
Overview
모두가 흔히 알고 있는 World Wide Web 줄여서 WWW는 우리가 알고있는 웹의 아버지라 불리는 팀 버너스 리에 의해 탄생했습니다.
SDF(SBS D FORUM)2013의 팀 버너스리의 기조연설을 참조하면 그가 WWW(world wide web)을 만든 이유는 지구 반대편에 떨어져 있더라도 각자의 머리에 반쯤 형성된 해답이 웹을 통해 합쳐져 비로소 진정한 솔루션을 찾아내는 것에 목표를 두었습니다.
1989년에 팀 버너스 리는 CERN(고에너지 물리학 연구소)에서 근무하던 당시 CERN의 연구 정보를 시간대와 대륙을 넘어 배포할 수 있는 방법을 고민했습니다.
이에 그는 인터넷을 통해 하이퍼텍스트 시스템을 구축하자는 제안서를 작성하게 되었고 이는 WWW의 초창기 이름인 Mesh(그물망)으로 불렸습니다.
실제 CERN에서는 웹은 원래 전 세계 대학과 연구소의 과학자들 간 자동 정보 공유에 대한 수요를 충족하기 위해 구상되고 개발 되었다고 말합니다.
실제 1990년대에 구현되면서 World Wide Web 으로 이름이 바뀌게 되었으며, 4개의 기본구성 요소로 구축되었습니다.
- 하이퍼텍스트 문서를 표현하는 텍스트 형식(HTML)
- HTML을 교환하기 위한 간단한 하이퍼텍스트 전송 프로토콜(HTTP)
- HTML을 표시 하거나 편집하기 위한 클라이언트(Web Browser)
- HTML에 대한 엑세스 권한을 부여하기 위한 서버(HTTPD - 웹 서버)
이 4개의 구성요소를 통해 1991년 초에 첫 번째 서버가 CERN 외부에서 실행되었으며, 이를 공개 프로젝트로서 WWW가 공식적으로 시작된 것으로 간주합니다.
2013년 CERN은 웹의 탄생 20주년을 기념하기 위해 1991년 개발한 세계 최초 웹 페이지를 복원하기도 했습니다.
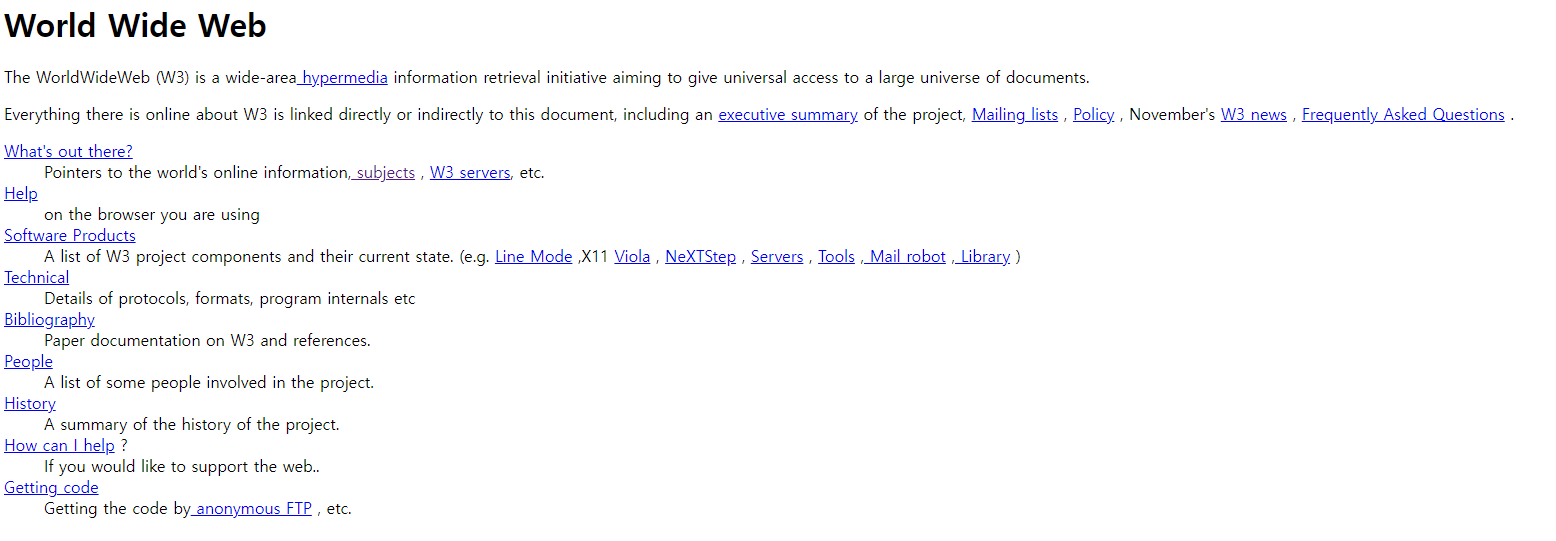
이번 글에선 이런 웹 페이지를 전송하는 데 사용되는 가장 일반적인 Hypertext Transfer Protocol(HTTP)에 대해 알아보려 합니다.
OSI / TCP
먼저 네트워킹 세계에서 호스트 간의 통신 및 데이터 전송 프로토콜에서 가장 이야기되는 모델은 OSI/ISO 모델과 TCP/IP 모델이 있습니다. 보통 OSI 7계층과 TCP 4계층으로 불리우고 있습니다.
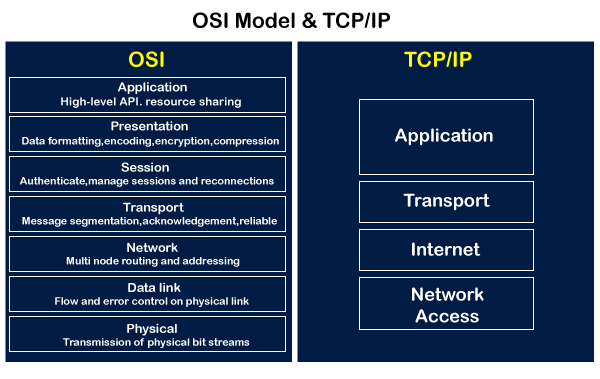
OSI Model
먼저 OSI 는 국제전기통신연합(ITU)와 국제표준화기구(ISO)에서 발표한 개방형 시스템 상호연결 모델을 의미합니다.
