이 글은 논문 Decision Transformer: Reinforcement Learning via Sequence Modeling에 대한 설명입니다. 논문 원본에 대한 링크는 아래에 적어놓았습니다.
논문 원본 : https://arxiv.org/abs/2106.01345
Abstract
Decision Transformer는 Causally masked Transformer를 활용하여 최적의 Action을 출력한다. 이 모델은 Return(Reward), Past States, Actions에 대한 Autoregressive model을 조절함으로써 원하는 Return 값을 갖는 미래의 Actions를 생성할 수 있다.
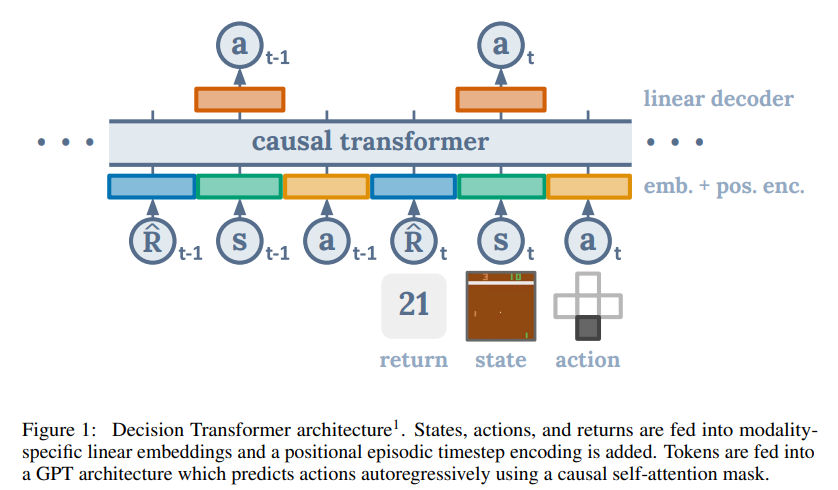
위 그림은 Decision Transformer의 Architecture이다. Return-to-go, States, Actions를 입력으로 취해 다음 step의 Action을 예측한다.
-
Causally Masked Transformer란?[3]
Causal Language Models를 사용한 Transformer라는 뜻으로, 이는 왼쪽에 나타나는 단어만을 고려하는 모델이다. (단방향 모델) -
Autoregressive Model[4]
변수의 과거 값의 선형 조합을 이용하여 관심 있는 변수를 예측하는 방법
Introduction
이 논문에서 고려하는 Paradigm의 변화는 다음과 같다.
Sequence modeling objective를 사용하여 수집된 경험을 바탕으로 Transformer Model을 훈련시킨다. 이 방법으로 Long term credit assignment를 위한 Bootstrapping에 대한 필요를 피할 수 있다. 따라서 "Deadly triad" 중 하나를 회피하여 Discounting factor를 사용하지 않아도 된다.
Transformer는 긴 Sequence를 모델링하는데 장점을 가지고 있으며, Self-Attention을 거쳐 시행했던 Action들이 결과에 어떤 영향을 미쳤는지 알 수 있다.
이 논문에서는 Offline RL을 고려하여 가설을 탐구한다.
State, Action, Return의 Sequence에 대해 Autoregressive model을 훈련함으로써, Autoregressive generative modeling으로 Policy sampling을 줄인다.
- Illustrative example
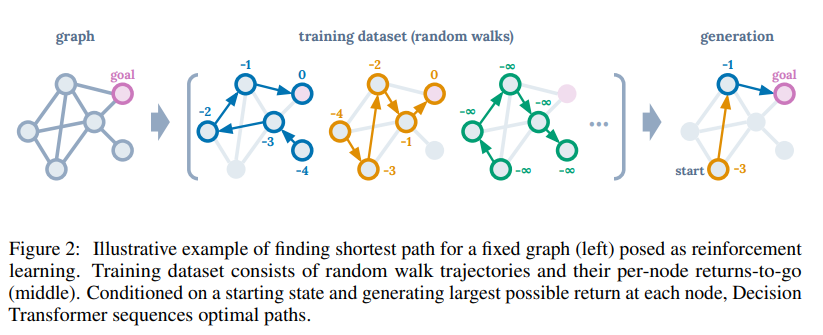
Offline RL의 예시를 위 그림으로 설명할 수 있는데, Node 하나를 이동할 때마다 Negative한 결과를 얻는 Random Trajectory 데이터들이 주어져 있을 때, 이 경로들을 이어서 새로운 최단 경로를 찾는 예제이다.
