
널 가능성
널 가능성은
NullPointerException오류를 피할 수 있게 돕기 위한 코틀린 타입 시스템의 특성이다.
코틀린을 비롯한 최신 언어에서는 null과 관련한 문제를 실행 시점에서 컴파일 시점으로 옮겼다. 널이 될 수 있는지 여부를 타입 시스템에 추가함으로써 컴파일러가 여러 가지 오류를 컴파일 시 미리 감지해서 실행 시점에 발생할 수 있는 예외의 가능성을 줄일 수 있다.
1. 널이 될 수 있는 타입
코틀린과 자바의 가장 큰 차이는 코틀린 타입 시스템이 널이 될 수 있는 타입을 명시적으로 지원한다는 점이다.
널이 될 수 있는 타입은 프로그램 안의 프로퍼티나 변수에 null을 허용하게 만드는 방법이다. 어떤 변수가 널이 될 수 있다면 그 변수에 대해 그 변수를 수신 객체로 메서드를 호출하면 NPE이 발생할 수 있으므로 안전하지 않다. 코틀린은 그런 메서드 호출을 금지함으로써 많은 오류를 방지한다.
int strLen(String s) {
return s.length();
}위 함수는 안전할까? 아니다. 만약 이 함수에 null을 넘기면 NPE이 발생한다. 그렇다면 s가 널 값인지에 대한 검사가 필요할까? 검사의 여부는 이 함수의 사용 의도에 따라 또 달라진다. 이러거나 저러거나 결론은 복잡하다!
그럼 코틀린의 경우는 어떻게 될까?
코틀린에서 이런 함수를 작성할 때 가장 먼저 답을 알아야 할 질문은 "이 함수가 널을 인자로 받을 수 있는가?" 이다.
널을 인자로 받을 수 있다는 말은 strLen(null) 처럼 직접 null 리터럴을 사용하는 경우 뿐 아니라 변수나 식의 값이 실행 시점에 null이 될 수 있는 경우를 모두 포함한다.
널을 인자로 받을 수 없는 경우
fun strLen(s: String) = s.length널을 인자로 받을 수 없는 경우는 위와 같이strLen 함수에서 파라미터 s의 타입을 단순 String으로 지정한다.
이는 s가 항상 String의 인스턴스여야 한다는 뜻이다. 따라서 컴파일러는 널이 될 수 있는 값을 strLen에게 인자로 넘기지 못하도록 막는다. 이렇게 하여strLen에 null 혹은 널이 될 수 있는 인자를 넘기는 것은 금지되며, 만약 그런 값을 넘기게 되면 컴파일 시 오류가 발생하게 된다.
즉, 이 경우 strLen 함수가 결코 실행 시점에 NPE을 발생시키지 않을 것이라고 장담할 수 있다.
널을 인자로 받을 수 없는 경우
fun strLen(s: String?) = s.length앞서 본 함수가 널과 문자열을 인자로 받을 수 있게 하려면 위와 같이 타입 이름 뒤에 ?'를 명시해야 한다.
어떤 타입이든 타입 이름 뒤에 물음표를 붙이면 그 타입의 변수나 프로퍼티에 null 참조를 저장할 수 있다는 뜻이다.
Type? = Type || null널이 될 수 있는 타입의 변수가 있다면 그에 대해 수행할 수 있는 연산이 제한된다.
- 널이 될 수 있는 타입인 변수에 대해
변수.메서드()처럼 메서드를 직접 호출할 수는 없다. - 널이 될 수 있는 값을 널이 될 수 없는 타입의 변수에 대입할 수 없다.
- 널이 될 수 있는 타입의 값을 널이 될 수 없는 타입의 파라미터를 받는 함수에 전달할 수 없다.
이렇게 제약이 많다면 널이 될 수 있는 타입의 값으로 대체 뭘 할 수 있을까?
바로 null과 비교하는 것이다.
null과 비교하고 나면 컴파일러는 그 사실을 기억하고 null이 아님이 확실한 영역에서는 해당 값을 널이 될 수 없는 타입의 값처럼 사용할 수 있다.
2. 타입의 의미
타입이란 무엇이고 왜 변수에 타입을 지정해야 할까?
타입은
분류로, 어떤 값들이 가능한지와 그 타입에 대해 수행할 수 있는 연산의 종류를 결정한다.
자바의 경우 String 타입의 변수에는 String이나 null이라는 두 가지 종류의 값이 들어갈 수 있다. 그러나 이 두 종류의 값에 대해 실행할 수 있는 연산은 완전히 다르다.
String이 들어있는 변수에 대해서는 String 클래스에 정의된 모든 메서드를 호출할 수 있다. 하지만 null이 들어있는 경우에는 사용할 수 있는 연산이 많지 않다.