쉽게 말하면, 서로 다른 컴퓨터 시스템 혹은 네트워크 장비가 서로 연결되어 통신할 수 있도록 하는 표준 이라고 할 수 있습니다.
OSI/ISO 계층 모델은 7개의 계층으로 구성되어 있으며, 단계로 보았을 때 나누어져 있는것 처럼 보이지만, 각 계층은 밀접하게 연결되어 있습니다.
각 계층 내의 장치들은 PDU(Protocol Data Unit)이라고 하는 특정 형식의 데이터 단위로 데이터를 교환합니다.
간단하게 예를 든다면, 응용 계층에서 생성된 데이터는 표현 계층에서 형식과 표현을 변환한 합니다.
이후, 세션 계층에서 전송을 관리하고 이후 전송 계층에서 데이터의 분할, 재조합, 오류 제어를 진행하고 네트워크 계층을 통해 전달 경로를 설정하는 작업을 합니다.
이 데이터는 데이터 링크 계층을 통해 프레임으로 포장하여 물리 계층을 통해 전기 신호 혹은 광신호 등으로 변환하여 물리적 매체를 통해 전송합니다.
TCP Model
TCP/IP 모델은 OSI 모델의 전송 계층(4계층)에 해당하는 프로토콜로 우리가 범용적으로 사용하는 TCP 프로토콜과 IP 프로토콜을 OSI 7계층 형식에 맞추어 더 추상화(혹은 간략화) 시킨 모델입니다.
컴퓨터는 서로 통신하는 경우, 특정 규칙 혹은 프로토콜을 사용해 순서대로 데이터를 전송 및 수신이 가능합니다. TCP/IP는 통상적으로 사용되는 프로토콜 중 하나로, 일반적인 기능은 메일, 컴퓨터간 파일의 전송, 원격 로그인 등이 있습니다.
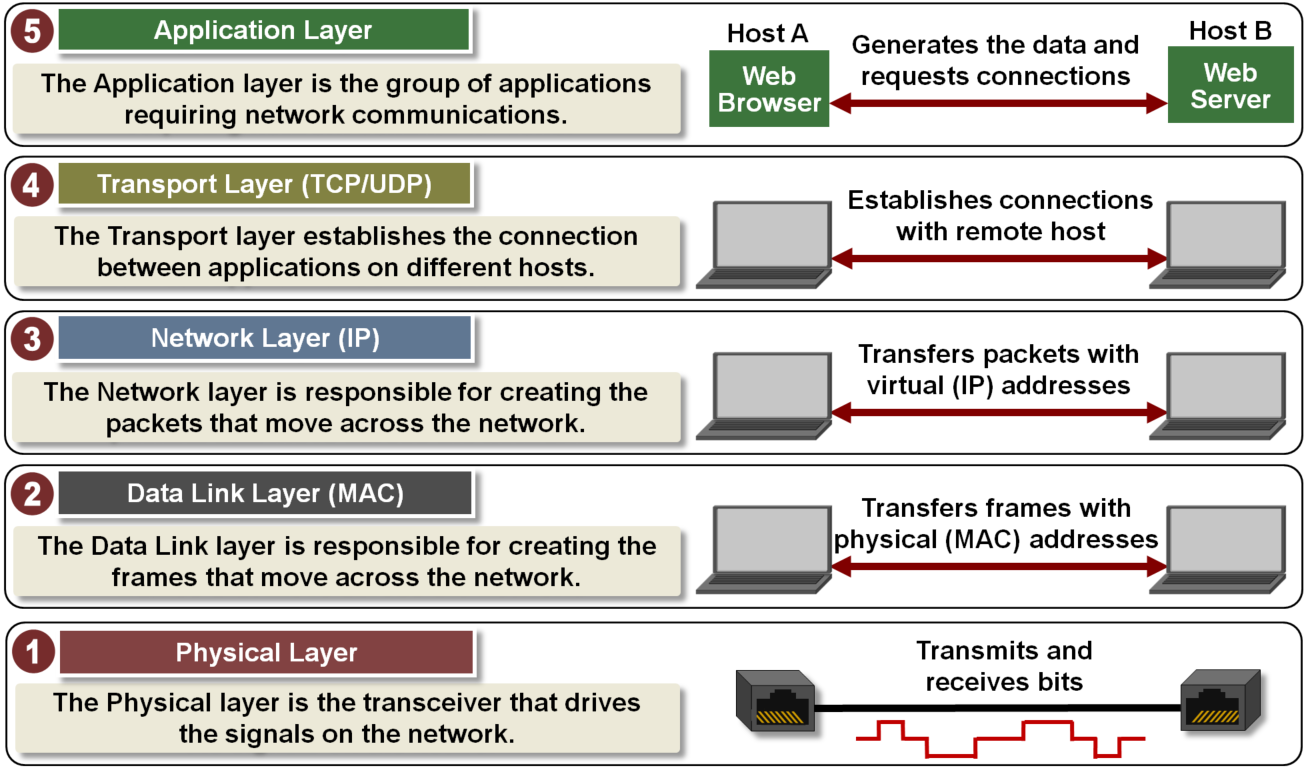
이러한 TCP(Transmission Control Protocol)는 애플리케이션으로 부터 데이터를 수신하고 이를 패킷이라는 작은 조각으로 나누어 대상 주소를 추가하여 다음 프로토콜 계층인 인터넷 네트워크 계층을 따라 패킷을 넘깁니다.
인터넷 계층은 패킷을 IP(인터넷 프로토콜) 데이터그램에 포함한 후 데이터그램 전송위치를 결정하여 네트워크 인터페이스 계층으로 넘깁니다.
네트워크 인터페이스 계층은 IP 데이터그램을 승인하고 이더넷이나 토큰 링 네트워크와 같은 특정 네트워크 하드웨어를 통해 이들을 프레임으로 전송합니다.
TCP는 신뢰적이고 연결지향적이라는 특성이 있으며, 이를 보장하기 위해 SYN와 ACK를 사용한 handshaking 과정을 통해 연결과 연결 해제를 합니다.
