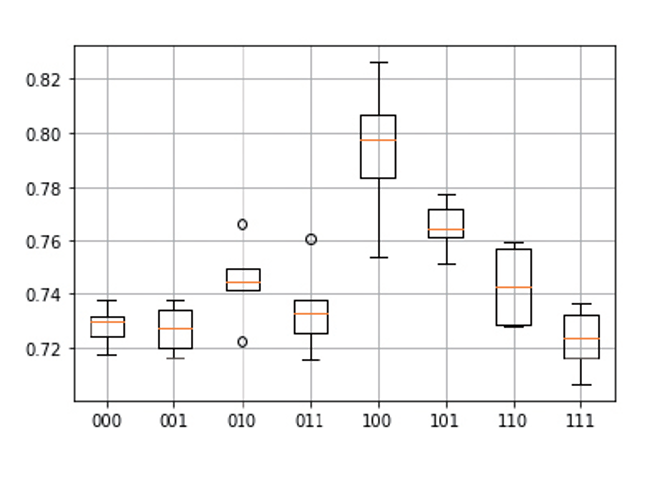
제거 분석 (여러가지 조건 나타낸 실험설계를 boxplot으로 표현함)
dropout
l1, l2, regulation,
정형데이터 : imbalance로 smot를 통해 부풀리기
이미지데이터 : 이미지 전처리, 기본으로 부풀리기
이미지는 전처리에서 255로 나눠지면 최적화 과정이 훨씬 빨라짐.
한 장 들어가는 데에 따라서 시간이 너무 걸림. gpu가 없으면 속도가 너무 느림
열두 장을 뽑아서 사용. 증가시키면서 속도가 필요하고 학습하는 데 속도가 필요해서 시간이 굉장히 오래 걸림.
image generatator을 활용하는 방법.
학습해야하는 12개가 그려보면 저럼...
label랑 같이.
12개를 가지고 학습을 하면, 뭘 많이 배울 게 없지만, 영상 증대기를 생성하여, 배치사이즈만큼 확대시켜서 생성함. 몇 장 확대시킬지는 배치사이즈에다 쓰면 됨. 12장이니 72장정도 학습시키겠다는 뜻.
# 영상 증대기 생성
batch_siz=6 # 한 번에 생성하는 양
generator=ImageDataGenerator(rotation_range=30.0,width_shift_range=0.2,height_shift_range=0.2,horizontal_flip=True)
gen=generator.flow(x_train,y_train,batch_size=batch_siz)imgaeDataGeneratator : rotation_image와 width_shift_range 라는 조건가지고 증대시킴.
generator.flow
:한장 한장 디렉토리에서 가져오는 것임.
12장에서 한장한장. 그 디렉토리로부터. 그래서 옵션이 2개가있음. 그래서 배치사이즈로 증대시킴.
# 첫 번째 증대하고 그리기
img,label=gen.next()
plt.figure(figsize=(16,3))
plt.suptitle("Generator trial 1")
for i in range(batch_siz):
plt.subplot(1,batch_siz,i+1)
plt.imshow(img[i])
plt.xticks([]); plt.yticks([])
plt.title(class_names[int(label[i])])첫번째 걸 가져와서 증대시킨다음에, 어떤식으로 증대시킬지.
# 두 번째 증대하고 그리기
img,label=gen.next()
plt.figure(figsize=(16,3))
plt.suptitle("Generator trial 2")
for i in range(batch_siz):
plt.subplot(1,batch_siz,i+1)
plt.imshow(img[i])
plt.xticks([]); plt.yticks([])
plt.title(class_names[int(label[i])])두번째 걸 가져와서 증대.
# 신경망 모델 학습(영상 증대기 활용)
cnn.compile(loss='categorical_crossentropy',optimizer=Adam(),metrics=['accuracy'])
batch_siz=16
generator=ImageDataGenerator(width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=True)
hist=cnn.fit_generator(generator.flow(x_train,y_train,batch_size=batch_siz),epochs=10,validation_data=(x_test,y_test),verbose=2)실시간으로 받아와서 학습시켜라는 거.
디렉토리에서 가져올 거면 generator.flow 에서 파일 이름과 같이.
하나 들어가서 6장 생성해서 학습(실시간으로). -> 속도가 좀 느림.
