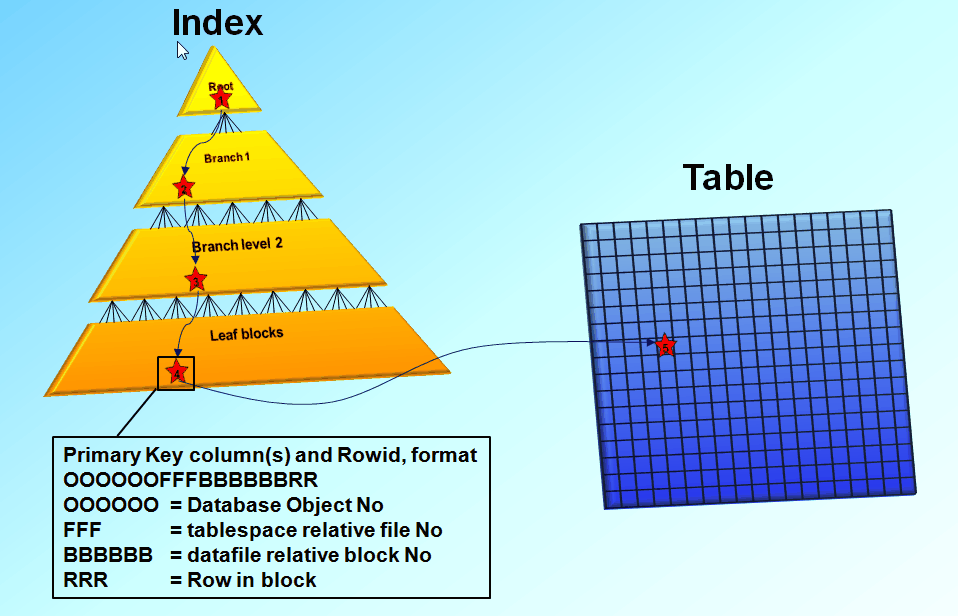
항상 데이터베이스의 인덱스에 대해 이야기하면 '너무 많은 인덱스는 항상 좋은 것이 아니다' 라는 이야기가 되곤 합니다.
보통 너무 많은 인덱스는 쿼리 최적화 도구(Optimizer)가 처리해야하는 데이터 페이지의 양이 늘어나는 현상과 추가적인 overhead가 발생한다는 단점이 있습니다. 또한 인덱스가 너무 많은 경우 저장 공간에 대한 낭비부분도 고려 해야합니다.
위와 같은 원인들은 기본적으로 알려진 문제점들이고 이로인해 적절한 인덱스에 대한 선택이 필요하다는 점은 대부분 알고 있을 것입니다.
이번 글에선 실제 인덱스가 많아지면 어떠한 문제가 생길 수 있으며, 그러한 문제들이 어떠한 이유에서 발생 되는지 알아보려 합니다.
인덱스
인덱스는 정렬되지 않은 테이블에 대해 검색 시 쿼리 효율성을 극대화할 수 있는 순서로 정렬하는 방법으로 테이블에 인덱스가 설정되지 않은 경우, 쿼리에서 행의 순서가 어떤 식으로든 최적화된 것으로 식별되지 않을 가능성이 높기때문에, 선형적인 검색을 수행합니다.
이는 조건과 일치하는 행을 찾기 위해 모든 행을 검색해야 하는 것을 의미하며, 데이터가 많은 상황이라면 이 작업은 오랜 시간이 걸릴 수 있습니다.
즉 인덱스를 적용하는 주요 목적은 전체 테이블 스캔 검색의 필요성을 줄임으로써 데이터 검색 프로세스의 가속화에 있습니다.
인덱스는 테이블의 실제 데이터에 대한 포인터나 참조를 포함하는 별도의 데이터 구조를 생성하여 데이터를 보다 효율적으로 찾을 수 있도록 합니다.
인덱스에 대한 설명을 하려다 보면 보통 도서 색인에 비유를 하는 경우가 많다보니 데이터에 대한 포인터를 흔히 도서 색인에 기록된 페이지 번호에 비유하게 되고, 그래서 인지 인덱스의 ROWID를 포인터라고 생각하는 경우가 많습니다.
