[AWES 3기] 11주차 스터디 내용 정리
해당 포스팅은 스터디를 진행하시는 최영락님의 GenAI with Inferentia & FSx Workshop 환경을 제공받아 실습한 내용을 정리하였습니다.
AI 워크로드에 대한 컨테이너 사용
[기존의 ML 사용법]
베어메탈 서버에 직접 GPU 드라이버와 라이브러리를 설치하여 작업을 했다.
이런 작업 방식에는 몇 가지 문제점이 있었는데,
- 환경 구성의 복잡성: CUDA, cuDNN 등 복잡한 드라이버 스택 설치 및 관리가 필요 (특히 버전 호환성 문제로 인해 특정 프레임워크(TensorFlow, PyTorch)가 특정 CUDA/cuDNN 버전만 지원하는 경우가 많았음)
- 재현성 부족: 동일한 실험 환경을 다른 시스템에서 재현하기 어려움
- 리소스 비효율성: 고가의 GPU 리소스가 특정 사용자나 프로젝트에 고정되어 활용도가 저하. (베어메탈 GPU 서버의 활용률은 30% 미만인 경우가 많았음)
- 확장성 제한: 대규모 분산 학습을 위한 인프라 확장이 어려웠음. 새로운 GPU 서버를 추가할 때마다 동일한 환경 구성 과정을 반복 필요.
이러한 복잡성을 해결하기 위해 컨테이너 기술을 사용하고자 했지만, GPU와 같은 특수 하드웨어 장치에 대해서는 몇 가지 근본적인 제약이 있었다.
왜냐하면 컨테이너 기술은 주로 두 가지 핵심 Linux 커널 기능에 의존하고 있는데,
- Cgroups (Control Groups): 프로세스 그룹의 리소스 사용(CPU, 메모리, 디스크 I/O, 네트워크 등)을 제한하고 격리하는 메커니즘
- Namespaces: 프로세스가 시스템의 특정 리소스만 볼 수 있도록 격리하는 기능 Linux는 여러 유형의 네임스페이스(PID, 네트워크, 마운트, UTS, IPC, 사용자 등)를 제공
이러한 기술들은 CPU와 메모리 같은 리소스를 효과적으로 관리할 수 있게 해주지만, CPU 코어나 메모리와 달리, 초기 GPU는 물리적으로 분할하여 여러 컨테이너에 할당하기 어려웠기 때문이다 (지금은 사용 가능!)
[컨테이너 환경에서의 GPU 리소스 사용 진화 (단일 GPU)]
- 초기 단계 (2016-2018)
초기에는 GPU 장치 파일을 컨테이너에 직접 마운트하고 필요한 라이브러리를 볼륨으로 공유해야 했다.
docker run --device=/dev/nvidia0:/dev/nvidia0 \
--device=/dev/nvidiactl:/dev/nvidiactl \
-v /usr/local/cuda:/usr/local/cuda \
tensorflow/tensorflow:latest-gpu- 이 방식 문제점
- 모든 장치 파일을 수동으로 지정해야 함
- 호스트와 컨테이너 간 라이브러리 버전 충돌 가능성
- 여러 컨테이너 간 GPU 공유 메커니즘 부재
- 오케스트레이션 환경에서 자동화하기 어려움
- NVIDIA Container Runtime 활용 (2018-2020)
NVIDIA는 이러한 문제를 해결하기 위해 NVIDIA Container Runtime을 개발하였으며, 다음 기능을 자동화했다. (https://developer.nvidia.com/container-runtime)
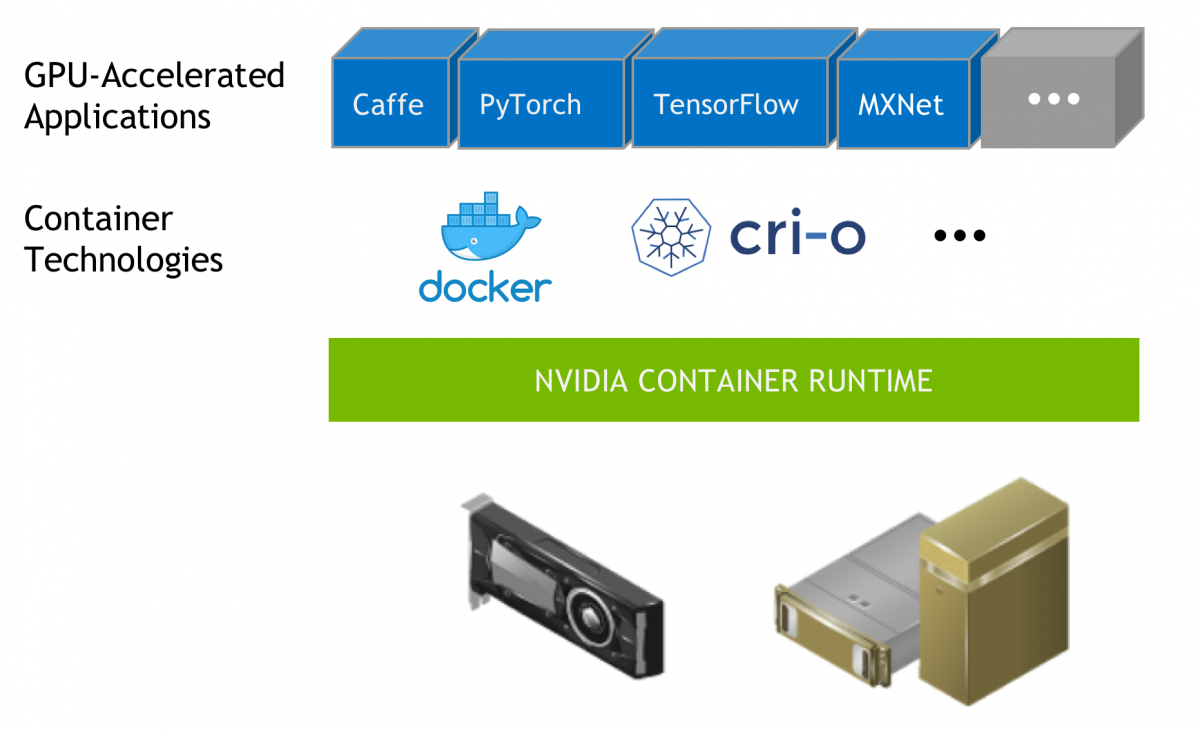
- GPU 장치 파일 마운트
- NVIDIA 드라이버 라이브러리 주입
- CUDA 호환성 검사
- GPU 기능 감지 및 노출
# Docker 19.03 이전 버전 사용
docker run --runtime=nvidia nvidia/cuda:11.0-base nvidia-smi
# Docker 19.03 이후부터는 더 간단하게 **--gpus** 플래그를 사용
docker run --gpus '"device=0,1"' nvidia/cuda:11.0-base nvidia-smi- 이 방식을 통해 다음과 같은 개선점을 얻음
- 자동화된 GPU 검출 및 설정
- 호스트-컨테이너 간 드라이버 호환성 자동 관리
- 컨테이너 이미지 이식성 향상
- Kubernetes 장치 플러그인 등장 (2020-현재)
Kubernetes 오픈 소스에 Device Plugin(Kubernetes 클러스터에서 NVIDIA GPU 리소스를 노출하고 관리하는 플러그인으로, 이를 통해 Pod 스펙에서 선언적으로 GPU 리소스를 요청)이라는 제안이 2017년 9월 처음으로 이루어짐 (https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/)
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: nvidia/cuda:11.0-base
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 2 # 2개의 GPU 요청- 이 방식을 통해 다음과 같은 장점 지원:
- 선언적 리소스 관리
- 클러스터 수준의 GPU 리소스 스케줄링
- 자동화된 GPU 할당 및 격리
- 다중 테넌트 환경에서의 리소스 공정성
멀티 GPU 활용을 위한 AI/ML 인프라 with EKS
[컨테이너 환경에서의 GPU 리소스 사용 진화 (멀티 GPU)]
- 분산 학습에서 발생하는 네트워크 병목 현상
- 대규모 모델이 등장하면서, 이제 단일 GPU로는 학습이 불가능해짐.
