느슨한 결합과 비동기 처리를 위해 브로커를 사용하는 방식은 오늘날 마이크로서비스 아키텍처에서 가장 널리 활용되는 패턴입니다. 하지만 모놀리식한 동기 방식에 비해 오류 처리 측면에서는 더 복잡한 문제에 직면할 수 있습니다.
이번 장에서는 카프카를 중심으로 프로듀서와 브로커에서 발생할 수 있는 오류에 대한 해결 전략을 살펴보겠습니다.
브로커 모델의 종류
Pub/Sub
Pub/Sub(Publish/Subscribe) 모델은 메시지 발행자가 메시지를 발행하면 이를 구독한 모든 수신자에게 동시에 전달하는 브로드캐스트 방식의 메시징 모델입니다.
주로 실시간 스트리밍이나 알림 시스템에 사용되며 구독자가 없는 경우 메시지는 즉시 유실됩니다.
대표적인 예로 Redis Pub/Sub이 있으며 메시지를 저장하지 않고 실시간으로만 전달합니다.
Message Queue
메시지 큐는 발행자가 메시지를 큐에 전송하고 큐가 이를 수신자에게 푸시하는 방식으로 동작하는 모델입니다.
대표적인 예로 RabbitMQ 가 있습니다.
RabbitMQ는 AMQP(Advanced Message Queuing Protocol_메시지 전송 표준 프로토콜)를 기반으로 동작하는 메시지 브로커로 복잡한 메시지 라우팅과 신뢰성 있는 전달을 지원합니다.
다음은 AMQP 표준의 핵심 요소 입니다.
- Exchange : 어떤 큐로 메시지를 전송할지를 결정하는 라우터
- Direct : 정확히 일치하는 키를 가진 큐에 전달
- Fanout : 연결된 모든 큐에 메시지 전달 (브로드캐스트)
- Topic : 와일드카드를 이용한 라우팅
- Headers : 메시지의 헤더를 기준으로 라우팅
- Queue : 메시지가 임시 저장되는 큐
- ACK : 소비자가 메시지를 수신한 후 큐에게 보내는 신호. 실패한 경우 재전송 가능
- Persistence : 메시지를 디스크에 저장할 수 있는 기능 제공 (RabbitMQ 메시지는 디폴트로 메모리 저장)
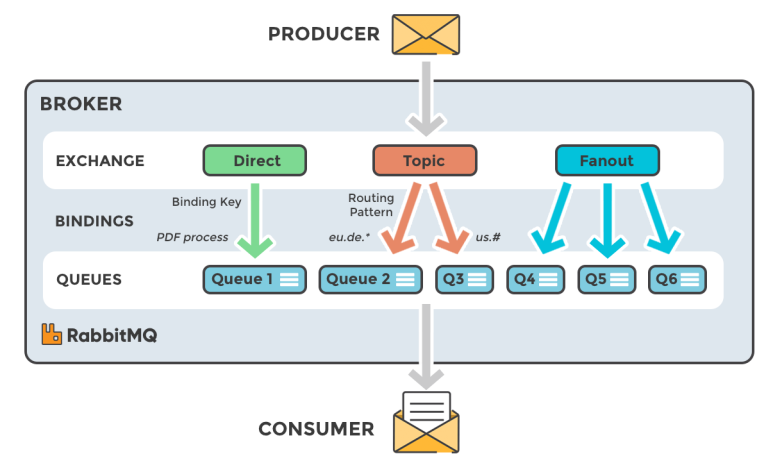
RabbitMQ는 하나의 메시지를 하나의 컨슈머가 처리하는 방식으로 동작하며 큐에 여러 컨슈머를 연결할 경우 라운드로빈 방식으로 메시지가 분산되어 처리됩니다. 컨슈머는 메시지를 읽고 처리한 뒤 ACK(확인 응답)를 전송하고 이때 해당 메시지는 큐에서 삭제됩니다. 만약 ACK을 보내지 않으면 메시지는 다시 전송되거나 큐에 남아 있게 됩니다.
RabbitMQ는 수평 확장성이 제한적이기 때문에 대량의 메시지를 고속으로 처리하는 스트리밍 기반 아키텍처에는 적합하지 않습니다. 그러나 복잡한 라우팅이 필요하거나 신뢰성이 중요한 환경, 예를 들어 결제 처리, 주문 큐, 인증 처리 등에서는 매우 유용하게 사용됩니다.
또한 관리용 웹 UI가 잘 갖춰져 있어 운영과 모니터링이 용이한 점도 장점 중 하나입니다.
요약하면 RabbitMQ는 고성능보다는 신뢰성과 유연한 라우팅, 운영 편의성이 중요한 시스템에 적합한 메시지 브로커입니다.