이는 자바의 타입 시스템이 널을 제대로 다루지 못한다는 뜻이다. 변수에 선언된 타입이 있지만 널 여부를 추가로 검사하기 전에는 그 변수에 대해 어떤 연산을 수행할 수 있을지 알 수가 없는 것이다.
코틀린의 널이 될 수 있는 타입은 이런 문제에 대해 종합적인 해법을 제공한다.
널이 될 수 있는 타입과 널이 될 수 없는 타입을 구분하면 각 타입의 값에 대해 어떤 연산이 가능할지 명확히 이해할 수 있고, 실행 시점에 예외를 발생시킬 수 있는 연산을 판단할 수 있다. 따라서 그런 연산을 아예 금지시킬 수 있다.
3. 안전한 호출 연산자: ?.
코틀린이 제공하는 가장 유용한 도구 중 하나가 안전한 호출 연산자인 ?.이다.
?.은null검사와 메서드 호출을 한 번의 연산으로 수행한다.
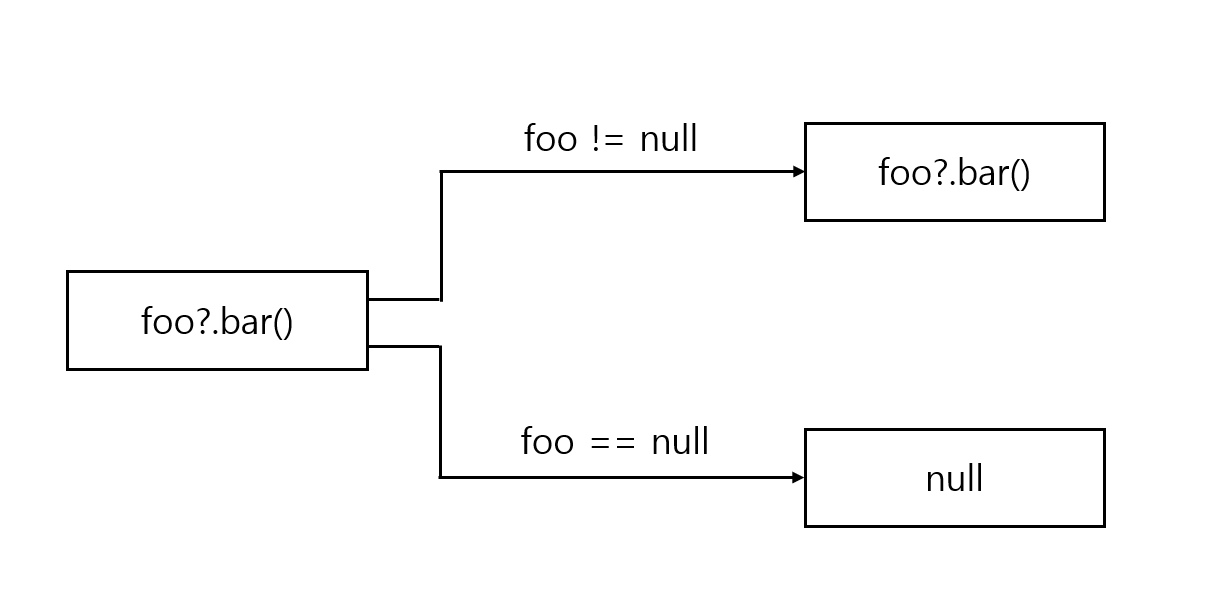
호출하려는 값이 null이 아니라면 ?. 은 일반 메서드 호출처럼 작동한다.
호출하려는 값이 null이면 이 호출은 무시되고 null 이 결과 값이 된다.
메서드 호출 뿐만 아니라 프로퍼티를 읽거나 쓸 때도 안전한 호출을 사용할 수 있다.
class Address(val streetAddress: String, val zipCode: Int,
val city: String, val country: String)
class Company(val name: String, val address: Address?)
class Person(val name: String, val company: Company?)
fun Person.countryName(): String {
val country = this.company?.address?.country
return if (country != null) country else "Unknown"
}
fun main(args: Array<String>) {
val person = Person("Dmitry", null)
println(person.countryName())
}?. 연산자를 사용하면 위와 같이 다른 추가 검사 없이 Person의 회사 주소에서 country 프로퍼티를 단 한 줄로 가져올 수 있다.
하지만 여전히 위 코드는 비효율적이다. 맨 아래의 if문을 보면 country가 null인지 검사해서 정상적으로 얻은 country 값을 반환하거나 null인 경우에 대응하는 "Unknown"을 변환한다. 코틀린을 사용하면 이런 if문도 없앨 수 있다.
4. 엘비스 연산자: ?:
코틀린은 null 대신 사용할 디폴트 값을 지정할 때 편리하게 사용할 수 있는 엘비스 연산자를 제공한다.