여기서 Generation을 보면 -3, -1 goal 순으로 나와있는데, Start에서 Goal까지 2번 이동했지만 Start의 값이 -2가 아닌 -3인 이유는 Dataset에 있는 Return을 그대로 가져오는 것이기 때문이다.
Preliminaries
1. Offline reinforcement learning
Online RL이 실제로 매번 예측을 수행하며 다음 상태를 탐색하는 것이라면, Offline RL은 고정된 Dataset으로 최적의 Policy를 찾는 것이다.
Offline RL에 대해 부가적으로 더 설명하자면, 어떠한 Rollout Policy를 이용하여 Suboptimal dataset을 수집한다. 이후 이 Dataset만을 이용하여 Policy를 학습하는 것이다.
이 논문에서 설명하기를 MDP = (S, A, P, R)이라 정의하고, 하나의 Trajectory(Sequence of states, actions, and rewards)를 아래와 같이 설명하고 있다.
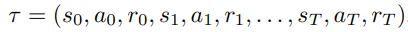
아래의 식은 하나의 Trajectory에 time stpe t에 따른 Return 값이다.
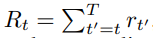
강화학습의 목표는 위 Rt 값의 기대값인 아래의 Expected Return 값을 최대화하는 Policy를 학습하는 것이다.
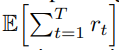
2. Transformer
Vaswani et al[1]이 제안한 Transformer는 Sequential data를 효과적으로 modeling하기 위한 Architecture이다.
Transformer는 Multi-head Attention으로 구성되어 있으며, 각각의 Self-Attention layer는 입력 토큰에 해당하는 n개의 임베딩을 수신하고, 입력 차원을 보존하는 n개의 임베딩을 출력한다.
i번째 토큰은 Linear Transformation을 통해 Key, Query, Value로 Mapping된다. 그리고 각 Self-Attention layer의 i번째 출력은 Query와 Key 사이의 정규화된 Dot product로 Value 값을 가중치로 부여하여 주어진다.
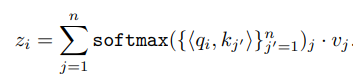
이 연구에서는 위에서 설명한 Transformer를 응용하여 개발된 GPT Architecture[2]를 사용한다.
Method
Decision Transformer의 전체적인 Pseudocode(for continuous actions)는 다음과 같다.

1. Trajectory representation
Transformer는 의미 있는 패턴을 학습할 수 있어야하고, Test할 때, 조건부로 Action을 생성할 수 있어야한다. 또한, 모델이 미래의 Rewards를 기반으로 Actions를 생성하기를 원하기 때문에 Reward를 Modeling하는 것은 중요하지 않다. 따라서 우리는 모델에 Return-to-go를 넣어준다.
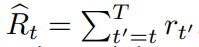
그리고 Trajectory representation은 다음과 같다.
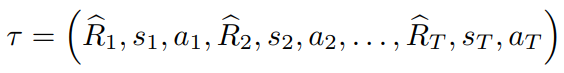
Test를 할 때에는 Environment의 Starting State와 원하는 Performance(성공(1) or 실패(0))를 미리 정할 수 있다. 그리고, 현재 State에 따른 Action을 실행한 후 받은 Reward만큼 Target Return을 줄여나가는 것을 Episode 종료 시까지 반복한다.
2. Architecture
논문에서 설명하는 Decision Transformer의 Architecture는 아래 그림과 같다.