최근 기존 4계층이라 불리던 TCP/IP는 인터넷 개발 이후 꾸준히 갱신되며 하위 레이어가 다시 세분화 되어 5계층으로 불리고 있는 추세입니다.
이때 연결에는3-way-handshake, 해제에는 4-way-handshake를 사용하죠. 해당 부분에 대해서 간단하게 짚어 보겠습니다.
3-way-handshake
TCP는 신뢰성을 확보하기 위해 연결시 3-way-handshake라는 작업을 수행합니다. 진행 순서는 아래와 같습니다.
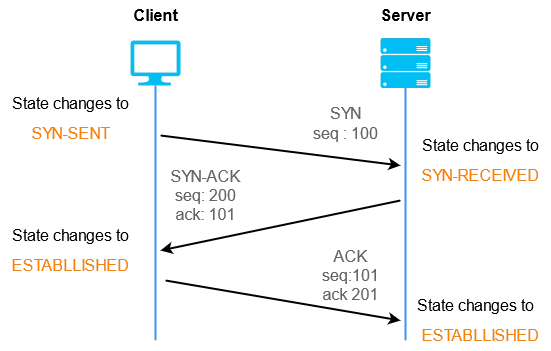
- SYN : 클라이언트는 서버에
임의의 시퀀스 번호인 ISN을 담아 SYN를 보냅니다.- SYN+ACK : 서버는 SYN를 수신후,
자신의 ISN과 승인번호로 클라이언트의ISN + 1을 보냅니다.- ACK : 클라이언트는 서버의 ISN + 1한 값인 승인번호를 담아 ACK를 서버에 보냅니다.
4-way-handshake
TCP는 연결을 해제할 때 4-way-handshake를 통해 연결을 해제하며 진행 순서는 아래와 같습니다.
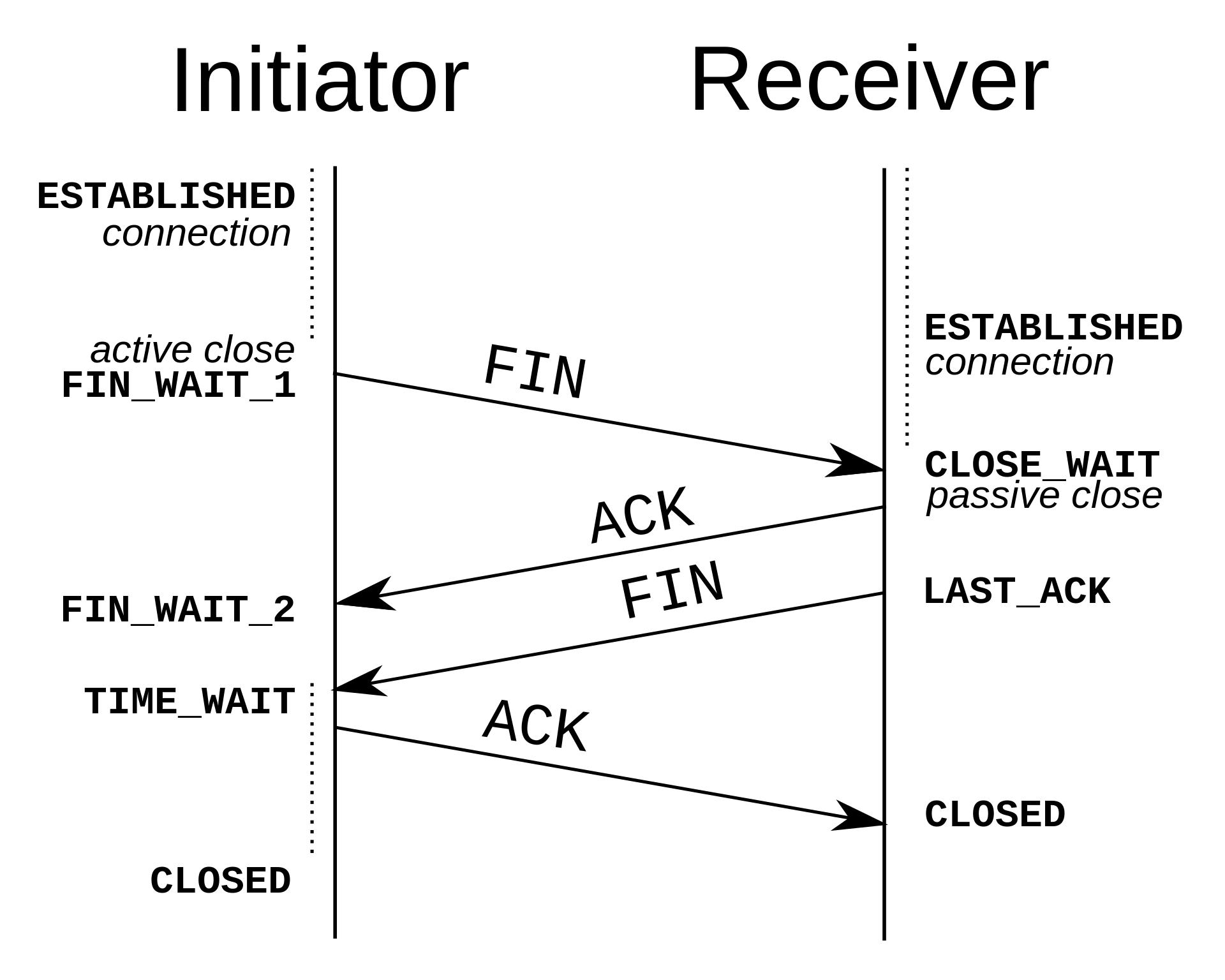
- 먼저
FIN으로 설정된 세그먼트를 서버에 전달합니다. 그리고 클라이언트는FIN_WAIT_1상태로 서버의 응답을 기다립니다.- 서버는 클라이언트로
ACK라는 승인 세그먼트를 보내며,CLOSE_WAIT상태로 변경됩니다. 클라이언트는세그먼트를 받으면FIN_WAIT_2상태로 들어가게 됩니다.- 서버는 ACK를 보내고 일정 시간 이후에 클라이언트에
FIN이라는 세그먼트를 전달합니다.- 클라이언트는
TIME_WAIT상태가 되며, 다시 서버로 ACK를 보내고 서버는CLOSED상태로 전환됩니다. 이후 일정 시간을 대기한 후 연결이 닫히고 모든 연결이 해제됩니다.
