Spring Data Access 요약
Spring Framework에서의 데이터 액세스는 JDBC, JPA, Hibernate, Spring Data JPA 등의 다양한 기술을 통합하여 데이터베이스와의 상호작용을 간편하고 효율적이게 만든다. 아래는 전체적인 흐름을 나타내는 그림이다.
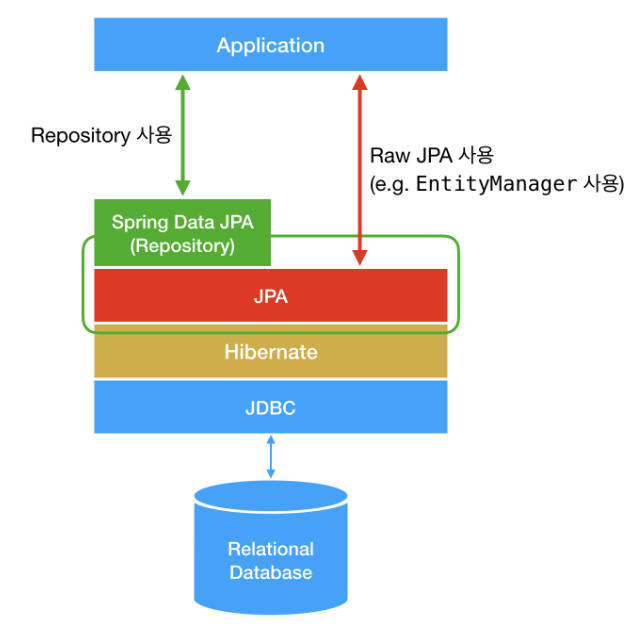
스프링을 사용하여 프로젝트를 진행하면 자연스럽게 위의 기술들을 사용하게 되고, 특히 Spring Data JPA의 사용에 의존하게 되는 경우가 많다. 하지만 단순히 사용하는 것 만으로는 작업의 구체적인 흐름을 인식할 수 없고, 각 키워드를 식별하거나, 그들 간의 관계를 이해하기 어려워진다. 지금부터 아래의 키워드를 통해, 단계적으로 스프링의 데이터 엑세스를 정복해보자.
- JDBC (Java Database Connectivity)
- ORM (Object Relational Mapping)
- JPA (Java Persistence API)
- Spring Data JPA
- Hibernate
1. JDBC (Java Database Connectivity)
JDBC(Java Database Connectivity)는 Java 언어에서 데이터베이스에 연결하고 SQL 쿼리를 실행할 수 있도록 하는 API이다. JDBC의 핵심은, DBMS(Oracle, MySQL 등)의 종류에 상관 없이 하나의 JDBC API를 이용해서 데이터베이스 작업을 처리한다는 점이다.
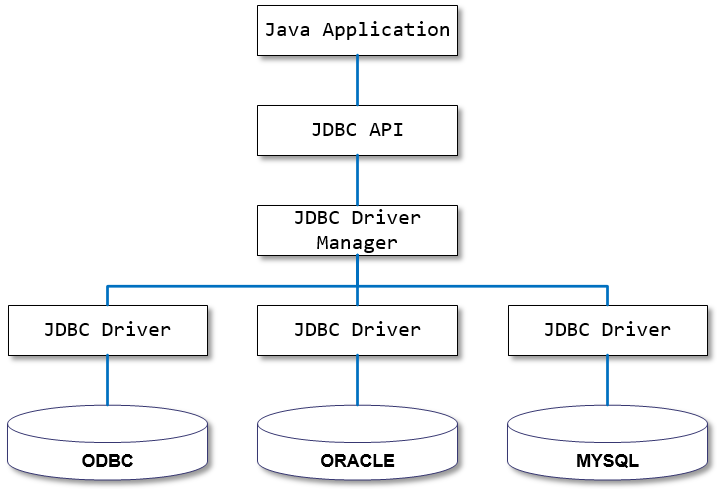
데이터베이스의 종류에 따라 SQL문의 작성 문법은 달라진다. 만약 JDBC가 없다면, 데이터베이스의 종류에 따라 SQL을 실행하는 방법(메서드)을 다르게 구현해야 한다는 번거로움이 따른다.
위의 그림을 보면, JDBC API는 JDBC Driver Manager을 통해 설정한 데이터베이스에 맞는 드라이버를 사용하여 데이터베이스에 접근한다는 사실을 알 수 있다. JDBC는 인터페이스, 각 데이터베이스 드라이버는 인터페이스를 구현한 구현체이다.
인터페이스와 구현체
Spring 보다는 Java와 관련된 개념이지만, 내용의 이해를 위해 가볍게 짚고 넘어가야 할 필요가 있다. 인터페이스는 클래스가 가져야 할 메소드와 속성을 정의한 틀로, 실제 구현은 없다. 구현체는 인터페이스에서 정의한 메소드와 속성을 실제로 작성한 클래스이다.
