이전 글에서는 Paging의 성능상 문제점을 개선하는 TLB에 대해서 알아봤다. 이번 글에서는 Paging의 또다른 문제점인 메모리 공간 차지와, 그 해결 방법에 대해 알아보도록 하자.
1. Page Table 크기
이전부터 Page Table의 크기가 크다는 점은 지속적으로 언급했지만, 얼마나 큰 것인지 간단하게 먼저 알아보자.
위의 그림에서는 한 페이지의 크기가 4KB이고, 주소 공간이 32bit인 경우를 보여주고 있다. 한 페이지의 크기가 4KB이므로, 주소 공간에서 Offset은 12bit가 되고(), 각 페이지를 식별하는 VPN은 20bit가 된다.
하나의 페이지 테이블 엔트리의 크기가 4B라고 할 때, 페이지 테이블의 크기를 계산해보자.
계산 결과, 4MB가 나온 것을 볼 수 있다. 만약 현재 프로세스가 100개라면 400MB가 될 것이고, 페이지 테이블의 크기가 이렇게 크기 때문에 CPU 내부의 MMU에 저장할 수 없는 것이다!
그렇다면, 지금부터 페이지 테이블의 크기를 줄이는 방법은 어떤 방법이 있을지 알아보자.
2. Simple Solution: Bigger Pages
위의 계산 과정을 살펴보면, 각각의 페이지의 크기를 크게 하면 되지 않을까? 라고 단순히 생각할 수 있다. 각각의 페이지의 크기가 늘어남에 따라, 페이지의 개수는 줄어드니까! 단순한 예시를 보자.
이전에는 각각의 페이지의 크기를 4KB로 책정했지만, 이번에는 그 4배인 16KB로 바꿨다. 그 결과, Offset은 14bit로 변하고, VPN은 18bit로 변하게 되어, 결과적으로 각 프로세스 당 페이지 테이블의 크기는 1MB로 줄게 되었다.
하지만 조금만 생각해봐도 이는 좋은 방법이 아니다. 왜? 무작정 페이지의 크기를 늘려버리면, 우리가 잊고 있었던 또 하나의 문제인 Internal Fragmentation이 악화되기 때문이다! (큰 페이지 내부에 사용되지 않고 낭비되는 부분이 많아진다.)
3. Hybrid Approach: Paging and Segments
1) Hybrid Approach
하이브리드 방식은 이전 글에서 다뤘던 세그먼트 방식과 페이징을 결합한 것이다. 세그먼트 방식에서는 Base 레지스터가 세그먼트의 물리 주소를 가리켰던 것을 기억하는가? 하이브리드 접근법에서는 Base 레지스터가 세그먼트를 직접 가리키는 대신, 해당 세그먼트에 대한 페이지 테이블의 물리적 시작 주소를 저장한다. 유사하게, Bounds 레지스터는 페이지 테이블의 끝을 가리키게 된다. 또한, 페이지 테이블은 code, heap, stack과 같이 세그먼트 단위로 나뉘어 관리된다.
그렇다면 이러한 방법이 어떻게 페이지 테이블의 크기를 줄일 수 있는 것일까? 그림을 통해 알아보자.
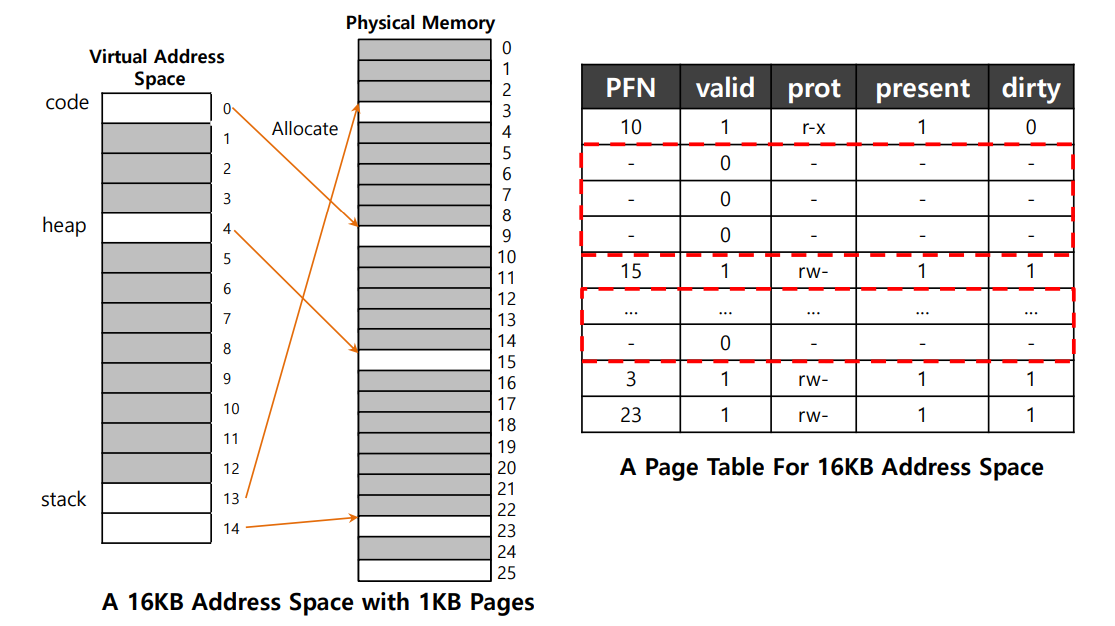
예시의 프로세스는 code, heap, stack 영역을 합해 단 4개의 페이지만 사용하고 있지만, 이를 관리하기 위해 16개의 페이지 테이블을 사용하고 있는 것을 볼 수 있다!