그러나 인덱스의 ROWID는 논리적 주소로, 디스크 상에서 테이블 레코드를 찾아가기 위한 위치 정보를 말한 다는 것이 중요합니다.
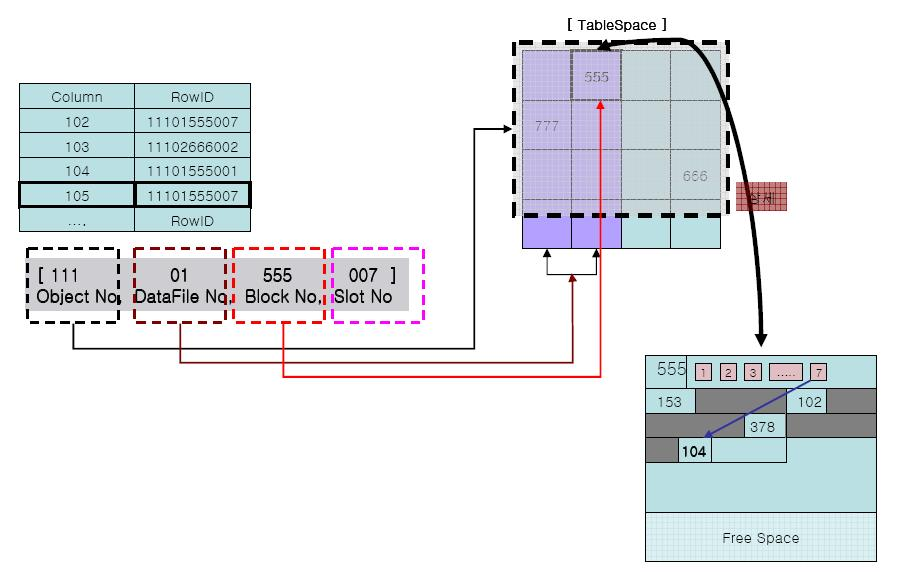
왜 인덱스를 사용하는가
데이터베이스에 데이터를 저장할 때는 데이터를 바이트 단위로 변환하여 디스크에 기록합니다.
또한 작업을 최적화 하기위해 블록단위로 기록하며, 이는 개별 데이터에 대한 바이트가 아닌 전체 데이터 블록을 쓰거나 업데이트 합니다.
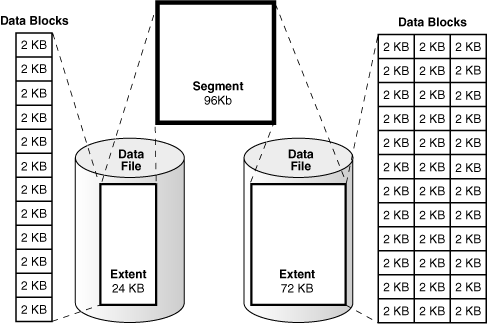
이러한 블록 단위의 데이터 바이트에서 특정 레코드를 가져오려면 해당 레코드가 존재하는 모든 블록을 가져와야 하며, 이는 곧 작업 속도로 이어집니다.
문제는 대량의 데이터 블록이 있는 디스크에서 특정 레코드를 검색하여 처리할 때 성능의 병목 현상으로 이어질 수 있다는 것입니다.
인덱스를 사용한다면, 효율적인 검색 작업을 용이하게 수행할 수 있도록 별도의 데이터 구조를 생성하여 찾으려 하는 데이터를 더 빠르게 검색할 수 있습니다.
사실 인덱스는 데이터베이스에 저장된 데이터가 많을수록 그 효과를 알 수 있습니다. 만일 10,000,000 건의 데이터 가 존재하는 테이블을 조회할 경우 인덱스 유/무에 대한 차이는 어떨까요?
