Code
-
특정 형태의 information을 다른 방법으로 표현하는 규칙 또는 해당 규칙으로 표현된 결과물
-
문자를 나타내기 위한 code는 인간이 사용하는 문자 를 일종의 기호 또는 숫자로 표현 하는 것을 의미한다.
encoding : 대상 information을 code로 변환하는 과정 또는 규칙
decoding : code로부터 원래의 information으로 얻는 과정 또는 규칙
문자를 나타내기 위한 code 중 가장 오래되었지만 여전히 사용되고 있는 ASCII (American Standard Code for Information Interchange) 가 가장 유명함.
- 문자를 나타내기 위한 code 중 가장 오래되었지만 여전히 사용되고 있는 ASCII (American Standard Code for Information Interchange)가 가장 유명하다. 하지만, 비영어권에서도 컴퓨터의 사용이 확장되면서 영문자만을 고려한 ASCII 외의 코드가 필요하게 되었고, 각 나라마다 자국어를 위한 고유의 코드들이 제안되던 시기를 거치게 됨 (1byte 또는 2bytes에 글자를 표현하기 위해 쥐어짜내던 시절).
그렇게 각 나라에서 제안된 코드들은 나름 효과적 (최소한 자국내에선) 이었지만, 다국어를 한번에 처리할 필요성 (하나의 웹페이지에 여러 언어를 표기)이 점점 커졌다.
그리하여 여러가지 형태의 Code들이 나왔고 이중 주요한것을 시대순으로 나열한것은 다음과 같다
The American Standard Code for Information Interchange (ASCII)
-
컴퓨터 초창기에 다양한 code들이 제안되었으나, 1963년 개발된 ASCII가 사실상 표준으로 살아남았다. ASCII는 영문자를 처리하는데 아직까지도 널리 사용된다.
-
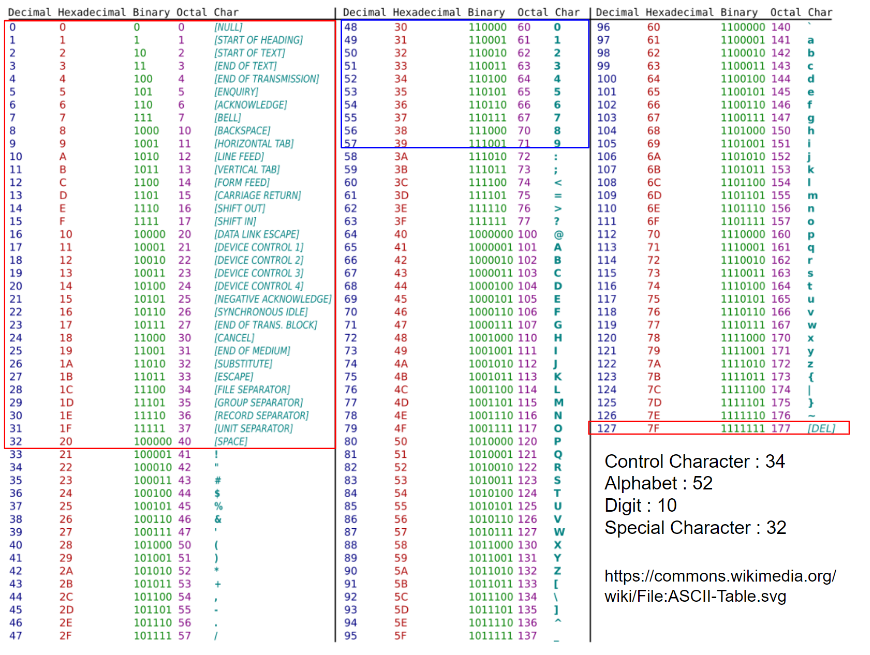
ASCII는 7bit 만으로 다양한 숫자기호 와 영문자들, 그리고 특수문자 및 Control character(제어문자) 들을 표현한다.
-
ASCII 의 상세 구성은 다음과 같다.
34개의 Control Character (NUL포함)
94개의 Printable Character
52개의 알파벳 대소문자
10개의 숫자
32개의 특수 문자
American National Standard Institute (ANSI)
ASCII의 7bit를 기반으로 8bit로 확장을 한 code
-
후에 개발된 Unicode가 단일 테이블에 모든 문자를 표현하는 것과 달리 ANSI는 code page를 이용 하여 한번에 해당 code page에 해당하는 나라의 문자를 표현하는 방식을 취한다.
-
즉, 128개는 ASCII 를 그리고 추가된 1 bit에 의해 늘어난 128개는 각국의 언어의 기호들이 할당되는 방식임.
한글과 같은 경우에 128개로 부족하기 때문에, 8bit를 더 할당하여 2byte를 사용 한다.
ANSI를 이용한 대표적 한글 code는 CP949이다
해당 이름의 949는 code page를 지칭 한다.
이는 Microsoft에서 제안한 방식이기 때문에 MS949라고도 불림.
Windows OS에서 주로 사용되는데, 한국의 당시 OS는 거의 Windows였기 때문에 사실상 한글 표준으로 사용되었음.