2. ORM (Object Relational Mapping)
ORM(Object-Relational Mapping)은 말 그대로 객체 지향 프로그래밍 언어에서 객체(Object)와 관계형 데이터베이스(Relational Database) 간의 매핑을 자동으로 처리하는 기술이다.
관계형 데이터베이스란?
관계형 데이터베이스(Relational Database)는 데이터를 테이블 형태로 구성하여 저장하고 관리하는 데이터베이스 시스템으로, 이러한 테이블들은 행과 열로 이루어져 있다. MySQL, Oracle 등이 RDBMS(Relational Database Management System)의 대표적 예시이다.
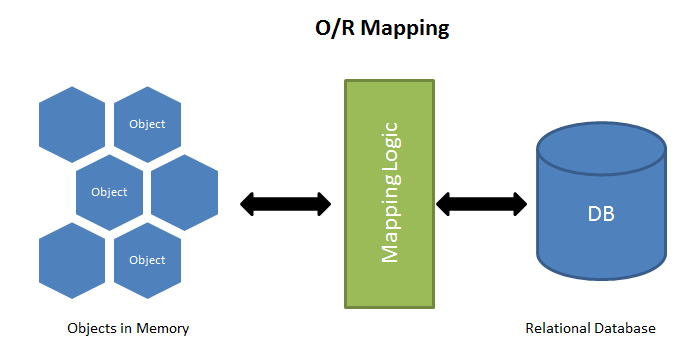
ORM이 유용한 이유는 무엇일까? 객체 지향 언어인 JAVA는 복잡한 객체 구조(상속, 다형성 등)를 관리하지만, 이를 관계형 데이터베이스에 저장하고 관리하는 것은 쉽지 않다.
객체의 상태나 정보가 변경될 때마다 데이터베이스 스키마를 수정해주고, 각 작업을 수행할 때마다 SQL 쿼리를 작성하는 것은 매우 번거롭고, 개발자로 하여금 실수를 유발한다. ORM은 자바 객체와 데이터베이스 테이블 간의 매핑을 통해, 객체를 조작함으로써 데이터베이스를 조작할 수 있게 한다.
이러한 ORM 기술을 사용하기 위한 인터페이스가 바로 JPA(Java Persistence API)이다. JPA에 대한 설명 부분에서 ORM 기술의 구체적인 예시를 살펴보자.
3. JPA (Java Persistence API)
JPA(Java Persistence API)는 자바 플랫폼에서 ORM을 구현하기 위한 표준 API이다. 말 그대로 JPA는 ORM을 구현하기 위한 표준 인터페이스인데, JPA 인터페이스를 구현한 구현체 중 하나가 Hibernate인 것이다. Hibernate에 대한 구체적인 설명은 이후에 진행하고, 먼저 JPA를 알아보자.
JPA를 사용하는 이유는 ORM 파트에서 이미 설명하였다. 객체 지향 언어와 관계형 데이터베이스의 패러다임 불일치를 해결하기 위해 JPA를 사용하는 것인데, 여기서는 실제 코드 예시를 살펴보도록 하겠다.
@Entity
public class User {
@Id // 해당 필드가 엔티티의 기본 키(primary key)
@GeneratedValue(strategy = GenerationType.IDENTITY) // 기본 키 값 자동 생성
private Long id;
private String name;
private String email;
// getters and setters
}위의 예시에서, User 클래스는 데이터베이스의 user 테이블과 매핑된다. @Entity 어노테이션은 JPA에게 이 클래스가 데이터베이스 테이블과 매핑된 엔티티임을 알려준다. JPA는 기본적으로 클래스 이름을 사용하여 테이블 이름을 추론하는데, @Table(name = "users")와 같이 직접적으로 작성할 수도 있다.
@Repository
@RequiredArgsConstructor
public class UserRepository {
// 엔티티 매니저 주입
private final EntityManager em;
// User 엔티티 저장 메소드
public void save(User user) {
em.persist(user); // 새로운 엔티티를 데이터베이스에 저장
}
// User 엔티티 삭제 메소드
public void remove(Long id) {
em.remove(findById(id)); // 엔티티를 기본 키로 찾아서 삭제
}
// 모든 User 엔티티 조회 메소드
public List<User> findAll() {
// JPQL을 사용하여 모든 User 엔티티 조회
return em.createQuery("SELECT u FROM User u", User.class)
.getResultList();
}
}
리포지토리는 데이터베이스와 상호작용하는 메소드를 제공하는 인터페이스다. JPA에서는 리포지토리를 통해 데이터베이스 CRUD(Create, Read, Update, Delete) 작업을 수행한다. 위의 예시에서 findAll 기능의 경우 지원하는 메소드가 없기에,SELECT u FROM User u와 같이 JPQL을 작성해야 한다.
