HotSpot JVM
JVM?
Java에서 프로그램을 실행한다는 것은 컴파일 과정을 통하여 생성된 Class 파일을 JVM으로 로딩하고 ByteCode를 해석(interpret)하는 과정을 거쳐 메모리 등의 리소스를 할당하고 관리하며 정보를 처리하는 일련의 작업들을 포괄한다. 이때, JVM은 Thread 관리 및 GC와 같은 메모리 정리 작업도 수행하게 된다.
- Java Compiler : Java 소스파일을 JVM이 해석할 수 있는 Java Byte Code로 변경한다
- Java Byte Code : Java Compiler에 의해 수행된 결과물 (.class 파일)
- Class Loader : JVM 내로 .class파일들을 로드하고, 로딩된 클래스들을 Runtime Data Area에 배치한다
- Runtime Data Area : JVM이라는 프로세스가 프로그램을 수행하기 위해 OS에서 할당받은 메모리 공간
- Execution Engine : Loading된 클래스의 Bytecode를 해석(Interpret)한다
JVM에서 Class Loader를 통해 Class 파일을 로딩시키고, 로딩된 Class 파일을 Execution Engine을 통해 해석하게 된다. 해석된 프로그램은 Runtime Data Area에 배치되어 실질적인 수행이 이루어지게 된다.
Execution Engine
Execution Engine은 Class Loader를 통해 JVM내에 Runtime Data Area에 배치된 바이트코드를 실행한다. 자바 바이트 코드를 명령어 단위로 읽어서 실행한다.
그런데 자바 바이트 코드는 기계가 바로 수행할 수 있는 기계어보다는 비교적 인간이 보기 편한 형태로 기술된 것이다. 그래서 Execution Engine은 이와 같은 바이트 코드를 실제로 JVM 내부에서 기계가 실행할 수 있는 형태로 변경하며, 그 방식은 크게 두가지가 있다.
- Interpreter : 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행한다. 하나씩 '읽고' '실행'하는 두 단계로 진행되는데, 하나하나의 해석은 빠르지만 실행은 느리다.
- JIT(Just-In-Time) Compiler : 인터프리터의 단점을 보완하기 위해 도입되었다. 인터프리터 방식으로 실행하다가 적절한 시점에 바이트 코드 전체를 컴파일하여 네이티브 코드로 변환시킨다. 이후에는 해당 메서드를 더이상 인터프리팅 하지 않고 캐시에 있는 네이티브 코드를 실행한다. 한번 컴파일된 코드는 빠르게 수행된다.
이때 JVM의 Runtime Data Area를 살펴보면 다음과 같다.
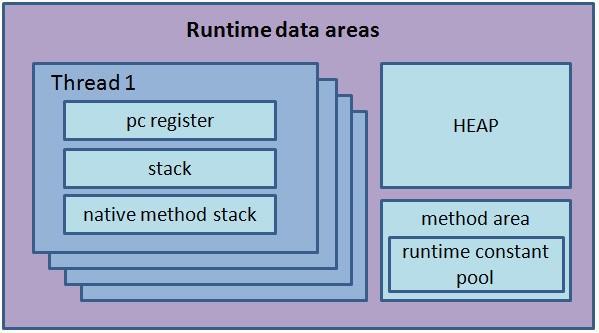
- Method Area : 클래스, 변수, 메소드, Static 변수, 상수정보 등이 저장되는 영역 (모든 Thread가 공유)
- Heap Area : new 명령어로 생성된 인스턴스와 객체가 저장되는 영역 (모든 Thread가 공유, GC 이슈가 일어나는 영역)
- Stack Area : 메소드 내에서 사용되는 값들이 저장되는 구역. 메소드가 호출되고 완료될 때 LIFO로 생성/제거 (Thread에 하나씩)
- PC Register : 현재 수행중인 JVM 명령의 주소값 저장
- Native Method Stack : 다른 언어의 메소드 호출을 위해 할당되는 구역. 언어에 맞게 Stack이 형성된다.
Java Heap
Java의 문제는 대부분 메모리 이슈에 집중되어 왔다. 이는 자동으로 메모리를 해제해주는 Garbage Collection과 연관이 깊다. 이러한 이유들로 Java의 메모리 구조는 Heap 구조라고 오해를 사는 경우도 있다. 하지만 Thread에서 Stack을 이용하고, Method Area를 통해 여러 정보들이 저장되기도 한다.
