설명 가능 인공지능 (1)
발전되어온 딥러닝 기술의 한계
우리는 딥러닝 기술을 사용하여 대규모 데이터를 학습하여 모델을 생성할 수 있게 되었다. 하지만 이런 딥러닝 기술을 적용한 모델이 정확도가 90%라고 무조건 믿을 수 있는 것이 아니다. 딥러닝 기술은 학습 과정을 이해할 수 없기에 왜 정확도가 90%가 나왔는지 사람에게 납득할 수 있는 이유를 알려주지 않는다.

Glassbox model vs Blackbox model
모델 자체가 설명성이 있는 Glassbox 모델의 경우 설명성이 높았지만, 데이터가 작은 모델에 적합하지 대규모 데이터를 처리하기 어렵다. 또한 위와 같이 의사결정트리의 경우 데이터 규모가 커질 수록 노드 수가 많아져 해석이 어려워진다.
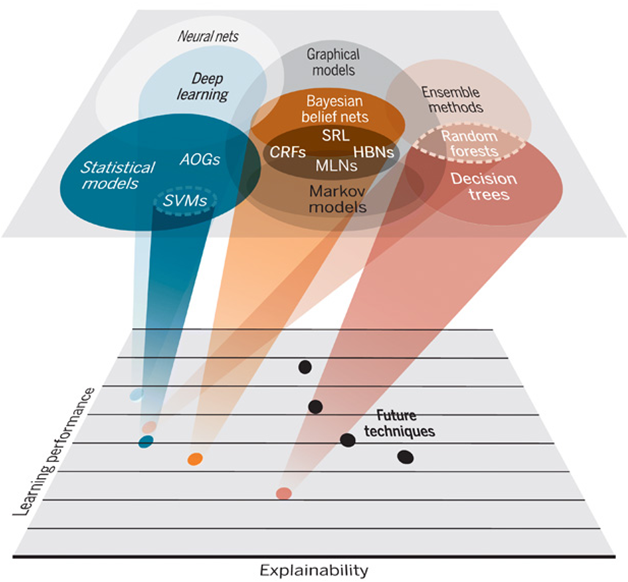
다음 그래프를 살펴보면 설명성이 높은 기술은 성능(performance)가 낮게 나오는 것을 확인할 수 있다.
딥러닝의 장점인 '기계가 스스로 학습한다.'는 것이지만, 사람은 그 과정을 해석할 수 없다. 성능은 좋으나 설명성이 낮다. 그러나 회귀 분석 혹은 의사결정모델과 같이 설명성이 좋은 모델은 성능이 떨어진다. 따라서 미래 기술은 두 가지 특징 모두를 잡을 수 있는 방향으로 나아가야 할 것이다.
설명 가능 인공지능이 왜 중요한가?
"Clever Hans"

영리한 한스(독일어: Kluger Hans)는 인간의 말을 이해하여 계산도 가능했던 19세기 말부터 20세기 초 독일에서 화제가된 오를로프 트로터 종의 말이다. 1891년 무렵부터 주인 빌헬름 폰 오스텐이 내는 간단한 문제를 발굽으로 횟수만큼 두드려서 유명해지고, 1904년에는 카를 슈툼프에 의해 조사되었으나, 어떠한 트릭도 없다고 결론지어졌다. 1907년에 심리학자 오스카르 풍그슈트에 의해 한스가 어떻게 답을 알았는지에 대해 해명되었다. 관객, 주인, 출제자 등 그 자리에 있던 사람들의 반응으로부터 발굽질을 해왔다. 즉 계산을 하는 것이 아니라, 주위의 분위기를 민감하게 감지하는 데 뛰어난 말이였다. 오늘은 이런 현상을 클레버 한스 효과라고 부르고, 관찰자 기대 효과로까지 발전되어 동물인지과학에 공헌했다.
정확한 근거가 아닌 영 다른 까닭으로 문제를 맞힌다. 정답이 나오더라도 명확한 설명성이 없는 경우 이러한 문제가 발생할 수 있다.

한스 효과라고 불리는 다른 예시, 설명성이 부족한 모델을 통해 시베리안 허스키를 구분해 내는 데에 모델의 정확도가 높았으나 알고 보니 개의 특징이 아닌 시베리안 허스키의 배경을 통해 종을 분리해내고 있었다.
설명성이 부족해도 분류만 잘 되면 된다고 생각하면 문제가 없겠지만, 그렇지 않은 경우에 문제가 발생한다.
설명 가능 인공지능의 수준과 어려움
하지만 인공지능 모델에 설명 가능성을 추가하여 모델을 생성해도 한계가 있다. 바로 설명성을 설명해줄 수 없다는 것이다. 이때 정형 데이터의 경우 사람들이 detect 할 수 있지만, 영상, 그림, 소리의 경우 사람들이 들여다 봐도 모르는 경우가 다반사이다.