잘 생각해보면, 이는 이전에 다뤘던 Base & Bounds의 Internal Fragmentation 문제와 유사하다는 점을 알 수 있다. 해당 문제를 해결하기 위해 세그먼트 방식을 사용한 것처럼, 페이지 테이블 또한 세그먼트 단위로 나눌 수 있게 되는 것이다. 아래의 그림을 보자.
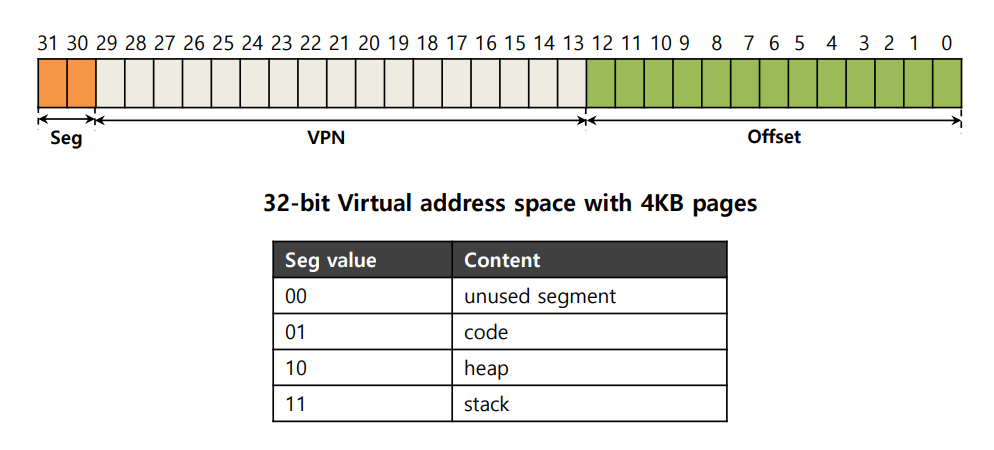
주목해서 볼 부분은 맨 앞의 Seg 비트이다. 01은 code, 10은 heap, 11은 stack으로 식별하여, 한 프로세스 당 세그먼트 별로 3개의 페이지 테이블을 할당받게 된다. 하드웨어는 Seg 비트에 따라 어떤 Base & Bounds 페어를 사용할지 결정하게 된다.
이제 하이브리드 방식이 어떻게 페이지 테이블의 크기를 줄이는지 요약해보자. 하나의 프로세스에서 비효율적으로 페이지 테이블을 할당받는 상황을 해결하기 위해, 통째로 하나의 페이지 테이블을 할당하는 대신 code, heap, stack의 세그먼트별로 3개의 페이지 테이블을 할당하고, Base & Bounds 레지스터를 사용하여 각 세그먼트 페이지 테이블이 실제로 점유하고 있는 메모리의 경계를 저장하였다. 결과적으로, 현재 사용되지 않는 엔트리만큼 메모리 공간을 절약할 수 있게 된 것이다!
2) Hybrid Approach 단점
-
만약 이후 사용될 것을 대비하여, 특정 프로세스가 큰 크기의 heap을 할당받은 이후 거의 사용하지 않는다면 또다시 메모리 낭비가 발생한다.
-
세그먼트마다 페이지 테이블을 별도로 관리하기 때문에, 세그먼트들 사이에 메모리 공간이 고르게 분포되지 않을 수 있고, 이는 External Fragmentation을 유발한다.
4. Multi-level Page Tables
1) Multi-level Page Tables
하이브리드 방식은 한계가 명확하기 때문에, 페이지 테이블의 크기를 줄이기 위한 다른 방법이 필요하게 되었다.
