
누구나 길을 걷다 길거리에 쓰레기들이 떨어져 있는 것을 본적이 있을 거다. 만일 아무도 그 쓰레기들을 정리하지 않고 둔다면 길거리를 걸어다닐 수 있을까?
새벽이나 오후 시간에 길에서 청소를 하시는 환경미화원 분들을 본적이 있을 것이다. 그때까지 쌓였던 쓰레기들을 정리하고 길을 청소하시는 분들이다.
이번 글에서 이야기할 GC(garbage-collection) 또한 그렇다.
Heap 메모리에 더 이상 쓰지 않고 남아있는 쓰레기 객체들을 정리하지 않는 다면, 더이상 Heap 영역을 사용하지 못할것이고, 이를 우리는 흔희 Out Of Memory Error(OOME) 라고 한다.
이때 이러한 쓰레기 객체들을 정리하여 Heap영역을 확보해주는 환경미화원 같은 존재를 JVM에선 GC 라고 한다. 이번 글에선 JVM에 대한 설명과 GC에 대한 설명, 그리고 GC 튜닝까지 해보려 한다.
About JVM
JVM(Java Virtual Machine)을 직역하면 자바 가상 머신이다.
JAVA는 C언어와 다르게 OS실행환경에서 종속적이지 않는 특징이 있다. 이를 가능하도록 해주는 것이 바로 JVM이다.
JAVA, C와 같은 컴파일 언어는 각 환경에 맞춰 컴파일 과정을 거쳐야 하는데, JAVA의 경우 JAVA로 작성한 코드를 컴퓨터가 읽을 수 있도록 ByteCode로 변환 하고, 이를 각 OS 환경에서 JVM을 설치함으로써 OS가 컴파일된 ByteCode를 이해할 수 있게 해준다.
JAVA Compile
- 개발자는 Java Code를 작성하고, 이는 ByteCode로 컴파일 된다.
- Java 인터프리터에 전달된 코드가 실행하기에 적합한 상태인지 확인하는 검증(
게이트키퍼)를 거친다.- Java인터프리터를 손상시킬 염려 없이 JVM에서 실행된다.
정리하자면, 요리 레시피(java 코드)를 각전국 여러 점포에 전달(바이트코드)하고, 이를 각 점포의 요리사(JVM)가 처리하는 역할을 한다.(각 점포의 환경에 영향을 받지 않는다.)

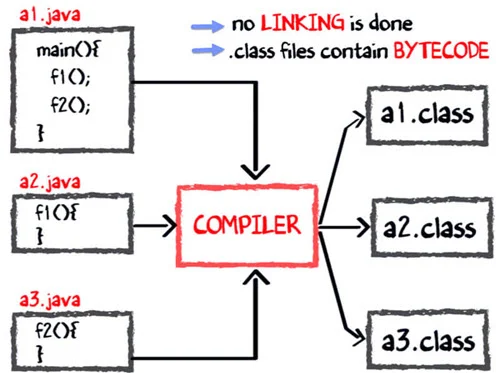
그럼 컴파일은 어떻게 진행될까
- main 메소드는 a1.java 파일에 저장된다.
- 마찬가지로 f1과 f2는 각각 a2.java와 a3.java에 저장된다.
- 컴파일러는 3개의 파일을 컴파일하여 ByteCode로 구성된 3개의 .class 확장자를 가진 파일을 생성한다.
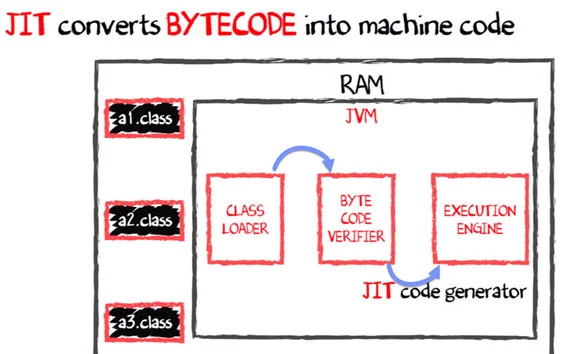
- 이후 RAM에 상주하는 JVM은 클래스 로더를 사용하여 클래스 파일을 RAM으로 가져온다.(이때 위에서 설명한 ByteCode Verifier를 거친다)
- 마지막으로 실행 엔진은
JIT컴파일러통해 바이트 코드를 네이티브 코드로 변환한다.만일 JIT가 궁금하다면 이전에 쓴 Spring GraalVm 글에서 확인할 수 있다.
JVM 아키텍쳐
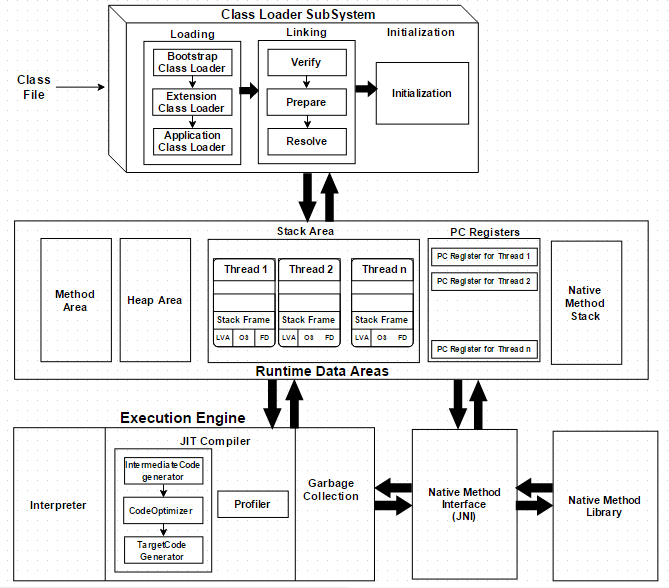
먼저 JVM은 세 가지 주요 하위 시스템으로 나뉘며 각 세부 구성은 아래와 같다.
Class Loader
JAVA의 동적 클래스 로딩 기능은 ClassLoader 하위 시스템에서 처리하며, 로드, 링크, 그리고 런타임시에 처음으로 클래스를 참조할 때 클래스 파일을 초기화 한다.
Runtime Data Areas
런타임 데이터 영역은 5개의 주요 구성요소로 나뉜다.
- Method Area : 정적 변수를 포함 모든 클래스 수준 데이터가 저장됨.
- Heap Area : 모든 개체와 해당 인스턴스 변수 및 배열이 저장됨.
- Stack Area : 모든 스레드에 대해 별도의 런타임 스택이 생성됨.
(모든 메서드 호출시에 스택 프레임이라는 하나의 항목이 만들어짐.)- PC Register : 현재 실행 중인 며령의 주소를 저장한다.
- Native Method Stack : 네이티브 메서드 정보를 보유한다.
Execution Engine
런타임 데이터 영역 에 할당된 바이트코드는 실행 엔진에 의해 실행된다
- Interpreter : 인터프리터는 바이트코드를 해석하는 역할을 한다.
- JIT Compiler : 런타임시에 기계어로 컴파일을 실행한다.
- GC : 참조되지 않는 개체를 수집하고 제거한다.
(System.gc() 를통해 트리거를 실행할 순 있지만 보장되진 않는다.)
Heap & Stack
Java에서 메모리 관리는 중요한 프로세스이며, 자동으로 관리된다. 보통 JVM은 메모리를 스택 메모리와 힙 메모리의 두 부분으로 나누며, 둘은 다른 용도로 사용된다. 이 둘의 차이점을 알아보자.
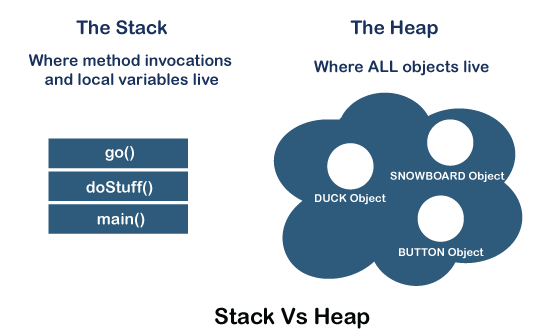
스택 메모리(Stack Memory)
스텍 메모리는 런타임에 각 스레드에 할당된 물리저 공간(RAM)이다. 스레드가 생성될 때 함께 생성되며, 스택의 메모리 관리는 전역적으로 접근할 수 있기 때문에LIFO(후입선출)순서를 따른다.(지역 변수와 매개변수가 저장되는 영역)함수가 호출되면 스택에는 함수의 매개변수, 호출이 끝난 뒤 돌아갈 반환주소값, 지역 변수등이 저장된다. 이렇게 스택 영역에 차례로 저장되는 함수의 호출 정보를
스택 프레임이라고 한다.스레드마다 자체 스택이 있어 스레드로 부터 안전하다는 특징이 있다.
참고) 저장 공간이 부족할 경우StackOverFlowError가 발생한다.