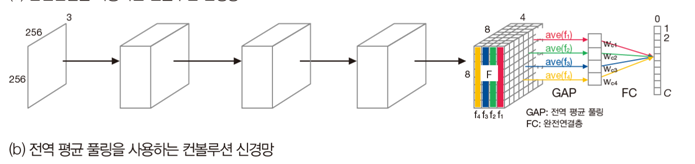
CAM
해당 인공지능이 어디를 보고 분류했는지 알려주는 알고리즘. 추출해 놓은 고급 특징에 Flatten층을 걸쳐 1차원으로 펼치지 말고 global average pooling층을 연결한다.
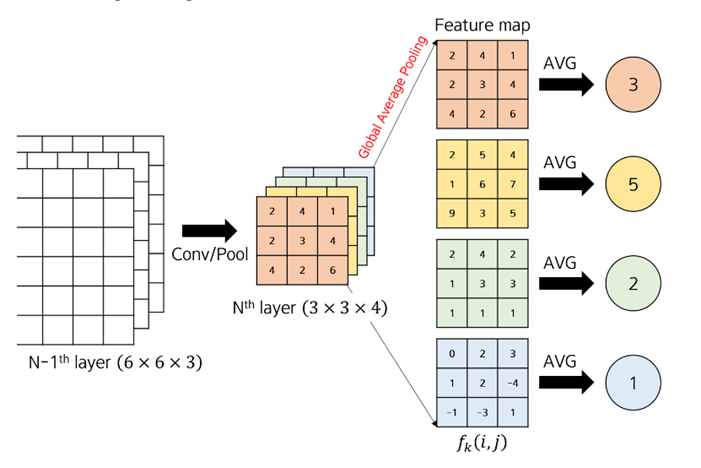
각각의 특징맵을 각각 하나의 값으로 곱해서 결과를 도출하면 어떤 값에 가중치를 많이 두었는지 알 수 있다.
Max Pooling의 경우 nXn layer에 가장 큰 값 하나를 가져온다면 global Average Pooling(GAP)의 경우 각 특징맵의 제곱의 평균값을 계산한다.
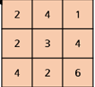
GAP층을 쌓는 대신 Flatten을 시켰다면, 다음 특징 맵이 {2,4,1,2,3,4,4,2,6}으로 펼쳐졌겠지만, 해당 특징 맵을 GAP으로 처리한다면 강조하고 싶은 정도를 하나의 숫자로 표현할 수 있다.
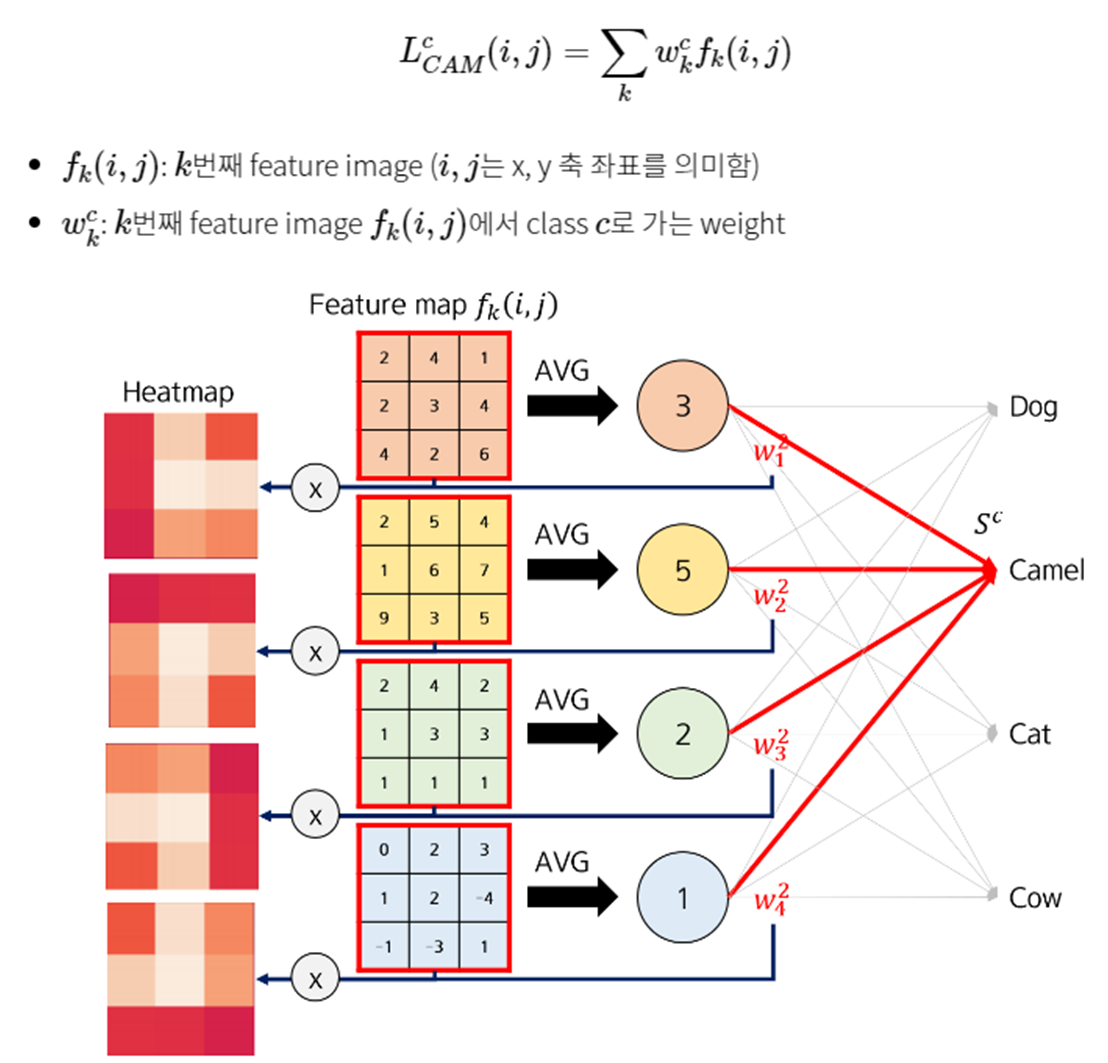
4개의 특징맵에 같은 자리에 있는 픽셀 값을 곱해서 더해주고 이미지에 덧씌우면 왜 CAMEL이라고 했는지 결과가 나온다.
그러나 flatten말고 GAP를 사용해야 하므로 ResNet이 아닌 VGG16 같은 기존 모델에 일반적으로 적용이 되지 않는다. 그렇다면 flatten된 값을 이용해서 설명성을 추가하려면 어떻게 해야 할까?
GradCAM
GAP를 사용하지 않는 모델에 적용할 수 있다.
오차 역전파 알고리즘의 아이디어에 착안을 하여 미분 값을 활용한다. 미분값 자체가 중요성을 담고 있다고 판단, 가중치를 곱하는 와중에 GAP하지 않고 Flatten된 값에 미분을 하여 ReLU를 통과시킨다.