- GPT-3: 1,750억 파라미터
- Megatron-Turing NLG: 5,300억 파라미터
- PaLM: 5,400억 파라미터
- AWS에서도 이러한 추세에 맞춰 대규모 모델 개발과 학습을 위한 인프라를 지속적으로 발전시키고 있음.
- Amazon Bedrock: 100개 이상의 LLM을 지원하며
- Trainium/Inferentia 칩을 통한 모델 성능 향상과 같은 AI 인프라 혁신에 투자
- 2025년 현재 AWS는 이러한 대규모 모델의 학습과 추론을 위해 분산 컴퓨팅 기술을 적극적으로 활용하고 있으며, 단일 GPU로는 처리할 수 없는 규모의 모델 개발을 지원하고 있음.
- 이러한 대규모 모델은 필연적으로 여러 GPU와 여러 노드에 걸친 분산 학습이 필요
- 대규모 모델이 등장하면서, 이제 단일 GPU로는 학습이 불가능해짐.
[분산 학습에서 이루어지는 주요 통신 패턴]
- AllReduce: 딥러닝 연산시 그래디언트 (Gradient) 동기화를 위해 모든 GPU가 데이터를 교환하고 집계하는 방식
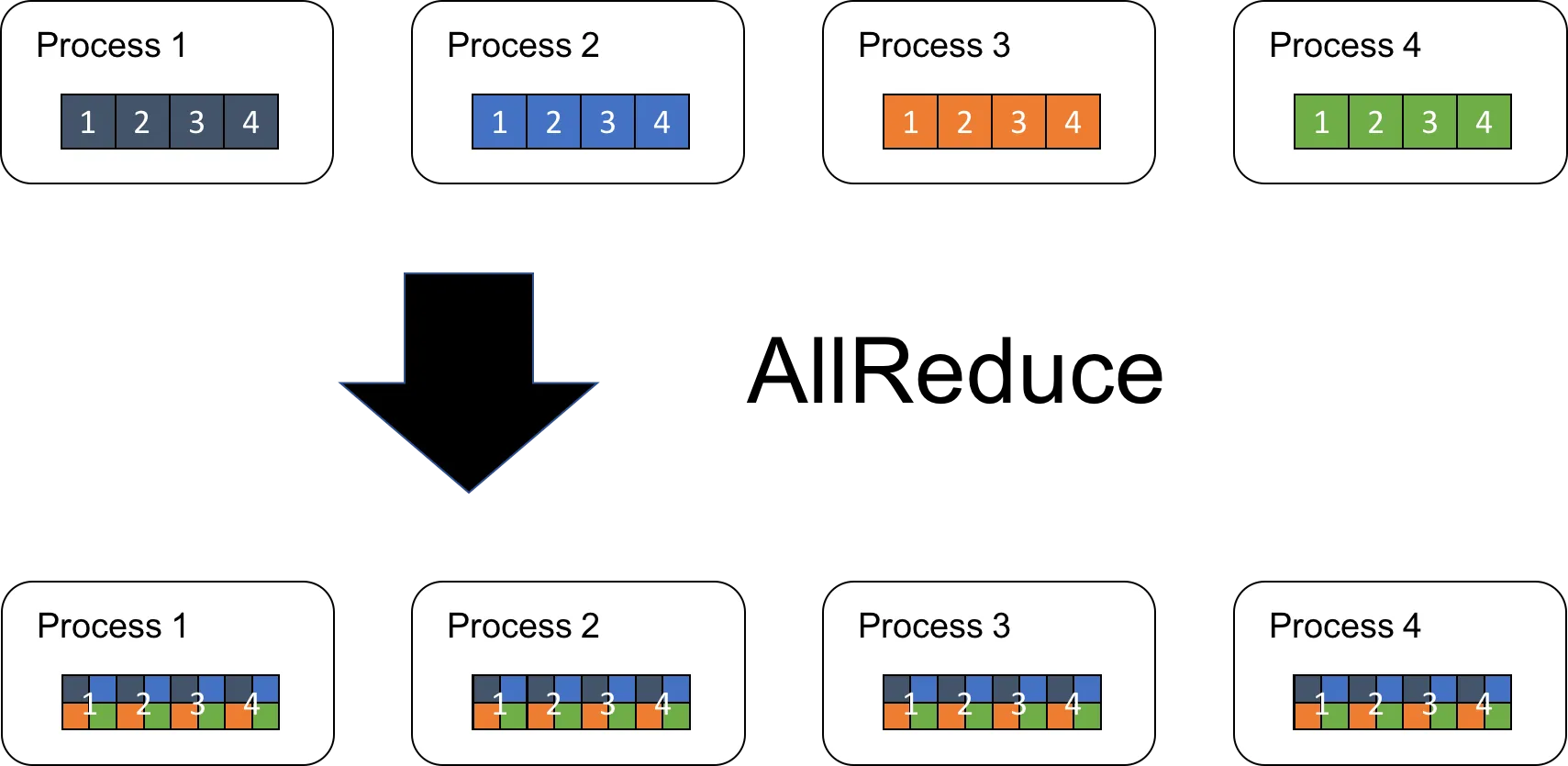
- NCCL: GPU 간 통신을 위한 NVIDIA의 해결책
[AWS EFA (Elastic Fabric Adapter)]
GPU 네트워크 병목 문제를 해결하기 위해 설계된 혁신적인 네트워크 인터페이스
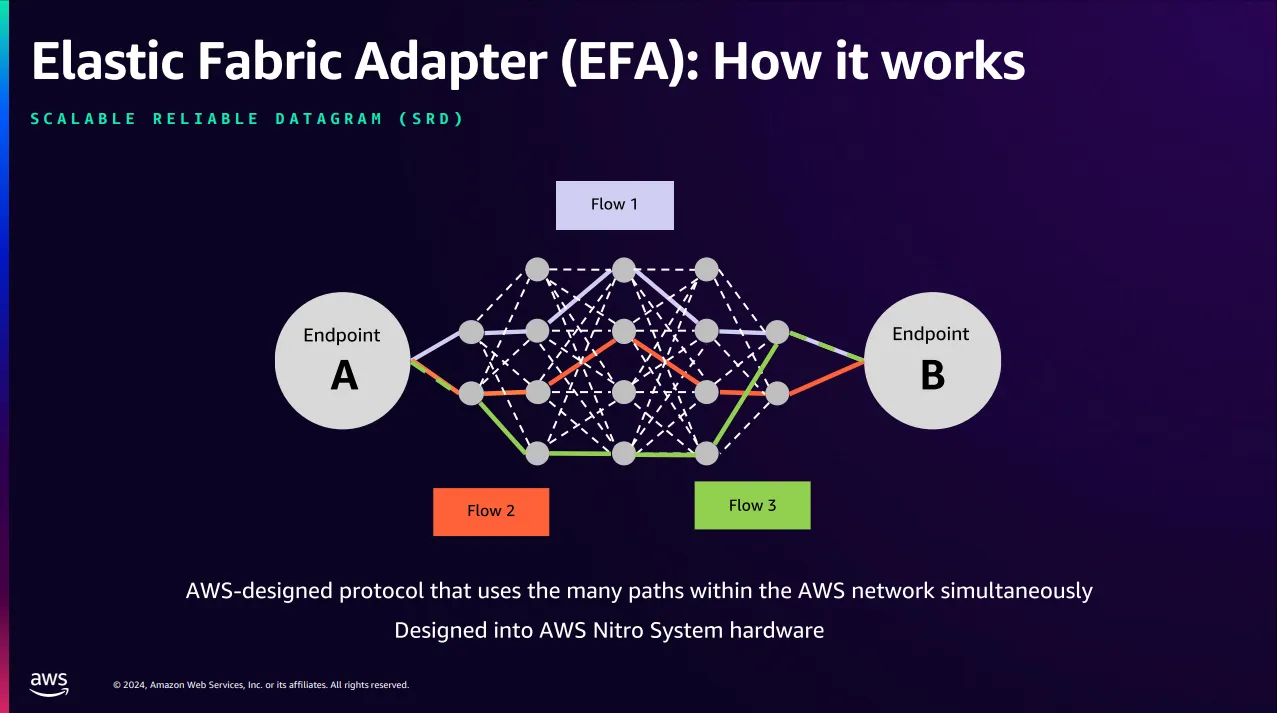
(EFA를 지원하는 인스턴스 유형 https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/efa.html 참고)
GenAI with Inferentia & FSx Workshop
[워크숍에서 배우는 내용]
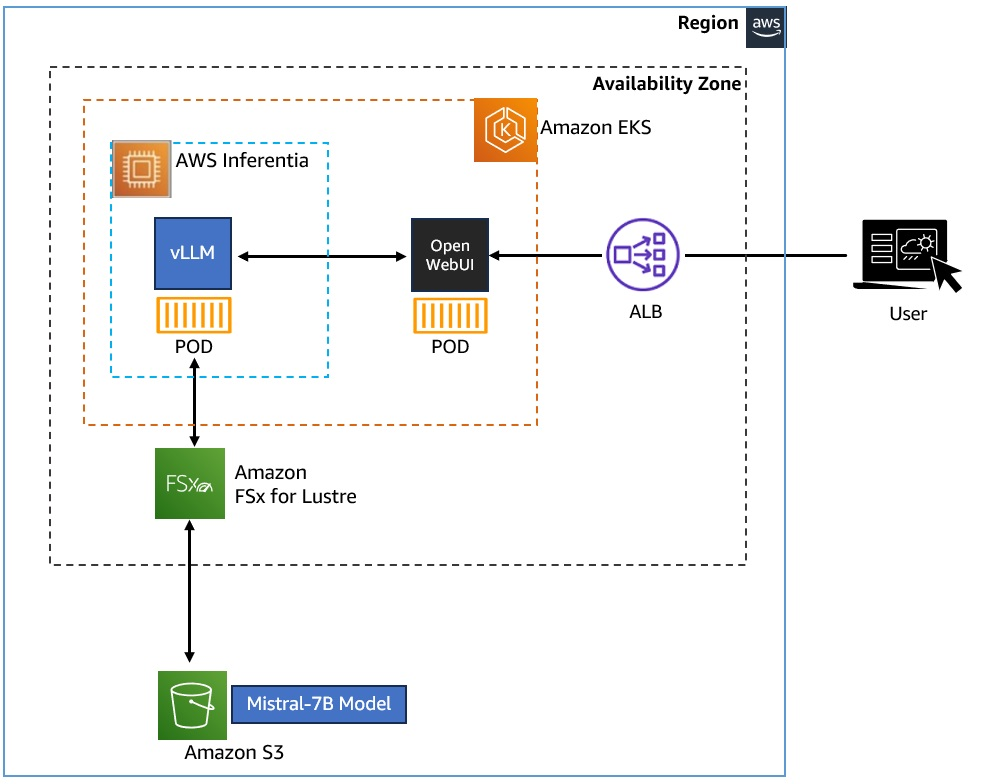
- 쿠버네티스에 생성형 AI 챗봇 애플리케이션 배포
- Amazon EKS 클러스터에 vLLM과 WebUI Pod 배포
- Amazon FSx for Lustre와 Amazon S3를 활용하여 Mistral-7B 모델 저장 및 접근
- AWS Inferentia 가속기를 사용하여 생성형 AI 워크로드의 컴퓨팅 성능 향상
- Karpenter를 활용한 EKS 노드 스케일링
- 추가 Pod 요청이 있을 때 자동으로 EKS 노드 수를 확장
- 효율적인 스케일링과 운영 효율성 향상
- Amazon EKS 클러스터에서 AWS Inferentia 가속 컴퓨팅 활용
- 생성형 AI 애플리케이션을 위한 새로운 노드풀로 Inferentia 가속 컴퓨팅 구성