Heap은 단지 Instance(Object)와 Array 객체 두가지 종류만 저장되는 공간이고, 모든 Thread에서 공유되는 영역이다. 이때, 모든 Thread에서 공유되기 때문에 동기화 문제 또한 수반된다.
JVM은 Java Heap에 메모리를 할당하는 Instruction (Bytecode로는 new, new array 등)만 존재하고, 해제를 위한 Java Code나 ByteCode는 존재하지 않는다. 메모리 해제는 오직 GC를 통해서만 수행된다. JVM 스펙은 이러한 원칙을 정하였고, JVM 벤더들은 이를 따라 각자의 구현방식으로 Heap의 구성과 GC를 구현한다.
Method Area
JVM이 읽어들인 각각의 클래스와 인터페이스에 대한 Runtime Constant Pool, 필드와 메서드 정보, Static 변수, 메서드의 바이트 코드 등을 보관한다. 이 영역에 있는 클래스 정보로 Heap 영역에 객체를 생성한다.
메서드 영역또한 JVM 벤더마다 다양한 형태로 구현될 수 있다. JVM(Hotspot JVM)에서는 흔히 Permanent Area, Permanent Generation(PermGen)이라고 불린다. 메서드 영역에 대한 가비지 컬렉션은 JVM 벤더의 선택사항이다.
Runtime Constant Pool
클래스 파일 포맷에서 constant pool 테이블에 해당하는 영역이다. 메서드 영역에 포함되는 영역이긴 하지만, JVM 동작에서 핵심적인 역할을 수행하는 곳이다. 각 클래스와 인터페이스의 상수뿐만 아니라 메서드와 필드에 대한 모든 레퍼런스까지 담고있는 테이블이다.
즉, 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아서 참조한다.
HotSpot JVM이란?
Hotspot JVM은 미국의 Longview Technologies LLC라는 회사에서 1999년에 처음 발표한 JVM이다. 이후 SUN에 인수되었으며, 1.2버전부터 SUN의 기본적인 JVM이 되었다. 현재 Hotspot JVM은 가장 일반적인 JVM 중 하나이다.
Hotspot은 말 그대로 Hot한 Spot을 찾아서 해당 부분에서는 JIT 컴파일러를 사용하는 방법이다. 내부적으로 프로파일링을 통해 핫스팟을 찾아내고, 해당 부분에 대한 네이티브 코드를 생성한다. 이때 네이티브 코드를 생성하는 방법에서 Client와 Server라는 두가지 방법이 존재한다.
HotSpot JVM - Client
클라이언트 모드에서 동작하는 컴파일러는 주로 프로그램의 시작 시간을 최소화하는데에 집중한다. 크게 세 단계로 이루어져있다.
- 바이트 코드를 해석해서 최적화를 쉽게하기 위해 HIR이라는 정적 바이트코드 표현을 만든다
- HIR로부터 플랫폼에 종속적인 중간표현식(LIR)을 만든다
- LIR을 사용하여 기계어를 생성한다.
클라이언트 모드 JIT의 특징은 바이트코드로부터 최대한 많은 정보를 뽑아내어 실제 동작하는 코드블럭에 대한 최적화에 집중하는 것이다. 전체적인 최적화에는 관심없다.
HotSpot JVM - Server
서버의 JIT은 부분적인 코드 실행보다는 전체적인 성능 최적화에 관점을 둔다.
- 일반적인 컴파일러 최적화 기술들을 이용해 일단 코드들을 최적화 한다
죽은 코드 삭제(Dead Code Elimination), loop 변수의 끌어올리기(Loop invariants hoisting), 공통 부분식 제거(Common Subexpression Elimination), 상수 지연(Constant propagation), 전역 코드 이동(Global Code motion) 등 - 자바에 최적화된 최적화를 진행한다.
Null Check 삭제, 배열의 Range Check 삭제, 예외처리 경로 최적화. 대단위 RICS 레지스터들을 최대한 활용하기 위한, Graph연산을 통한 register할당
참고
https://blog.naver.com/2feelus/220738480797
https://sehun-kim.github.io/sehun/JVM/