JPQL이란?
JPQL(Java Persistence Query Language)은 JPA의 표준 쿼리 언어로, SQL과 유사하지만 데이터베이스 테이블이 아닌 엔티티 객체를 대상으로 쿼리를 수행한다. 즉, 객체 지향적 데이터베이스 쿼리를 작성하기 위해 사용된다.
EntityManager는 JPA에서 엔티티의 생명주기를 관리하고, 데이터베이스와 상호작용을 담당하는 핵심 인터페이스이다. EntityManager를 통해 엔티티를 데이터베이스에 저장, 수정, 삭제할 수 있으며, JPQL 쿼리를 실행할 수도 있다. 예시의 persist, remove등은 EntityManager의 주요 메소드이다.
그렇다면 JDBC를 왜 쓰는가? JPA가 더 좋아보이는데?
위의 문장은 근본적으로 틀렸다. JPA를 사용하면 직접 SQL 쿼리를 작성하지 않고도 데이터베이스와 상호작용할 수 있지만, JPA가 내부적으로 JDBC를 사용하여 SQL 쿼리를 실행하기 때문이다. 즉, JPA 또한 데이터베이스와의 통신을 위해 JDBC를 사용한다.
또한, 쿼리를 적지 않는다는 점에서 무조건 JPA가 좋은 것도 아니다. 성능 최적화와 SQL 제어가 중요한 경우, 직접적으로 쿼리를 작성하는 JDBC가 유리할 수 있다. 반면, 객체 지향적인 접근과 복잡한 객체 관계 매핑이 필요한 경우 JPA가 유리하다고 할 수 있다.
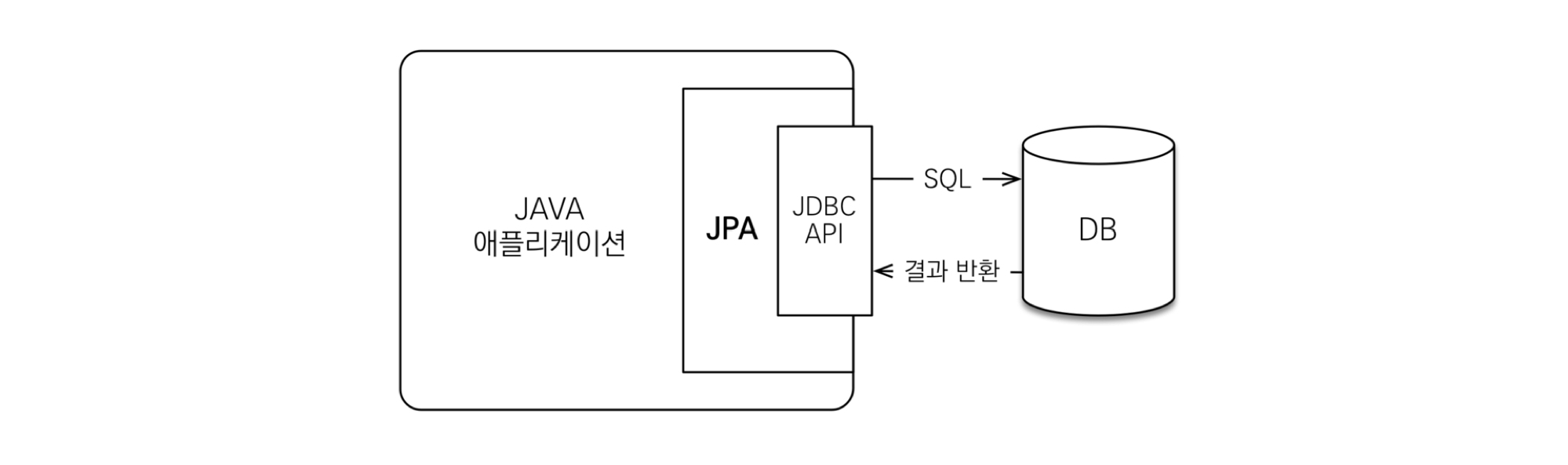
4. Spring Data JPA
Spring Data JPA는 Spring에서 제공하는 모듈 중 하나로, JPA를 한 단계 추상화시킨 Repository라는 인터페이스를 제공한다.
실제로 스프링으로 프로젝트를 진행하며 JPA를 사용한 경험이 있는 사람들은, 위의 JPA 사용 예시에 위화감을 느낄 수 있다. EntityManager가 어색하고, 아래의 Repository 형태가 익숙하다면 Spring Data JPA를 사용한 것이다.