이때 TIME_WAIT은 소켓이 바로 소멸되지 않고 일정 시간 유지되는 상태를 말하며 이는 패킷이 늦게 도달하고 이를 처리하지 못하는 경우 발생하는 데이터 무결성 문제 혹은 클라이언트와 서버의 연결이 확실히 닫혔는지를 확인하기 위한 상태입니다.
HTTP가 아닌 OSI/TCP를 먼저 설명한 이유는
HTTP 통신도 기본적으로 TCP 통신 위에서 동작되는 구조이기 때문입니다. 다만 HTTP는 TCP/IP 스택에 의존하여 TCP의 기능을 사용하지만 정의된 프로토콜 자체가 다르기 때문에 같다고 볼 순 없습니다.
HTTP는 TCP 통신위에서 동작하는 구조라는 말은 HTTP 통신이 이루어지기 위해선 TCP통신을 거져야 한다는 이야기입니다.
즉, HTTP 통신을 하기 위해서는 OSI 계층의 TCP 기반인 4계층에서 3-way-handshake로의 연결과정을 거치고, OSI 7계층에서 HTTP 프로토콜 기반으로 데이터전송을 진행하며, 다시 4계층에서 4-Way-Handshake로 연결을 종료하는 과정을 거칩니다.
이때 연결은 전송 계층에서 제어되므로 기본적으로 HTTP의 범위를 벗어나는 일이고 HTTP 에서는 신뢰할 수 있거나 메시지가 손실되지 않아야 하기에, 신뢰할 수 있는 연결 기반인 TCP 표준을 사용하는 것입니다.
정리하자면, HTTP 도 TCP 기반이기 때문에 TCP와 같이 소켓 기반으로 통신을 하지만, 4계층에서 사용되는 TCP 통신의 데이터 전송에서 사용되는 소켓과, 7계층에서 사용되는 HTTP 통신의 데이터 전송의 소켓은 다르게 동작합니다.
그렇기에, HTTP 통신은 소켓기반의 통신은 맞지만 TCP 통신의 특징중 하나인 양방향이 아닌 단방향으로 동작하는 것이죠.
물론 이를 극복하기 위해 양방향이면서 실시간 통신이 필요한 상황에 대해 여러 기술이 나왔으며, 그중 web socket(웹소켓)은 이를 만족하며, IP와 포트를 사용한 통신을 한다는 점이 있지만, 마찬가지로 해당 웹 소켓또한 위의 내용과 같이 TCP의 소켓과는 엄연히 다른 것으로 봐야합니다.
HTTP
HTTP는 HTML 문서와 같은 리소스를 가져올 수 있는 프로토콜 입니다. 실제 웹에서 이루어지는 모든 데이터 교환의 기반이되는 Client - Server 프로토콜입니다.
서버는 HTTP를 따르는 브라우저로 부터 Request를 전달 받고, 브라우저가 파싱 할 수 있는 HTTP로 Response를 전달합니다.
HTTP 는 WWW의 기본 프로토콜로 시간이 지나며 많은 변화를 거치는 동안 단순성을 유지하면서도 유연성을 강화하게 되었습니다.
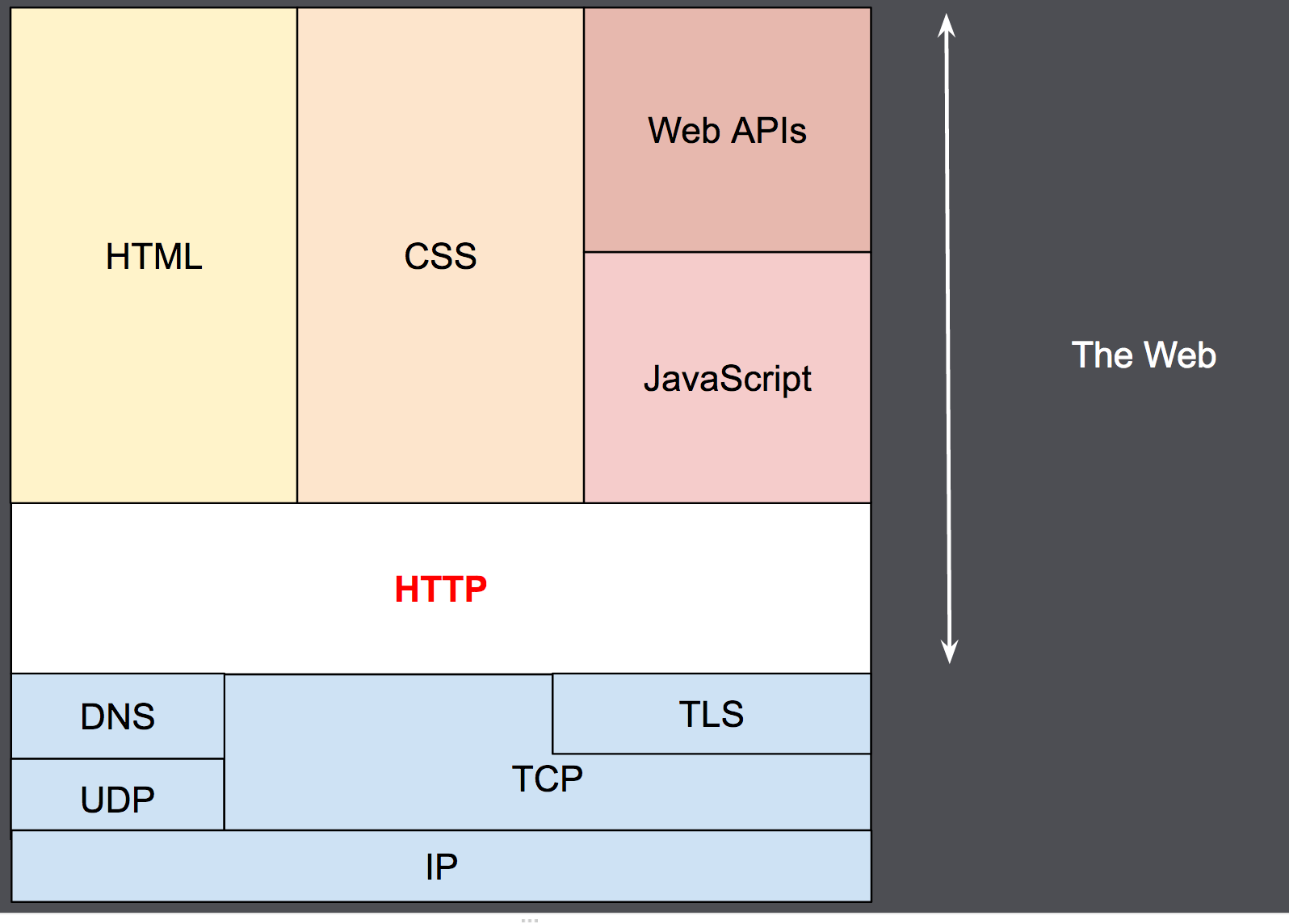
HTTP의 통신 흐름
클라이언트가 서버와 통신하는 경우 HTTP의 통신은 간단하게 아래와 같은 순서로 통신이 이루어집니다.
