[기계학습] SHAP CODE
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over,y_train_over = smote.fit_resample(X_train,y_train)이미지도 SMOTE를 이용해 불균형 데이터를 조절할 수 있다.
!pip install shap
import shapimport SAHP
explainer = shap.KernelExplainer(model, X_test[:100])보통은 X_test 그대로 사용한다. 빠르게 확인하고 싶어서 100번까지 사용하였다.
KernelExplainer: 비선형TreeExplainer: tree 형태, XGBoost/random forest 사용DeepExplainer: 딥러닝 구조에서 사용한다
shap_values = explainer.shap_values(X_test[:100]) 데이터마다 SHAP value를 확인한다.
shap.initjs()
shap.force_plot(explainer.expected_value,
shap_values[0], X_test[:100])force_plot: 데이터 하나하나 확인한다.summary_plot: 전체 변수가 얼마나 영향을 미쳤는가. feature importance와 다름이 없다.
딥러닝 입력을 받을 때 헤더는 들어가지 않으므로 변수 번호로 표시된다.
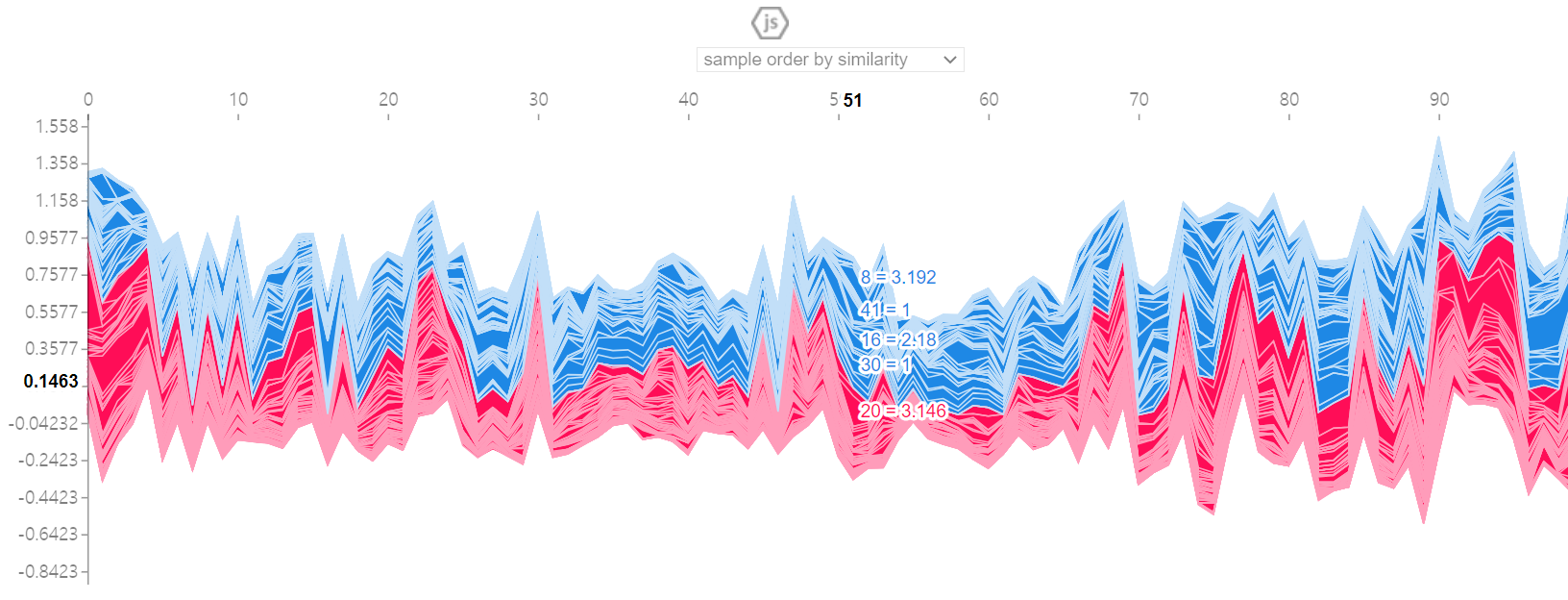
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0][5], X_test.loc[5,:])jsp를 이용해 개별 데이터의 변수 영향도를 측정한다.
shap_values의 0행에 value값이 들어 있고, 몇 번째 그림을 확인하고 싶은지 열에 그 번호를 기입한다.
shap.summary_plot(shap_values, X_test[:100])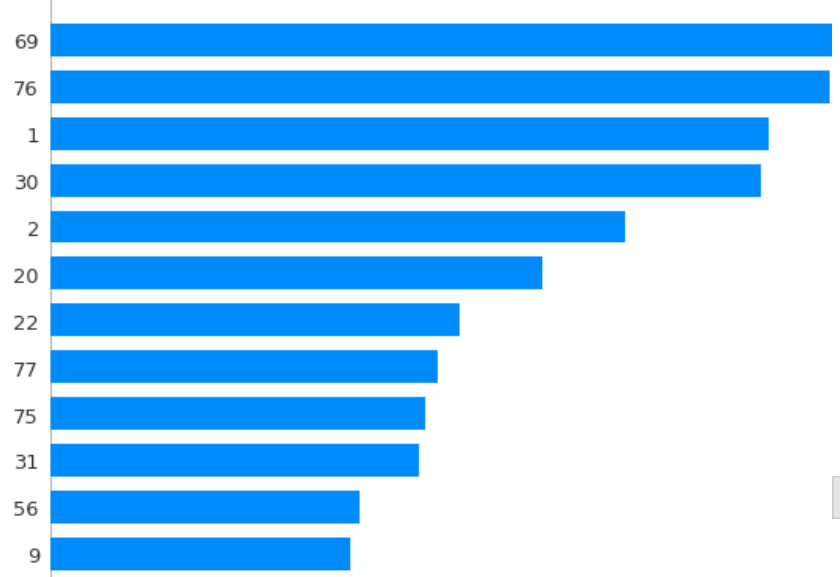
print(df.columns[69])변수 정보 확인
shap.dependence_plot(69, shap_values[0], X_test[:100])dependence_plot는 변수들이 그 데이터에 어느정도 영향을 끼치고 있는지 보여준다.

리액트