?:은 이항 연산자로 좌항을 계산한 값이 널인지 검사한다.

좌항 값이 널이 아니면 좌항 값을 결과로 하고, 좌항 값이 널이면 우항 값을 결과로 한다.
코틀린에서는 return 이나 throw 등의 연산도 식이다. 따라서 엘비스 연산자의 우항에 return , throw 등의 연산을 넣을 수 있고, 엘비스 연산자를 더욱 편하게 사용할 수 있다.
(함수의 전제 조건을 검사하는 경우, 엘비스 연산자의 좌항이 널이면 함수가 즉시 어떤 값을 반환하거나 예외를 던지도록 하여 유용하게 쓸 수 있다.)
5. 안전한 캐스트: as?
코틀린의 타입 캐스트 연산자인 as의 경우 자바 타입 캐스트와 마찬가지로 대상 값을 as 로 지정한 타입으로 바꿀 수 없으면 ClassCastException이 발생한다.
물론 as를 사용할 때마다 is를 통해 미리 as로 변환 가능한 타입인지 검사해볼 수 있다. 그러나 코틀린이라면..... 이런 원시적인 방식보다 더 나은 해법을 제공하지 않을까 하는 합리적 의심이 든다 !
as?연산자는 어떤 값을 지정한 타입으로 캐스트한다.
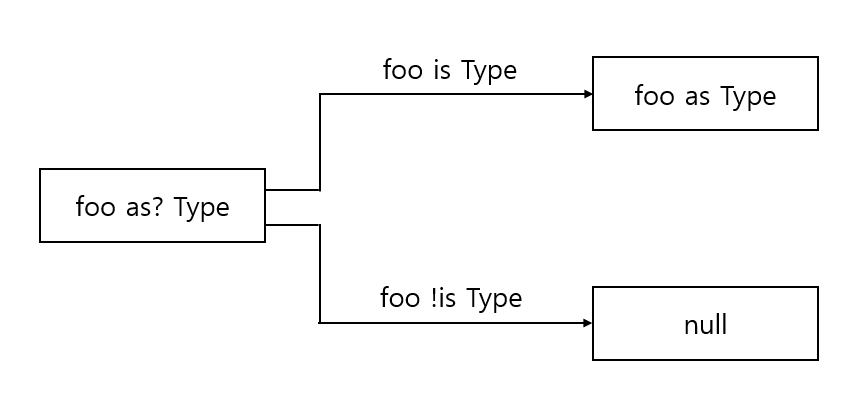
as?는 값을 주어진 타입으로 변환하려 시도하고 타입이 맞지 않아 변환할 수 없으면 null을 반환한다.
안전한 캐스트를 사용할 때 일반적인 패턴은 캐스트를 수행한 뒤에 엘비스 연산자를 사용하는 것이다. 예를 들어 equals를 구현할 때 이런 패턴이 유용하다.
class Person(val firstName: String, val lastName: String) {
override fun equals(o: Any?): Boolean {
val otherPerson = o as? Person ?: return false
return otherPerson.firstName == firstName &&
otherPerson.lastName == lastName
}
override fun hashCode(): Int =
firstName.hashCode() * 37 + lastName.hashCode()
}
fun main(args: Array<String>) {
val p1 = Person("Dmitry", "Jemerov")
val p2 = Person("Dmitry", "Jemerov")
println(p1 == p2)
println(p1.equals(42))
}이 패턴을 사용하면 파라미터로 받은 값이 원하는 타입인지 쉽게 검사하고 캐스트할 수 있고, 타입이 맞지 않으면 쉽게 false를 반환할 수 있다. 이 모든 동작을 한 식으로 해결 가능하다.
6. 널 아님 단언: !!
앞서 살펴본 안전한 호출, 안전한 캐스트, 엘비스 연산자는 유용하긴 하지만 때로는 코틀린의 널 처리 지원을 활용하는 대신 직접 컴파일러에게 어떤 값이 널이 아니라는 사실을 알려주고 싶은 경우가 있다. 이런 정보는 컴파일러에게 어떻게 넘길 수 있을까?
느낌표를 이중으로 사용하면 (
!!) 어떤 값이든 널이 될 수 없는 타입으로 강제로 바꿀 수 있다.