Multi-level Page Tables는, 페이지 테이블을 트리와 같은 계층 구조로 표현하는 것이다! 아래의 그림을 보자.
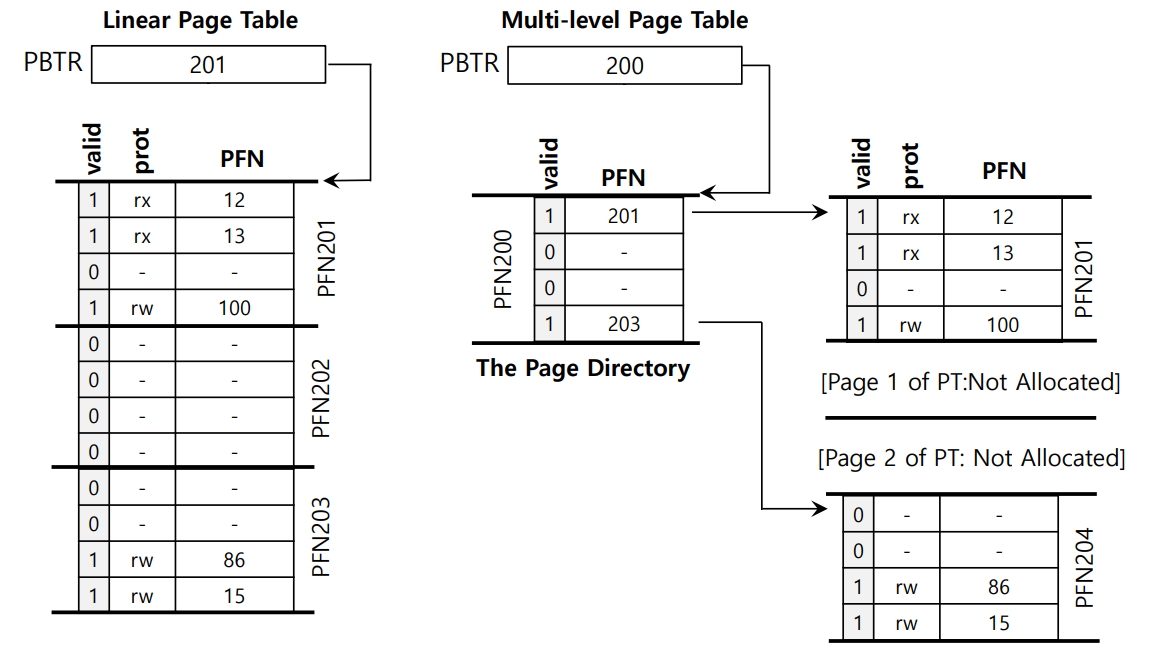
그림과 같이 선형 페이지 테이블을 트리 구조처럼 변형하면, 페이지 테이블의 특정 페이지가 모두 무효(유효하지 않은 페이지 테이블 항목)라면, 해당 페이지 테이블 페이지를 아예 할당하지 않을 수 있다.
페이지 테이블이 여러 레벨로 나누어지기 때문에 각 레벨이 유효한지 추적해야 하는데, 이를 위해 Page Directory라는 새로운 자료 구조가 사용된다. 페이지 디렉토리는 여러 개의 Page Directory Entry로 구성되고, 각 페이지 디렉토리 엔트리는 해당 PFN이 유효한지 추적하는 valid 비트를 갖고 있다.
2) Multi-level Page Tables: Advantage & Disadvantage
Advantage
-
필요한 만큼만 페이지 테이블 공간을 할당하여 메모리 낭비를 줄일 수 있다.
-
운영체제는 페이지 테이블이 더 필요하거나 확장해야 할 때마다 동적으로 빈 페이지를 할당할 수 있다. (단순히 현재 Page Directory의 valid bit이 0인 엔트리를 할당하면 된다.)
Disadvantage
-
Page Directory로의 주소 접근 단계가 추가되므로, 메모리 엑세스 시간이 늘어난다. Multi-level Page Table은 time-space trade-off의 하나의 예시로 볼 수 있다.
-
Single-level Page Table에 비해 구현이 복잡하다.
마치며
사실 책에서는 Multi-level Page Tables의 구현과 관련된 내용과, 2-level page table에 관한 내용 등을 추가적으로 다루지만, 이 글에서는 각 방식의 개념을 위주로 정리하였다.
다음 글에서는 Paging과 관련된 추가적인 내용에 더불어, Memory Management Policy에 대해 알아보도록 하자. 운영체제 메모리 파트의 마지막 글이 될 예정!