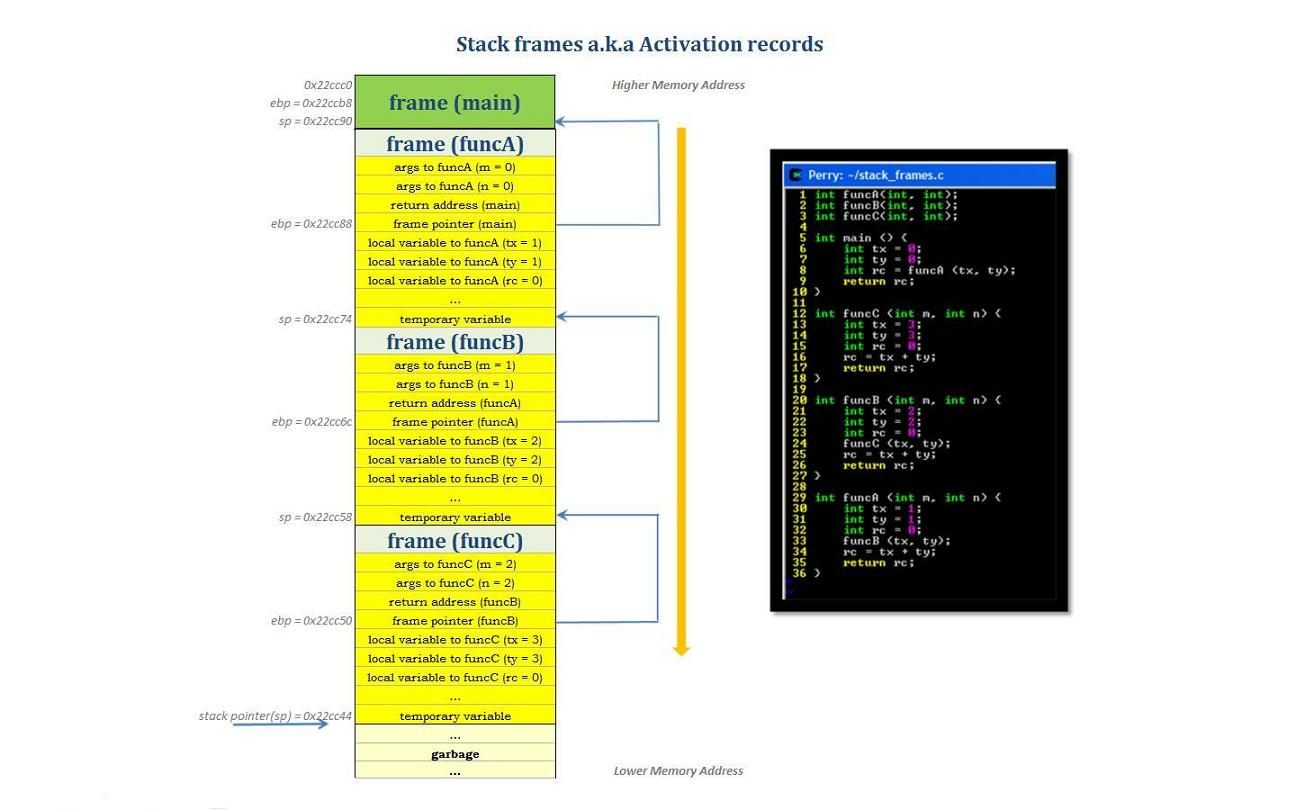
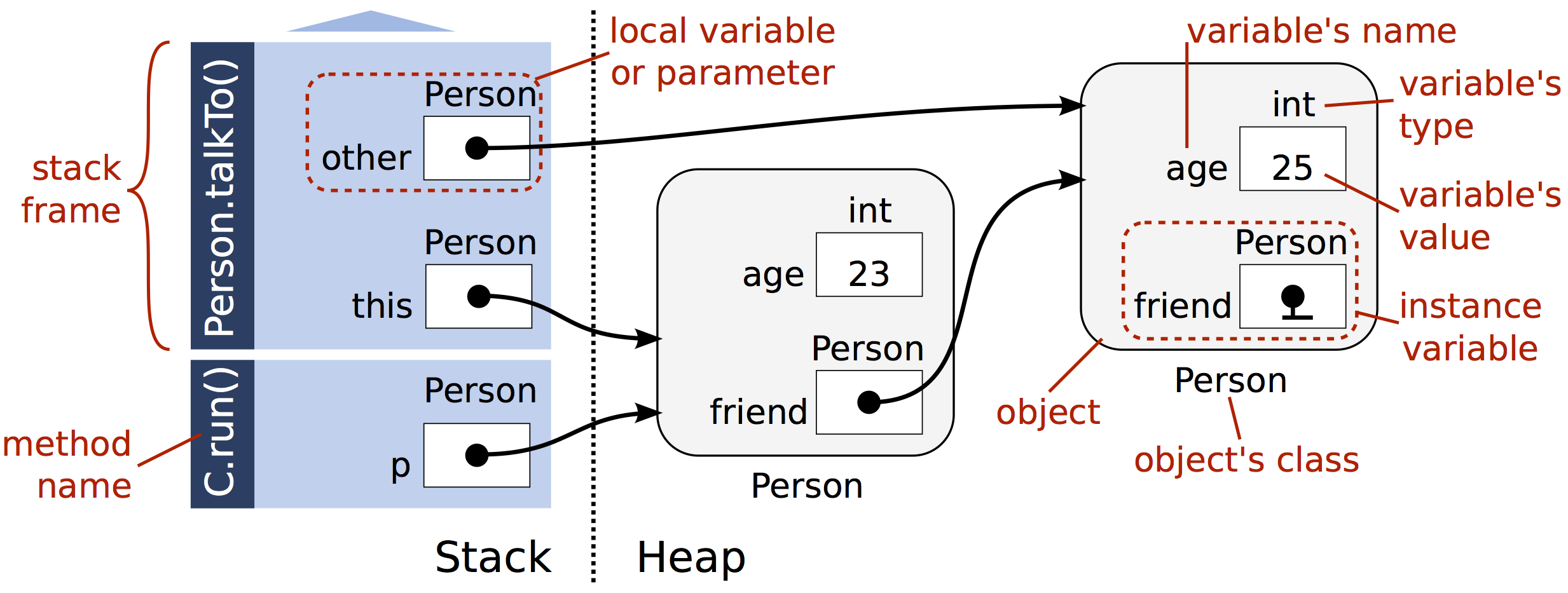
힙 메모리(Heap Memory)
JVM이 시작될 때 생성되며, 애플리케이션이 실행되는 동안 사용된다. 객체와 JRE 클래스를 저장하며, 개체를 만들 때마다 해당 개체의 참조가 스택에 생성되는 동안 개체는 힙 메모리에 쌓인다.스택과 같이 LIFO 순서를 따르진 않으며, 메모리 불록을 동적으로 처리한다.(수동으로 메모리 처리가 필요없다.) 메모리를 자동으로 관리하기 위해 더 이상 사용하지 않는 개체에 대해
GC를 제공한다.스레드로부터 안전하지 않으므로 코드의 적절한 동기화가 필요하다.
참고) 저장공간이 없으면OutOfMemoryError가 발생한다.
아래는 Stack 과 Heamp Memory의 다이어 그램이다.
GC(Garbage Collection)
그럼 Heap Memory의 더이상 사용하지 않는 개체에 대해 정리를 해주는 GC를 Heap Memory의 상세 영역과 함께 알아보자.
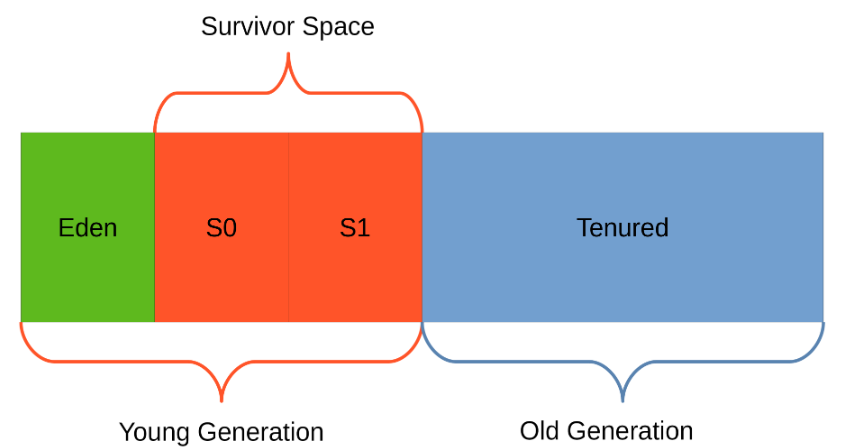
젊은 세대(Young Generation) - Minor GC
1. 새로운 객체는 항상Young Genration의Eden영역에 생성된다.
2.Eden영역이 꽉차면 Scavenge GC가 참조되지 않은 객체를 제거 한다.
3. 살아남은 객체는 survivorS1공간으로 이동한다.
4.S1에서 살아남은 개체는S2로 이동한다.(S1 과 S2는 동일한 크기이다.)Young Generation의 공간은 Old Generation에 비해 상대적으로 작기 때문에 메모리 상의 객체를 찾아 제거하는데 적은 시간이 걸린다. 이처럼 Young Generation영역에서 발생하는 GC를
Minor GC라 부른다.survivor 공간의 크기는
-XX:SurvivorRatio옵션을사용하여 Eden 공간에 상대적으로 설정이 가능하다. 예를 들어-XX:SurvivorRatio=6로 설정시에, eden과 생존자 공간 사이의 비율을 1:6으로 설정한다.이는 1
S1: 1S2: 6Eden이 되며, 각 생존자 공간의 크기는Young Generation크기의 1/8이 된다. 뒤에 나올Old Generation과Young Generation간의 비율은-XX:NewRatio를 사용하며, 서버 JVM의 기본 설정은 아래와 같다.

구 세대(Old Generation - Major GC
이름에서 알 수 있듯이 전체 GC 중 가장 오래 살아남은 개체의 영역이다.
Young Generation에서 살아남은 개체 들이며, Young Generation에 항상 비례하는 크기를 가지고 있다. 반면에 Young Generation에 비해 GC는 적게 발생하며, 이때 Old Generation에서 발생하는 GC를Major GC라고 한다.(참고로 Heap 영역 즉, Young, Old를 모두 청소하는 GC를Full GC라 한다.
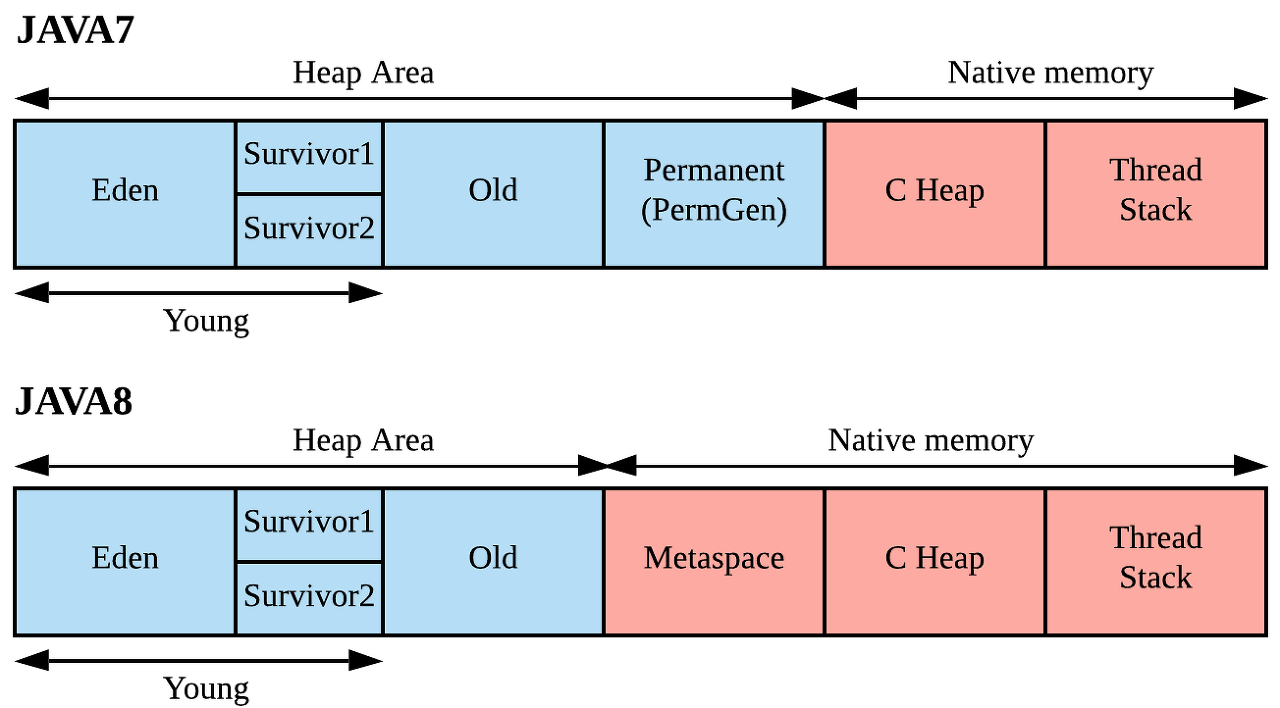
구 PermGen 현 Metaspace
기존의 PermGen 여역은 Heap 영역의 공간으로 클래스와 메소드의 메타데이터를 저장했었다. 또한 JVM이 사이즈르 지정하고, 앱이 뜨면 사이즈 변경이 되지 않았었다. JAVA에선 메타데이터를 저장하는 Perm 영역의 사이즈 제한을 없애고 사용자가(개발자) 영역 확보의 상한을 크게 의식하지 않도록 1.8 버전 이후 부터Native Memory로 옮겨가면서 이를 OS 에서 관리하게 되었다.(Heap은 JVM에서 관리한다.)Natvie 영역으로 옮겨지면서 클래스 메타 데이터를 native 메모리에 저장하고, 부족할 경우 동적으로 늘려준다.
GC Process
위에서 간단하게 동작 하는 방법을 어느정도 알 수 있지만, 좀 더 상세하게 GC 가 어떠한 프로세스로 동작하는지 확인해 보자.