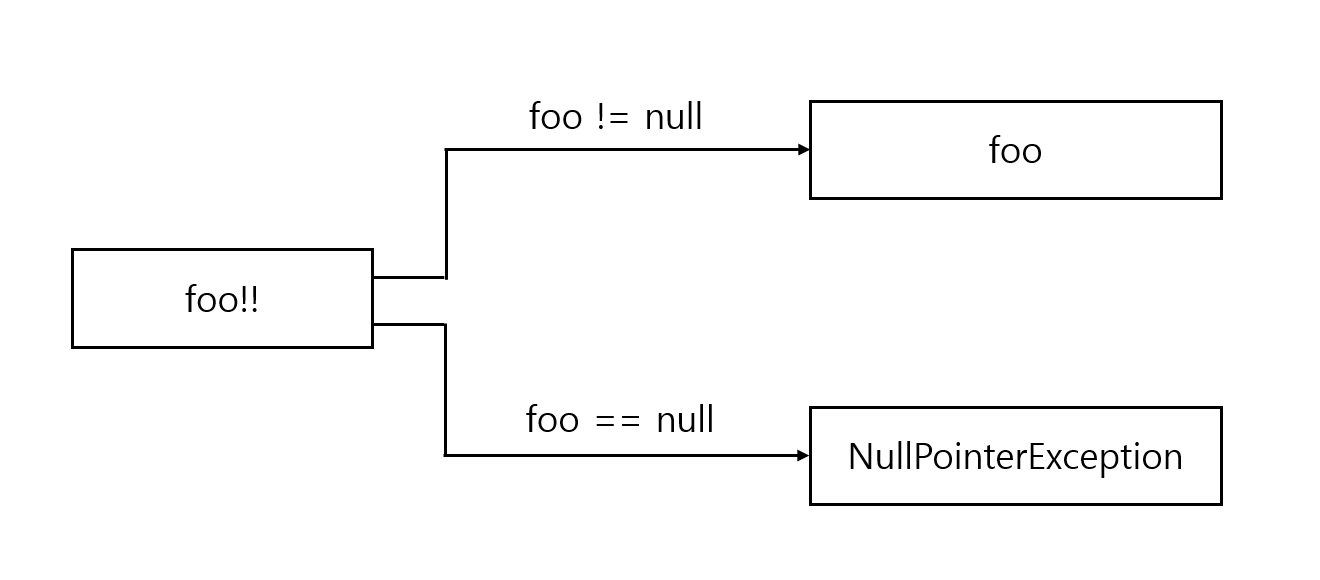
널 아님 단언을 사용하면 값이 널일 때 NPE를 던질 수 있다.
어떤 함수가 값이 널인지 검사한 다음에 다른 함수를 호출한다고 해도 컴파일러는 호출된 함수 안에서 안전하게 그 값을 사용할 수 있음을 인식할 수 없다.
하지만 이런 경우 호출된 함수가 언제나 다른 함수에서 널이 아닌 값을 전달받는다는 사실이 분명하다면 굳이 널 검사를 다시 수행하고 싶지 않을 것이다. 이럴 때 널 아님 단언문을 쓸 수 있다.
기억해야 할 점은 어떤 값이 널이었는지 확실히 하기 위해 여러
!!단언문을 한 줄에 함께 쓰는 일을 피하라.
!!를 널에 대해 사용해서 발생하는 예외의 스택 트레이스에는 어떤 파일의 몇 번재 줄인지에 대한 정보는 들어있지만 어떤 식에서 예외가 발생했는지에 대한 정보는 들어있지 않기 때문이다.
7. let 함수
지금까지는 널이 될 수 있는 타입의 값에 대해 어떻게 접근하는지에 대해 주로 살펴봤다. 하지만 널이 될 수 있는 값을 널이 아닌 값만 인자로 받는 함수에 넘기려면 어떻게 해야 할까?
그런 호출은 안전하지 않기 때문에 컴파일러는 그 호출을 허용하지 않는다. 코틀린의 경우 이런 경우 특별한 지원을 제공하지 않지만 표준 라이브러리에 도움이 될 수 있는 함수가 있다.
let함수를 안전한 호출 연산자와 함께 사용하면 원하는 식을 평가해서 결과가 널인지 검사한 다음에 그 결과를 변수에 넣는 작업을 간단한 식을 사용해 한꺼번에 처리할 수 있다.
let을 사용하는 가장 흔한 용례는 널이 될 수 있는 값을 널이 아닌 값만 인자로 받는 함수에 넘기는 경우다.
fun sendEmailTo(email: String) {
println("Sending email to $email")
}
fun main(args: Array<String>) {
var email: String? = "yole@example.com"
email?.let { sendEmailTo(it) }
email = null
email?.let { sendEmailTo(it) }
}하지만 let 함수를 통해 인자를 전달할 수도 있다. let 함수는 자신의 수신 객체를 인자로 전달받은 람다에게 넘긴다. 널이 될 수 있는 값에 대해 안전한 호출 구문을 사용해 let을 호출하되 널이 될 수 없는 타입을 인자로 받는 람다를 let에 전달한다. 이렇게 하면 널이 될 수 있는 타입의 값을 널이 될 수 있는 타입의 값으로 바꿔서 람다에 전달하게 된다.

let을 안전하게 호출하면 수신 객체가 널이 아닌 경우 람다를 실행해준다.