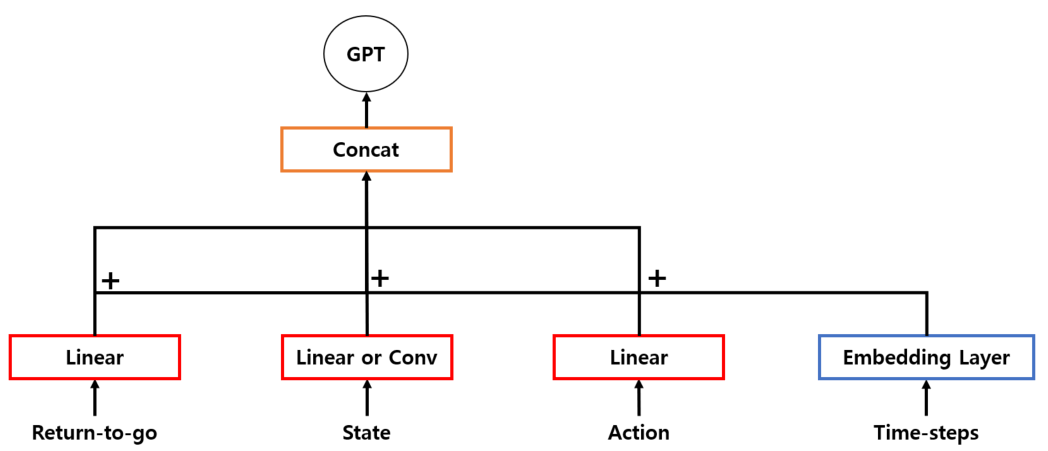
모델의 입력은 K time-steps만큼의 Return-to-go, State, Action, Time-step index로 구성된다.
각 토큰들의 Embedding을 위해서는 Linear layer를 학습하며, 이미지 입력이 있는 경우에는 Convolution Encoder를 사용한다.
또한, 각 Time-steps에 대한 Embedding이 학습되고, 각 토큰에 추가된다. 여기서 Time-stpe에 대한 Embedding은 기존 Transformer의 Positional embedding과 다른, 세 개의 토큰에 대응되는 하나의 Time-step에 대한 것이다.
이 후, 토큰들은 GPT 모델에 의해 처리되며, 이 모델은 Autoregressive modeling을 통해 미래의 Action을 예측한다.
3. Training
Offline trajectories에 대한 Dataset이 제공된다. 그리고 Dataset에서 K 길이 만큼의 Mini-batches를 샘플링한다.
입력 토큰의 s(t)에 해당하는 예측 토큰 a(t)는 이산 Action일 경우에는 Cross-entropy loss, 연속 Action일 경우에는 Mean-squared-error로 예측하도록 훈련되며 각 Time-step의 loss는 평균화하여 최종 loss로 계산한다.
Evaluations on Offline RL Benchmarks
이 논문에서는 이산 제어 작업(Atari 게임)과 연속 제어 작업(Open AI Gym) 모두를 평가한다.
Atari 게임은 고차원의 Observation spaces를 포함하고, Long-term credit assignment를 요구하는 반면에, Open AI Gym은 연속 제어를 요구하여 다양한 Task set를 나타낸다.
1. Atari
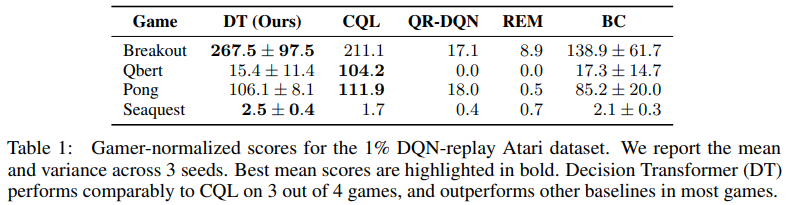
Atari 환경에서는 Breakout, Qbert, Pong, Seaquest에서 Benchmark를 진행했으며, 비교군으로는 CQL, REM, QR-DQN, BC를 사용했다. Qbert에서는 SOTA인 CQL에 많이 뒤쳐졌지만, 다른 환경에서는 비슷한 성능을 낸 것을 알 수 있다.