- 새 개체는
Young Generation의Eden공간에 할당된다.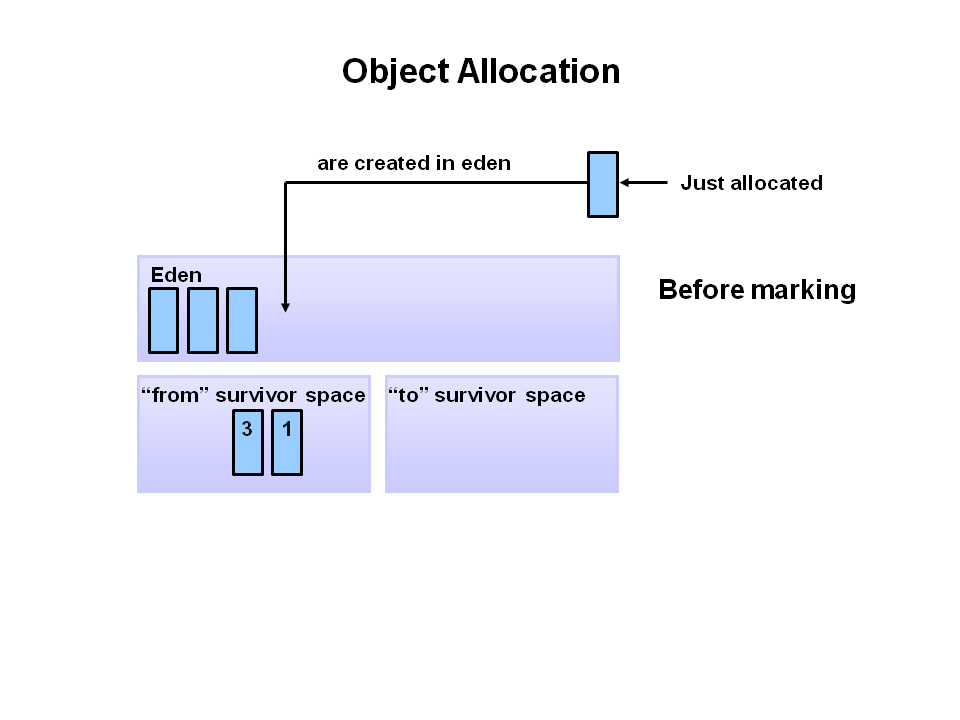
2.Eden 공간이 가득 찰 경우 Minor GC가 동작하며, 참조된 개체는
S0으로 이동되고, 참조되지 않은 개체는 Eden 공간이 지워지며 삭제된다.
(즉 사용하지 않은 개체는 삭제된다.)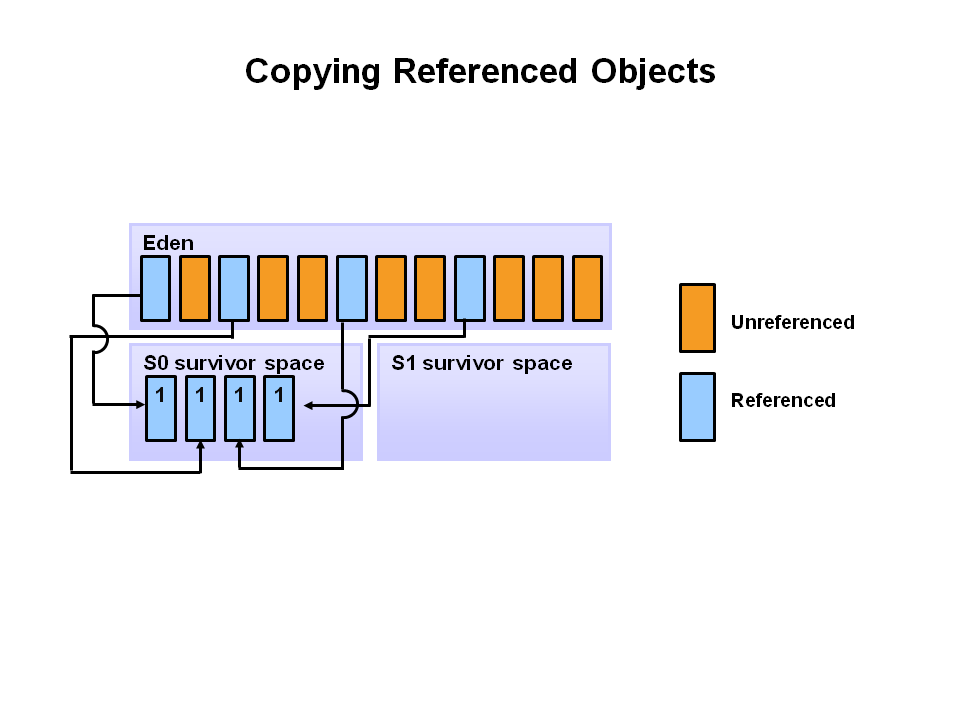
- 이후 동일한 작업이 진행되고, 이번엔 사용중인 개체가
S1영역으로 이동한다. 또한S0에 있던 개체들은 모두 나이가 증가하며,S1으로 이동한다. 살아남은 모든 개체가S1으로 이동하면S0과 Eden이 모두 삭제 된다.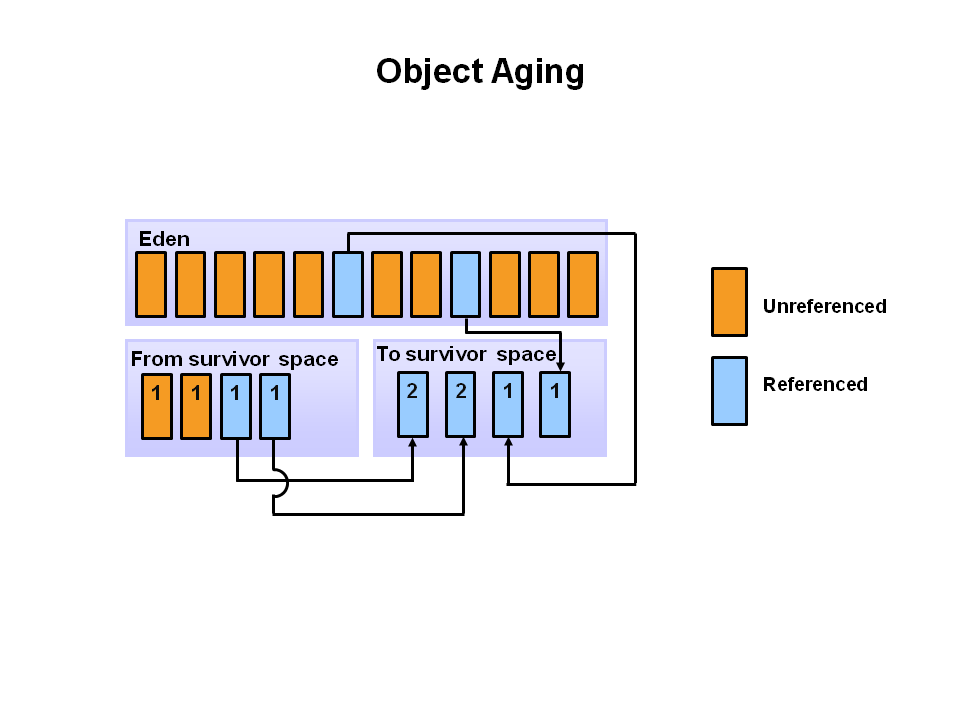
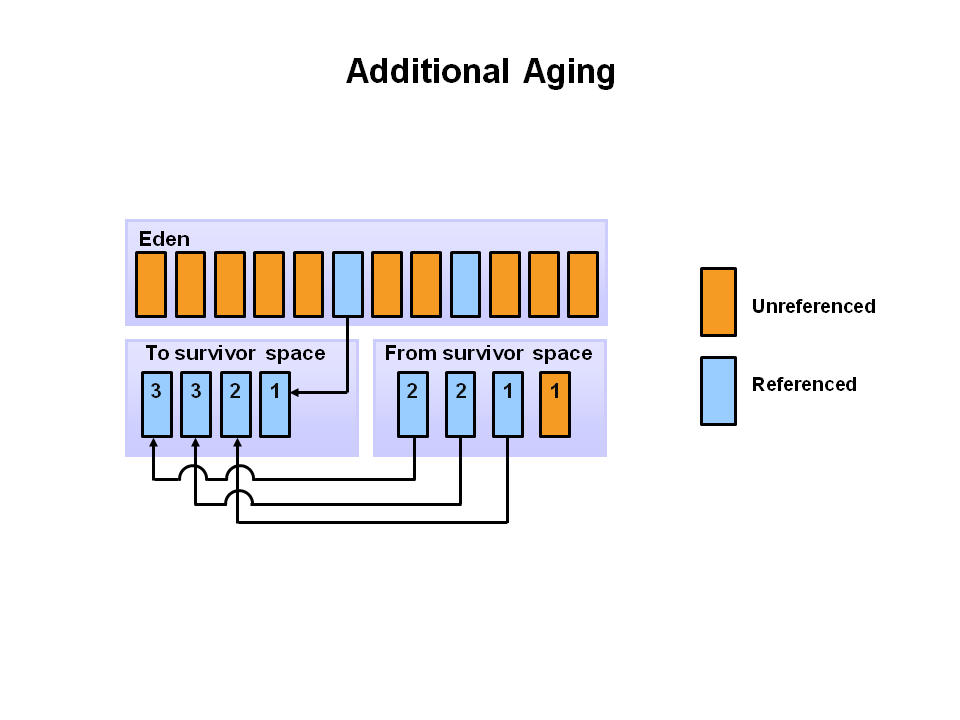
- 다음 Minor GC 동작시 이번엔 생존자 공간이 전환되어 사용중인 개체는
S0로 이동되며Eden 과 S1이 삭제된다.
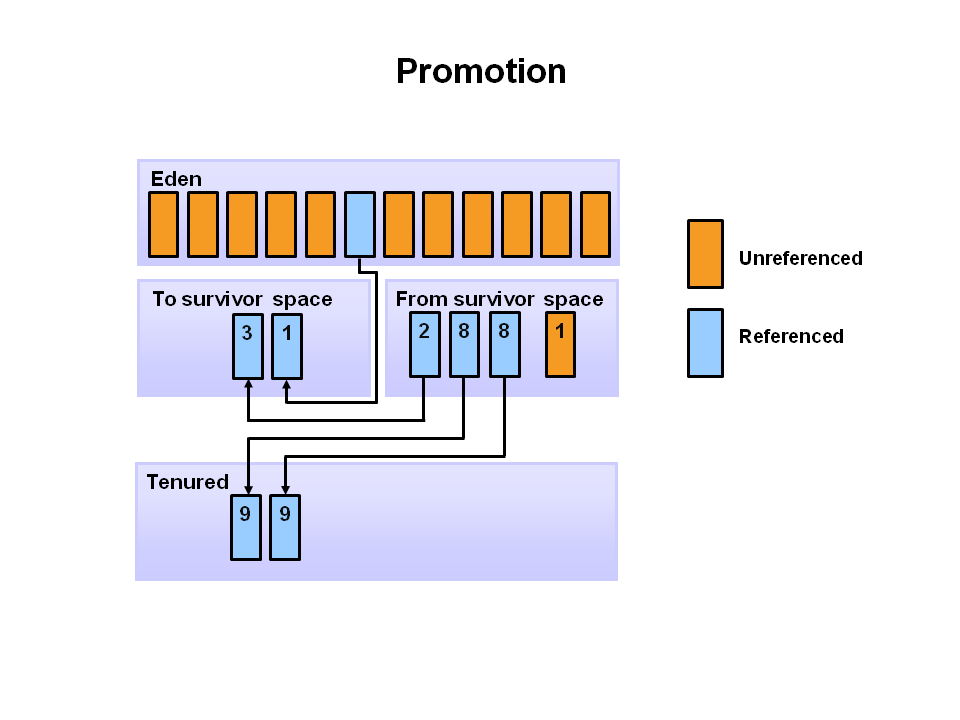
- 이후 오래된 개체가 특정 나이가 되면(임계값 - 여기선 8)
Young Generation에서Old Generation으로 이동한다.
- 최종적으로 이런 작업들이 진행되며, 결국 해당 공간을 정리하고 압축하는
Old Generation에서 주요 GC가 수행된다.