여러 값이 널인지 검사해야 한다면 let 호출을 중첩시켜서 처리할 수 있다. 그렇게 let을 중첩시켜 처리하면 코드가 복잡해져서 알아보기 어려워진다. 그런 경우 일반적인 if를 사용해 모든 값을 한꺼번에 검사하는 편이 낫다.
8. 나중에 초기화할 프로퍼티
실제로는 널이 될 수 없는 프로퍼티인데 생성자 안에서 널이 아닌 값으로 초기화할 방법이 없는 경우가 있다. 이런 상황을 코틀린에서는 어떻게 처리할까?
코틀린에서는 일반적으로 생성자에서 모든 프로퍼티를 초기화해야 한다. 게다가 프로퍼티 타입이 널이 될 수 없는 타입이라면 반드시 널이 아닌 값으로 해당 프로퍼티를 초기화해야 한다. 그러나 이런 초기화 값을 제공할 수 없으면 널이 될 수 있는 타입을 사용할 수밖에 없다.
하지만 널이 될 수 있는 타입을 사용하면 모든 프로퍼티 접근에 널 검사를 넣거나 !! 연산자를 써야 한다. 특히 프로퍼티를 여러 번 사용해야 하면 코드가 못생겨진다.
이를 해결하기 위해
lateinit변경자를 붙이면 프로퍼티를 나중에 초기화할 수 있다.
class MyService {
fun performAction(): String = "foo"
}
class MyTest {
private lateinit var myService: MyService // 초기화하지 않고 널이 될 수 없는 프로퍼티를 선언한다.
@Before fun setUp() {
myService = MyService()
}
@Test fun testAction() {
Assert.assertEquals("foo",
myService.performAction()) // 널 검사를 수행하지 않고 프로퍼티를 사용한다.
}
}나중에 초기화하는 프로퍼티는 항상 `var`여야 한다. `val` 프로퍼티는 `final` 필드로 컴파일되며, 생성자 안에서 반드시 초기화해야 하기 때문이다. (late-initialized 프로퍼티는 생성자 밖에서 초기화해야 한다.)
그렇지만 나중에 초기화하는 프로퍼티는 널이 될 수 없는 타입이라 해도 더 이상 생성자 안에서 초기화할 필요가 없다. 그 프로퍼티를 초기화하기 전에 프로퍼티에 접근하면 예외가 발생하는데, 단순 NPE 예외보다 훨씬 구체적인 예외가 발생하므로 더 낫다.
9. 널이 될 수 있는 타입 확장
널이 될 수 있는 타입에 대한 확장 함수를 정의하면 null 값을 다루는 강력한 도구로 활용할 수 있다.
어떤 메서드를 호출하기 전에 수신 객체 역할을 하는 변수가 널이 될 수 없다고 보장하는 대신 직접 변수에 대해 메서드를 호출해도 확장 함수인 메서드가 알아서 널을 처리해준다.
이런 처리는 확장 함수에서만 가능하다. 일반 멤버 호출은 객체 인스턴스를 통해 *디스패치되므로 그 인스턴스가 널인지 여부를 검사하지 않는다.
*디스패치: 객체지향 언어에서 객체의 동적 타입에 따라 적절한 메서드를 호출해주는 방식
널이 될 수 있는 타입에 대한 확장을 정의하면 널이 될 수 있는 값에 대해 그 확장 함수를 호출할 수 있다. 자바의 경우 메서드 안의 this는 그 메서드가 호출된 수신 객체를 가리키므로 항상 널이 아니다. 그러나 코틀린에서는 널이 될 수 있는 타입의 확장 함수 안에서 this가 널이 될 수 있다.
10. 타입 파라미터의 널 가능성
코틀린에서 함수나 클래스의 모든 타입 파라미터는 기본적으로 널이 될 수 있다. 널이 될 수 있는 타입을 포함하는 어떤 타입이라도 타입 파라미터를 대신할 수 있다.
따라서 타입 파라미터 T를 클래스나 함수 안에서 타입 이름으로 사용하면 이름 끝에 물음표가 없더라도 T는 널이 될 수 있는 타입이다.
fun <T> printHashCode(t: T) {
println(t?.hashCode())
}
>>> printHashCode(null)
null위 함수 호출에서 타입 파라미터 T에 대해 추론한 타입은 널이 될 수 있는 Any? 타입이다. t 파라미터의 타입 이름 T에는 물음표가 붙어있지 않지만 t 는 null을 받을 수 있다.
타입 파라미터가 널이 아님을 확실히 하려면 널이 될 수 없는 타입 상한을 지정해야 한다.
fun <T: Any> printHashCode(t: T) {
println(t.hashCode())
}
>>> printHashCode(null)
Error: Type parameter bound for `T` is not satisfied
>>> printHashCode(42)
42위와 같이 널이 될 수 없는 타입 상한을 지정하면 널이 될 수 있는 값을 거부하게 된다.