[인덱스가 없는 경우]
CREATE TABLE `authors` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `first_name` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci', `last_name` VARCHAR(50) NOT NULL COLLATE 'utf8_unicode_ci', `email` VARCHAR(100) NOT NULL COLLATE 'utf8_unicode_ci', `birthdate` DATE NOT NULL, `added` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) COLLATE='utf8_unicode_ci' ENGINE=INNODB;위와 같이 간단한 테이블의 구조이며,
PRIMARY KEY인 id를 제외하곤 인덱스가 존제하지 않습니다.
이때 아래와 같은 조건으로 데이터를 조회한다면 1천만건의 데이터를 모두 스캔(Full table scan)하여 그 결과를 출력할 것이며, 이때 걸리는 시간을 확인해 보겠습니다.SELECT birthdate FROM authors WHERE birthdate BETWEEN '2012-03-01' AND '2012-04-30';
확인 결과 약
18만 건의 데이터를 조회하였으며, 이때 약13초정도의 시간일 걸림을 알 수 있습니다.

[인덱스가 있는 경우]
이번엔 아래와 같이 조회 조건인birthdate에 인덱스를 설정한 후 조회결과를 체크해 보겠습니다.CREATE INDEX idx_birthdate ON authors(birthdate); SELECT birthdate FROM authors WHERE birthdate BETWEEN '2012-03-01' AND '2012-04-30';
동일한 쿼리문에 동일한 결과값에 대해 약
0.7초의 시간이 걸리며 이는 인덱스가 없을 경우의 쿼리와 비교하여 약15배의 성능차이를 보여줍니다. 이때 실행계획을 통해 확인해 보면 아래와 같습니다.explain SELECT birthdate FROM authors_index1 WHERE birthdate BETWEEN '2012-03-01' AND '2012-04-30';
실행계획을 살펴보면
idx_birthdate인덱스를 사용할 수 있으며, range를 통해 인덱스 특정 범위의 행에 대해 접근(Index Range Scans)이 가능함을 알 수 있습니다.


다만, 인덱스가 설정되어 있다고 해서 위의 테스트와 같이 모두 인덱스를 사용하는 것은 아닙니다. MySql의 InnoDB의 경우 옵티마이저(Optimizer)의 판단에 따라 테이블의 전체 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔이 더 빠르다고 판단하는 경우 혹은 인덱스 레인지 스캔을 활용할 수 있는 쿼리여도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은경우 풀 테이블 스캔을 선택합니다.
인덱스의 자료구조
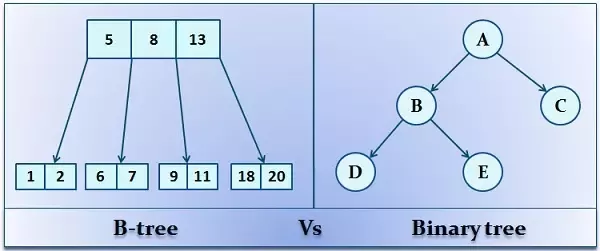
RDBMS 기준으로 우리가 알고 있는 Oracle, PostgreSQL, MySQL, Maria등 대부분은 Tree 구조의 인덱스를 사용합니다. 정확히 말하자면 Tree 구조중 B+ Tree를 사용하며, 이런 자료 구조의 사용으로 검색 작업에 효율적인 성능을 가져올 수 있습니다. B+ tree는 B-tree(Balanced-tree)와 유사한 구조이지만 몇가지 특성이 있습니다.
B-tree
Tree 구조의 경우 평균적인 시간 복잡도로 O(logN)을 가지지만, 이는 평균적인 시간 복잡도이며, 아래와 같이 트리 노드의 요소가 한쪽 방향으로만 쏠린다면 최악의 경우에는 O(N) 까지의 시간복잡도를 가지게 됩니다.