- Amazon FSx for Lustre와 Amazon S3 구성
- 고성능 확장 가능한 데이터 레이어로 모델과 데이터 호스팅
- 데이터 레이어에서의 운영 효율성 달성
- 여러 사본을 저장하지 않고 컨테이너 Pod 간 동일한 모델 데이터 접근
- 지역 간 데이터 원활한 공유(분산 접근, DR 등의 시나리오를 위함)
[생성형 AI와 기계 학습]
- 비즈니스 운영 및 혁신 방식의 변화에 도움
- 대규모 언어 모델(LLM)을 활용해 텍스트, 이미지, 오디오, 코드 등 새로운 콘텐츠 생성
[대규모 언어 모델(LLM)]
- 방대한 텍스트 데이터로 학습된 기계 학습 모델
- 자연어 처리 작업(텍스트 생성, 질문 응답, 언어 번역 등)에 활용
- 워크숍에서는 70억 매개변수를 가진 오픈소스 Mistral-7B-Instruct 모델 사용
[vLLM(Virtual Large Language Model)]
- LLM 추론 및 서빙을 위한 오픈소스 라이브러리
- OpenAI API와 호환되는 API 제공으로 쉬운 통합
- 장점:
- 최고 수준의 서빙 처리량
- PagedAttention을 통한 메모리 효율적 관리
- 지속적인 배치 처리
- CUDA/HIP 그래프로 빠른 모델 실행
- HuggingFace 모델과 통합 용이
- AWS Neuron, NVIDIA GPU 등 다양한 칩셋 지원
[Amazon EKS에 Mistral-7B-Instruct 배포]
- vLLM 프레임워크를 활용해 Amazon EKS에 배포
- Karpenter로 AWS Inferentia2 EC2 노드 구성
- Amazon EKS는 컨테이너 기반 앱 실행/관리를 위한 관리형 쿠버네티스 서비스
[추론 서비스 활용]
- "Open WebUI" 애플리케이션을 통해 OpenAI 호환 엔드포인트 연결
- 채팅 기반 인터페이스로 LLM 모델과 상호작용
[모델 및 학습 데이터 저장/접근]
- Mistral-7B-Instruct 모델은 Amazon S3 버킷에 저장
- Amazon FSx for Lustre 파일 시스템을 통해 모델 데이터 접근
- FSx for Lustre는 고성능 확장형 파일 시스템 제공(밀리초 미만 지연시간, TB/s 처리량)
[컴퓨팅 가속화]
- AWS Inferentia 가속기: 딥러닝 및 생성형 AI 추론에 최적화된 성능/비용 제공
- AWS Neuron SDK: AWS Inferentia 가속기에 모델 배포 지원
- PyTorch, TensorFlow 등과 통합하여 기존 코드 및 워크플로 유지 지원
[실습]
Cloud9에서 genaifsxworkshoponeks를 클릭한다.