GC Alogorithm
GC는 사실 JAVA에만 있는 것은 아니며, JAVA 외의 언에서 각자의 GC를 다루고 있다. 이러한 GC에서 사용하는 기본적인 알고리즘이 있으며, 이를 한번 알아보자.
Reference Counting
참조 카운팅 알고리즘은 개체에 대한 참조가 하나 이상 있는 한 개체가 살아 있다는 생각을 기반으로 한다.개체에 대한 새 참조가 생성 될때마다 해당 개체의 참조 횟수가 증가한다.
같은 원리로 참조가 제거될 때마다 참조 횟수가 감소한다.개체의 참조 횟수가 0에 도달할 경우 해당 개체를 더 이상 사용할 수 없으며, 메모리에서 해제할 수 있는 상태임을 나타낸다.
- 장점
참조 카운팅의 주요 이점은 GC 수집 주기를 기다리지 않고 메모리에 도달할 수 없게 되는 즉시 메모리를 회수할 수 있다는 것이다. 즉 메모리의 소비를 줄이고, 응답성을 향상 시킬 수 있다.
- 단점
다만 참조가 생성되거나 소멸시에 해당 개체의 참조 횟수를 업데이트 해야한다는 점(원자성 작업, 잠금 또는 동기화 등이 포함됨)에서 실행 속도가 느려질 수 있다. 또한 객체 간에 루프를 형성하는참조(순환참조)의 수집이 힘들 다.(Memory Leak으로 이어질 수 있음)
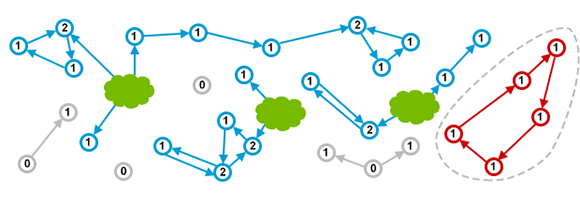
Mark-and-Sweep
모든 GC 수집 알고리즘은 2가지 기본 작업을 수행해야 한다.
첫째, 도달할 수 없는 모든 개체를 감지할 수 있어야 한다.
둘째, 힙 공간을 회수하고 다시 사용할 수 있는 공간을 만들어야 한다.이를
Mark and sweep에선 각각mark와sweep두 단계로 수행한다.- Mark
객체가 생성될 때마크비트는 0(false)로 설정된다. Mark 단계에서 도달 가능한 모든 객체에 대해 표시된 비트를 1(true)로 설정한다. 모든 객체를 노드로 간주하여 도달할 수 있는 모든 노드를 방문하고 도달 가능한 모든 노드를 방문할 때까지 계속된다.
Sweep
단어에서 알 수 있듯이 도달할 수 없는 개체를 청소한다. 즉, 도달할 수 없는 모든 개체에 대한 힙 메모리를 지운다. 표시된 값이 false로 설정된 모든 객체는 힙 메모리에서 지워지고 다른 접근 가능한 객체의 경우 표시된 비트가true로 설정된다.이후 다시 표시단계를 거치기 때문에 도달 가능한 모든 객체의 표시 값은
false로 설정된다.
- 장점
순환 참조가 있는 경우 처리가 가능한다.
알고리즘 실행 중에 발생하는 추가 오버헤드가 없다.
- 단점
프로그램에서 여러 번 실행된 후 도달 가능한 객체가 사용되지 않는 많은 작은 메모리 영역으로 분리된다.
사용 가능한 영역이 많이 존재할 수 있지만 할당을 수용할 만큼 충분히 큰 단일 영역이 없으면 할당이 계속 실패한다.
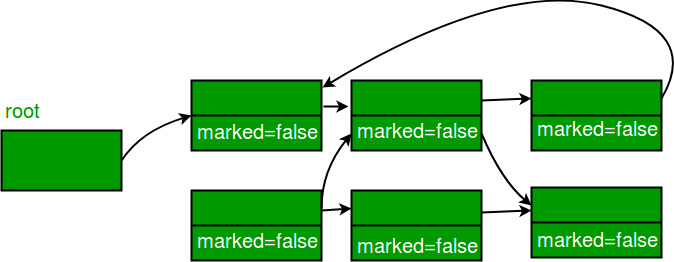
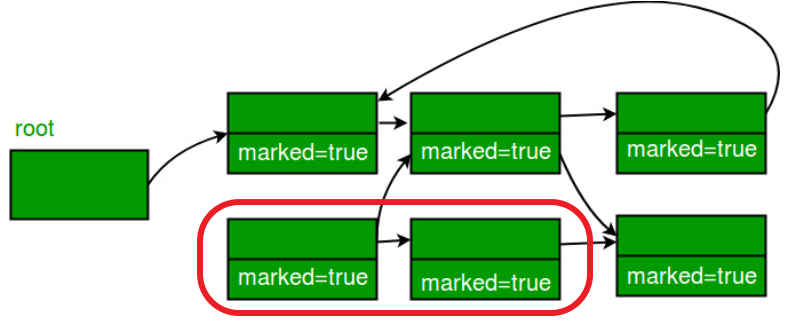
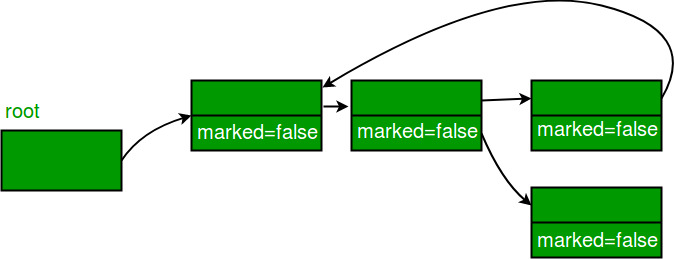

Mark-Sweep-Compact
표시된 모든 객체를 메모리 영역의 시작 부분으로 이동하여 Mark 및 Sweep의 단점을 해결한다. Sweep 대신 Compact이라는 용어를 사용 하였지만 Sweep이 사라진 것은 아니고Compact Phase안에 포함되어 있다.과정은
Mark and Sweep Algorithm과 동일하게 보이지만 Compact 과정을 거치게 된다. 아래의 그침처럼 기존의 띄엄 띄엄 남아있던 빈자리들을Compaction작업을 통해 차곡차곡 적재하여 메모리 공간의 효율을 높일 수 있다.다만,
Compaction작업 이후 모든 개체를 새 위치에 복사하고 해당 개체에 대한 모든 참조를 업데이트해야 하므로 GC 일시 중지 기간이 증가한다.
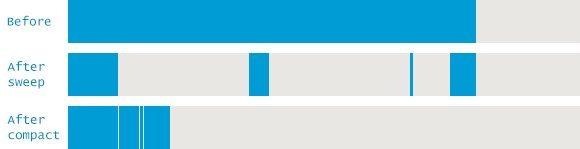
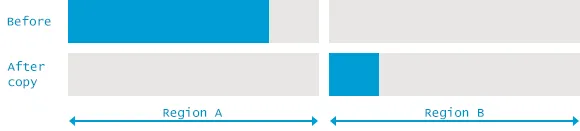
Copying Algorithm
힙을 대상 공간과 시작 공간 두 영역으로 나눈다.(논리적 구분)
모든 개체는Active공간에 할당 되며, 새 공간이 가득 차면 수집이 수행되고 공간이 교체된다. 그런다음 새 할당이 다시 새 대상 공간에서 수행된다.GC 수행후 살아남은 객체를
Inactive영역으로Copy하는 작업을 수행하며, Copy를 수행하는 동안 프로그램이Suspend상태가 되기 때문에Stop-the-Copying이라고도 부른다.Copy 작업 완료이후
Active영역엔 참조하지 않는 객체만 남게 되고,Inactive영역엔 참조되는 객체만 남게된다. 이후 참조되지 않는 객체를 제거하면,Active영역은 비어있게 되고,Active와Inactive영역이 서로 바뀌게 된다. 이를Scavenge라고 한다.
- 단점
반을 나눠서 쓰기 때문에 Heap의 절반만 사용하는 공간 활용의 비효율성.
Copy에 대한 Overhead가 존재함.
Generational Algorithm
현대 GC가 사용하고 있는 알고리즘이다. 쉽게말해Generational세대를 활용한 알고리즘이다.GC를 수행할 경우
stop-the-world즉 애플리케이션이 중지되는데, 처리해야할 참조하지 않는 객체가 많을 수 록 시간이 오래걸린다. 실제 애플리케이션의 대부분의 개체의 특성은 아래 두 가지와 같다.
- 오래된 객체에서 젊은 객체로의 참조는 거의 없다.
- 일반적으로 오랫동안 생존하지 못한다.
위 두 가지의 가설을
Weak generational hypothesis약한 세대 가설이라고 하며, 이 가설을 바탕으로 Heap 메모리에서 설명했던Young Generation과Old Generation영역이 탄생했다. 우리가 주로 사용하는 HotSpotJVM이Generational Algorithm을 바탕으로 Heap을 구성하고 있다.
GC 수집기
새로운 JAVA 버전이 나오면서 일반적으로 기본 수집기 또한 변경되는데 이번엔 각 버전에 따른 알고리즘과 처리기를 알아 보려한다.
(Java 7 부터의 Default GC를 알아본다)
JAVA 7 & 8 - Parallel GC
병렬 수집기 라고도 한다. GC의 수집 속도를 높이기 위해 여러 스레드가 사용되며,-XX:+UseParallelGC.로 사용 가능하다.
반대로 싱글 스레드로 동작하는Serial GC (-XX:+UseSerialGC)가 있다.싱글 스레드로 동작하는 Serial GC 보다 빠르게 처리가 가능하며 Parallel GC는 메모리가 충분하고 코어의 개수가 많을 경우 유리하다.
참고로 JAVA 6에선
ParallelOldGC가 update 되었고, 해당 옵션은Old Generation에 대해Mark and Compact알고리즘을 사용한다.
또한-XX:+UseParallelOldGC를 통해 기존의 Parallel까지 함께 사용하여 GC를 진행할 수 있다.
JAVA 9 ~ 11 - G1 GC(높은 처리량과 낮은 Stop-The-World 지향)
G1(Garbage-First)는 대용량 메모리가 있는 다중 프로세서 시스템을 대상으로 한다. G1은 할당을 위해 세분화된 여유 목록을 완전히 사용하지 않도록 충분히 압축하는 압축 수집기이다.이전 버전의 GC 수집기(
Paralle, Serial, CMS) 등은 모두 힙을 Young, OLD 그리고 고정 메모리 크기의 여구 세대 섹션으로 보통 구성했다. 우리가 위에서 봤던 Heap의 구조와 가깝다.G1의 경우 다른 접근방식을 사용하며, 힙을 3개의 큰 영역으로 분할하는 대신 동일한 크기의 영역 집합으로 분할한다는 점이 다르다.(논리적 분할)
G1 GC는 수행 시 먼저 Heap 영역 전체에서 Garbage의 비율이 높은 Region을 파악하여 해당 region을 우선적으로 처리한다. 이에
Garbage First GC라는 이름을 가지게 되었다.
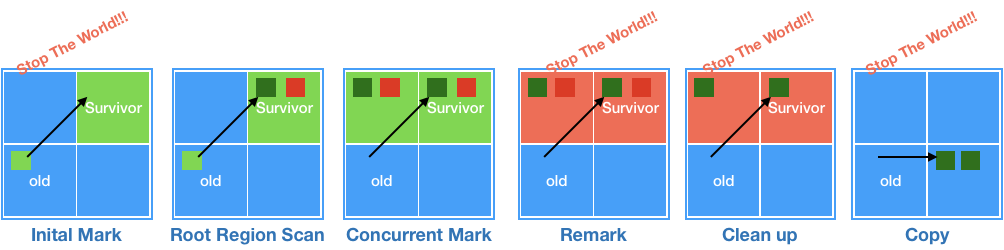
[G1 GC 단계]
- Initial Mark : Old Region에 존재하는 객체들이 참조하는 Survivor Region을 찾는다(STW 발생)
- Root Region Scan : 찾은 Survivor 객체들에 대한 스캔 작업을 실시한다.