1. TCP 연결을 맺습니다.
TCP 연결은 요청을 하나 혹은 여러개를 보내고 응답을 받는데 사용되며, 이때 클라이언트는 새 연결을 열거나, 기존 연결을 재사용하거나, 여러 개의 TCP 연결을 시도할 수 있습니다.
2. HTTP 메세지를 보냅니다.
HTTP/2 이전버전의 경우 HTTP 메시지를 사람이 읽을 수 있지만, HTTP/2에서는 이러한 간단한 메시지가 프레임으로 캡슐화되어 직접 읽을수는 없습니다. 다만 메세지를 보내는 원칙은 동일하게 유지됩니다.
ex)
GET / HTTP/1.1
Host: www.naver.com
Accept-Language: ko3.서버로부터 보내진 응답을 읽습니다.
ex)
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html>… (here come the 29769 bytes of the requested web page)4. 이후의 추가 요청을 위해 연결을 닫거나, 기존 연결을 재사용합니다.
HTTP 메세지
HTTP 메시지는 서버와 클라이언트 간에 데이터가 교환되는 방식입니다. 메시지에는 클라이언트가 서버에 동작을 트리거 하기위한 요청과, 서버의 응답을 받기위한 요청 두 가지의 유형이 있습니다.
보통 이런 HTTP의 메시지는 개발자들이 직접 작성하는 경우는 거의 없으며, 보통은 소프트웨어, 웹 브라우저, 또는 웹서버가 이러한 요청을 대신 작성해 줍니다.
프록시 또는 서버의 경우 구성파일, 브라우저의 경우 우리가 흔히 알고 있는 API를 통해 이러한 HTTP 메시지를 제공합니다.
HTTP 요청과 응답은 유사한 구조를 공유하고 있으며, 기본적인 구조는 아래와 같습니다.
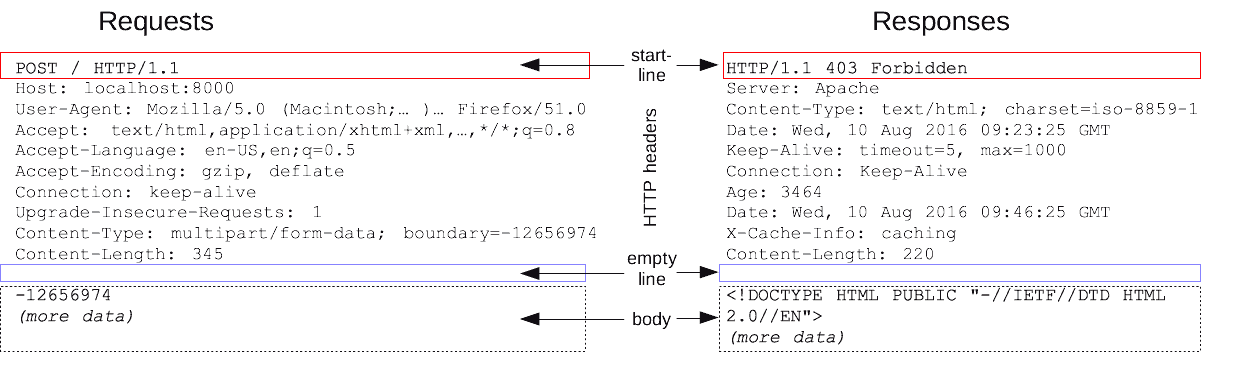
- start-line : 구현할 요청을 설명하는 줄 또는 성공과 실패에 대한 여부를 나타내는 상태줄로 항상 한 줄입니다.
- HTTP header 집합 : 요청을 지정하거나 메시지에 포함된 본문을 설명하는 선택적 HTTP 헤더 집합
- blank-line : 요청에 대한 모든 메타 정보가 정송되었음을 알리는 빈 줄
- body : 요청과 관련된 데이터 혹은 응답과 관련된 문서가 포함된 선택적 본문 입니다. 존재 여부와 크기는 시작줄 혹은 HTTP 헤더에 의해 지정됩니다.
그럼 요청과 응답 메세지에 대한 구조를 나누어서 보도록 하겠습니다.
HTTP Request
Start Line
요청의 경우 클라이언트가 서버에 작업을 시작하기 위해 보내는 메시지로 start-line에는 세 가지의 요소가 포함됩니다.
