[기계학습] 자살 고위험군 예측 실습 (1)
<학습 목표>
1. pipline을 통해 전처리
2. 노드와 히든레이어를 통해 네트워크 구조 설계
실습 준비
(1) 라이브러리 import
import pandas as pd
import numpy as np
from collections import Counter
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline(2) google drive 내 실습 데이터 파일 가져오기
np.random.seed(3)
tf.random.set_seed(3)
df = pd.read_csv("/content/drive/MyDrive/MyLecture/2022/ML2022/suicide_data.csv")
df전처리
-
데이터 feature가 범주형인지 수치형인지 확인해야 함. (실무에서는 협업 과정에서 알아내거나, 본인이 하거거나, customer측에서 알려줘야 함)
-
결측 값이 굉장히 많지만, 결측값을 우선 제거하는 것이 좋음. nan만 결측값이 아니라 무응답 혹은 모름을 선택항목으로 집어넣은 경우가 있기에 이 값들을 nan으로 대체해야 함.
df = df.replace({'cfam':8, 'cfam':np.nan})
df = df.replace({'cfam':9, 'cfam':np.nan})
df = df.replace({'BD1_11':8, 'BD1_11':np.nan})
df = df.replace({'BD1_11':9, 'BD1_11':np.nan})
df = df.replace({'BE8_1':88, 'BE8_1':np.nan})
df = df.replace({'BE8_1':99, 'BE8_1':np.nan})- 결측값 찾는 법 : numeric으로 변환.
Counter(df.dtypes)- numberic으로 전환이 안 되는 경우
df = df.iloc[:,1:].apply(pd.to_numeric, errors='coerce')- df를 받아와 결측값을 어떤 식으로 처리(대체, 삭제)할 건지 체크하기 위한 함수
def null_check(df):
null = df.isnull().sum()
null_col=[]
for i in range(len(df.columns)):
if (null[i]!=0):
print(null.index[i],null[i])
null_col.append(null.index[i])null_check(df)mh_stress 1445
L_OUT_FQ 750
mh_suicide 1445
BE8_1 476
LW_mt 3608
LW_oc 3608
HE_HP 2176
HE_anem 1555
O_chew_d 1976
L_BR_FQ 750
L_LN_FQ 750
L_DN_FQ 750
DI2_pr 476
DI3_pr 476
DI4_pr 921
DI5_pr 476
DI6_pr 476
DM1_pr 924
DM2_pr 476
DM3_pr 476
DM4_pr 476
D_8_2 476
D_8_4 476
DJ4_pr 476
DE1_pr 476
DE2_pr 476
DC1_pr 476
DC2_pr 476
DC3_pr 476
DC4_pr 476
DC5_pr 476
DC6_pr 476
DC7_pr 476
DF2_pr 476
DL1_pr 476
DJ8_pr 476
DH2_pr 476
DH3_pr 476
DN1_pr 476
DK8_pr 476
DK9_pr 476
DK4_pr 476
LQ4_00 476
LQ1_sb 476
LQ_1EQL 476
LQ_2EQL 476
LQ_3EQL 476
LQ_4EQL 476
LQ_5EQL 476
educ 476
EC1_1 476
BO1 476
BO1_1 476
BO2_1 476
BD1_11 476
incm 52
edu 968
occp 2025
HE_wt 409
HE_wc 413
HE_BMI 421
N_EN 752
N_WATER 752
N_PROT 752
N_FAT 752
N_SFA 752
N_MUFA 752
N_PUFA 752
N_CHOL 752
N_CHO 752
N_TDF 752
N_CA 752
N_FE 752
N_NA 752
N_K 752
N_VITC 752
LF_SAFE 427
LF_S2 427
- y_label이 결측인 경우 그 label은 아예 사용이 불가능하기에 아예 삭제
df1 = df.dropna(subset=['mh_suicide'])
df1- sucide가 없는 값만 체크해도 확 줄음
print(df1.shape)(5935, 88)
- 다시 결측 확인
(LW_mt/LW_oc는 무응답이 너무 많아서 해당 feature가 무엇인지 확인하고 삭제)mh_stress 1
L_OUT_FQ 643
LW_mt 2640
LW_oc 2640
HE_HP 845
HE_anem 411
O_chew_d 531
L_BR_FQ 643
L_LN_FQ 643
L_DN_FQ 643
DI4_pr 365
DM1_pr 365
incm 36
edu 398
occp 652
HE_wt 5
HE_wc 7
HE_BMI 9
N_EN 645
N_WATER 645
N_PROT 645
N_FAT 645
N_SFA 645
N_MUFA 645
N_PUFA 645
N_CHOL 645
N_CHO 645
N_TDF 645
N_CA 645
N_FE 645
N_NA 645
N_K 645
N_VITC 645
LF_SAFE 354
LF_S2 354
df2 = df1.drop(['LW_mt','LW_oc'],axis='columns',inplace=False)- 데이터 확인
df2.describe()- y_label 비율 확인
Counter(df2['mh_suicide'])Counter({0.0: 5611, 1.0: 324}) : 불균형 데이터
불균형 데이터 다루는 방법
(1) OverSampling
: 적은 데이터의 개수를 억지로 50:50으로 맞춘다.
-> overfitting이 쉽게 일어남.
(2) UnderSampling
: 많은 데이터의 개수를 억지로 50:50으로 맞춘다.
-> 데이터 손실
(3) SMOTE
: 적은 데이터의 개수를 비슷한 데이터로 계산하여 맞춘다. (FOR KNN)
-> 유사하게 생성한 (없는)데이터를 생성해내기에 어떤 실무에서는 받아들이지 않는다. (공장 불량품 판별<->의료데이터)
(4) class - weight
: 학습 단계에서 가중치를 부여함. 적은 양의 데이터에 큰 가중치를 부여함.