분산 스트리밍 플랫폼
분산 스트리밍 플랫폼은 대규모 데이터를 실시간으로 저장하고 전송할 수 있는 시스템입니다.
브로커는 데이터를 로그 형태로 저장하고 컨슈머는 이를 폴링 방식으로 읽어갑니다.
대표적인 예로는 Apache Kafka가 있습니다.
- Producer : 메시지를 생산하는 주체
- Broker : 전달받은 메시지를 로그 형태로 저장하는 서버 (카프카)
- Zookeeper : 카프카의 통신과 상태 관리를 담당하고 메타데이터를 저장하는 역할
- Consumer : 메시지를 폴링하는 주체
카프카의 메시지는 토픽에 저장되며 하나의 토픽은 여러 개의 파티션으로 구성됩니다.
메시지는 각 파티션에 라운드로빈 혹은 특정 키 기반으로 분산 저장되며
파티션은 병렬로 메시지를 읽을 수 있도록 구성되어 있어 고속 처리에 유리합니다.
파티션 수를 브로커 수와 동일하게 설정하면 각 브로커가 하나의 파티션을 담당하게 되어 부하 분산이 용이해지고 시스템 리소스를 효율적으로 활용할 수 있습니다. 이 구조는 카프카 성능의 핵심 요소 중 하나입니다.
각 파티션은 하나 이상의 레플리카로 구성됩니다.
이는 특정 브로커에 장애가 발생해도 다른 브로커의 레플리카가 자동으로 리더로 승격되어 메시지 손실 없이 서비스를 지속할 수 있게 합니다. 하지만 레플리카 수가 많을 경우 저장 공간과 네트워크 비용이 증가하므로 보통 2~3개 수준으로 설정하는 것이 일반적입니다.
예를 들어 브로커가 3대이고 파티션을 3개, 레플리카를 2개(master + replica)로 설정한 경우
다음과 같은 구조로 분산됩니다:
| master | replica | |
|---|---|---|
| broker1 | broker1 master | broker3 replica |
| broker2 | broker2 master | broker1 replica |
| broker3 | broker3 master | broker2 replica |
이처럼 파티션과 레플리카를 적절히 설정함으로써 Kafka는 높은 확장성과 내결함성을 갖춘 분산 스트리밍 플랫폼으로 동작할 수 있습니다.
프로듀서 오류 처리 전략
카프카는 AMQP(Advanced Message Queuing Protocol)를 따르지는 않지만 ACK 모드를 통해 메시지가 브로커에 정상적으로 전달되었는지 그리고 레플리카에 복제가 완료되었는지를 확인할 수 있는 메커니즘을 제공합니다.
- 0 : 프로듀서로부터 전송 결과를 받지 않습니다.
- 1 : 프로듀서로부터 전송 결과를 받습니다. (default)
- all : 프로듀서로부터 전송 결과과 레플리카 성공 유무를 받습니다.
ACK Level 을 올리면 내구성이 향상되지만 성능이 저하 됩니다.
@Configuration
public class KafkaProducerConfig {
@Value("${kafka.host}")
private String kafkaHost;
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaHost);
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
// ACK Mode (default = 1)
configProps.put(ProducerConfig.ACKS_CONFIG, "all");
// ACK 실패시 재시도 횟수
configProps.put(ProducerConfig.RETRIES_CONFIG, 3);
// 카프카 접속 오류 타임아웃 시간
configProps.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 1000);
return new DefaultKafkaProducerFactory<>(configProps);
}
}@Slf4j
@Component
@AllArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public void send (String message, String topicName) {
kafkaTemplate.send(topicName, message)
// ACK 성공
.thenAccept(sendResult ->
log.info("[{}] ==> {}", topic, message))
// ACK 실패
.exceptionally(ex -> {
log.error("[{}] failed ==> " + ex.toString());
return null;
});
}
}만약 브로커 서버에 장애가 발생해 접속 지연이 생기면 콜백을 통한 예외 처리만으로는 한계가 있어 메시징 시스템 전체에 영향을 줄 수 있습니다. 이를 대비해 Kafka 대신 외부 저장소에 메시지를 임시 저장하고 별도 에이전트가 이를 주기적으로 폴링해 카프카로 전송하는 구조로 전환하면 일시적인 브로커 장애에도 안정적으로 대응할 수 있습니다.