- 수행해야 할 작업을 설명하는
HTTP 메소드(GET, PUT, POST 등)입니다.요청대상(일반적으로 URL, 도메인의 절대경로, 포트)으로 일반적으로 요청 컨텍스트에 의해 특정지어 집니다. 또한 이 요청형식은 HTTP 메서드마다 다릅니다.- 나머지 메시지의 구조를 정의하는
HTTP 버전으로, 응답에 사용할 것으로 예상되는 버전을 나타냅니다.
ex)
GET(요청 메소드) /background.png(Path or Query) HTTP/1.0(Http Version)Headers
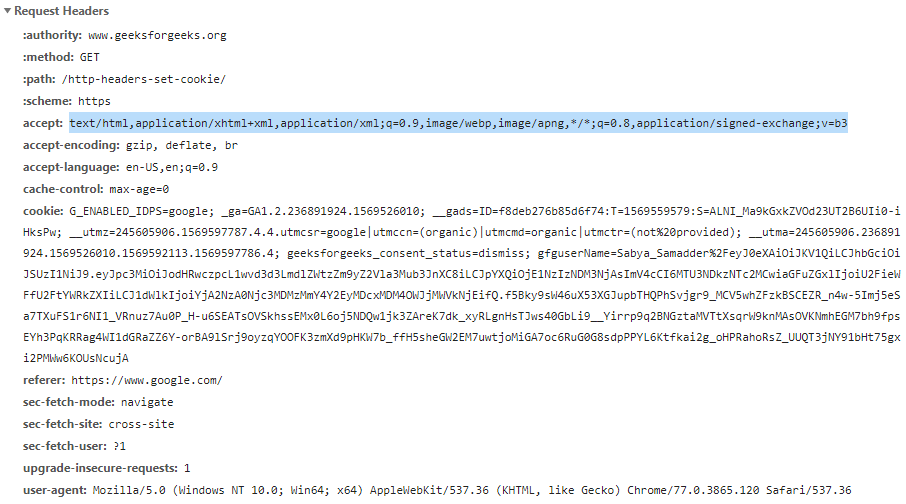
요청에 대한 HTTP 헤더는 대소문자를 구분하지 않는 문자열과 콜론(:)으로 구성된 HTTP 헤더의 기본 구조를 따릅니다.
요청에는 다양한 헤더가 표시될 수 있으며, 헤더는 여러 그룹으로 나눌 수 있습니다.
- Request headers : 서버가 응답을 맞춤 설정할 수 있도록 요청 컨텍스테 대한 정보를 제공하기 위해 서용됩니다.
accept의 경우허용되는 응답 형식과선호하는 응답 형식을 의미합니다.
- General headers : 요청 및 응답 메시지 모두에 사용될 수 있지만 콘텐츠 자체에는 적용되지 않는 HTTP 헤더를 지징합니다. 보통 Date, Cache-Control, Connection 등이 포함되어 있습니다.
- Representation headers : 메시지 데이터의 원래 형식과 적용된 인코딩(메시지 body가 있는 경우)을 설명하는 Content-Type 과 같은 형식입니다.
Body
요청의 마자막 부분에 해당합니다. 다만 모든 요청에 Body가 있지는 않습니다.
GET, HEAD, DELETE 또는 OPTIONS와 같이 리소스를 가져오는 요청에는 일반적으로 본문이 필요하지 않습니다. 일부 요청은 서버를 업데이트 하기 위해 데이터를 서버로 전송하는데 POST요청 등이 이에 해당합니다.
HTTP Reponse
Status Line
상태표시줄이라고 하는 HTTP Response의 시작 줄에는 아래와 같은 정보들이 포함됩니다.
- 프로토콜 버전(보통은 HTTP/1.1)
- 요청의 성공 또는 실패를 나타내는 상태코드를 나타냅니다.(주 상태코드는 200, 404, 302 입니다.)
- 상태 코드에 대한 간략한 정보성 텍스트 설명(예를 들어
HTTP/1.1 404 Not Found등입니다.)
Headers
응답에 대한 HTTP 헤더는 다른 헤더와 동일한 구조, 즉 대소문자를 구분하지 않는 문자열 뒤에 콜론(':')과 헤더의 유형에 따라 구조가 달라지는 값으로 구성됩니다. 해당 값을 포함한 전체 헤더는 한 줄로 표시됩니다.
HTTP Response에는 다양한 헤더가 표시되며, 이러한 헤더는 여러 그룹으로 나뉘게 됩니다.
- General header : 위의 HTTP Request와 마찬가지로 바디에서 최종적으로 전송되는 데이터와는 관련이 없는 헤더입니다.
- Response header : 메시지 콘텐츠와 관련없는 헤더로 보통 위치 또는 서버 자체에 대한 정보(이름, 버전)과 같은 부가적인 정보를 갖습니다.
- Representation headers : HTTP Response에 Body가 있는 경우에만 존재하는 헤더로 메시지 데이터의 원래 형식과 적용된 인코딩을 설명하는
Content-Type과 같은 형식입니다.
Body
응답의 마지막 부분으로 모든 응답에 Body가 있지는 않습니다. Body의 경우 크게 세 가지 범위로 나눌 수 있습니다.
- 알려진 길이의 단일 파일로 구성된 단일 리소스 본문으로
Content-Type및Content-Length두 개의 헤더로 정의 됩니다.- 길이를 알 수 없는
단일 파일로 구성된 단일 리소스 본문으로 전송 인코딩이 청크로 설정되어 있습니다.여러 부분으로 구성된 본문으로, 각각 다른 정보 섹션을 포함하는 다중 리소스 본문입니다.
HTTP Connectionless
HTTP는 Connectionless 방식으로 클라이언트 - 서버 간의 통신 과정에서 요청에 대한 응답이 도착하면 접속을 끊습니다.
이는 매번 요청을 진행할 때마다 TCP의 3-way-handshake와 4-way-handshake 등의 요청을 초기부터 다시 진행해야 하는 번거로움이 있으며, 결국 TCP 여결 과정에서 생기는 round-trip으로 인해 latency가 증가하게 됩니다.
이를 위해 HTTP keep-alive가 있으며, 이는 HTTP의 Persistent connection을 맺는 기법중 하나로 HTTP/1.0부터 지원하고 있습니다.