확인이 되었으면 아래 명령을 실행하여 랩 지역 이름을 설정한다.
TOKEN=`curl -s -X PUT "http://169.254.169.254/latest/api/token" -H "X-aws-ec2-metadata-token-ttl-seconds: 21600"`
export AWS_REGION=$(curl -s -H "X-aws-ec2-metadata-token: $TOKEN" http://169.254.169.254/latest/meta-data/placement/region)
export CLUSTER_NAME=eksworkshop
kube-config 파일을 업데이트 해준 후 node를 조회해본다.
aws eks update-kubeconfig --name $CLUSTER_NAME --region $AWS_REGION
kubectl get nodes
[Explore workshop environment]
kubectl -n karpenter get deploy/karpenter -o yaml
주요 환경 변수
- CLUSTER_ENDPOINT: 새로운 노드가 연결할 수 있는 외부 Kubernetes 클러스터 엔드포인트 지정 (설정되지 않은 경우: 노드는 DescribeCluster API를 사용하여 클러스터 엔드포인트를 자동 탐색함)
- INTERRUPTION_QUEUE (EKS Terraform 블루프린트의 일부로 생성된 SQS 대기열 엔드포인트, 클러스터의 워크로드 연속성을 보장하기 위해 중단 이벤트를 처리하는 데 활용)
카펜터가 잘 설치되어 있는지 확인하기 위해 아래 커맨드를 실행한다.
kubectl get pods --namespace karpenter
[Configure storage - Host model data on Amazon FSx for Lustre]
모델 스토리지 구조
- Mistral-7B-Instruct 모델은 Amazon S3 버킷에 저장
- 이 S3 버킷은 Amazon FSx for Lustre 파일 시스템과 연결
- vLLM 컨테이너는 FSx for Lustre를 통해 생성형 AI 챗봇 애플리케이션에 모델 데이터 접근
인프라 구성
- Amazon EKS 클러스터(EC2 워커 노드 2개)
- Amazon FSx for Lustre 파일 시스템
- Amazon S3 버킷
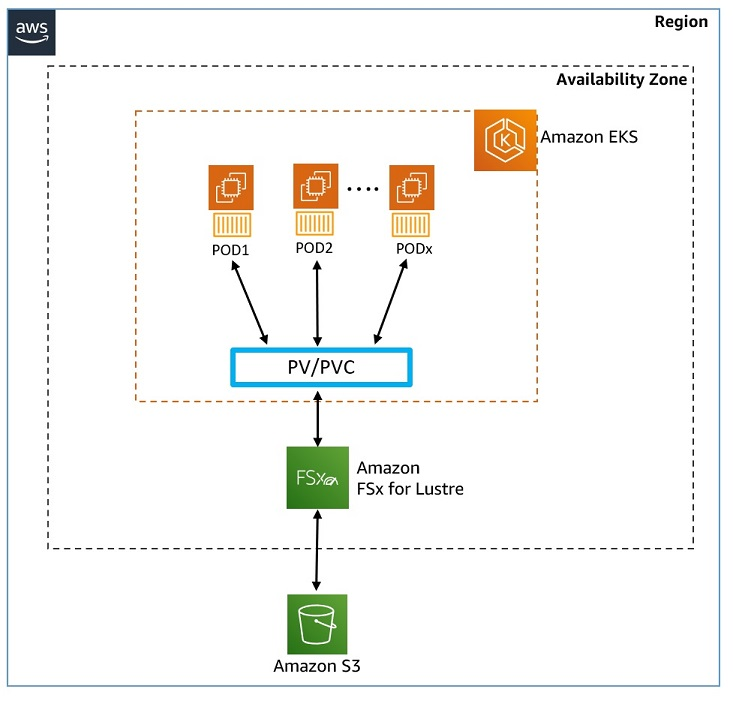
[Amazon FSx for Lustre 개요]
- 정의: 속도가 중요한 워크로드를 위한 완전 관리형 고성능 병렬 파일 시스템
- 성능: 밀리초 미만의 지연 시간, TB/s 처리량, 수백만 IOPS까지 확장 가능
- S3 통합:
- S3 객체를 파일로 투명하게 표시
- Lustre 파일 시스템에서 파일이 추가, 수정, 삭제될 때 연결된 S3 버킷 내용 자동 업데이트
[쿠버네티스 스토리지 개념]
1. CSI 드라이버(Container Storage Interface):
- 컨테이너 오케스트레이션 시스템이 블록/파일 스토리지 시스템을 관리하는 표준
- FSx for Lustre CSI 드라이버: EKS가 FSx for Lustre 기반 영구 볼륨의 수명 주기 관리 지원
- StorageClass:
- 관리자가 제공하는 "스토리지 클래스" 설명
- 다양한 스토리지 유형(FSx, EBS, EFS 등) 또는 백업 정책에 매핑 가능
- 영구 볼륨(PV, Persistent Volume):
- 관리자가 이미 프로비저닝한 EKS 클러스터에 매핑된 스토리지 볼륨
- Pod의 수명을 넘어서 존재하여 공유 데이터 접근이 필요한 Pod에 이상적
- 영구 볼륨 클레임(PVC, Persistent Volume Claim):
- 사용자의 스토리지 볼륨 요청
- 특정 크기와 접근 모드(ReadWriteOnce, ReadOnlyMany, ReadWriteMany) 요청 가능
[스토리지 프로비저닝 유형]
- 정적 프로비저닝(Static Provisioning):
- 2단계 프로세스:
- 1단계: 관리자가 백엔드 스토리지 볼륨 생성(FSx for Lustre 인스턴스) 및 쿠버네티스 클러스터에 해당 PV 정의 생성
- 2단계: 애플리케이션 개발자가 Pod에서 해당 PV를 사용하기 위한 PVC 요청 제출
- 동적 프로비저닝(Dynamic Provisioning):
- 관리자가 스토리지를 미리 프로비저닝할 필요 없음
- 사용자가 PVC 요청할 때 자동으로 PV(및 연결된 FSx for Lustre 인스턴스) 프로비저닝
- 주문형 영구 스토리지 생성 및 사용 가능
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output text)아래 명령을 복사하여 실행하여 fsx-csi-driver.json 파일을 만든다.
cat << EOF > fsx-csi-driver.json
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"iam:CreateServiceLinkedRole",
"iam:AttachRolePolicy",
"iam:PutRolePolicy"
],
"Resource":"arn:aws:iam::*:role/aws-service-role/s3.data-source.lustre.fsx.amazonaws.com/*"
},
{
"Action":"iam:CreateServiceLinkedRole",
"Effect":"Allow",
"Resource":"*",
"Condition":{
"StringLike":{
"iam:AWSServiceName":[
"fsx.amazonaws.com"
]
}
}
},
{
"Effect":"Allow",
"Action":[
"s3:ListBucket",
"fsx:CreateFileSystem",
"fsx:DeleteFileSystem",
"fsx:DescribeFileSystems",
"fsx:TagResource"
],
"Resource":[
"*"
]
}
]
}
EOF그 이후에는 설정한 내용을 기반으로 iam policy를 생성한다.