2. Open AI Gym
-
Medium : Expert policy의 1/3정도 점수에 도달한 Medium policy로 생성된 100만개의 time-step
-
Medium-Replay : Medium policy로 학습된 Agent의 Replay-buffer (25K-400K)
-
Medium-Expert : Medium으로 생성된 100만개의 time-step과 Expert policy로 생성된 100만개의 time-step을 함께 사용
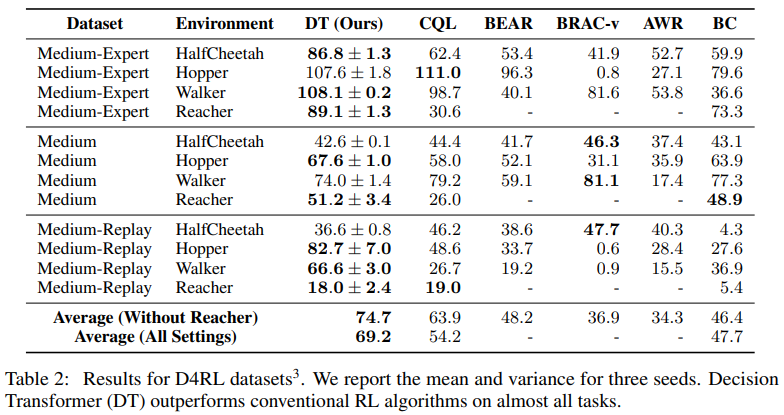
Open AI 환경에서는 HalfCheetah, Hopper, Walker, Reacher에서 Benchmark를 진행했으며, 비교군으로는 CQL, BEAR, BRAC-v, AWR, BC를 사용했다. 거의 모든 환경에서는 비슷한 성능을 낸 것을 알 수 있다.
- 비교군으로 사용한 알고리즘들의 참고 문헌 -
- CQL
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020. - BEAR
Aviral Kumar, Justin Fu, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. arXiv preprint arXiv:1906.00949, 2019. - BRAC-v
Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019. - AWR
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression : Simple and scalable off-policy reinforcement learning. arXiv preprint arXiv:1910.00177, 2019. - REM
Rishabh Agarwal, Dale Schuurmans, and Mohammad Norouzi. An optimistic perspective on offline reinforcement learning. In International Conference on Machine Learning, 2020. - QR-DQN
Will Dabney, Mark Rowland, Marc Bellemare, and Rémi Munos. Distributional reinforcement learning with quantile regression. In Conference on Artificial Intelligence, 2018.
Discussion
1. Does Decision Transformer perform behavior cloning on a subset of the data?
- Behavior Cloning(BC)란?[5]
-> 전문가의 플레이에서 (State, Action)을 무작위로 꺼내온 다음 주어진 State에 맞는 정답인 Action을 잘 맞추도록 학습하는 것을 말한다.
(강화학습 문제를 기존의 머신 러닝 문제를 푸는 방식으로 생각하는 것.)
-> 이 논문에서는 Dataset의 전체 중 (10%, 25%, 40%, 100%)의 Data를 사용하여 위처럼 학습된 모델을 가져와 게임을 플레이한 결과를 비교 대상으로 가져왔다.
-> "100%BC"는 모든 Dataset을 사용한 것이다.
Open AI Gym
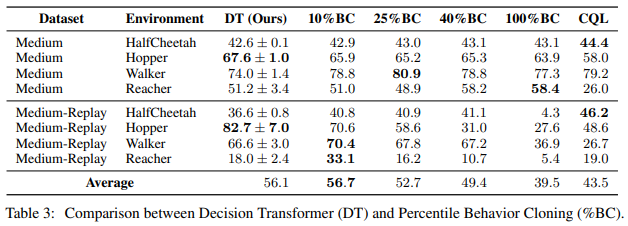
- Environment는 Open AI Gym에서 제공되는 HalfCheetah, Hopper, Walker, Reacher를 사용했다.