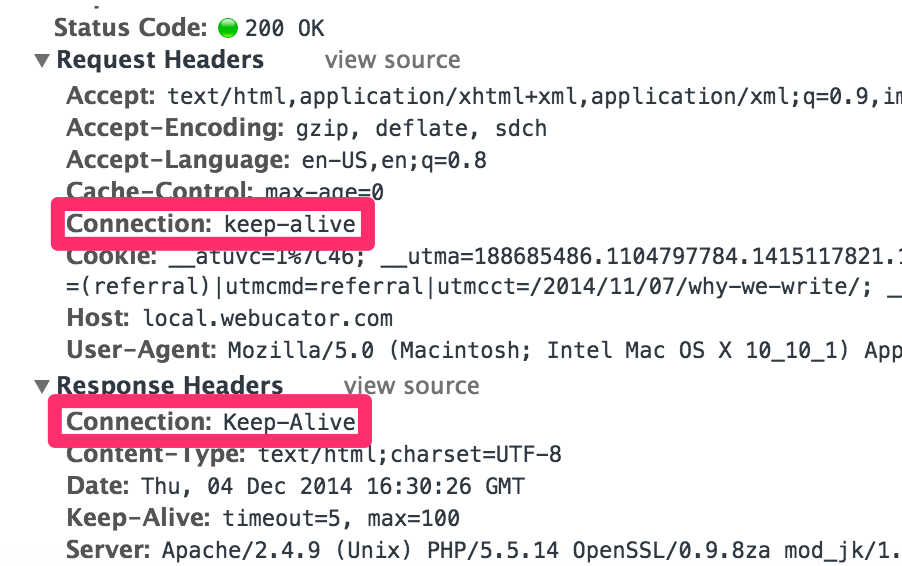
해당 옵션을 헤더에 설정을 통해 요청하는 경우 connection이 idel한 상태로 얼마동안 유지될지, 또한 keep-alive connection을 통해 주고받을 수 있는 request의 최대 갯수 등을 지정하여, 연결을 유지할 수 있습니다.(다만 이때 서버측도 keep-alive connection`을 지원 해야 합니다.)
다만, keep-alive 의경우 서버와 클라이언트 사이에 Proxy 서버가 있는 경우 해당 proxy 서버가 keep-alive를 지원하지 않을시 해당 옵션을 extension header로 인식하여 정상적으로 동작하지 않는 설계적인 문제가 있습니다.
실제 HTTP/1.1의 경우 해당 옵션을 별도로 설정하지 않아도 서버가 응답한 뒤에 계속 재사용할 수 있다고 가정합니다. 다만 connection을 종료할 경우 명시적으로 Connection : close 헤더 입력을 통해 종료가 가능합니다.

HTTP/2 에서는 해당 옵션(connection 과 keep-alive)이 실제 표준에서 빠지게 되었으며, 연결 관리는 다른 메커니즘에 의해 처리되게 됩니다. 주의할 점은 HTTP에서 해당 옵션이 표준에서 빠진것이지, keep-alive에 대한 개념이 사라진것은 아닙니다.
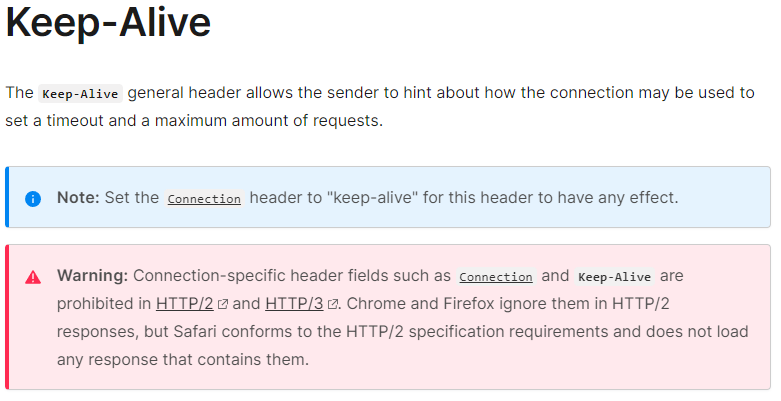
HTTP/2에선 Stream multiplexing 처럼 하나의 TCP 연결에서 여러 HTTP Request/Response를 동시에 전송하는 방법이나 Header compression으로 HTTP 헤더의 크기를 줄여 TCP 세그먼트 헤더의 오버헤드를 줄이는 방법등으로 성능을 향상시키고 있습니다.
HTTP Stateless
HTTP는 상태 비저장형이라는 말을 들어본 적이 있을 겁니다. 클라이언트(브라우저)와 서버(XXX.com) 간에 통신이 이루어지는 WWW에서 클라이언트는 서버로 다양한 명령을 보내고 서버는 해당 명령에 대한 응답을 합니다.
이때 각각의 명령은 이전 명령에 대해 알지 못하며 독립적으로 실행됩니다. 마찬가지로 서버는 여러 요청이 진행되는 동안 사용자에 대한 정보를 보관할 필요가 없는 기록된 연속성이 없습니다.
쉽게 말해, HTTP Stateless란 일반적으로 서버인 수신자가 세션 정보를 보유하지 않는다는 뜻입니다. 이 덕분에 클라이언트와 서버 간의 통신을 단순화하고 전송되는 데이터양을 최소화할 수 있습니다.
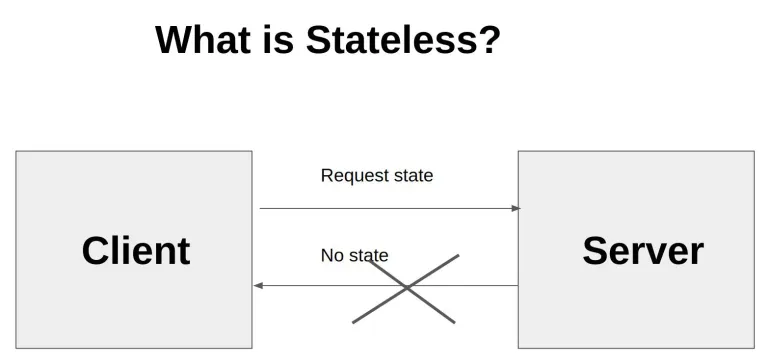
다만 이러한 방식은 사용자의 입장에서 매우 번거로운 작업이 될 수 있습니다. 버튼을 클릭하거나, 새로고침을 할 때마다 로그인을 다시 해야할 수도 있기 때문이죠. 그렇다면 이러한 HTTP Stateless는 어떻게 해결할 수 있을까요?
Cookie
HTTP의 cookie는 서버가 사용자의 웹 브라우저로 전송하는 작은 데이터 입니다. 브라우저는 이 조각을 저장했다가 이후 요청이 있을때 동일한 서버로 다시 전달할 수 있습니다.
이를 통해 사용자가 로그인 상태를 유지하고 있는지 확인하는데 사용될 수 있으며, 이는 Statless한 HTTP 프로토콜의 상태 정보를 기억합니다.