- Concurrent Mark : 전체 Heap의 scan 작업을 실시하며, GC 대상 객체가 없으면 이후 단계를 제외
- Remark : 애플리케이션을 멈추고(STW발생) GC 대상에서 제외할 객체를 식별한다.
- Cleanup : 애플리케이션을 멈추고(STW) 참조되는 객체가 가장 적은 Region의 미사용 객체 제거
- Copy :
Cleanup에서 비워지지 않은 살아남은 객체들을 새로운 Region에 복사하여 압축 수행.

JAVA 15 ~ now - ZGC(At 64bit)
차세대 GC로 JDK 15에서 Production Ready 상태였다.
STW시간을 줄이기 위해Marking시간에만 STW를 가져가도록 하는 것이 특징이며 64bit 운영체제 에서 사용이 가능하다. 객체를 가리키는 변수의 포인터에서 64bit를 활용해 Marking을 하는 방식으며,G1GC와는 다르게 메모리를 재배치 하는 과정에서 STW없이 재배치 한다.
[ZGC의 기본 원칙]
- ZGC는 확장 가능하도록 설계되어 수백 MB에서 최대 수 TB까지 JAVA heap을 처리할 수 있다.
- 동일한 워크로드에서 전체 성능의 15% 내에서 성능을 유지하며 애플리케이션을 시도한다.
- 1MS 미만의 일정한 STW 시간
- 성능 최적화에 필요한 튜닝의 양을 줄이기기 위해 hot spot GC의 많은 튜닝옵션을 자동화한다.
[ZGC의 특징]
- 동시성
JAVA 스레드가 계속 실행되는 동안 GC가 수집됨을 의미한다.- 일정한 STW 시간
여전히 STW가 존재하지만, heap의 크기와 상관없이 일정한 STW 시간을 유지한다.- 병렬과 압축
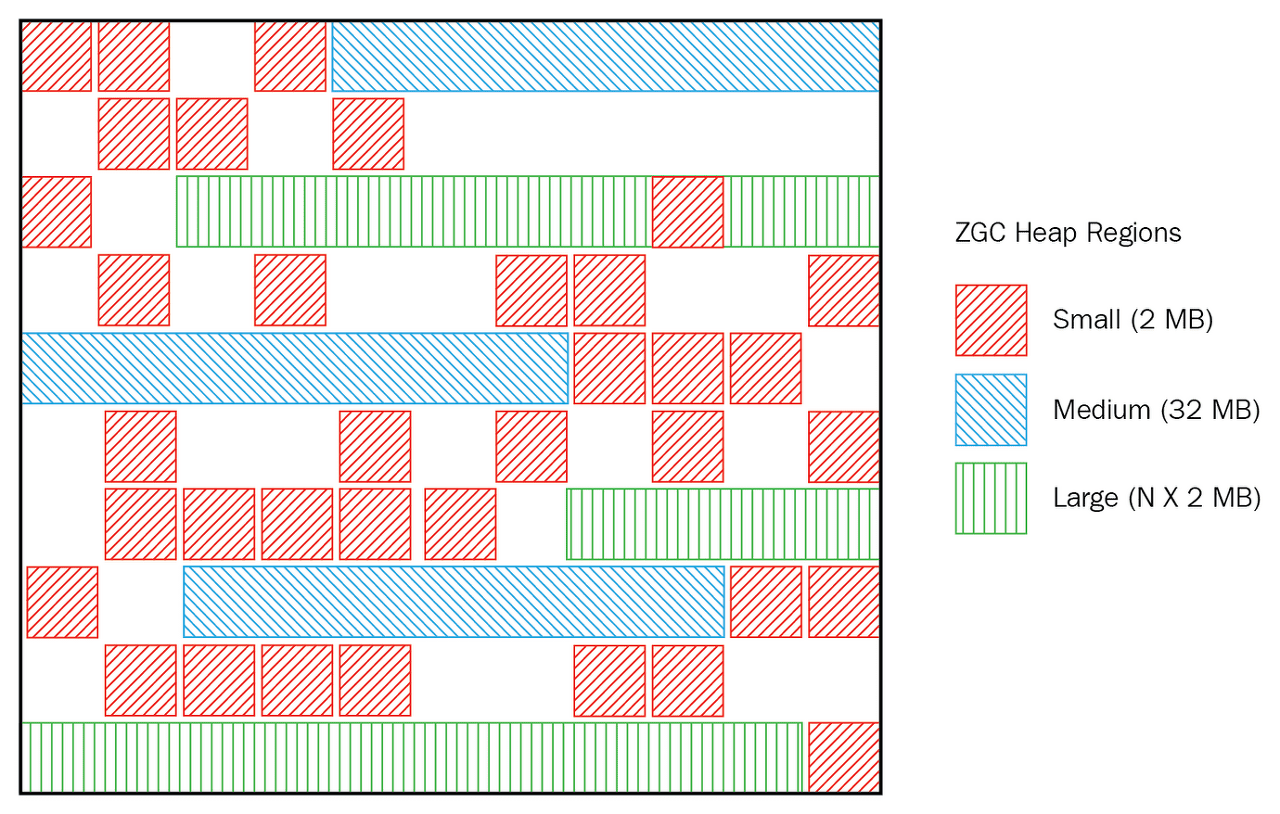
여러 부분으로 분할되고 여러 스레드에서 실행되며 압축한다.동시압축은 G1 GC와의 차별점이다.- 영역기반
heap이 작은 여러 영역으로 분할되고, ZGC가 일반적으로 garbage가 많은 하위 집합을 수집한다.- 자동조정
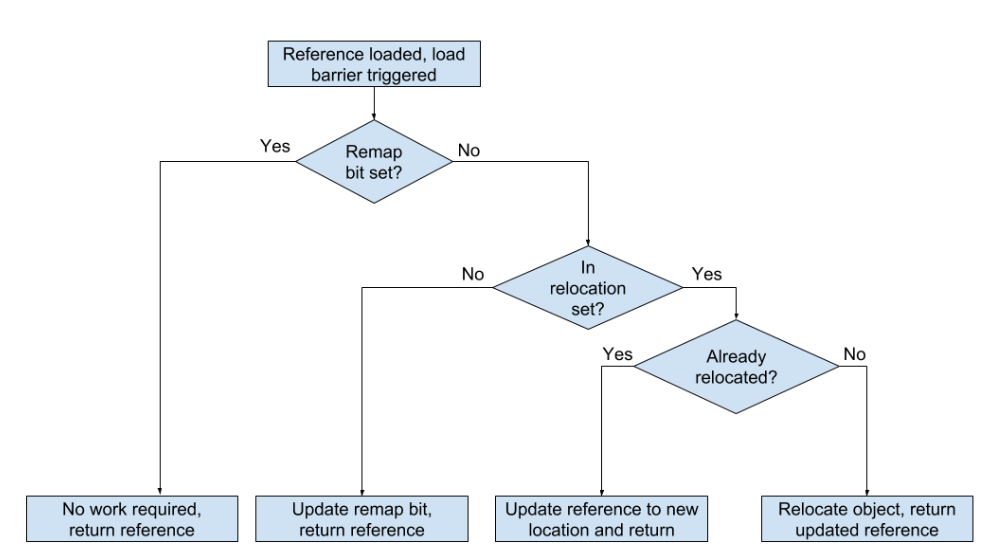
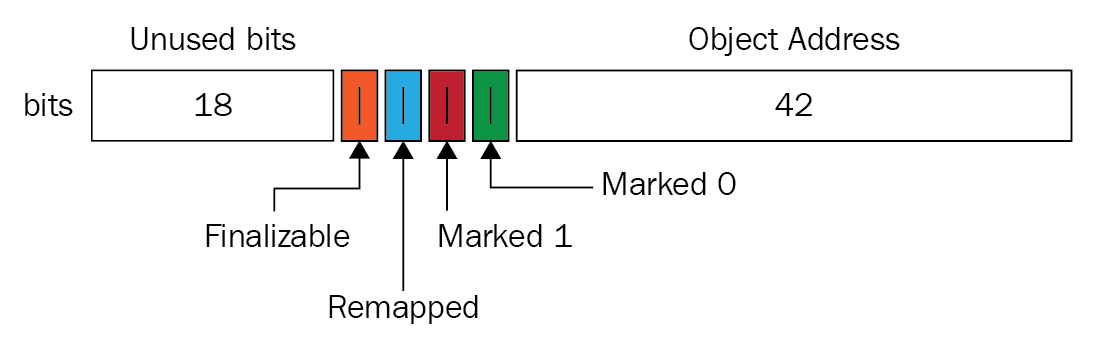
위에서 언급한대로 복잡한 설정 없이 사용이 가능하다.- Load barriers & Colored pointers
동시성을 달성하기 위해 두 가지 주요 기술로 부하 정벽과 컬러 포인터 알고리즘을 사용한다.
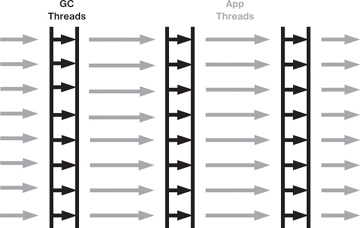
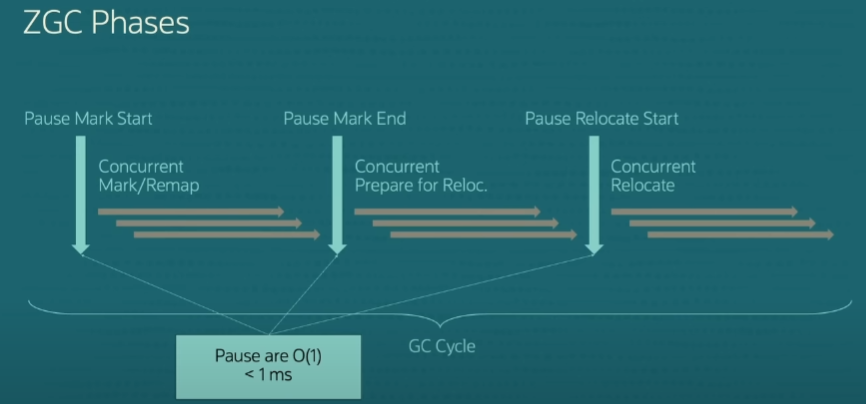
[ZGC 단계]
위 그림에서
아래쪽을 가리키는 파란색 화살표는 GC 저장지점으로 상태전환이 발생하는 동기화 지점이며, GC 일시중지의 유일한 소스이다.모든 실제
GC 작업은 가로 화살표로 표시된 동시 단계에서 발생한다고 말할 수 있으며 여기서 애플리케이션은 계속 실행되고 작업은 동시에 또는 병렬로 실행되는 여러 스레드로 나뉜다.GC 작업의 몇 가지 예는 루트를 스캔하고 힙의 전체 객체 그래프를 살펴보는 동시 마크 단계와 garbage가 많은 힙 영역을 수집하는 동시 재배치 단계가 있다.
마지막으로 각 동기화 지점이 완료되는 데 1ms 미만이 걸리기 때문에 ZGC가 1ms 미만의 일정한 일시 정지 시간을 제공할 수 있음을 알 수 있다.