4~50정도 학습해서 끝내고 30회정도에서 끝나긴함
79%정도 나오는데 epoch = 10 하면 그걸 못 따라감.
그래프를 보면
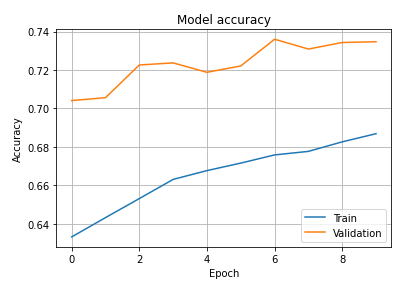
training 데이터가 쭉 놀라가고 있으니 앞으로 학습할 여지가 많아서 underfitting
학습이 너무 많이 일어나면 validation 이 뚝 떨어질 텐데 계속 올라가고 있어서 더 학습이 필요함.
accuracy만아니라 loss도 마찬가짐.
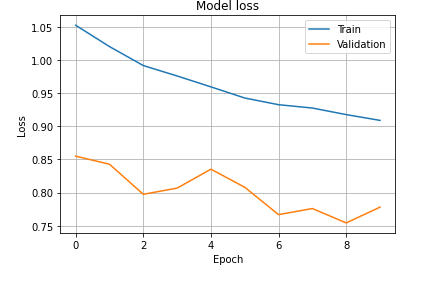
점점 떨어지고 있기 때문에 어딘가에 좋은 모델이 나올 수 있음.
ecpoch 을 50정도 해서 earlystopping으로 하면 30에서 끝낼 수 있음.
drop out 예제
validation 데이터를 따로 빼면 데이터 손실이 커서 k겹 검증을 통해 번갈아서 빼서 검증시킴.
그네들의 평균을 구하는 게 k-겹 검증. 몰리지 않고 5번을 골고루 빼어 쓰니까.
기본 0.5를 기준으로, 다음 노드로의 완전 연결 구조를, 하나도 뗴어먹지 않고, 완전 연결구조를 1로 잡음. 모든 정보를 다 연결하면 overfitting이 일어날 수 있기 때문에. 한칸 안주고 한칸 주고........... -> 0.5
0.75는 3/4씩 정보를 주는 것임. 실험을 할 때, dropout 해서 열심히 돌림... 0.25도 열심히 돌린 다음에 그다음 결과가
보통 이걸 어캐하면 되냐면 함수를 만들면 됨. 0.5, 0.25,.0.75... 다양하게 값들을 모두 모여 하나로 찍고 싶을 때.
# 드롭아웃 비율에 따라 교차 검증을 수행하고 정확률을 반환하는 함수
def cross_validation(dropout_rate):
accuracy=[]
for train_index,val_index in KFold(k).split(x_train):
# 훈련 집합과 검증 집합으로 분할
xtrain,xval=x_train[train_index],x_train[val_index]
ytrain,yval=y_train[train_index],y_train[val_index]
# 신경망 모델 설계
cnn=Sequential()
cnn.add(Conv2D(32,(3,3),activation='relu',input_shape=(32,32,3)))
cnn.add(Conv2D(32,(3,3),activation='relu'))
cnn.add(MaxPooling2D(pool_size=(2,2)))
cnn.add(Dropout(dropout_rate[0]))
cnn.add(Conv2D(64,(3,3),activation='relu'))
cnn.add(Conv2D(64,(3,3),activation='relu'))
cnn.add(MaxPooling2D(pool_size=(2,2)))
cnn.add(Dropout(dropout_rate[1]))
cnn.add(Flatten())
cnn.add(Dense(512,activation='relu'))
cnn.add(Dropout(dropout_rate[2]))
cnn.add(Dense(10,activation='softmax'))
# 신경망 모델을 학습하고 평가하기
cnn.compile(loss='categorical_crossentropy',optimizer=Adam(),metrics=['accuracy'])
cnn.fit(xtrain,ytrain,batch_size=batch_siz,epochs=n_epoch,verbose=0)
accuracy.append(cnn.evaluate(xval,yval,verbose=0)[1])
return accuracydrop out 에 droput비율을 주게 되어있음.
acc_without_dropout=cross_validation([0.0,0.0,0.0])cross_validation할때, 다 안하니까 드랍아웃을 적용하지 않은 모델이고.
acc_with_dropout=cross_validation([0.25,0.25,0.5])0.25, 0,25,0.5로 드랍아웃줌.