참고로 완성형 임.
- ANSI 방식은 자국어 만을 지원하는 경우에는 큰 문제가 없지만, 영어 외의 다른나라 글자들을 동시에 표현해야하는 경우엔 사용이 어렵다는 단점을 가진다.
Extended Unix Code-Korea (EUC-KR)
이름에서 알 수 있듯이 Unix 계열에서 한글 지원을 위해 등장 한 encoding 방식이며, 2byte를 이용한 완성형 방식이다.
CP949와 마찬가지로 ANSI를 한글 지원을 위해 확장한 형태 이며, 완성형의 한계로 인해 모든 한글을 표현하지 못한다(또한, ANSI의 단점도 그대로 가진다).
CP949 보다 먼저 개발되었고, 웹페이지 등에서 CP949 못지 않게 널리 사용되었다.
표현 가능한 한글 문자 수는 CP949보다 적었으나 인터넷에서 서버로 사용되는 장비의 OS가 주로 Unix 계열이었기 때문에 널리 사용되었다고 볼 수 있다.
Unicode
-
전세계의 문자기호(고대문자나 음악기호, 수학기호 등도 포함)를
단일 코드 테이블로 표현 한 코드이며, 이를 기반으로 하는 여러 encoding 방식을 가지고 있다 -
Unicode 처음에는 16bit를 기반으로 다양한 언어의 글자를 표현 가능하도록 설계되었으나 현재는 21bit로 확장 됨.
-
Unicode는 워낙 많은 문자와 기호를 지원하다 보니 code가 매우 긴 bit를 요구하기에 기존의 다른 code들과 달리 할당된 code와 다른 byte로 컴퓨터에서 저장 된다.
Unicode 와 관련 encodings
영문자만 사용하는 경우 8bit(사실은 7bit)의 ASCII 만으로도 충분하기 때문에, Unicode가 제안된 이후에도 서구권은 ASCII 만을 고려 및 지원하는 경우가 일반적이었음.
결국 기존의 ASCII와 같은 code 들과의 호환성을 유지하면서 Unicode를 사용할 수 있도록 해주는 encoding의 필요성이 요구됨.
또한 너무 많은 bit를 요구한다는 단점으로 저장과 전송에 효율적인 bytes로 변환이 요구됨.
이같은 이유로 Unicode는 일종의 code 값의 역할을 하고, 이를 컴퓨터에서 실제 저장하는 byte는 다르게 하는 encoding 방식 들이 개발되었고 사용되고 있음.
이는 기존의 code값이 곧 컴퓨터에서 사용하는 byte 값이었던 ASCII와 같은 이전 코드들과 unicode가 가지는 가장 큰 차이점임.
Encodings for Unicode
Unicode는 "ASCII와 같은 단순한 encodings" 와 비교할 때 훨씬 많은 bit를 요구 하기 때문에 저장 및 전송 에 사용되는 bytes 를 Unicode의 코드값을 그대로 사용하지 않는다.그렇기 때문에 둘 사이에도 변환을 위한 encodings가 존재한다
UTF-8
- 가변길이(multi-bytes)인 UTF-8 은 단일 encoding으로서 다국어가 쉽고 효율적으로 처리 하면서 Unicode 의 거의 모든 문자를 처리할 수 있게 해주는 장점이 있다
- 개발자들에게 매우 적극적으로 도입되었고 현재는 사실상의 표준으로 자리를 잡음.
사실 UTF-8은 한글 만으로 한정짓게 되면 저장공간의 관점에선 효율적이지 않다. 한글 문자 하나가 2byte로 처리가 가능한 UTF-16이나 ANSI 방식(EUC-KR, CP949)과 달리 UTF-8은 3byte로 처리함.
하지만 storage 용량과 통신속도가 나날이 빨라지는 현실에서 단일 방식으로 일관적이면서 쉽게 처리 가 되는 UTF-8은 전세계의 개발자들에게 환영을 받았고, 거의 대부분의 unicode 지원 S/W들 및 programming languages가 UTF-8을 기본방식으로 사용하면서 실제적인 표준 이 됨.
UTF-16
초기에 가장 많이 사용된 encoding은 다국적 기업들이 적극적으로 사용한 UTF-16이었다.
- 2 bytes를 통해 영어권과 유럽의 언어를 효과적으로 처리하는 장점이 있다.
- 특정 문자의 경우 4 bytes로 확장되어야하는 단점을 가진다.
- 비영어권 개발자들에게 UTF-16은 기존의 ANSI보다 불편하다.
- 자국 이외의 국가에서 서비스해야 하는 경우를 제외하고는 기존의 ANSI계열의 encoding을 선호함.
UTF-32 (고정길이)
고정길이를 사용하며 어찌보면 가장 처리가 일관적인 방식이다.
문자 하나에 4bytes를 쓴다는 단점이 무색해질 만큼 storage가 더욱 가격이 내려가고, 통신속도나 압축기술이 발전한다면 UTF-8을 대체할 수도 있다고 취급된다.