-> 데이터를 건드리지 않지만, 불균형이 굉장히 심한 경우 class-weight로는 불가능함. (ex. 0.01%)
(5) 앙상블 학습
: 의사결정모델과 같은 여러 학습 모델을 이용.
-> 데이터를 건드리지 않음.
- 자살 생각 여부를 성별에 따라 확인
import seaborn as sns
f = sns.countplot(x='mh_suicide', data=df)
f.set_title("Suicide presence distribution")
f.set_xticklabels(['didnt think Suicide', 'Think Suicide'])
plt.xlabel("")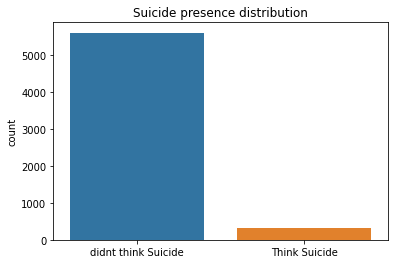
- 자살 생각 여부에 영향을 끼치는 변수를 확인(상관계수)를 할 때 주의할 점, 상관계수나 회귀분석에서 변수를 생성할 때 변수들의 독립성을 가정하지만, 이처럼 의료 데이터에서는 변수 간에 종속성이 있기 때문에 설명 가능 인공지능에서 해당 변수를 높게 치지 않을 수가 있음.
f = sns.countplot(x='mh_suicide', data=df, hue='sex')
plt.legend(['Female', 'Male'])
f.set_title("Suicide presence distribution by gender")
f.set_xticklabels(['No Suicide', 'Suicide'])
plt.xlabel("")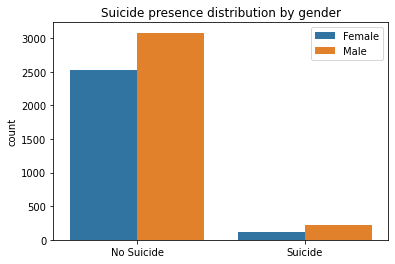
mh_suicide_corr = df.corr()['mh_suicide']
mh_suicide_corr.sort_values(axis=0)DF2_pr -0.182007
LF_S2 -0.138665
allownc -0.098459
edu -0.091495
incm -0.082476
...
occp 0.090633
O_chew_d 0.111216
LF_SAFE 0.120603
mh_stress 0.220486
mh_suicide 1.000000
Name: mh_suicide, Length: 86, dtype: float64
데이터 전처리
- library import
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler,StandardScaler,OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import FeatureUnion- preprocess_pipeline = featureUnion(num_pipeline + cat_pipleline)
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline)]) - ont-hot encoding을 하지 않아도 되는 이유, serial한 번호로 매겨놓은 경우(1,2,3,4학년). 하지만 옷 사이즈의 경우(55,66,77,88)엔 하는 것이 좋음.
one-hot encoding은 시간이 많이 걸려서 이 경우엔 하지 않고 넘어감.null 값 대치
범주형 : 최빈값
수치형 : 평균/중앙값
def pipeline(df, nums, cats):
num_inputer = SimpleImputer(strategy='median')
num_pipeline=Pipeline([
("select_numeric",DataFrameSelector(nums)),
("impute", num_inputer),
("scaler", StandardScaler())])
cat_imputer = SimpleImputer(strategy='most_frequent')
cat_pipeline = Pipeline([
("select_cat",DataFrameSelector(cats)),
("impute", cat_imputer)])
#("encoder", OneHotEncoder())])
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline)])
X=preprocess_pipeline.fit_transform(df)
return X- 데이터 나누기
X_train, X_test, y_train, y_test = train_test_split(X_data, y_label, test_size=0.3, random_state=0)
X_train = np.asarray(X_train)
y_train = np.asarray(y_train)
X_test = np.asarray(X_test)
y_test = np.asarray(y_test)- 가뜩이나 없는 데이터가 한 쪽에 몰리지 않았는지 확인. 따라서 비중을 유지하기 위해 stratify사용
print('Train data shape: {0}'.format(X_train.shape))
print('Test data shape: {0}'.format(X_test.shape))
print('Train data label => %s' %Counter(y_train))
print('Test data label => %s' %Counter(y_test))Train data shape: (4154, 84)
Test data shape: (1781, 84)
Train data label => Counter({0.0: 3926, 1.0: 228})
Test data label => Counter({0.0: 1685, 1.0: 96})
- SMOTE함수를 호출하여 X_train과 Y_train을 적용.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over,y_train_over = smote.fit_resample(X_train,y_train)print('SMOTE 적용 전 학습용 피처/레이블 데이터 세트: ', X_train.shape, y_train.shape)
print('SMOTE 적용 전 레이블 값 분포: \n', pd.Series(y_train).value_counts())
print('SMOTE 적용 후 학습용 피처/레이블 데이터 세트: ', X_train_over.shape, y_train_over.shape)
print('SMOTE 적용 후 레이블 값 분포: \n', pd.Series(y_train_over).value_counts())SMOTE 적용 전 학습용 피처/레이블 데이터 세트: (4154, 84) (4154,)
SMOTE 적용 전 레이블 값 분포:
0.0 3926
1.0 228
dtype: int64
SMOTE 적용 후 학습용 피처/레이블 데이터 세트: (7852, 84) (7852,)
SMOTE 적용 후 레이블 값 분포:
0.0 3926
1.0 3926
dtype: int64