쿠키는 클라이언트에게 안전하게 전송되기 위해 두 가지 방법을 사용합니다. 이때 보안속성과 HttpOnly 속성을 사용하여 안전하게 전달할 수 있습니다.
이번 글에서는 다루지 않는 HTTPS를 활용하면, HTTPS프로토콜을 통해 암호화된 요청과 함께 서버로 전송이 되며, 이는 중간에 해당 쿠키에 다른 제 3자가 쉽게 접근할 수 없습니다.(HTTP 프로토콜을 사용하는 경우 해당 쿠키에 대한 접근이 더 쉽습니다.)
HTTPS프로토콜을 사용한다고 해서 모든 액세스를 차단한다고 가정할 순 없습니다. 예를 들어 클라이언트의 하드 디스크 또는 javsCript에 액세스할 수 있는 사람은 해당 정보를 탈취할 수 있습니다.
이때 HttpOnley를 사용하여, 해당 문제를 막을 수 있으며, 이러한 설정은 크로스 사이트 스크립팅(XSS)를 방어하는데 도움이 됩니다.
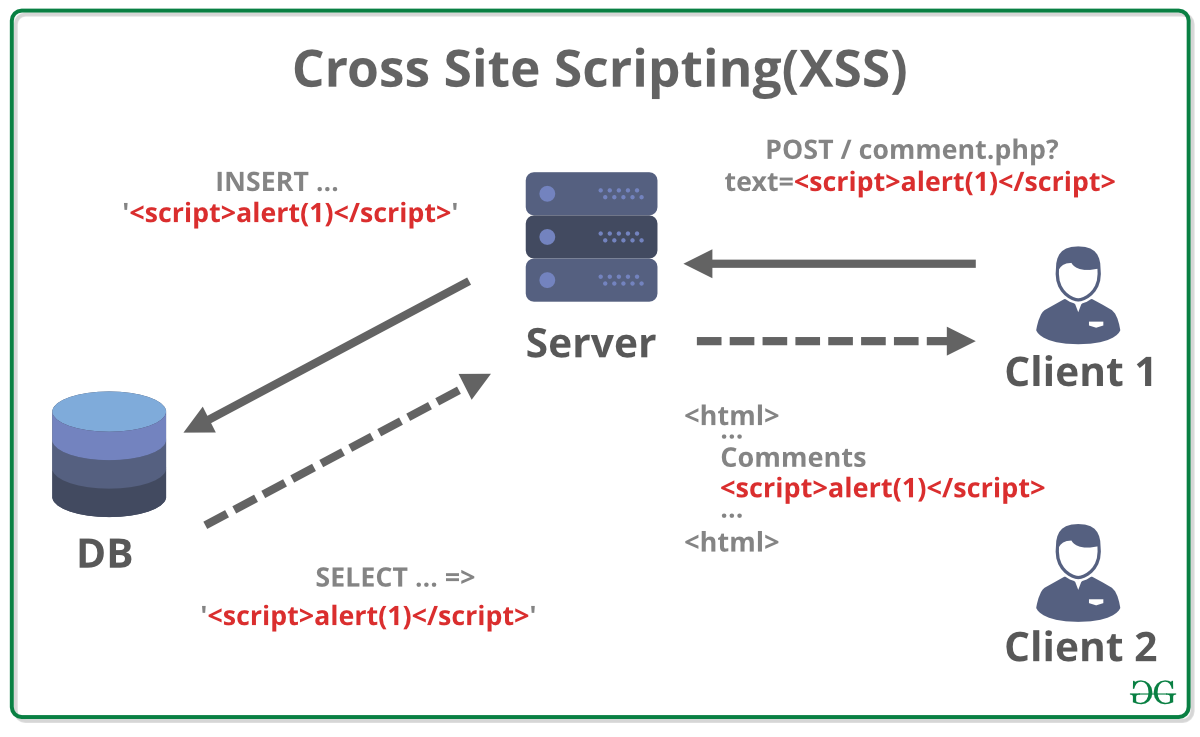
XSS(Cross Site Scripting)란?
웹 사이트의 어드민(관리자)이 아닌 악의적인 목적을 가진 제 3자가 악성 스크립트를 삽입하여 의도하지 않은 명령을 실행시키거나 세션 등을 탈취할 수 있는 취약점입니다.
이러한 쿠키의 단점은 만일 사용자가 여러 기계(핸드폰, 노트북, 컴퓨터 등)을 사용하여 웹 사이트에 로그인 하는 경우, 해당 서버는 이를 개별 사용자로 인식하기때문에 3번의 로그인이 필요한 불편한 상황이 발생할 수 있습니다.
또한 클라이언트의 브라우저에 저장되어 있는 모든 쿠키 값을 최종 사용자가 볼 수 있고 변경할 수 있다는 점에 유의해야 합니다. 이는 공공장소 혹은 공유가 가능한 공간에서 탈취의 우려가 있기도 합니다.
한번 탈취된 쿠키는 서버가 보관하고 있는 해당 쿠키의 정보를 지우지 않는 이상 지속적으로 악의적인 요청이 가능합니다.

이에, 쿠키에는 중요한 정보(ex 회원정보 등)을 보관하지 않고, 서버에서는 예측 불가능한 임의의 랜덤 값의 토큰을 쿠키로 생성하여 클라이언트(브라우저)에게 전달하며, 서버는 해당 쿠키로 요청을 받을 경우 사용자의 정보를 매핑하여 관리하는 방법이 있습니다.
정리
사실 더 쓰고싶은 내용이 많지만 너무 방대한 범위라 기본적으로 알아야할 몇가지에 대해 작성해 봤습니다. 이후 기회가 된다면 다음에는 아직 이야기 하지 못한 HTTP security, HTTP caching 등에 대해서도 이야기 해보고 싶습니다.
참조
https://medium.com/@gwenilorac/understanding-network-models-osi-and-tcp-ip-42f94eb1aa84
https://www.ibm.com/docs/ko/aix/7.1?topic=protocol-tcpip-protocols
https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
https://www.smithsonianmag.com/smart-news/world-wide-web-was-almost-known-mesh-180964242/