aws iam create-policy \
--policy-name Amazon_FSx_Lustre_CSI_Driver \
--policy-document file://fsx-csi-driver.json
이후에는 아래 명령을 복사하여 실행하여 서비스 계정을 생성하고 3단계에서 생성한 IAM 정책을 첨부한다.
eksctl create iamserviceaccount \
--region $AWS_REGION \
--name fsx-csi-controller-sa \
--namespace kube-system \
--cluster $CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::$ACCOUNT_ID:policy/Amazon_FSx_Lustre_CSI_Driver \
--approve
export ROLE_ARN=$(aws cloudformation describe-stacks --stack-name "eksctl-${CLUSTER_NAME}-addon-iamserviceaccount-kube-system-fsx-csi-controller-sa" --query "Stacks[0].Outputs[0].OutputValue" --region $AWS_REGION --output text)이제 FSx for Lustre용 CSI 드라이버를 배포한다.
kubectl apply -k "github.com/kubernetes-sigs/aws-fsx-csi-driver/deploy/kubernetes/overlays/stable/?ref=release-1.2"
kubectl get pods -n kube-system -l app.kubernetes.io/name=aws-fsx-csi-driver
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa \
eks.amazonaws.com/role-arn=$ROLE_ARN --overwrite=trueCloud9 터미널에서 아래 명령을 실행하여 FSx Lustre 인스턴스 세부 정보(사전 생성됨)로 변수를 채운다.
cd /home/ec2-user/environment/eks/FSxL
FSXL_VOLUME_ID=$(aws fsx describe-file-systems --query 'FileSystems[].FileSystemId' --output text)
DNS_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].DNSName' --output text)
MOUNT_NAME=$(aws fsx describe-file-systems --query 'FileSystems[].LustreConfiguration.MountName' --output text)그 이후에는 PV를 만들어준다.
sed -i'' -e "s/FSXL_VOLUME_ID/$FSXL_VOLUME_ID/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/DNS_NAME/$DNS_NAME/g" fsxL-persistent-volume.yaml
sed -i'' -e "s/MOUNT_NAME/$MOUNT_NAME/g" fsxL-persistent-volume.yaml
cat fsxL-persistent-volume.yaml
kubectl apply -f fsxL-persistent-volume.yaml
kubectl get pv

이어서 PVC도 만든다.
kubectl apply -f fsxL-claim.yaml
kubectl get pv,pvc
=> PersistentVolume을 성공적으로 구성하고 vLLM이 Mistral-7B 애플리케이션에 액세스하는 데 사용할 PersistentVolumeClaim을 생성을 완료했다.
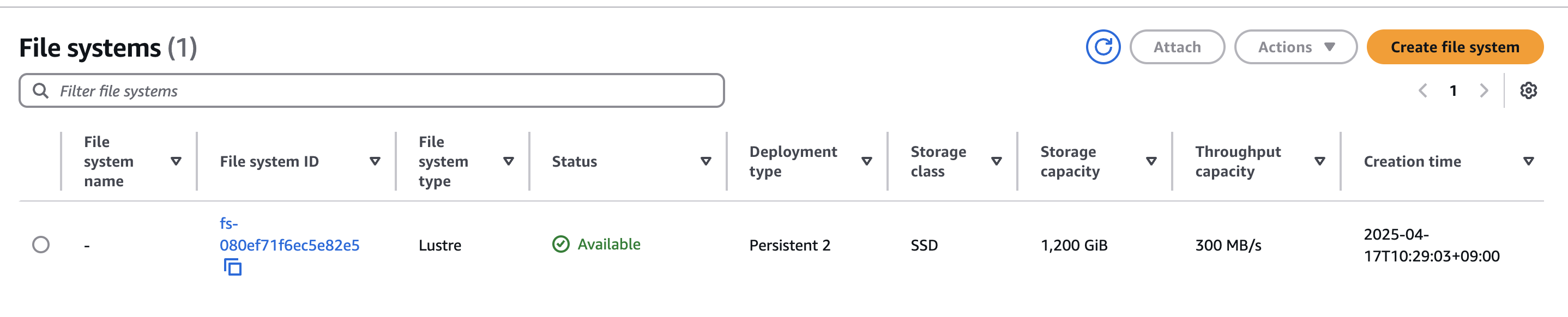
콘솔에서도 생성된 File system을 확인할 수 있다.
[Deploy Generative AI Chat application]
Karpenter 구성은 NodePool 커스텀 리소스(CR)를 통해 이루어진다. 이 NodePool은 Karpenter가 생성할 수 있는 노드와 해당 노드에서 실행할 Pod에 대한 제약 조건을 설정한다. NodePool은 특정 컴퓨터 아키텍처로 노드 생성을 제한하거나 여러 아키텍처를 유연하게 사용하도록 구성할 수 있다. 단일 Karpenter NodePool은 다양한 Pod 형태를 처리할 수 있으며, Pod의 라벨이나 어피니티와 같은 속성에 기반하여 스케줄링 및 프로비저닝 결정을 내린다. 하나의 클러스터에 여러 NodePool을 구성할 수 있으며, 현재 상황에서는 추가적으로 inferentia NodePool을 선언할 예정이다. 이를 통해 Karpenter는 다양한 워크로드 요구사항에 맞게 노드를 효율적으로 관리할 수 있다.
cd /home/ec2-user/environment/eks/genai
cat inferentia_nodepool.yaml
kubectl apply -f inferentia_nodepool.yaml
kubectl get nodepool,ec2nodeclass inferentia
이번에는 Neuron device plugin & scheduler를 설치한다.
# Neuron Device plugin
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin-rbac.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-device-plugin.yml
# Neuron Scheduler
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/k8s-neuron-scheduler-eks.yml
kubectl apply -f https://raw.githubusercontent.com/aws-neuron/aws-neuron-sdk/master/src/k8/my-scheduler.yml
여기까지 성공했다면 이제 모델 서빙 기능과 추론 엔드포인트를 제공할 vLLM 포드를 배포하게 된다. vLLM 포드가 온라인 상태가 되면, FSx for Lustre 기반 영구 볼륨에서 Mistral-7B 모델(29GB)을 메모리에 로드할 것이며, 그 후에 사용할 준비가 완료된다. 이 과정이 완료되면 모델 서빙을 통해 추론 서비스를 이용할 수 있게 된다.
kubectl apply -f mistral-fsxl.yaml
cat mistral-fsxl.yaml
kubectl get pod

정상적으로 배포된 것을 확인할 수 있다.

콘솔에서도 AWS Inferentia inf2.xlarge compute node가 생성된 것을 확인할 수 있다.
이제 실제로 ui에 접근하기 위해 ingress를 배포한다.
kubectl apply -f open-webui.yaml
# 1-2분 뒤에 실행하기
kubectl get ing
Mistral-7B이 보인다.