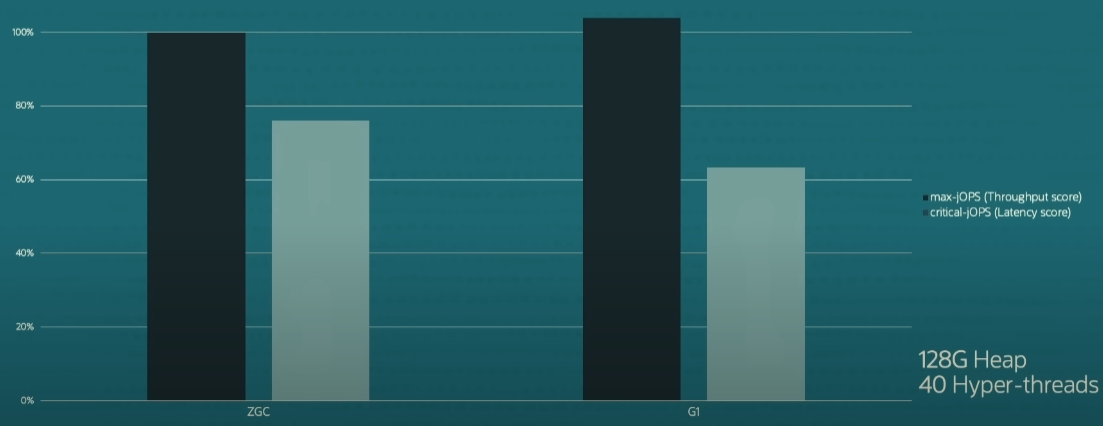
[ZGC G1 GC 비교]
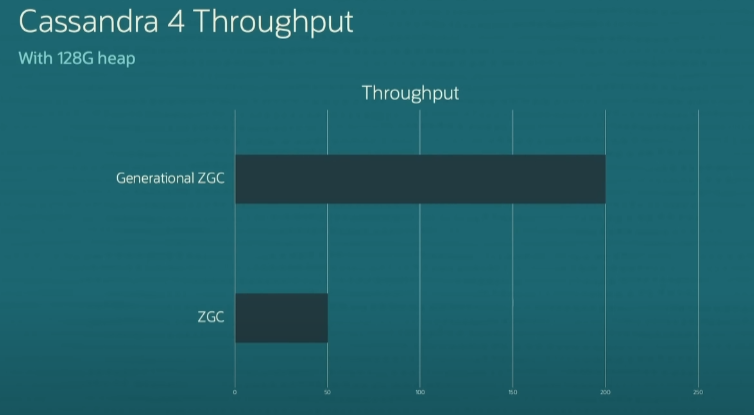
128 GB의 heap에 대한 ZGC와 G1의 비교이다.
G1의 처리량 점수는 약간 더 높지만 지연 시간 점수는 ZGC가 훨씬 더 우수한걸 볼 수 있다.(오른쪽)
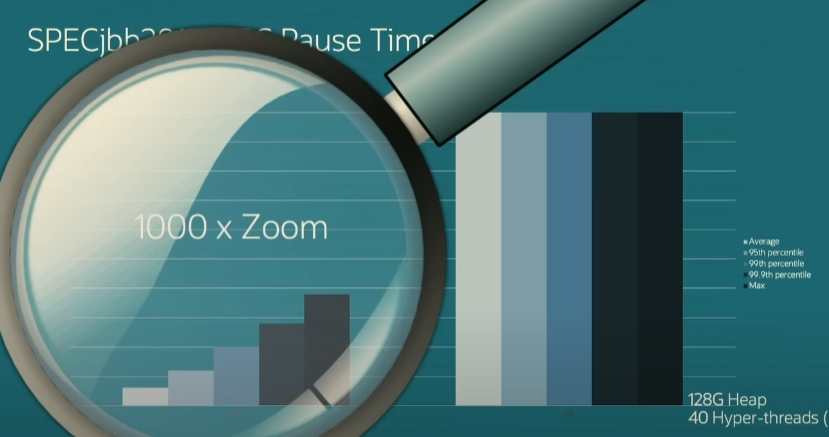
G1의 평균 일시 중지 시간은 약 150ms, 최대 일시 중지 시간은 약 450ms 이며, 왼쪽에는 ZGC의 일시 중지 시간이 전혀 없는 것으로 보인다. ZGC 일시 중지 시간을 보려면 실제로 천 배로 확대해야 한다.
[ZGC 에서의 Generational]
Weak Generational Hypothesis(약한세대 가설)를 이용하여Young Generation에 수집을 집중하면 효율성이 높아져 GC를 처리하는 데 CPU 사이클이 소비되지 않는 한 낮은 힙 오버헤드로 더 높은 할당률을 처리할 수 있다.
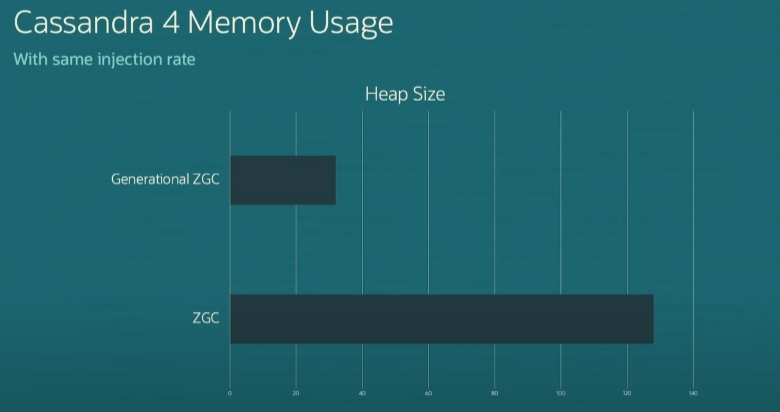
위 예시는 Cassandra 4의 메모리 사용 그래프다 여기서 볼 수 있는 것은 heap의 크기를 원래 ZGC 알고리즘이 실행하는 데 필요한 것의 약 25%로 줄이면서도 여전히 잘 실행될 수 있다는 것이다.
위 예시는 처리량 관련 그래프이며,
세대별 ZGC를 사용하면 할당 중단이 발생하기 전에 ZGC보다 4배 더 높은 요청 가중치를 처리할 수 있다.[요약]
요약하면세대별 ZGC는 4배의 처리량을 달성할 수 있고, 현재와 비교하여 25퍼센트의 메모리를 사용할 수 있으며, 1ms 미만의 GC 일시 중지 시간을 유지하면서 작업을 수행할 수 있다.
GC Tuning
GC에 대해 어느정도 알아봤으니 간단하게 오라클에서 제공하는 가이드 기준으로 GC를 튜닝해보는 작업을 하려한다. 먼저 아래는 오라클 의 GC(G1 GC기준) 튜닝 가이드 중 일부를 가져왔다.
주의 해야할 점은 무조건 GC Tuning만이 답이 아니다. 실제 VM을 더 나은 성능으로 조정하는 것보다 애플리케이션 단계의 수준 최적화가 더 효과적일 수 있으며, GC Tuning은 최후의 보루로 생각하자.
[일반권장 사항]
최종적으로 다른 일시 중지 시간 목표를 부여하며, 원하는 경우-Xmx를 사용해 최대 Java heap 크기를 결정한다.G1의 목표는 최대 처리량이나 최저 지연 시간이 아니라 높은 처리량에서 상대적으로 균일한 일시 중지를 제공하는 것이다. 높은 처리량을 선호하는 경우
-XX:MaxGCPauseMillis를 사용해 일시 중지 시간 목표를 완화하거나 더 큰 힙을 제공할 수 있다.
Young Generation의 크기는 G1이 일시정지 시간을 충족할 수 있는 주요 수단이기 때문에-Xmn, -XX:NewRatio과 같은 옵션으로 크기를 특정 값으로 제한하지 않는 것이 좋다. 해당 크기를 단일 값으로 설정하면 일시 정지 시간 제어가 재정의되고 실질적으로 비활성화 된다.
[G1 성능 향상 - Full GC에 대한 모니터링과 처리]
기본적으로 추가 옵션 없이도 G1은 우수한 성능을 제공하지만, 최적의 결과를 제공하지 못하는 경우를 위해-Xlog:gc*=debug옵션을 통해 출력을 세분화하여 원인을 파악하고 세부적인 설정을 하는 것이 좋다.
Full GC가 발생하는 이유는 애플리케이션이 충분히 빨리 회수할 수 없는 개체가 너무 많이 할당 되었기 때문이다. 많은 개체를 할당시에Full GC가 발생할 확률이 더 높아질 수 있으며, 예상보다 훨씬 더 많은 메로리를 차지할 수 있다.목표는
동시 마킹이 제시간에 완료하는 것이어야 하며, 이는Old Generation할당 비율을 낮추거나 동시 마킹을 완료하는 데 더 많은 시간을 주어 달성이 가능하다.
gc+heap=info을 통해 heap에서 거대한 객체가 차지하는 영역의 수를 확인이 가능하다. 추가로Humongous regions: X->Y는 거대한 영역의 양을 나타낸다. 이 수치가Old Generation영역에 비해 높다면-XX:G1HeapRegionSize를 사용해 영역 크기를 늘려 튜닝이 가능하다.
- Java heap 크기를 늘려보자. 이렇게 하면 일반적으로 마킹을 완료하는데 걸리는 시간이 늘어난다.
- 명시적으로
-XX:ConcGCThreads를 설정하여 동시 마킹 스레드 수를 늘린다.
[GC 성능향성 - Young Generation 내의 Collection이 너무 오래 걸리는 경우]
일반적으로Young Generation의 Collection은 일반적으로 해당 영역의 크기, 구체적으로는 복사해야 하는 collection Set 내의 살아있는 객체 수에 비례하여 시간이 걸린다.Collection Set를 비우는 단계에서 오래걸리는 경우
-XX:G1NewSizePercent를 통해Young Generation의 최소 크기가 줄어들어 잠재적으로 일시 중지 시간이 단출될 수 있다.
Do Test
테스트를 위해 Spring Boot 프로젝트와 Visaul Vm, Visual GC를 IntelliJ와 연동하여 진행했다.
자세한 내용은 설명되어 있는 글이 많으니 쉽게 참조 가능하다.
그럼 먼저 GC 를 하기전 간단한 코드로 OOM을 발생시켜 보자.
@GetMapping("/test")
public String test() {
List<byte[]> list = new ArrayList<>();
int size = 1024 * 1024; // 1MB
Long iterations = 80L;
for (int i = 0; i < iterations; i++) {
byte[] array = new byte[size];
size += 1024 * 1024;
list.add(array);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
list.clear();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "test";
}간단한 스프링 프로젝트 이며, 호출시 정해진 횟수만 큼 for문을 돌며 결국 OOM을 발생시키는 코드이다. 해당 코드는 -Xms2g -Xmx4g를 통해heap size를 최대 4GB 까지 잡아줄 경우 성공하지만 3GB로 설정하는 경우 OOM이 발생한다.(이미 해당 루프에서 3GB이상의 데이터가 쌓인다.)
우선 GC 관련 로그확인을 위해 -Xlog:gc*=debug 설정을 했으며, OOM 발생 직전의 로그는 아래와 같다.