- Percentile Behavior Cloning(%BC)와 CQL을 비교 데이터로 사용했다.
- 이 Test는 Open AI Gym과 같이 데이터가 충분할 때, Decision Transformer가 %BC보다 성능이 높고 일반화 능력이 좋다는 것을 시사한다.
Atari
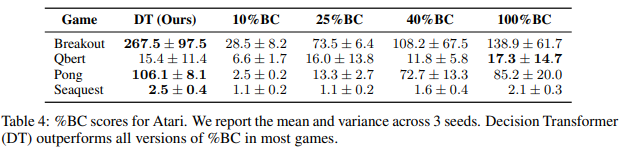
- Atari에서 제공되는 Breakout, Qbert, Pong, Seaquest를 사용했다.
- Percentile Behavior Cloning(%BC)을 비교 데이터로 사용했다.
- 이 Test는 Atari와 같이 데이터가 불충분할 때, Decision Transformer가 Imitation learning보다 효과적이라는 것을 시사한다.
2. How well does Decision Transformer model the distribution of returns?
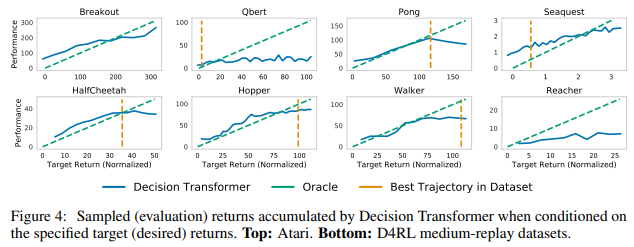
- 위 그래프는 Target return 값에 따라 Agent가 획득한 누적 Return 값을 나타내며 둘은 높은 상관관계를 보이는 것을 알 수 있다.
- 또한, 데이터의 분포를 잘 학습했지만, Dataset 최고 성능 이상의 Return을 조건으로 주었을 때는 한계를 갖는 것을 확인했다.
3. What is the benefit of using a longer context length?
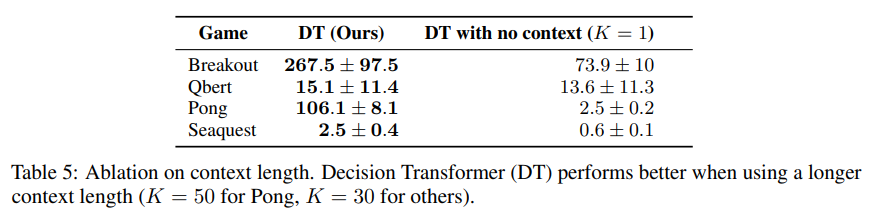
- K 값에 대한 중요성을 보기 위한 실험이다.
- K = 1, 즉 바로 직전의 상태만을 보았을 때보다 여러 번의 상태를 Input으로 넣었을 때, 더 좋은 결과를 가지는 것을 보여준다.
4. Does Decision Transformer perform effective long-term credit assignment?
- 이 절에서는 Long-term credit assignment 능력을 평가하기 위해 Key-to-Door류의 환경을 사용하여 평가했다.

- 위 표는 Random Trajectory로 생성한 Dataset으로 모델들을 학습시킨 결과이며, Decision Transformer와 %BC는 효과적인 Policy를 학습할 수 있었으나, CQL과 BC는 좋은 결과를 얻지 못했다.
- Key-to-Door 환경이란?
-> 첫번째 단계에서 Agent는 열쇠가 있는 방에 배치가 된다.
-> 그런 다음 Agent는 빈 방에 배치가 된다.
-> 마지막으로, Agent는 문이 있는 방에 배치된다.
Agent는 세 번째 단계에서 문에 도달했을 때, 이진 보상을 받게 된다. 만약 첫번째 단계에서 Key를 집어들지 않았다면 보상을 받지 못한다.