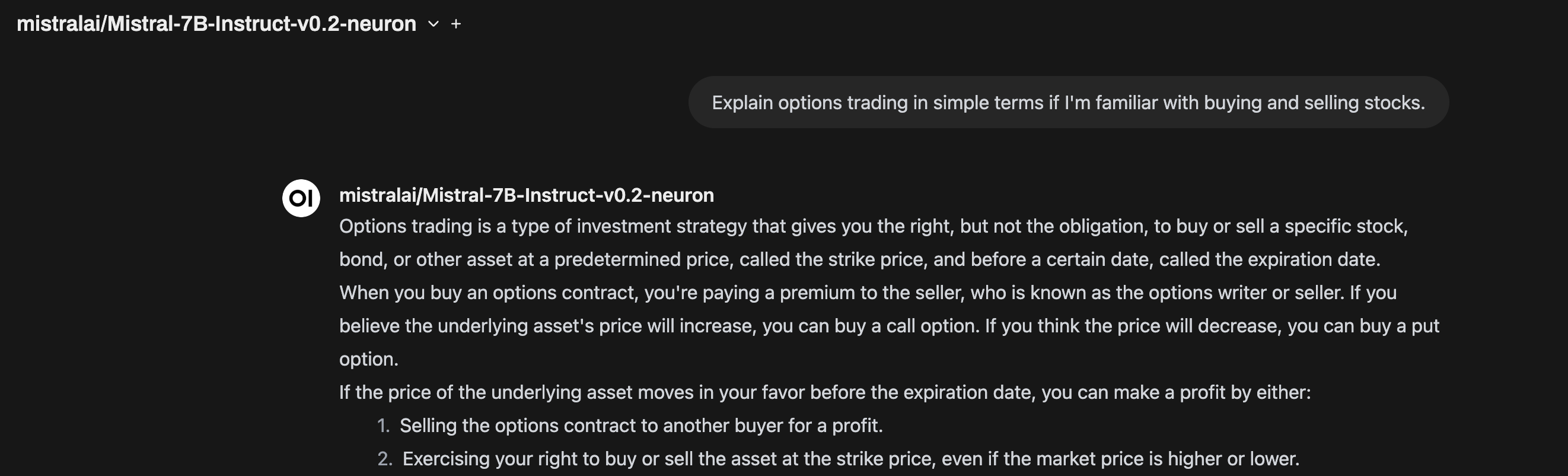
결과도 잘 나오는 것을 확인할 수 있다.
[Inspect Mistral-7B data, and share & replicate generated data assets]
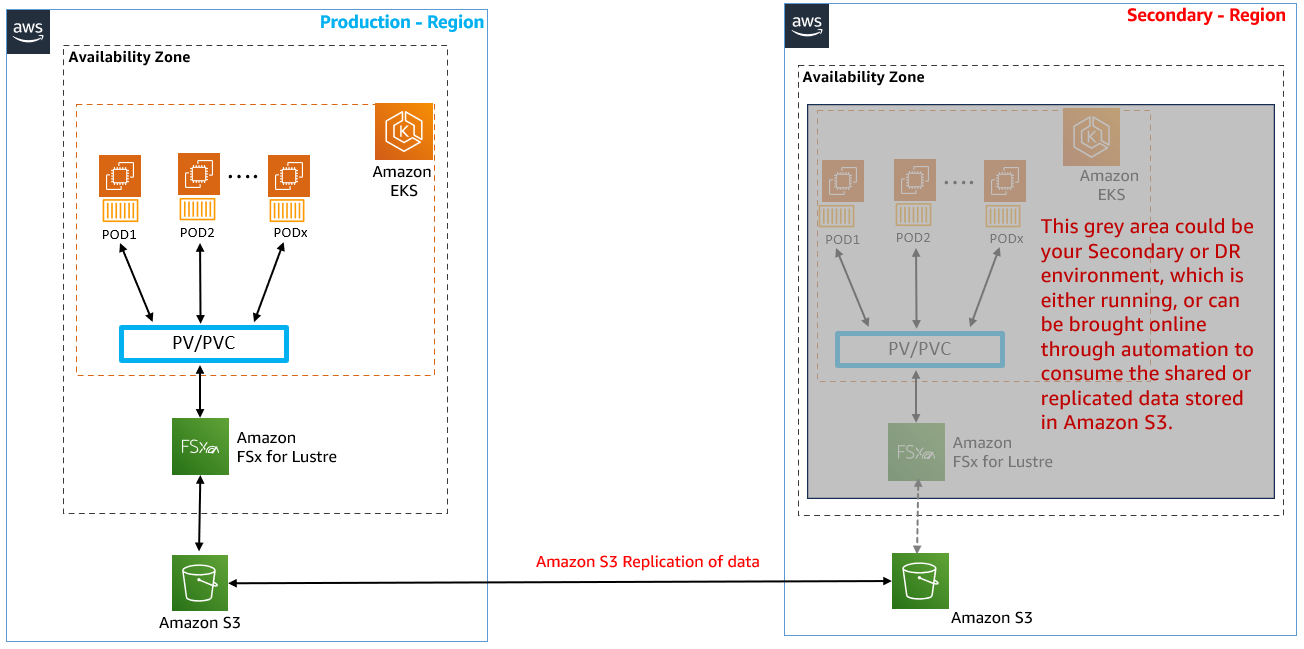
이 과정에서 vLLM 포드에 로그인하여 영구 볼륨에 저장된 Mistral 모델 데이터 구조를 확인하게 된다. vLLM 포드에 접속함으로써 FSx Lustre 파일 시스템이 지원하는 영구 볼륨을 통해 S3 버킷에 저장된 모든 데이터에 접근하고 확인하는 방법을 볼 수 있으며, 이는 다른 리전의 EKS 클러스터와 모델이나 학습 데이터를 공유해야 하는 시나리오(재해 복구 또는 다른 팀의 분산 접근)에 유용하다. 실습에서는 영구 볼륨에 테스트 파일을 생성하고, 이 파일이 자동으로 S3 버킷으로 내보내지는 과정을 관찰합니다. 또한 설정할 S3 복제를 통해 테스트 파일이 다른 대상 AWS 리전(us-east-2)의 S3 버킷으로 자동 복제되는 과정도 확인하게 된다.
S3 Bucket 중에 fsx-lustre-suxxx 버킷에 ReplicationRule을 추가한다.