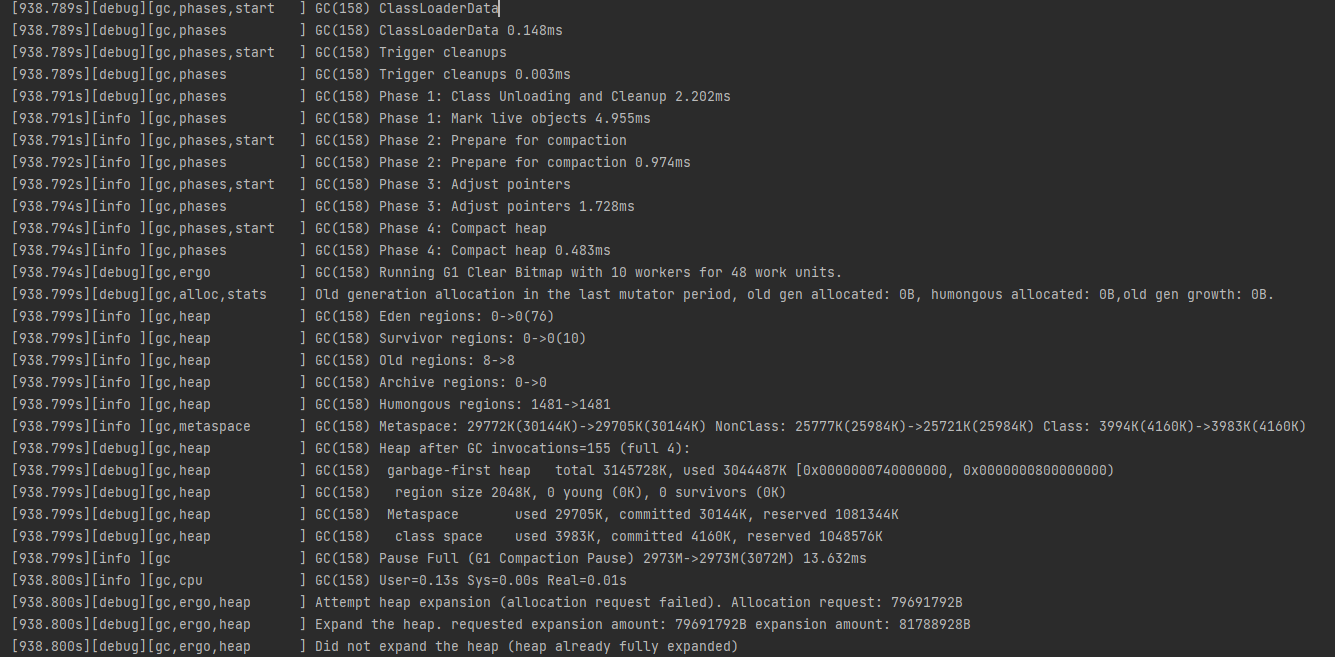
아래는 로그에 대한 간단한 설명이다.
GC(158) Phase: GC의 각 Phase 실행 을보여주며 소요된 시간을 보여준다.GC(158) Eden regions: 0->0(76): Eden 영역의 상태이며 0에서 변하지않음을 보여준다.(최대 76)GC(158) Survivor regions: 0->0(10): Survivor 영역의 크기이다.(최대 10)GC(158) Old regions: 8->8: Old 영역을 나타내며, 새로운 영역이 할당 / 해제 되지 않았다.GC(158) Humongous regions: 1481->1481: 큰 객체를 처리하는 영역에 대한 로그다.GC(158) Metaspace: 29772K(30144K)->29705K(30144K): Metaspace의 상태이다.GC(158) Pause Full: Full GC가 발생했으며(STW 발생) 메모리 사용량이 3GB에 가깝다.GC(158) User=0.13s Sys=0.00s Real=0.01s: Full GC의 소요시간을 나타낸다.Attempt heap expansion: 해당된 크기만큼 heap 확장을 시도했으나 공간이없어 실패했다.Expand the heap: heap 확장을 수행했으며, 최종확장량은 81788928B이다.Did not expand the heap: 이미 최대 크기로 확장된 heap으로 확장되지 않는다.
결국 OOM 메세지가 출력되며, 정상적인 응답을 하지 못하게 되었다. 위로그를 VisaulVM으로 보자.
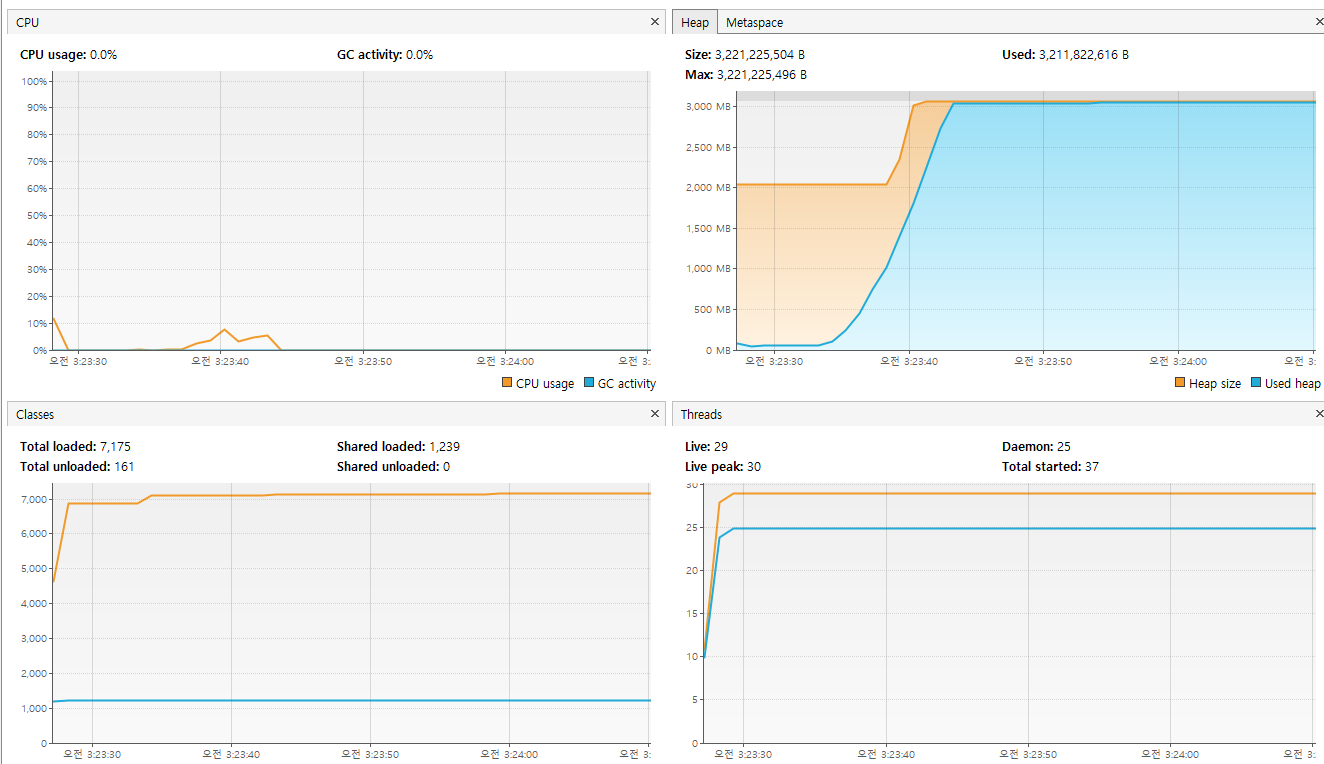
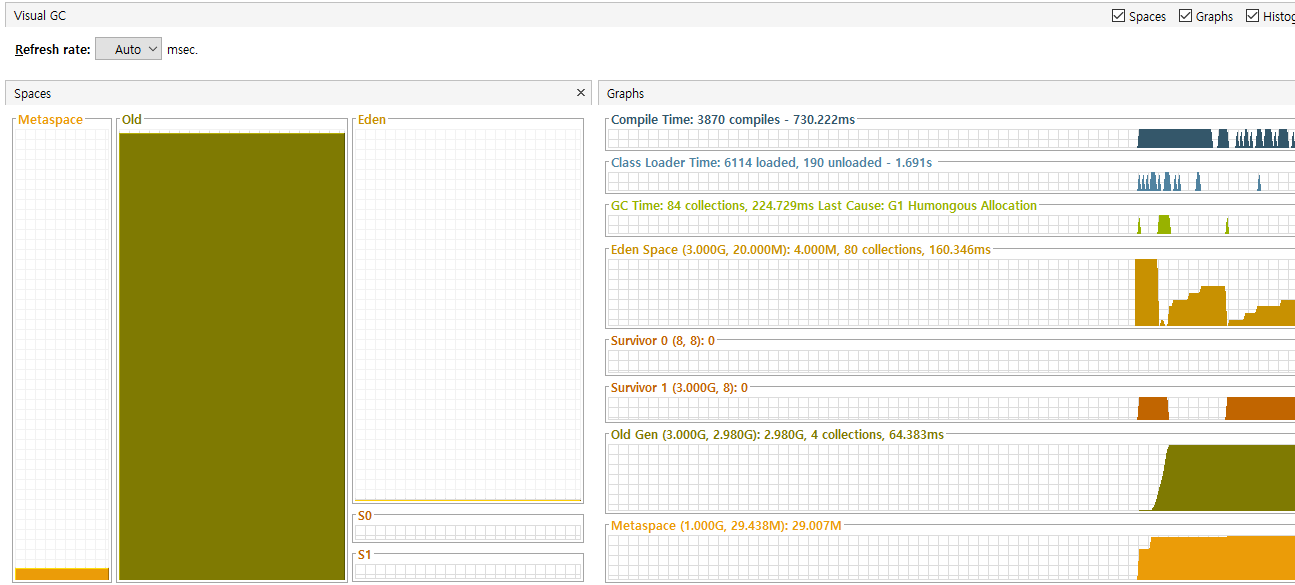
당연스럽게도 heap 영역을 조금 더 늘려준다면 성공할 것이다. 위의 내용과 같이 4GB로 heap size를 늘리고 시작할 경우 정상적으로 처리가 되는것을 확인할 수 있다.
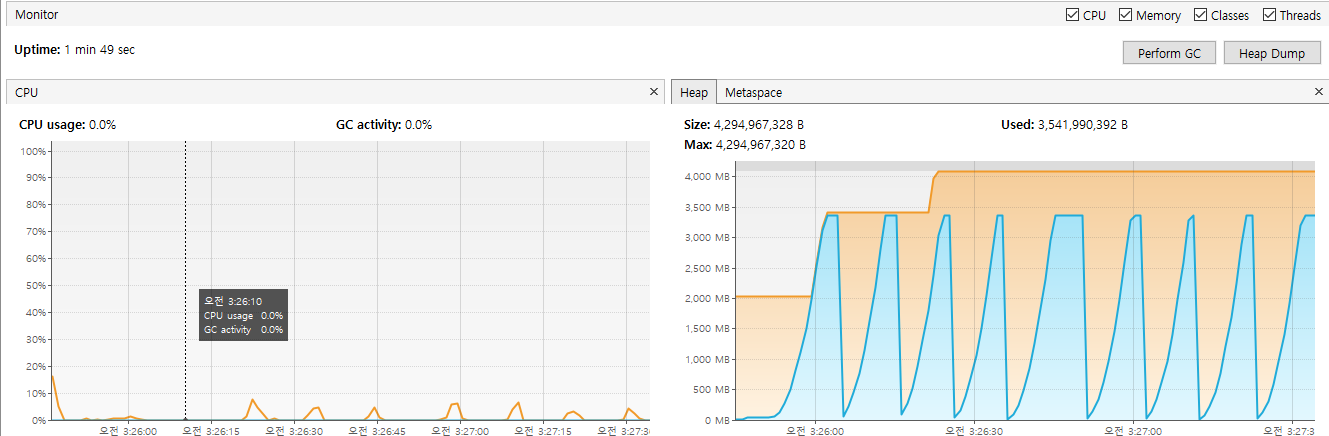
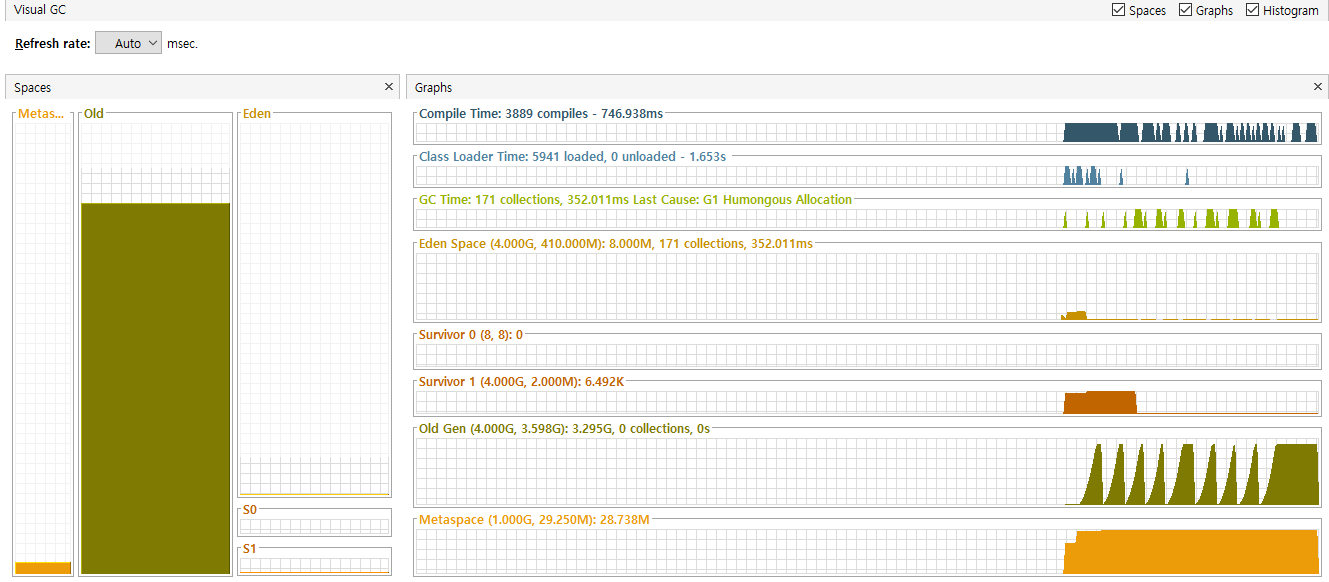
위 테스트의 경우 이미 해당 로직이 완료될 당시 3GB이상의 메모리가 사용되기 때문에 heap의 영역을 늘려주는 것으로 해결이 가능했다. 그렇다면 다른 경우의 테스트는 어떨까?