코틀린의 원시 타입
코틀린은 원시 타입과 래퍼 타입을 구분하지 않는다. 그 이유와 코틀린 내부에서 어떻게 원시 타입에 대한 래핑이 작동하는지에 대해 알아보고, 자바 타입과 코틀린 타입 간의 대응 관계에 대해서도 살펴보자.
1. 원시타입: Int, Boolean 등
자바의 경우 원시 타입과 참조 타입을 구분한다. 그리고 참조 타입이 필요한 경우 특별한 래퍼 타입으로 원시 타입 값을 감싸서 사용한다.
- 원시 타입: 변수에 그 값이 직접 들어간다.
- 참조 타입: 변수에 메모리상의 객체 위치가 들어간다.
그러나 코틀린은 원시 타입과 래퍼 타입을 구분하지 않으므로 항상 같은 타입을 사용한다.
원시 타입과 참조 타입이 같다면 코틀린이 그들을 항상 객체로 표현하는 걸까? 그렇게 한다면 비효율적이지 않을까? 코틀린이 그럴리가 없다. (?) 코틀린은 항상 객체로 표현하지 않는다.
실행 시점에 숫자 타입은 가능한 한 가장 효율적인 방식으로 표현된다. 대부분의 경우 코틀린의 Int 타입은 자바 int 타입으로 컴파일된다.
Int와 같은 코틀린 타입에는 널 참조가 들어갈 수 없기 때문에 쉽게 그에 상응하는 자바 원시 타입으로 컴파일할 수 있다. 마찬가지로 반대로 자바 원시 타입의 값은 결코 널이 될 수 없으므로 자바 원시 타입을 코틀린에서 사용할 때도 널이 될 수 없는 타입으로 취급할 수 있다.
2. 널이 될 수 있는 원시 타입: Int?, Boolean? 등
null 참조는 자바의 참조 타입 변수에만 대입할 수 있으므로 널이 될 수 있는 코틀린 타입은 자바 원시 타입으로 표현할 수 없다.
따라서 코틀린에서 널이 될 수 있는 원시 타입을 사용하면 그 타입은 자바의 래퍼 타입으로 컴파일된다.
3. 숫자 변환
코틀린과 자바의 가장 큰 차이점 중 하나는 숫자를 변환하는 방식이다.
코틀린은 한 타입의 숫자를 다른 타입의 숫자로 자동 변환하지 않는다.
결과 타입이 허용하는 숫자의 범위가 원래 타입의 범위보다 넓은 경우조차도 자동 변환은 불가능하다. 대신 직접 변환 메서드를 호출해야 한다.
코틀린은
toInt(),toChar()등 모든 원시 타입(Boolean 제외)에 대한 변환 함수를 제공한다.
이 중에는 더 표현 범위가 넓은 타입으로 변환하는 함수도 있고, 더 표현 범위가 좁은 타입으로 변환하면서 값을 벗어나는 경우에는 일부를 잘라내는 함수도 있다.
4. Any, Any?: 최상위 타입
자바에서 Object가 클래스 계층의 최상위 타입이듯 코틀린에서는 Any 타입이 모든 널이 될 수 없는 타입의 조상 타입이다.
자바에서는 참조 타입만 Object에 포함되며, 원시 타입은 그런 계층에 들어있지 않다. 즉, Object 타입의 객체가 필요한 경우 int와 같은 원시 타입을 래퍼 타입으로 감싸야 한다.
그러나 코틀린에서는
Any가Int등의 원시 타입을 포함한 모든 타입의 조상이다. 만약 널을 포함하는 모든 값을 대입할 변수를 선언하려면 쉽게 유추할 수 있듯이Any?타입을 사용해야 한다.
5. Unit 타입: 코틀린의 void
코틀린의 Unit 타입은 자바의 void와 같은 기능을 한다.
fun f(): Unit { ... }
fun f() { ... }위 코드의 첫번째 줄과 두번째 줄은 같은 의미다. 즉, 반환 타입이 Unit인 함수는 반환 타입 선언이 없는 함수와 같다.
그렇다면 코틀린의 Unit이 자바 void와 다른 점은 무엇일까?
Unit은 모든 기능을 갖는 일반적인 타입이며,void와 달리Unit을 타입 인자로 쓸 수 있다.
즉, 묵시적으로 Unit을 반환하는 함수인 것이다.
이 특성은 제네릭 파라미터를 반환하는 함수를 오버라이드하면서 반환 타입으로 Unit을 쓸 때 유용하다.
interface Processor<T> {
fun process(): T
}
class NoResultProcessor : Processor<Unit> { // Unit을 반환하지만 타입을 지정할 필요는 없다.
override fun process() {
// do stuff
} //여기서 따로 return을 명시할 필요가 없다.