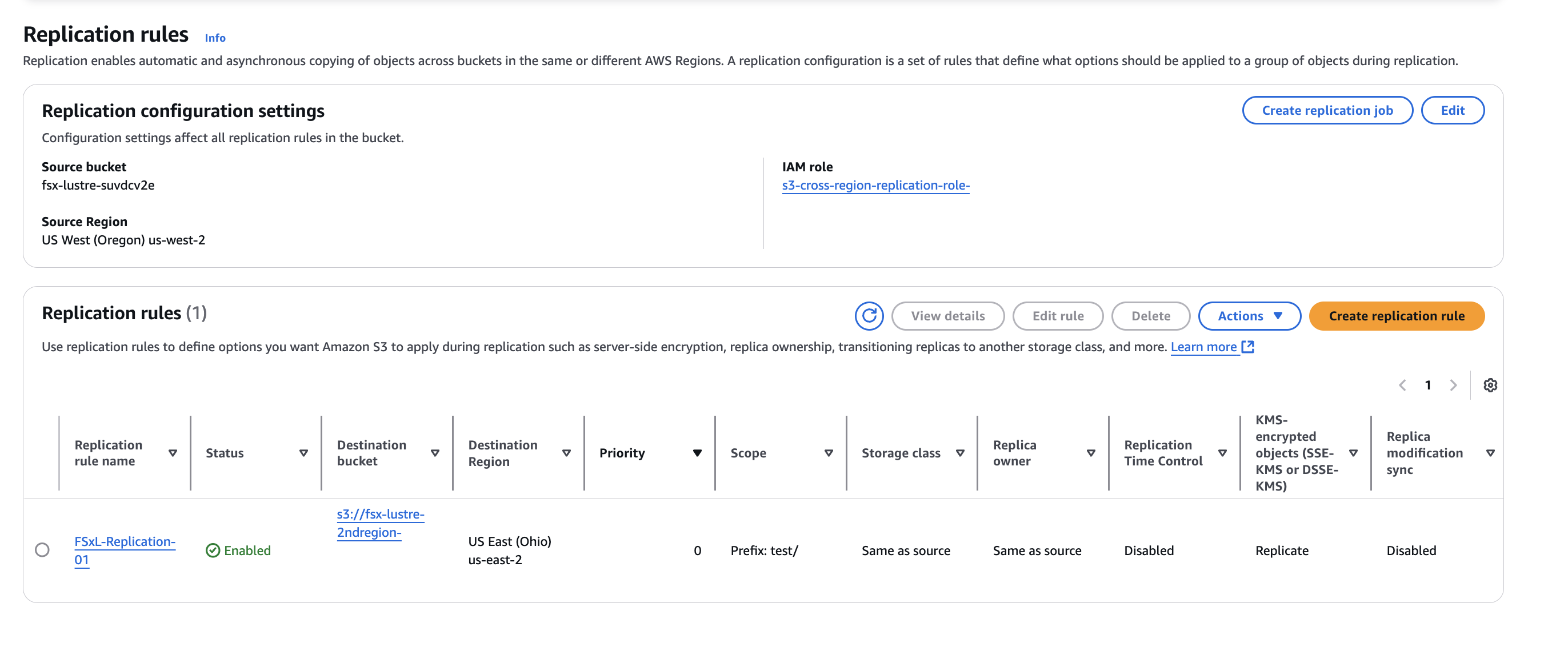
두 개의 S3 버킷 간에 S3 크로스 리전 복제 규칙을 성공적으로 생성했다. 다음 섹션에서는 포드에 마운트된 영구 볼륨에 테스트 데이터를 생성하고, 생성된 데이터가 원활하게 대상 S3 버킷으로 복사되는 과정을 확인한다.
cd /home/ec2-user/environment/eks/FSxL
kubectl get pods
vllm이라는 이름으로 시작하는 새로운 파드가 생겼다.
kubectl exec -it <YOUR-vLLM-POD-NAME> -- bash
cd /work-dir/
ls -ll
cd Mistral-7B-Instruct-v0.2/
ls -ll
cd /work-dir
mkdir test
cd test
cp /work-dir/Mistral-7B-Instruct-v0.2/README.md /work-dir/test/testfile
ls -ll /work-dir/test

버킷에 방금 생성한 파일이 똑같이 생성된 것을 확인할 수 있다.
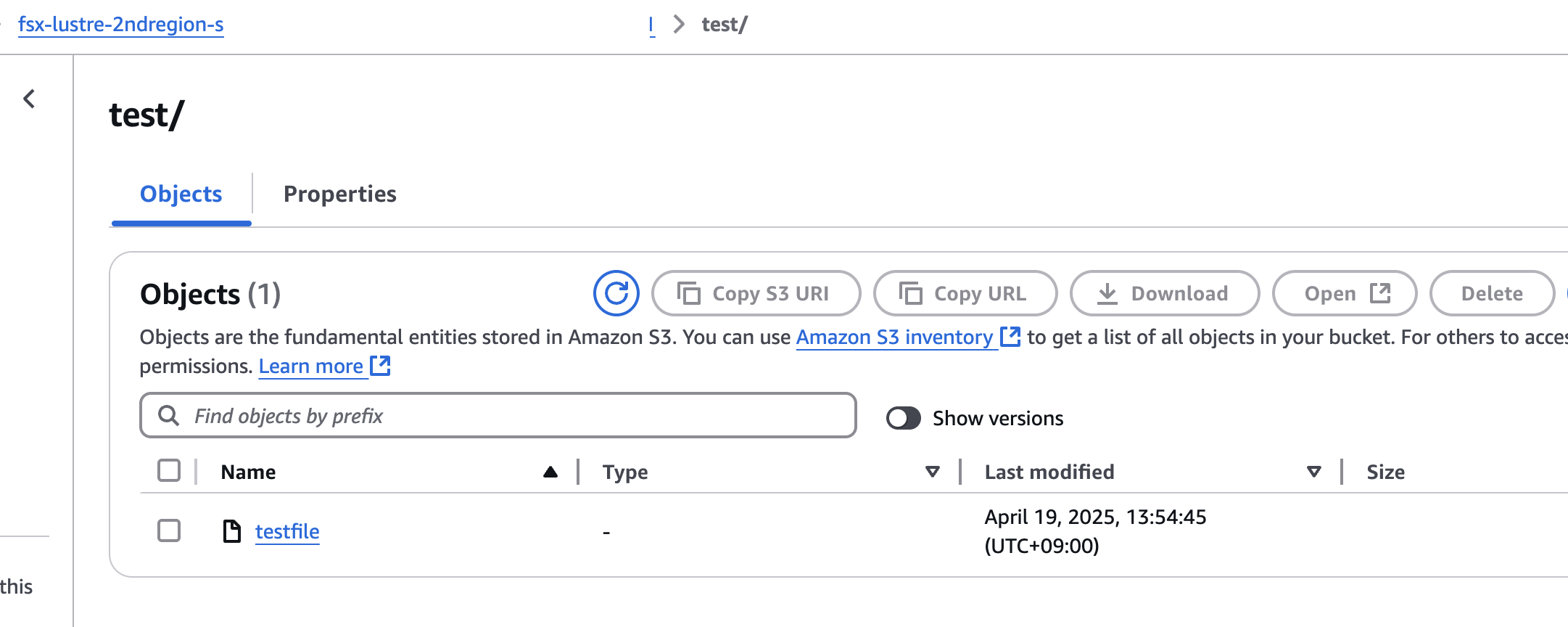
다른 리전에 있는 버킷에도 자동으로 동기화가 된 것을 확인할 수 있다.
[Use Dynamic Provisioning to deploy a new PV and FSx Lustre instance for testing]
이전 모듈에서는 기존 스토리지 엔티티(관리자가 생성한)를 사용하여 정적 프로비저닝으로 영구 볼륨과 클레임을 생성하는 방법을 배웠다. 이번 섹션에서는 사용자가 CSI 드라이버와 동적 프로비저닝 기능을 사용하여 주문형 영구 볼륨과 클레임을 배포하는 방법을 배우게 된다. 이 과정에서는 백엔드에서 연결된 FSx Lustre 인스턴스도 자동으로 생성되며, 관리자의 사전 프로비저닝이 필요하지 않다. 정적 프로비저닝과 동적 프로비저닝 간의 차이점을 강조하기 위해 StorageClass, PersistentVolume 및 PersistentVolumeClaim에 대한 정의를 생성한다. 이렇게 생성된 영구 볼륨은 이번 실습 섹션에서 테스트 용도로 사용하게 된다.