이 문제는 중간에 취해진 행동을 건너뛰고, Episode 시작부터 끝까지 Credit이 전파되어야하므로 Credit assignment가 어렵다.
5. Can transformers be accurate critics in sparse reward setting?
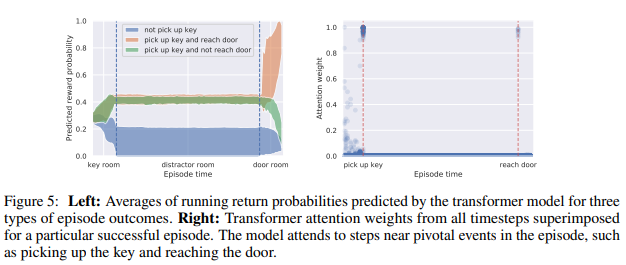
- 위 그래프는 Episode 중 Event를 기반으로 보상 확률을 지속적으로 업데이트한다는 것을 발견했다.
- 또한, Transformer의 Attention weight가 중요한 Event에서 높은 것을 발견할 수 있었다.
6. Does Decision Transoformer perform well in sparse reward settings?
- TD Learning의 약점은 우수한 성과를 내기 위해 밀집된 보상이 필요하다는 것인데, 이는 비현실적이거나 비용이 많이 들 수 있다.
- 이와 대조적으로, Decision Transformer는 보상의 밀도에 대해 최소한으로 가정을 하기 때문에 이러한 설정에서 견고성을 개선할 수 있다.
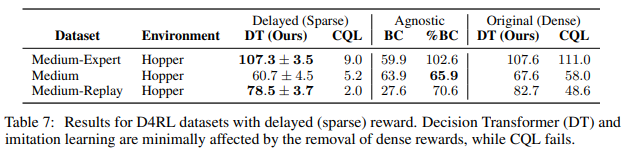
- 위 Table에서 Delayed(Sparse)는 Hopper Env에서 보상을 주지 않다가 마지막 Time step에 몰아서 주도록 설정(Sparse)한 것인데 이 때, Robust한 결과를 얻을 수 있었다.
- BC는 학습 방법 상 Rewards와 무관하다.
7. Why does Decision Transformer avoid the need for value pessimism of behavior regularization?
- Decision Transformer와 과거 Offline RL과의 주요 차이점은 우수한 성능을 달성하기 위해 Policy regularization과 conservatism이 필요하지 않다는 것이다.
- Decision Transformer가 Policy regulariation과 conservatism이 필요하지 않은 이유는 학습된 Functions을 목표로 하는 최적화가 필요하지 않기 때문이다.
8. How can Decision Transformer benefit online RL regimes?
- Offline RL과 행동을 모델링하는 능력은 Downstream tasks에 대해 sample-efficient online RL을 가능하게 할 수 있는 잠재력을 가지고 있다.
- 이 논문에서는 Offline RL을 연구했지만, Decision Transformer는 Behavior generation을 위한 강력한 모델의 역할을 함으로써 Online RL 방법을 의미있게 개선할 수 있을 것이라 저자들은 믿고 있다.
Conclustion
- Decision Transformer는 Standard language modeling architectures의 최소한의 수정으로 Standard offline RL benchmarks에서 우수한 성능을 보여주었다.
- Returns, States, Actions에 대한 보다 정교한 Embedding을 고려할 수 있다.
- Transformer 모델을 사용하여 Trajectory의 State evolution을 모델링할 수 있으며, Model-based RL의 대안으로 작용할 수 있다.
- Real-world applications의 경우, Transformer가 MDP 설정에서 발생되는 오류와 탐색되지않는 Possible negative consequences를 이해하는 것이 중요하다. 따라서 Destructive biases를 추가할 수 있는 모델을 훈련하는 Dataset도 고려해야한다.
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez,Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 2017.
(https://arxiv.org/abs/1706.03762)
[2] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.(https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf)
[3] https://ichi.pro/ko/nlpui-mlm-gamyeon-eon-eo-model-mich-clm-ingwa-eon-eo-model-ihae-1738411038373