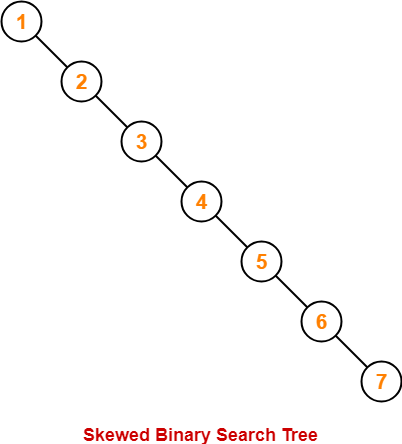
이러한 상황을 해결하기 위해 노드가 한 방향으로 쏠리지 않도록, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재정렬되어 왼쪽 과 오른쪽의 자식 양쪽 수의 균형(Balance)을 유지할 수 있는 B-Tree가 사용됩니다. 이를 통해 O(logN)의 시간복잡도를 보장할 수 있습니다.
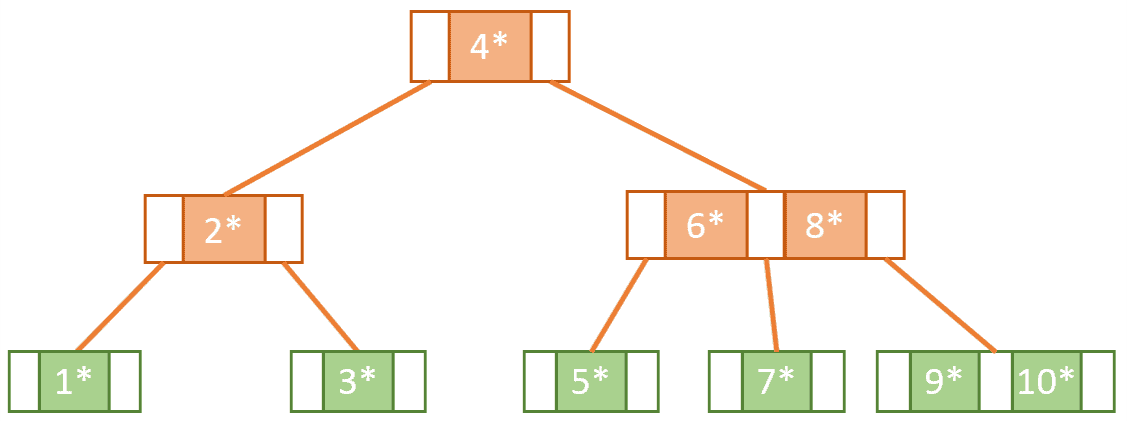
다만 노드의 삽입/삭제 등의 작업으로 인해 트리가 재정렬되는 작업이 발생하며, 이로 인해 큰 차이는 아니지만 일반적인 트리보다는 성능적인 부분에서 떨어질 수 있습니다.
B+ tree
실제 데이터베이스 인덱스에 많이 사용되는 B+ tree의 경우 B tree와 비슷한 구조입니다. 다만 모든 리프 노드(마지막 노드)는 이중으로 연결된 목록(Linked list)으로 서로를 연결합니다.
또한 중간 노드들의 데이터에 key와 value를 담을 수 있는 B tree와 다르게 중간 노드에는 key만 두고 value는 담지 않습니다. 오직 리프 노드에만 key와 data를 저장하는 구조 입니다.
이러한 방식의 장점으로 리프 노드를 제외하면 value를 담지 않기 때문에 메모리 용량에 대한 확보가 가능하며, 트리의 높이 또한 낮아져 탐색 시 리프 노드의 데이터만 살피기 때문에 B-tree에 비해 탐색에 유리합니다.(B+ tree의 경우 리프 노드가 서로 연결되어 있어 범위 검색 작업에 효율적입니다.)
또한 리프 노드에서만 데이터의 추가와 삭제가 이루어 지기때문에 더 효율적입니다.