}타입 인자로 '값 없음'을 표현한다고 생각하면 된다.
6. Nothing 타입: 이 함수는 결코 정상적으로 끝나지 않는다
코틀린에는 결코 성공적으로 값을 돌려주는 일이 없으므로 '반환 값'이라는 개념 자체가 의미 없는 함수가 일부 존재한다.
예를 들어 테스트 라이브러리들은 fail 이라는 함수를 제공하는 경우가 많은데, fail은 특별한 메세지가 들어있는 예외를 던져서 현재 테스트를 실패시킨다.
다른 예로는 무한 루프를 도는 함수도 값을 반환하며, 정상적으로 끝나지 않는다.
이런 함수들을 호출하는 코드를 분석하는 경우, 함수가 정상적으로 끝나지 않는다는 사실을 알면 유용하다. 그런 경우를 표현하기 위해 코틀린에는 Nothing 이라는 특별한 반환 타입이 있다.
Nothing타입은 아무 값도 포함하지 않는다.
따라서 Nothing은 함수의 반환 타입이나 반환 타입으로 쓰일 파라미터로만 쓸 수 있다. 그 외의 다른 용도로 사용하는 경우 Nothing 타입의 변수를 선언하더라도 그 변수에 아무 값도 저장할 수 없으므로 아무 의미가 없다.
컬렉션과 배열
1. 널 가능성과 컬렉션
컬렉션 안에 널 값을 넣을 수 있는지의 여부는 어떤 변수의 값이 널이 될 수 있는지의 여부와 마찬가지로 매우 중요하다.
변수 타입 뒤에
?를 붙이면 그 변수에 널을 저장할 수 있다는 뜻인 것처럼 타입 인자로 쓰인 타입에도 같은 표시를 사용할 수 있다.
널이 될 수 있도록 컬렉션을 만들 때에는 널이 될 수 있는 게 컬렉션의 원소인지 컬렉션 자체인지를 헷갈리면 안된다.
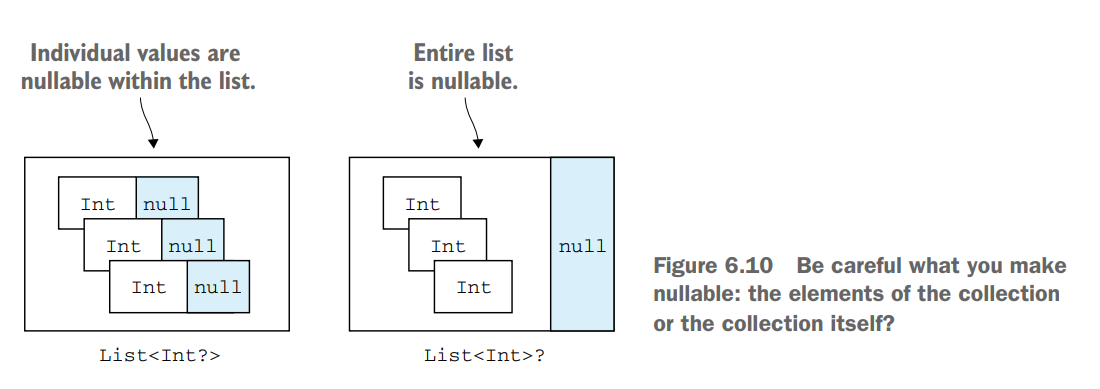
(출처: Kotlin in Action)
경우에 따라 널이 될 수 있는 값으로 이루어진 널이 될 수 있는 리스트를 정의해야 할 수도 있다. 이 경우 쉽게 유추할 수 있듯이 List<Int?>?와 같이 표현할 수 있다.
이런 리스트를 처리할 때는 변수에 대해 널 검사를 수행한 다음에 그 리스트에 속한 모든 원소에 대해 다시 널 검사를 수행해야 한다.
2. 읽기 전용과 변경 가능한 컬렉션
코틀린 컬렉션과 자바 컬렉션을 나누는 가장 중요한 특성 하나는 코틀린에서는 컬렉션 안의 데이터에 접근하는 인터페이스와 컬렉션 안의 데이터를 변경하는 인터페이스를 분리했다는 점이다.
Collection 인터페이스를 사용하는 경우
- 컬렉션 안의 원소에 이터레이션
- 컬렉션의 크기를 얻음
- 어떤 값이 컬렉션 안에 들어있는지 검사
- 컬렉션에서 데이터를 읽는 여러 다른 연산을 수행
-> 원소를 추가하거나 제거하는 메서드는 없음
MutableCollection 인터페이스를 사용하는 경우
- 원소를 추가함
- 원소를 삭제함
- 컬렉션 안의 원소를 모두 지움
-> Collection을 확장하면서 컬렉션 내용을 변경하는 메서드를 더 제공함
읽기 전용 컬렉션이 항상 스레드 안전하지는 않다는 점을 명심해야 한다. 다중 스레드 환경에서 데이터를 다루는 경우 그 데이터를 적절히 동기화하거나 동시 접근을 허용하는 데이터 구조를 활용해야 한다.