이때 CAM과 GradCAM 성능 차이는 크지 않다.
XAI : gobal vs local
전체를 보고 도출해 낸 특성보다, 개개인 정보를 고려하여 개개인이 가진 데이터를 더 이용해 정보를 도출해 낸다. 현재는 local 설명성이 더 주목을 많이 받고 있다.
대리분석 surrogate Analysis
엔지니어링에서 먼저 대리분석을 사용했었다. 본래 기능을 흉내내는 대체제를 만들어 프로토타입을 판단하는데, 인공지능에서는 이와 같이 대체할 수 있는 유사한 (설명 가능한) 모델로 (설명 불가능한) 딥러닝 모델을 해석한다.
분석 모델 f를 두고 대리 분석할 g를 만든다. 이때 g는
- 모델 f보다 학습하기 쉽다.
- 설명가능하다.
- 모델 f를 유사하게 흉내낼 수 있어야 한다.
를 만족시켜야 한다.
로컬 대리 분석
데이터 하나에 대해 블랙박스가 해석하는 과정을 분석하는 기법이다.
(1) LIME
신뢰성의 기준(Trust)
- 개별 예측을 얼마나 믿을 수 있는지 (Trusting a Prediction)
- 모델 자체를 얼마나 믿을 수 있는지 (Trusting a Model)
Explainer를 만들 때 고려해야 할 세 가지 요건
-
해석 가능해야 한다. (Ineterpretablility)
-
데이터 하나하나를 믿을 만 해야 한다. (Local Fidelity)
-
어떤 모델이든 Explainer만 있으면 해석 가능해야 한다.(Model Agonistic)
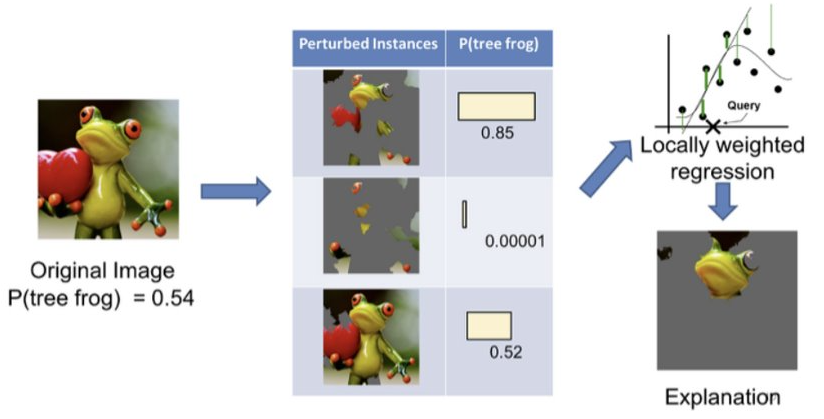
랜덤으로(교란변수) 변수를 삭제하여 성능 차이가 두드러지는 정도를 판단하여 변수의 중요도를 판단한다.