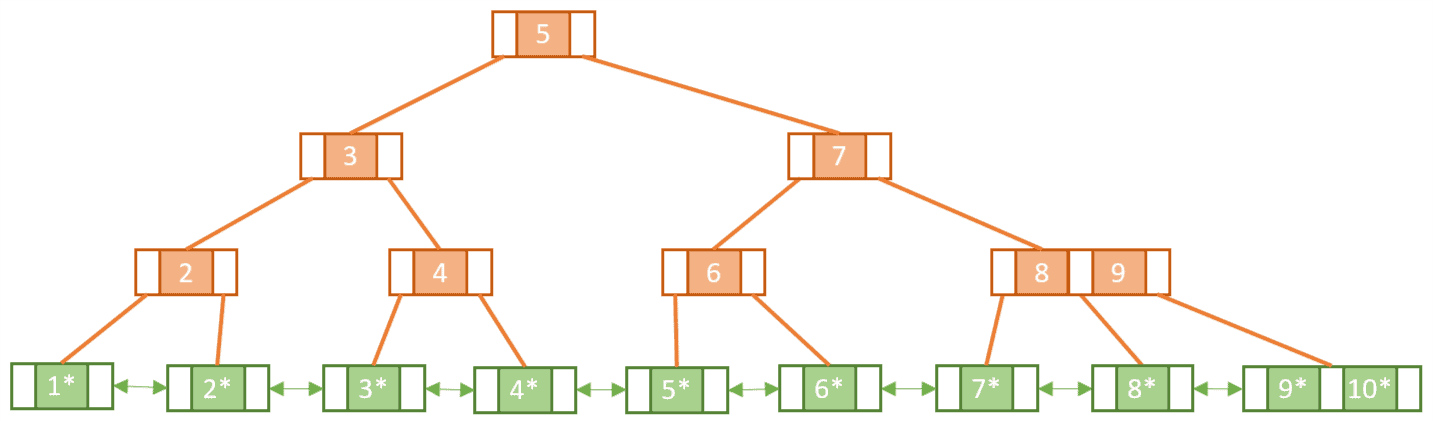
왜 B+ tree인가
위에서 설명한 내용과 같이 인덱스의 구조인 B tree 계열의 경우 시간복잡도가 O(logN)임을 알 수 있습니다. 그러나 트리구조의 최악의 상황(한쪽 방향으로 쏠린경우)을 보완하기 위해 스스로 균형을 맞추는 바이너리 트리(self-balancing BST)가 등장하며 대표적으로 AVL tree 와 Red-Black tree가 있습니다.
두 트리 모두 조회 삽입 삭제 에 대해 O(logN)의 시간복잡도를 가집니다. 그렇다면 왜 데이터베이스는 AVL tree 혹은 Red-Black tree 가아닌 B tree 계열의 자료구조를 사용할까요?
데이터베이스는 기본적으로 Secondary storage 즉 SSD 혹은 HDD와 같이 영구적 보관이 가능한 디스크에 저장이 됩니다.
Secondary storage는 컴퓨터 시스템에서 데이터를 처리하는 속도가 가장 느리며, 데이터를 저장하는 용량이 가장 크다는 특징이 있습니다. 또한 위에서 설명한 내용과 같이 Block 단위로 데이터를 읽고 씁니다.
데이터베이스의 관점에서 본다면 서비스 상에서 생성된 중요한 데이터를 보관해야 하며, 이때 영구적 보관이 가능해야 하고, 계속 늘어나는 데이터에 대한 용량도 필요합니다. 이런 특징에 따라서 Secondary storage를 사용하게 됩니다.
이때 핵심이 되는 데이터는 Main memory(RAM)에 올려 관리를 하며, 나머지 데이터는 Secondary storage에 저장하는 것이죠, 이후 RAM에 있는 데이터 만으로 부족할 경우 HDD에서 데이터를 읽어와야 하며, 이때 Block 단위의 데이터를 읽어 RAM에 올린뒤 데이터 처리를 통해 요청에 대한 응답을 합니다.
이러한 식으로 데이터베이스 시스템이 동작을 할 때 가장 중요한 것은 HDD 즉 Secondary storage에 최대한 적게 접근하는 것이 성능 면에서 좋습니다. 또한 block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있습니다.
이때 B tree 계열의 경우 차수가 존재하며, block단위에 데이터를 담아두고, 노드들을 한 block안에 최대한 모아서 저장할 수 있기 때문에 데이터를 찾을 떄 탐색 범위를 빠르게 좁힐 수 있으며, 저장 공간의 활용도가 높아집니다. 이는 다른 Binary tree에 비해Secondary storage에 적게 접근할 수 있는 구조입니다.