3. 코틀린 컬렉션과 자바
모든 코틀린 컬렉션은 그에 상응하는 자바 컬렉션 인터페이스의 인스턴스이므로 코틀린과 자바를 오갈 때 아무 변환도 필요 없다.
하지만 코틀린은 모든 자바 컬렉션 인터페이스마다 읽기 전용 인터페이스와 변경 가능한 인터페이스라는 두 가지 표현을 제공한다.
자바는 읽기 전용 컬렉션과 변경 가능 컬렉션을 구분하지 않으므로, 코틀린에서 읽기 전용 컬렉션으로 선언된 객체라도 자바 코드에서는 그 컬렉션 객체의 내용을 변경할 수 있다.
따라서 컬렉션을 자바로 넘기는 코틀린 프로그램을 작성한다면 호출하려는 자바 코드가 컬렉션을 변경할지 여부에 따라 올바른 파라미터 타입을 사용해야 한다.
4. 컬렉션을 플랫폼 타입으로 다루기
플랫폼 타입의 경우 코틀린 쪽에서는 널 관련 정보가 없다.
따라서 컴파일러는 코틀린 코드가 그 타입을 널이 될 수 있는 타입이나 널이 될 수 없는 타입 어느 쪽으로든 사용할 수 있게 허용한다. 마찬가지로 자바쪽에서 선언한 컬렉션 타입의 변수를 코틀린에서는 플랫폼 타입으로 본다.
플랫폼 타입인 컬렉션은 기본적으로 변경 가능성에 대해 알 수 없다. 따라서 코틀린 코드는 그 타입을 읽기 전용 컬렉션이나 변경 가능한 컬렉션 어느 쪽으로든 다룰 수 있다.
하지만 컬렉션 타입이 시그니처에 들어간 자바 메서드 구현을 오버라이드하려는 경우 읽기 전용 컬렉션과 변경 가능 컬렉션의 차이가 문제가 된다.
플랫폼 타입에서 널 가능성을 다룰 때처럼 이런 경우에도 오버라이드하려는 메서드의 자바 컬렉션 타입을 어떤 코틀린 컬렉션 타입으로 표현할지 결정해야 한다.
이런 상황에는 아래의 여러가지 요소들을 선택하여 코틀린에서 사용할 컬렉션 타입에 반영해야 한다.
- 컬렉션이 널이 될 수 있는가?
- 컬렉션의 원소가 널이 될 수 있는가?
- 오버라이드하는 메서드가 컬렉션을 변경할 수 있는가?
5. 객체의 배열과 원시 타입의 배열
자바 main 함수의 표준 시그니처에는 배열 파라미터가 들어있어서 지금까지 살펴본 여러 예제에서 코틀린 배열 타입을 이미 봤다.
코틀린 배열은 타입 파라미터를 받는 클래스다. 배열의 원소 타입은 바로 그 타입 파라미터에 의해 정해진다.
코틀린에서 배열을 만드는 방법은 다양하다.
arrayOf함수에 원소를 넘기면 배열을 만들 수 있다.arrayOfNulls함수에 정수 값을 인자로 넘기면 모든 원소가null이고 인자로 넘긴 값과 크기가 같은 배열을 만들 수 있다.
물론 원소 타입이 널이 될 수 있는 타입인 경우에만 이 함수를 쓸 수 있다.Array생성자는 배열 크기와 람다를 인자로 받아서 람다를 호출해서 각 배열 원소를 초기화해준다.
arrayOf를 쓰지 않고 각 원소가 널이 아닌 배열을 만들어야 하는 경우 이 생성자를 사용한다.
다른 제네릭 타입에서처럼 배열 타입의 타입 인자도 항상 객체 타입이 된다.
코틀린은 원시 타입의 배열을 표현하는 별도 클래스(IntArray , ByteArray , CharArray , BooleanArray등)를 각 원시 타입마다 하나씩 제공한다.
원시 타입의 배열을 만드는 방법은 다음과 같다.
- 각 배열 타입의 생성자는
size인자를 받아서 해당 원시 타입의 디폴트 값(보통은 0)으로 초기화된size크기의 배열을 반환한다. - *팩토리 함수는 여러 값을 가변 인자로 받아서 그런 값이 들어간 배열을 반환한다.
- 크기와 람다를 인자로 받는 생성자를 사용한다.
*팩토리 함수: IntArray를 생성하는 intArrayOf 등을 말한다.