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
//기본적인 CRUD는 자동 제공, 메소드 추가 가능
}위의 코드에서 UserRepository 인터페이스는 JpaRepository를 확장하여 기본적인 CRUD 메소드를 자동으로 상속받는다. JpaRepository<User, Long>에서 User는 엔티티 클래스이고, Long은 기본 키의 타입이다. 아래는 Spring Data JPA 사용 시, UserService 클래스의 예시이다.
@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
// User 엔티티 저장 메소드
public User save(User user) {
return userRepository.save(user); // 새로운 엔티티를 데이터베이스에 저장
}
// User 엔티티 삭제 메소드
public void remove(Long id) {
userRepository.deleteById(id); // 엔티티를 기본 키로 찾아서 삭제
}
// 모든 User 엔티티 조회 메소드
public List<User> findAll() {
return userRepository.findAll(); // 모든 User 엔티티 조회
}
}위의 UserService 클래스는 UserRepository를 주입받아 userRepository.save(), userRepository.deleteById(), userRepository.findAll() 메소드를 사용하고 있다. 단순 JPA 사용 예시와 비교해보면, Repository에 메소드를 선언하지 않았음에도 기본적인 CRUD 메소드를 전부 사용할 수 있다는 것을 알 수 있다.
이처럼 Spring Data JPA에서는 사용자가 Repository 인터페이스에 규칙에 맞는 메소드 이름을 작성하기만 하면, Spring이 자동으로 그 메소드에 맞는 쿼리를 만들어준다. 그리고 이 구현된 리포지토리 빈(Bean)을 스프링 컨테이너에 등록해준다.
예를 들어, findByName(String name)이라는 메소드를 작성하면, Spring이 이 메소드에 맞는 SELECT * FROM user SQL 쿼리를 생성하여 실행한다.
사실 Spring Data JPA Repository의 구현에서는 JPA를 사용하고 있고, EntityManager가 사용된다. 이처럼 Spring Data JPA는 JPA를 추상화하여 JPA 기반 애플리케이션 개발을 보다 간편하게 만들어주는 모듈이다.
5. Hibernate
이전에 언급한 바와 같이, Hibernate는 JPA 인터페이스의 구현체이다. JPA는 ORM을 구현하기 위한 표준 API, 명세를 의미한다고 설명하였다. 따라서 JPA를 사용하려면 JPA를 구현한 ORM 표준 프레임워크를 선택해야 하는데, 현재 가장 대중적인 ORM 프레임워크가 Hibernate이다.
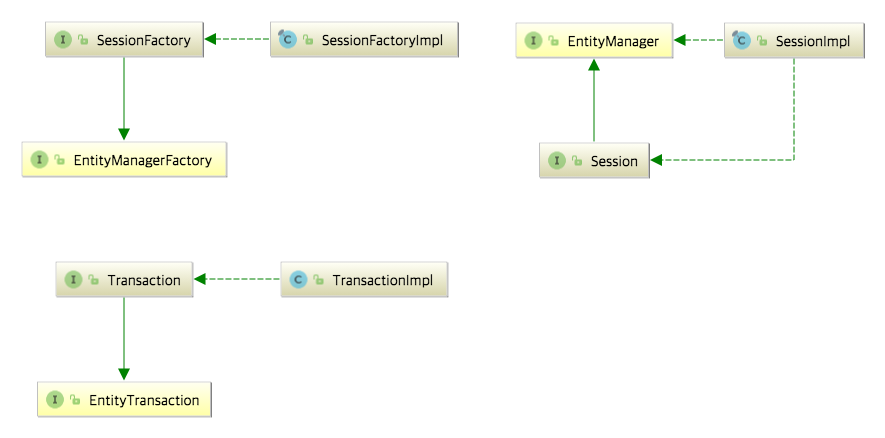
위의 다이어그램을 통해, JPA의 핵심 요소인 EntityManagerFactory, EntityManager, EntityTransaction이 Hibernate에서는 각각 SessionFactory, Session, Transaction으로 상속받아 사용되며, 이들이 각각 구현체(Impl)로 제공됨을 확인할 수 있다.
Hibernate는 JPA의 구현체일 뿐, JPA를 사용하기 위해 반드시 Hibernate를 사용할 필요는 없다. Hibernate 대신 다른 JPA 구현체(EclipseLink, OpenJPA 등)를 사용할 수 있지만, Hibernate는 가장 대중적이고, 그만큼 성숙한 ORM 프레임워크이기에 그럴 필요성은 적다.
Hibernate의 사용이 필수가 아니라는 점에서 복기할 수 있는 스프링의 특징은? 바로 PSA(Portable Service Abstraction, 일관된 서비스 추상화)이다. Hibernate라는 특정 기술을 사용하더라도 표준 인터페이스인 JPA를 통하기에, 코드 변경 없이도 구현체의 변경이 가능하고, 따라서 기술에 대한 종속성이 없다고 할 수 있다.