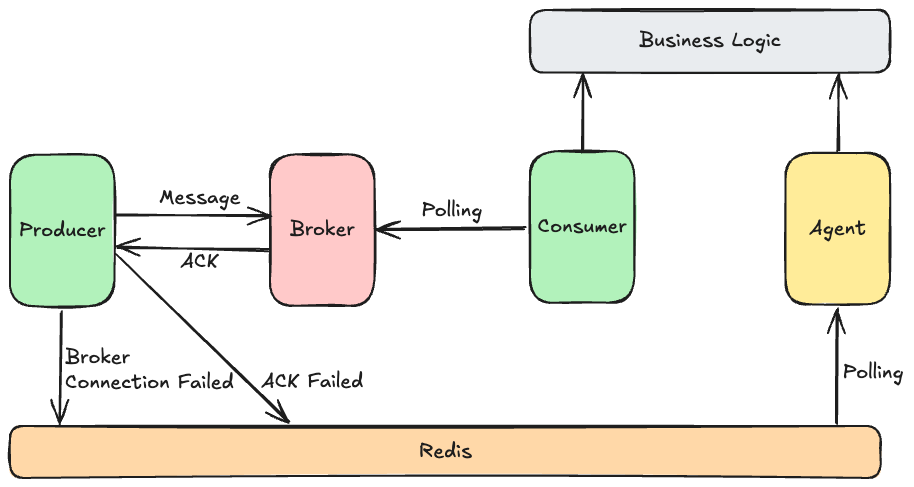
@Slf4j
@Component
@AllArgsConstructor
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
@Override
@CircuitBreaker(name = "kafka", fallbackMethod = "sendMessageFallback")
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message)
.thenAccept(sendResult ->
log.info("[{}] ==> {}", topic, message))
.exceptionally(ex -> {
sendMessageFallback(topic, message, ex);
return null;
});}
public void sendMessageFallback(String topic, String message,
Throwable ex) {
log.error("kafka sendMessage Error : " + topic);
redisTemplate.opsForValue().set(topic + "-" + UUID.randomUUID(), \
message, Duration.ofMinutes(10));
}
}
컨슈머 오류 처리 전략
카프카 컨슈머는 폴링한 메시지를 처리한 후 비즈니스 로직이 성공적으로 완료되었을 때만 offset을 기록하는 수동 커밋 방식을 지원합니다. 이를 통해 로직 오류로 인한 메시지 손실을 방지할 수 있지만 offset이 커밋되기 전까지 동일한 메시지를 반복 처리하게 되어 오류가 지속되면 동일한 실패가 계속 발생하는 단점이 있습니다.
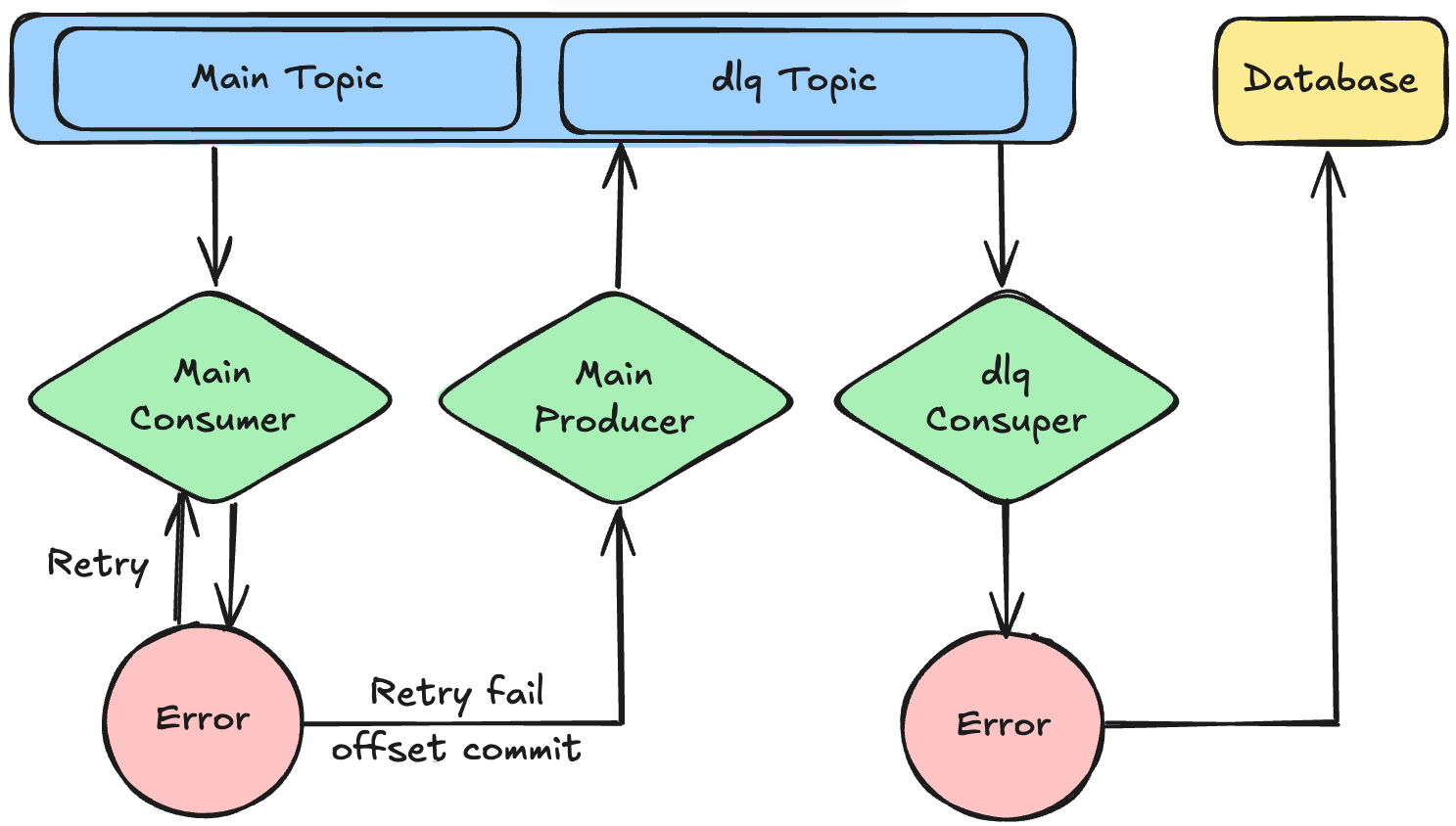
이러한 문제를 해결하기 위해 DLQ(Dead Letter Queue) 패턴을 도입할 수 있습니다.
DLQ는 메시지 처리 실패 시 해당 메시지를 별도의 토픽으로 분리하여 메인 토픽의 정상 메시지 흐름을 방해하지 않도록 하는 기법입니다. 이를 통해 전체 시스템의 안정성과 처리 속도를 유지할 수 있습니다.
일반적으로 메인 컨슈머는 네트워크 장애 등 일시적인 이슈에 대응하기 위해 일정 횟수 재시도를 수행한 후 최종적으로 실패한 메시지를 DLQ 토픽에 저장하고 offset을 커밋합니다.
DLQ 토픽은 별도의 컨슈머가 구독하며 이 컨슈머가 메시지 처리를 재시도합니다.
만약 이 과정에서도 처리에 실패하면 해당 메시지를 데이터베이스에 저장하여 향후 비즈니스 로직 수정 이후에 수동으로 재처리할 수 있도록 합니다.
@Slf4j
@Component
public class KafkaConsumerConfig {
@Value("${kafka.host}")
private String kafkaHost;
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaHost);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "product");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String>