인덱스가 많을 경우에 따른 Trade Off
기업의 면접에서 가장 많이 나오는 질문중 하나는 인덱스가 데이터베이스의 검색 성능을 향상시켜 준다면, 많은 인덱스를 설정하는 것이 좋은지 물어보는 경우가 있습니다.
이는 지금까지 설명한 Index의 특성과 그 구조의 특성을 통해 설명이 가능한 부분입니다. 우선 테스트를 통해 인덱스가 많은경우 발생하는 문제가 무엇일지 알아보겠습니다.
위의 테스트와 동일하게 70,000,000 건의 동일한 데이터를 보유한 2개의 테이블을 기준으로 테스트 예정이며, 한 곳은 설정된 PK를 제외한 인덱스가 존재하지 않으며, 다른 곳은 인덱스가 10개 이상 입니다.
[인덱스가 없는 경우]
create table ex_rate_history ( id bigint auto_increment primary key, change_rate decimal(15, 2) null, change_rate_diff decimal(15, 2) null, dest varchar(10) null, updated datetime null, manual bit default b'0' null, rate decimal(16, 7) null, rate_diff decimal(16, 7) null, rate_time datetime null, source varchar(10) null, updated_by_id bigint null, rate_hash varchar(255) null, constraint fk_ex_rate_history_updated_by_id foreign key (updated_by_id) references admin (id) ) charset = utf8;위와 같이
ex_rate_history테이블에 존재하는 인덱스는 현재 PK를 제외하고 없는 상태 입니다. 이런 상황에서 해당 테이블에 레코드를 추가하면 얼마의 시간이 걸릴까요?-- 임의의 데이터 삽입 INSERT INTO ex_rate_history (change_rate, change_rate_diff, dest, updated, manual, rate, rate_diff, rate_time, source, updated_by_id, rate_hash) VALUES (12.34, 1.23, 'USD', '2024-03-26 12:34:56', b'0', 1.2345678, 0.1234567, '2024-03-26 12:34:56', 'KRW', 1, 'abc123');
약
37ms로 매우 빠른 시간안에 INSERT를 하는것을 볼 수 있습니다.

[인덱스가 많은 경우]
반면에 가능한 인덱스를 최대한 등록한 경우CREATE INDEX idx_dest_updated ON ex_rate_history (dest, updated); CREATE INDEX idx_dest_manual ON ex_rate_history (dest, manual); CREATE INDEX idx_dest_rate_time ON ex_rate_history (dest, rate_time); CREATE INDEX idx_dest_source ON ex_rate_history (dest, source); CREATE INDEX idx_dest_rate_hash ON ex_rate_history (dest, rate_hash); CREATE INDEX idx_dest_updated_by_id ON ex_rate_history (dest, updated_by_id); . . . CREATE INDEX idx_updated_manual ON ex_rate_history (updated, manual); CREATE INDEX idx_updated_rate_time ON ex_rate_history (updated, rate_time);
만일 위와 같이 많은 인덱스가 존재하는 테이블에 인덱스가 없을 때와 동일한 쿼리를 입력하면 얼마나 걸릴까요?
-- 임의의 데이터 삽입 INSERT INTO ex_rate_history (change_rate, change_rate_diff, dest, updated, manual, rate, rate_diff, rate_time, source, updated_by_id, rate_hash) VALUES (12.34, 1.23, 'USD', '2024-03-26 12:34:56', b'0', 1.2345678, 0.1234567, '2024-03-26 12:34:56', 'KRW', 1, 'abc123');
약
279ms초로 느린편은 아니지만, 별도의 인덱스를 설정하지 않았을 때보다 약 8배 가까운 시간이 더 걸리는 것을 볼 수 있습니다. 만일 더 많은 데이터가 존재할 수록 더 많은 시간이 걸릴 것입니다.