VPC_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.vpcId" --output text)
SUBNET_ID=$(aws eks describe-cluster --name $CLUSTER_NAME --region $AWS_REGION --query "cluster.resourcesVpcConfig.subnetIds[0]" --output text)
SECURITY_GROUP_ID=$(aws ec2 describe-security-groups --filters Name=vpc-id,Values=${VPC_ID} Name=group-name,Values="FSxLSecurityGroup01" --query "SecurityGroups[*].GroupId" --output text)
echo $SUBNET_ID
echo $SECURITY_GROUP_ID
cd /home/ec2-user/environment/eks/FSxL
sed -i'' -e "s/SUBNET_ID/$SUBNET_ID/g" fsxL-storage-class.yaml
sed -i'' -e "s/SECURITY_GROUP_ID/$SECURITY_GROUP_ID/g" fsxL-storage-class.yaml
cat fsxL-storage-class.yaml
kubectl apply -f fsxL-storage-class.yaml
kubectl get sc
그 뒤에는 앞서 정의한 스토리지 클래스에 대한 영구 볼륨 클레임을 생성한다.
kubectl apply -f fsxL-dynamic-claim.yaml
kubectl describe pvc/fsx-lustre-dynamic-claim
kubectl get pvc
15분 정도 기다리면 "Pending" 상태에서 "Bound" 상태로 변경된다.
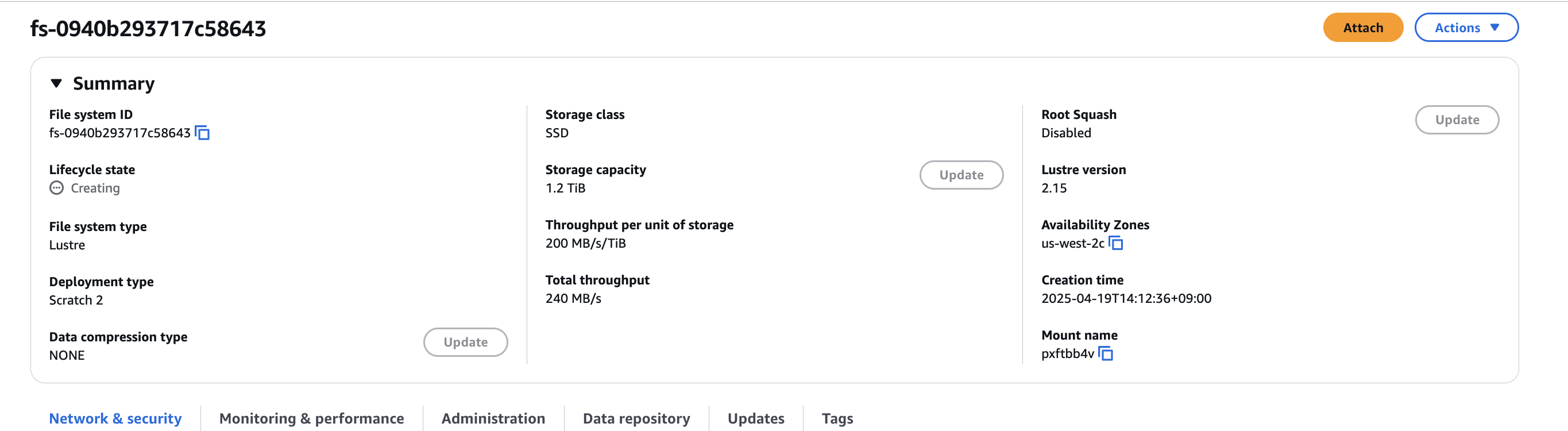
새로운 PV와 Amazon S3 버킷에 연결된 관련 FSx for Lustre 파일을 생성했다. 영구 볼륨을 위해 FSx for Lustre를 사용하는 StorageClass 정의를 생성하고, Pod가 생성된 영구 볼륨에 접근할 수 있도록 영구 볼륨 클레임을 생성했다.
[Performance testing]
aws ec2 describe-subnets --subnet-id $SUBNET_ID --region $AWS_REGION | jq .Subnets[0].AvailabilityZone
cd /home/ec2-user/environment/eks/FSxL
vi pod_performance.yaml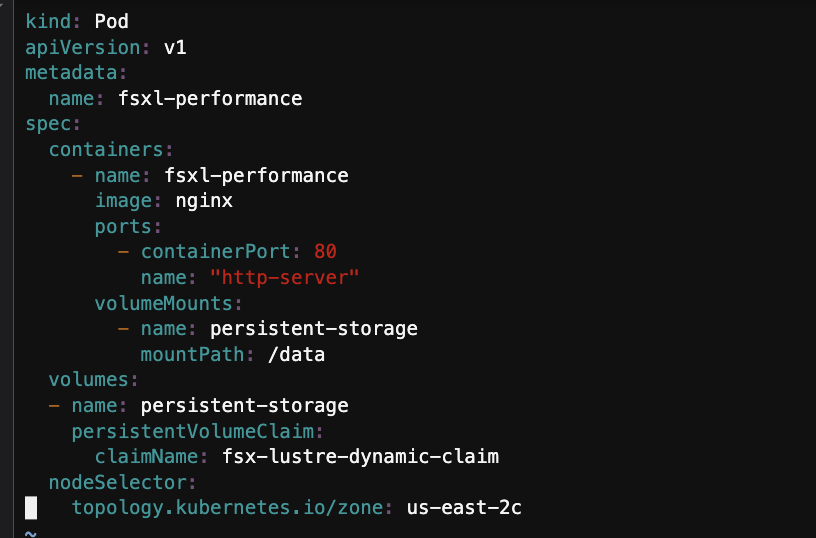
아래 두줄 주석을 해제한다.
kubectl apply -f pod_performance.yaml
kubectl get pods
FSx for Lustre 파일 시스템의 지연 시간을 테스트하려면 아래 IOping 명령을 실행해본다.
kubectl exec -it fsxl-performance -- bash
apt-get update
apt-get install fio ioping -y
ioping -c 20 .
mkdir -p /data/performance
cd /data/performance
fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=fiotest --filename=testfio8gb --bs=1MB --iodepth=64 --size=8G --readwrite=randrw --rwmixread=50 --numjobs=8 --group_reporting --runtime=10
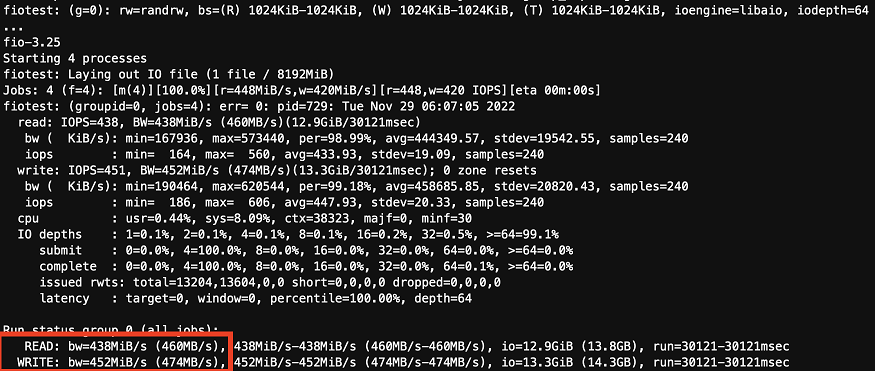
FIO와 IOping 도구를 사용하여 Amazon FSx for Lustre 파일시스템의 성능 테스트를 성공적으로 완료했다.