kafkaListenerContainerFactory(
ConsumerFactory<String, String> consumerFactory,
CommonErrorHandler errorHandler) {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// Kafka 2.5 이하 버전에서는 RetryTemplate 사용
factory.setCommonErrorHandler(errorHandler);
// 재시도 후 자동 커밋 되도록
factory.getContainerProperties()
.setAckMode(ContainerProperties.AckMode.RECORD);
return factory;
}
@Bean
public CommonErrorHandler errorHandler(
KafkaTemplate<String, String> kafkaTemplate) {
// 재시도 간격: 2초, 최대 재시도 횟수: 3회
FixedBackOff fixedBackOff = new FixedBackOff(2000L, 3L);
// 재시도 실패시 핸들링 (Dead Letter Queue)
DefaultErrorHandler hadler = new DefaultErrorHandler(
(record, exception) -> {
if (record != null) {
String topicName = record.topic() + "-dlq";
String payload = (String) record.value();
kafkaTemplate.send(topicName, payload)
.exceptionally(ex -> {
log.error("[{}] failed ==> {} | {}",
topicName, payload, ex.toString());
return null;
});
}
}, fixedBackOff);
return hadler;
}
}@Slf4j
@Component
@RequiredArgsConstructor
class UpdateProductSalesCountConsumer {
@KafkaListener(
topics = "product-update-sales-topic",
containerFactory = "kafkaListenerContainerFactory",
concurrency = "3"
)
void updateProductSalesCountConsumer(@Payload String payload) {
// 비즈니스 로직
}
@KafkaListener(
topics = "product-update-sales-topic-dlq",
containerFactory = "kafkaListenerContainerFactory",
concurrency = "3"
)
void updateProductSalesCountConsumerDlq(@Payload String payload) {
try {
// 비즈니스 로직
} catch (Exception e) { // 예외 처리 하였으므로 retry 가 실행되지 않음
// 실패한 메시지를 DB에 저장
}
}
}