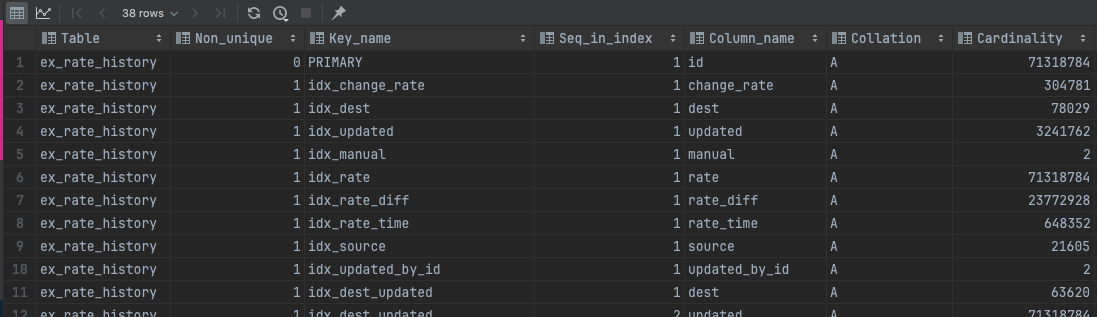

위와 같은 결과가 나오는 이유는 무엇일까요? 먼저 단일 컬럼 혹은 멀티컬럼에 대해 인덱스를 생성한 경우 인덱스 하나에 대한 B+ tree가 생기게 됩니다.
이런 상황에서 만일 해당 테이블에 로우가 하나 추가되면 어떠한 상황이 생긴다면, 해당 테이블에 설정되어 있는 각 인덱스에 해당 데이터 로우가 추가되며, 이때, 각 인덱스의 기준에 맞춰 정렬작업이 필요합니다.
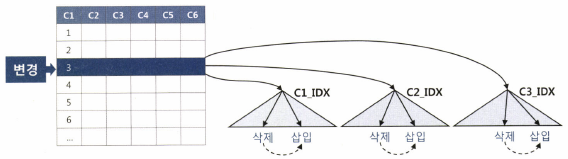
이는 위 테스트와 같이 여러개의 인덱스가 존재할 경우 존재하는 만큼의 B+ tree구조에 데이터가 추가되며, 이때 각 트리는 정렬을 위해 트리 구조의 재배치 작업이 발생합니다. 또한 인덱스가 너무 많을 경우 데이터베이스 엔진이 각 인덱스의 무결성을 유지해야 하므로 쓰기 작업시 속도가 저하될 수 있습니다. 이는 위에서 설명한 내용과 같이 성능적인 부분에서 영향을 주게 됩니다.
이는 곧 DML에 대한 성능저하(TPS 저하)와 데이터베이스 사이즈의 증가(인덱스가 차지하는 공간으로 인한 디스크 공간 낭비)등으로 이루어 질 수 있습니다. 더군다나 필요하지 않는 인덱스라면 성능 저하, 및 디스크 공간에 대한 낭비가 심해질 수 있습니다.
따라서 많이들 알고있듯이 인덱스 설계시 무분별한 인덱스 설계는 오히려 데이터베이스 시스템의 성능 저하 문제로 이어질 수 있기 때문에 적절한 기준에 따른 인덱스 설계가 필요 합니다.
정리
인덱스를 이루고 있는 자료구조의 특성을 통해 왜 인덱스를 설정하는 것이 더 효율적인지, 반면 그러한 장점만 믿고 인덱스를 무조건 적으로 많이 생성하는 것이 데이터베이스 시스템에 어떠한 영향을 미치는지 이야기 하고 싶었습니다.
이 글을 통해 인덱스 설정시 무분별한 설정이 시스템에 어떠한 영향을 주며, 각자의 시스템에 맞는 적절한 인덱스 설계 방식이 무엇인지 고민해 볼 수 있었으면 좋겠습니다.
참고
https://www.quora.com/What-are-the-disadvantages-of-having-too-many-indexes-on-a-single-table-How-can-you-avoid-having-too-many-indexes-on-a-single-table
https://www.youtube.com/watch?v=liPSnc6Wzfk
https://www.baeldung.com/cs/b-trees-vs-btrees
