이 글은 논문 Palette: Image-to-Image Diffusion Models (2022) 에 대한 설명입니다. 논문 원본에 대한 링크는 아래에 적어놓았습니다.
논문 원본 : https://arxiv.org/abs/2111.05826
Abstract
- 본 논문은 Conditional diffusion model을 기반으로 Image-to-Image 변환을 위한 프레임워크를 개발함
- Image-to-Image 변환의 Task 중 Colorization, Inpainting, Uncropping, JPEG restoration에 대해 실험을 진행
- Image-to-Image diffusion model은 하이퍼 파라미터 조정 등과 같은 정교한 기술 없이도 모든 Task에서 GAN과 Regression baseline을 능가한다.
- L2 vs L1 loss가 샘플 다양성에 미치는 영향을 발견하고, 신경망에서 Self-attention의 중요성을 입증함
- Multi-task diffusion model의 성능이 작업별 전문가 모델보다 성능이 우수한 것을 보여줌
1. Introduction
- Vision과 이미지 처리의 많은 문제는 Image-to-Image 변환으로 공식화할 수 있다.
- 이미지 분야의 많은 Task들은 그림 1과 같이 다수의 출력 이미지가 하나의 입력 이미지로부터 나오게 된다.

- Diffusion 모델은 최근 관심이 높아졌으며, 음성 합성에서 SoTA를 능가했다.
- Class-conditional ImageNet 생성 과제에서는 FID 측면에서 GAN을 능가했다.
- 이미지 초해상도에서도 GANs를 능가하는 결과를 제공했다.
- 이러한 결과에도 불구하고, Diffusion 모델이 이미지 조작을 위한 다재다능하고 일반적인 프레임워크를 제공하는 GAN과 경쟁하는지는 명확하지 않다.
- 본 논문에서는 Image-to-Image Diffusion 모델의 구현인 Palette이 Colorization, Inpainting, Uncropping, JPEG restoration 문제들에서의 적용 가능성을 확인한다.
- Palette는 Denoising loss function으로는 L2, L1 Loss를 사용했으며, Palette의 U-Net 아키텍처에서 self-attention을 제거했을때 결과가 안좋아지는 것을 확인했다.
2. Related work
- 논문 참조
3.Palette
- Image-to-Image Diffusion 모델은 p(y|x) 형태의 Conditional diffusion 모델로, x는 Gray scale이고, y는 RGB 이미지이다.
- y = Target image
- ŷ = Noisy image
- γ = Noise level indicator
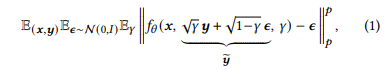
- L1 loss는 L2 loss에 비해 훨씬 낮은 샘플 다양성을 산출한다는 것을 발견했지만, 일부에서 잠재적인 Hallucinations를 줄이기 위해, 출력 분포를 더 충실하게 포착하는 L2 loss를 채택한다.
- 네트워크 구조는 Conditional U-Net 아키텍처를 몇가지 수정하여 사용한다.
- 본 논문의 네트워크 구조와 이전 구조와의 차이점은 Class-conditioning의 부재와 연결을 통한 Source 이미지의 추가 조절이다.
4. Evaluation protocol
- Image-to-Image 변환 모델을 평가할 때,
- Colorization = FID 점수
- Inpainting = 정성 평가
- JPEG restoration = PSNR, SSIM 등과 같은 픽셀 수준의 유사성 점수를 사용
- 본 논문에서는 ImageNet에서 Inpainting, Uncropping, JPEG restoration을 위한 통합 평가 프로토콜을 제안한다.
- Places2의 표준 평가 설정을 사용한다. 구체적으로 ImageNet ctest 10k 분할을 ImageNet에서 모든 이미지 간 변환 작업의 벤치마킹을 위한 표준 하위 집합으로 사용할 것을 지지한다.
- 또한, Places10k라고 하는 Places2 검증 세트에 유사한 이미지 집합을 소개한다.
- 본 논문에서는 사람 평가 외에도 이미지 품질과 다양성을 모두 포착하는 자동화된 매트릭을 사용하며, PSNR과 SSIM과 같은 픽셀 수준 매트릭은 사용하지 않는다.
- PSNR과 SSIM을 사용하지 않는 이유
- Super-resolution 작업과 같이 어려운 작업에 대해서 신뢰할 수 있는 표본 품질의 측정 기준이 아님
- PSNR과 SSIM을 사용하지 않는 이유
- 정량적인 평가
- FID
- Pre-trained ResNet-50 분류기의 분류 정확도
- Inception-v1 feature space의 유클리드 거리의 간단한 측정
- 정성적인 평가
- "어떤 이미지가 원본이미지인가?"라는 질문을 받았을 때, 모델의 출력을 선택하는 인간 평가자의 비율
5. Experiments
- 모든 작업에 대한 입력과 출력은 256x256의 RGB 이미지로 표현된다.
- 따로 명시되지 않는 한 Palette는 L2 loss를 사용한다.
5.1 Colorization
"Gray scale의 이미지를 Input으로 받아 Color 이미지로 변환"
- 본 논문에서는 RGB 색 공간을 사용하여 작업 전반에 걸쳐 일반성을 유지하며, 예비 실험은 Pallete가 YCbCr과 RGB 공간에서 동등하게 효과적이라는 것을 보여주었으며, Pix2Pix, PixColor, ColTran과 Pallete를 비교한다.

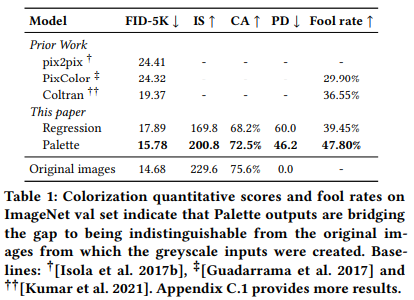
- Pallete는 새로운 SoTA를 구축했으며, 성능 측정 결과, 원래 이미지와 거의 구별되지 않는 것을 알 수 있다.
- 인간 평가에서는 인간 평가자의 ColTran fool rate보다 10% 향상되어 이상적인 Fool rate인 50%에 근접한 것을 알 수 있다.
5.2 Inpainting
"사용자가 지정한 마스크된 이미지 영역을 사실적인 내용으로 채우는 것"
5.3 Uncropping
"입력 이미지를 하나 이상의 방향을 따라 확장하여 이미지를 확대"
5.4 JPEG restoration
"JPEG compression artifacts를 수정하여 그럴듯한 이미지 세부 정보를 복원"
5.5 Self-attention in diffusion model architectures
5.6 Sample diversity
5.7 Multi-task learning
Conclusion

기억하고 싶은 것들 모음.zip