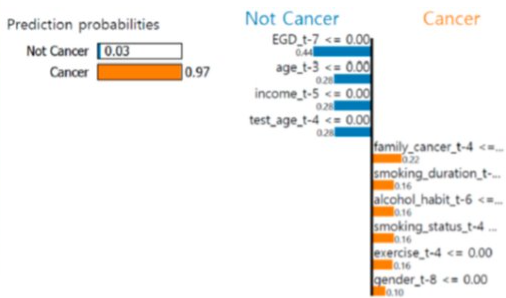
정형 데이터도 마찬가지 변수 제거하거나 교란 변수를 사용하여 성능 차이가 있다면 변수의 중요도를 확인할 수도 있다.
따라서 데이터의 형태가 무엇이든, 모델이 무엇이든 설명가능하다.
(2) Shapley Additive explanation (SHAP)
경제학에서 아이디어를 가져왔다. 각 사람들이 결과에 얼마나 공헌했는지 수치로 표현한다. 그 사람의 기여도를 제외했을 때 전체 성과의 변화 정도를 계산하여 표현할 수 있다.
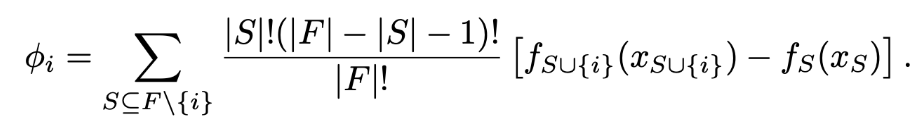
- S : 전체 집합에서 i(특정 사람)번째 사람이 빠진 나머지 집합
- F : 전체 집합
- f : 공헌도
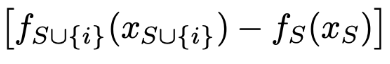
나를 포함한 전체 집합에서 나를 뺀 나머지 집합의 기여도를 빼서 크고 작음을 판단하여 중요도를 판단한다.
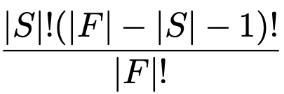
i번째 하나만 빠지는 게 아니라 i번째 혹은 j번째 등등 여러가지 조합을 경우의 수로 계산한다.
이 수식을 인공지능에서 학습 변수에 그대로 적용한다. LIME이랑 동작 방식은 비슷하지만, SHAP의 경우 변수 간의 의존성을 고려하였다.
- SHAP는 정형데이터에 많이 쓰인다. (의료 데이터는 변수 하나가 다른 변수에 영향을 끼치는 경우가 다반사이다)
- 집합의 모든 경우의 수를 고려해야 하므로 동작 시간이 오래 걸린다. + feature가 전부 setting 되어 있는 상황에서 사용하는 것이 좋다. (변수 삭제와 수정이 빠른 모델x)
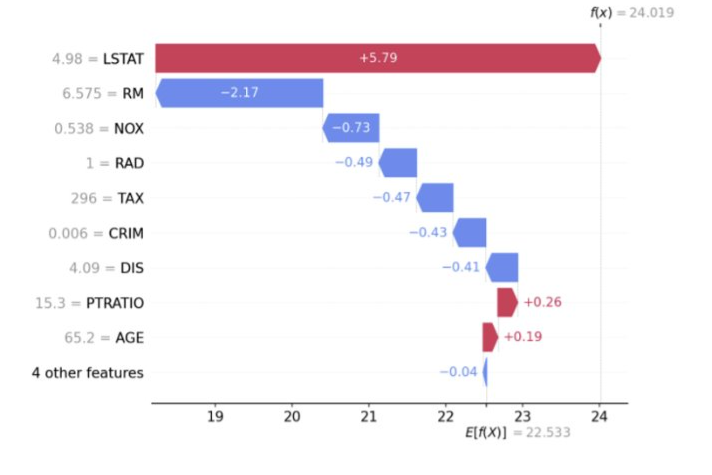
- 붉은 색 : 양수(+), 결과를 서포트하는 변수
- 푸른 색 : 음수(-), 결과와 반대되는 변수