xtrain,xval=x_train[train_index],x_train[val_index]
ytrain,yval=y_train[train_index],y_train[val_index]k폴드 검증. 각각에다가
import matplotlib.pyplot as plt
# 박스 플롯으로 정확률 표시
plt.grid()
plt.boxplot([acc_without_dropout,acc_with_dropout],labels=["Without Dropout","With Dropout"])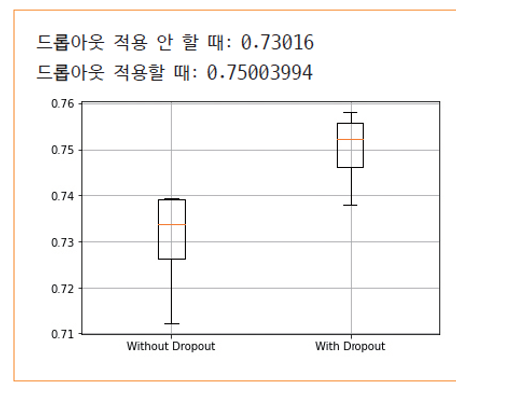
dropout 각각각...
여러 옵션이 있으니 함수를 하나 만들어놓고 다른 값들을 적용해보면서 모델을 찾아야지. o.5, 0.3 같은 걸 어디 써놓고 가기엔 찾기가 어려움. 좋은 모델을 찾을 때 저 함수를 사용하면돔.
매개변수를 변경시켜가면서 겨로가 찌어내면 됨.
또하나는 드롭아웃을 적용할 수 도 있고 규제를 적용할 수도 있음.
언더 피팅이 일어났기에 규제를 적용해봤지 좋은 모델이 안나옴, 오버피팅을 했다는 이유는 별로 중요하지 않은 것들까지 다 잡아냈기에 효과가 좋지 못한거임 그리고 구디 별로 안중요한걸 끌어내려면 어캐해야함? 일반화되는 모델로 가는 과정으로 규제라는 걸 쓰는데 그 핵심아이디어는, 가중치가 너무 큰 것들..... 손실함수에다가 값을 덧붙임(벡터값의 놈) 어떻게 활용할 수 있는가?
총 모델 예시
def cross_validation(data_gen,dropout_rate,l2_reg):
accuracy=[]
for train_index,val_index in KFold(k).split(x_train):
xtrain,xval=x_train[train_index],x_train[val_index]
ytrain,yval=y_train[train_index],y_train[val_index]
# 신경망 모델 설계
cnn=Sequential()
cnn.add(Conv2D(32,(3,3),activation='relu',input_shape=(32,32,3)))
cnn.add(Conv2D(32,(3,3),activation='relu'))
cnn.add(MaxPooling2D(pool_size=(2,2)))
cnn.add(Dropout(dropout_rate[0]))
cnn.add(Conv2D(64,(3,3),activation='relu'))
cnn.add(Conv2D(64,(3,3),activation='relu'))
cnn.add(MaxPooling2D(pool_size=(2,2)))
cnn.add(Dropout(dropout_rate[1]))
cnn.add(Flatten())
cnn.add(Dense(512,activation='relu'))
cnn.add(Dropout(dropout_rate[2]))
cnn.add(Dense(10,activation='softmax',kernel_regularizer=regularizers.l2(l2_reg)))
# 신경망을 학습하고 정확률 평가
cnn.compile(loss='categorical_crossentropy',optimizer=Adam(),metrics=['accuracy'])
if data_gen:
generator=ImageDataGenerator(rotation_range=3.0,width_shift_range=0.1,height_shift_range=0.1,horizontal_flip=True)
cnn.fit_generator(generator.flow(x_train,y_train,batch_size=batch_siz),epochs=n_epoch,validation_data=(x_test,y_test),verbose=2)
else:
cnn.fit(xtrain,ytrain,batch_size=batch_siz,epochs=n_epoch, validation_data=(x_test,y_test),verbose=2)
accuracy.append(cnn.evaluate(xval,yval,verbose=0)[1])
return accuracy(data_gen, dropout_rate, l2_reg)
그 조합 그대로 변수를 가져오게 됨.
쫙 돌려보고 그 결과를 똑같이 찍어보면 그 결과가 이런식으로 나옴.