public String test() {
List<byte[]> list = new ArrayList<>();
int size = 1024 * 1024; // 1MB
Long iterations = 76L;
for (int i = 0; i < iterations; i++) {
byte[] array = new byte[size];
size += 1024 * 1024;
list.add(array);
if (i == 38) {
callB();
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return "test";
}
public void callB() {
int size = 1024 * 1024; // 1MB
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < 600; i++) {
byte[] array = new byte[size];
list.add(array);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}테스트 방법을 좀 바꿔보았다 기존 80번 반복의 경우 이미 3GB를 초과하는 양이기 때문에 76번으로 아슬아슬하게 3GB의 heap 영역을 통과할 수 있게 맞추고 중간에 callB()라는 메소드를 실행 하도록 했다.
예상했던 동작방식은 38번째 부터 callB가 실행되고 해당 메소드가 종료되면 GC로 인해 callB에서 차지하고 있던 Garbage는 모두 사라지고 정상적으로 애플리케이션이 종료 될거라 생각했다.
그러나 실제 테스트 결과 OOM이 발생함을 확인할 수 있었고 로그를 확인해 보니 지속적으로 많은 GC가 일어 났음에도 Full GC 까지 발생하는 것을 확인할 수 있었다.
개인적인 생각에 우선 기본적으로 많은 GC가 발생할 필요가 없던 상황이라고 생각했다. 38번째(절반) 까지의 루프 이후 callB가 실행되니, callB가 종료 된이후 GC가 돌도록 대략 65% ~ 70% 영역의 heap 영역이 차고 난 이후 이후부터 GC가 동작하면 되지 않을까 라는 생각을 했다.(callB에서 600MB + a의 메모리가 쌓인다.)
잦은 GC는 GC의 오버헤드를 발생시키기도 하며 더 이상 사용하지 않는 작은 조각들로 메모리가 조각나는 메모리 프래그먼테이션 상태로 GC의 성능이 저하될수 있어 이를 해결하려 했다.
관련된 설정 옵션은 -XX:InitiatingHeapOccupancyPercent 였으며, 기본 설정은 45 였기 때문에 이를 70까지 올리고 테스트를 진행해 봤다.
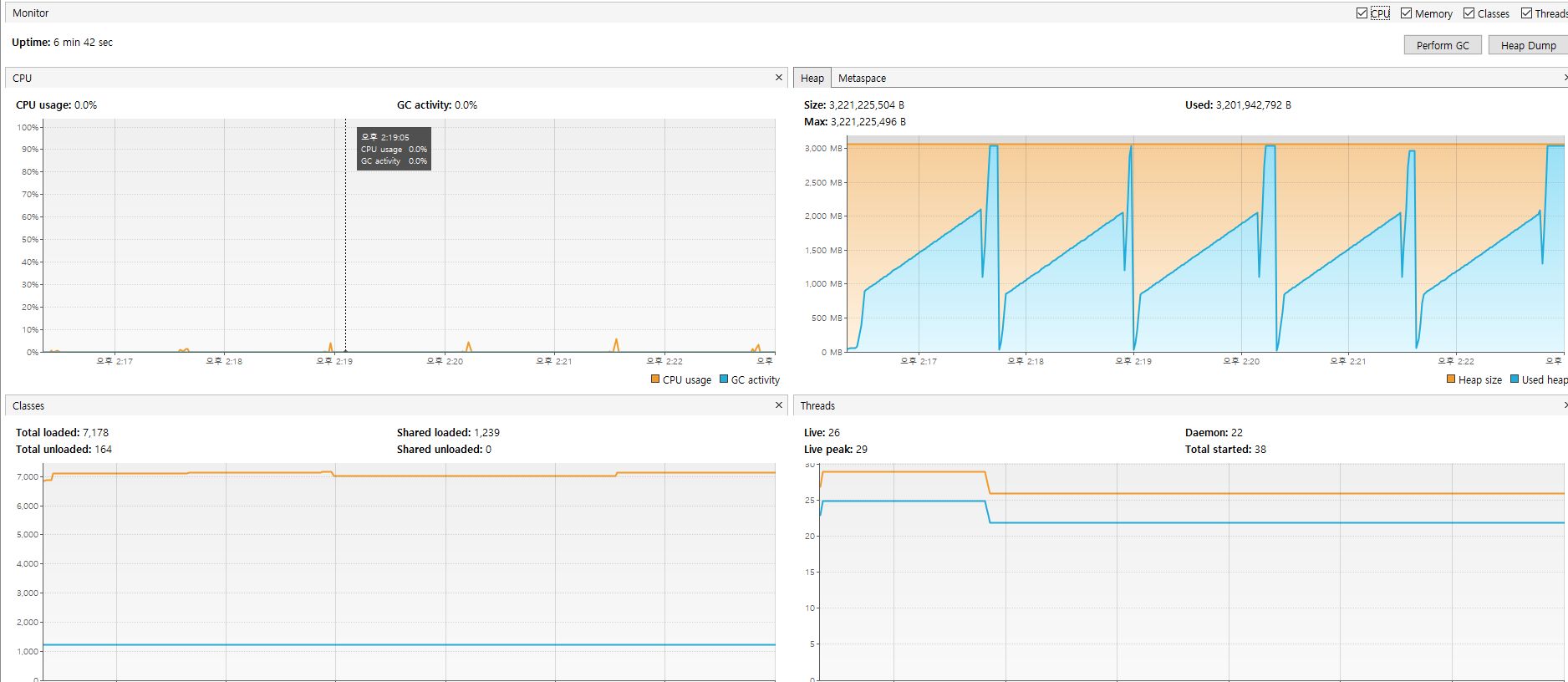
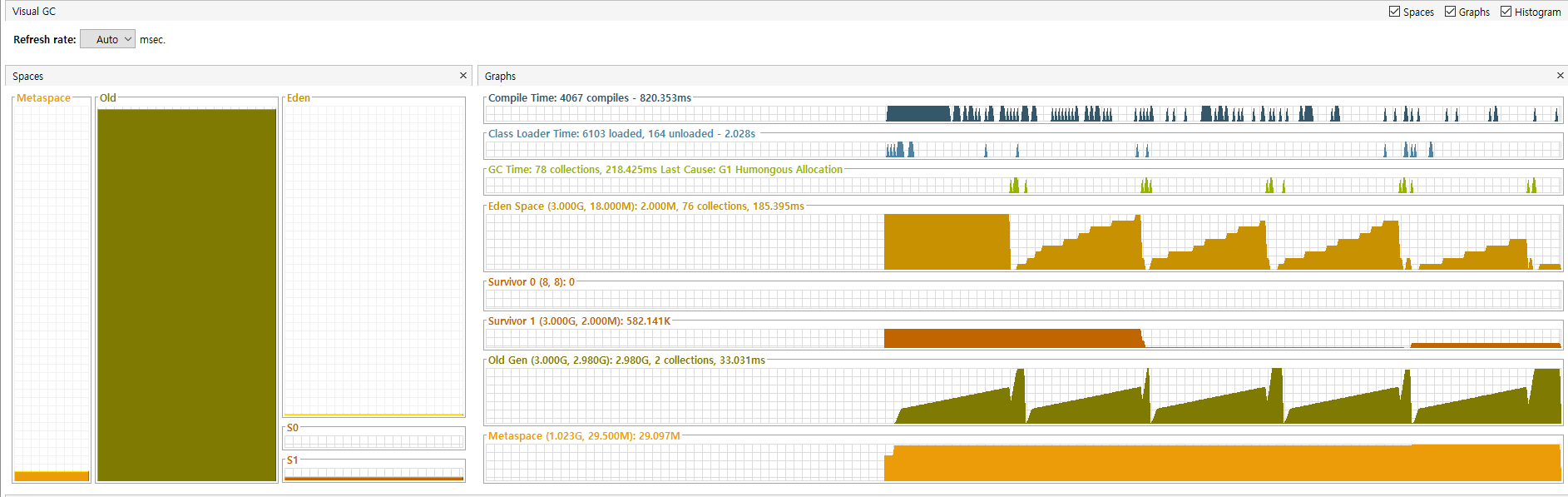
실제 오래걸리긴 했지만 정상적으로 애플리케이션이 정상적인 응답을 주는 것을 확인 할 수 있었으며, Full GC가 발생하는 로그는 없었다.
정리
사실 정상적인 애플리케이션에서 Full GC 가많이 발생하여 응답이 느리거나 하는 경우의 테스트를 해보고 싶었다. 그러나 해당 상황을 구축하기가 까다로운 상황이라 나름의 극단적인 과정에서 테스트를 해봤다. 가장 중요한 내용은 위에서 언급했겠지만 GC 튜닝은 최후의 보루로 먼저 애플리케이션의 코드등을 최적화 하는것이 우선 되어야 한다. 위의 테스트 코드도 코드의 최적화를 통해 OOM을 충분히 막을 수 있는 코드 이다. 기회가 된다면 실제 운영 상황에서의 GC 튜닝도 해보고 싶다는 생각이 드는 좋은 기회였다.
참조
https://notionalmachines.github.io/nms/StackAndHeapDiagram-1.html
https://www.baeldung.com/jvm-garbage-collectors
https://plumbr.io/handbook/gc-tuning
https://www.javatpoint.com/stack-vs-heap-java?
https://www.youtube.com/watch?v=OnodHoNYE1Y
https://www.oracle.com/webfolder/technetwork/tutorials/obe/java/gc01/index.html
https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
https://docs.oracle.com/en/java/javase/11/gctuning/garbage-first-garbage-collector-tuning.html#GUID-4914A8D4-DE41-4250-B68E-816B58D4E278

훌륭한 글 감사드립니다.