유니코드와 UTF-8
왜 유니코드와 UTF-8을 알아야 할까?
"왜 어떤 웹사이트에서는 한글이 깨져보일까?" 또는 "특정 이모티콘이 제대로 표시되지 않는 이유는 무엇일까?"
이러한 문제들은 문자 인코딩과 관련이 있다. 전 세계의 모든 언어와 문자를 컴퓨터가 다룰 수 있도록 하기 위해 만들어진 것이 바로 유니코드와 UTF-8이다.
유니코드(Unicode)란?
- 유니코드는 전 세계 모든 문자를 하나의 표준 코드로 표현하기 위해 개발된 문자셋이다.
등장 배경
- 과거에는 ASCII나 EUC-KR과 같은 각각의 문자 인코딩 방식이 있었지만, 이는 여러 언어를 동시에 표현하는 데 한계가 있었습니다
- 예를 들어, EUC-KR에서는 '한글'이라는 단어를 표현할 수 있지만, 중국어나 일본어 문자와 함께 사용하기가 어려웠다.
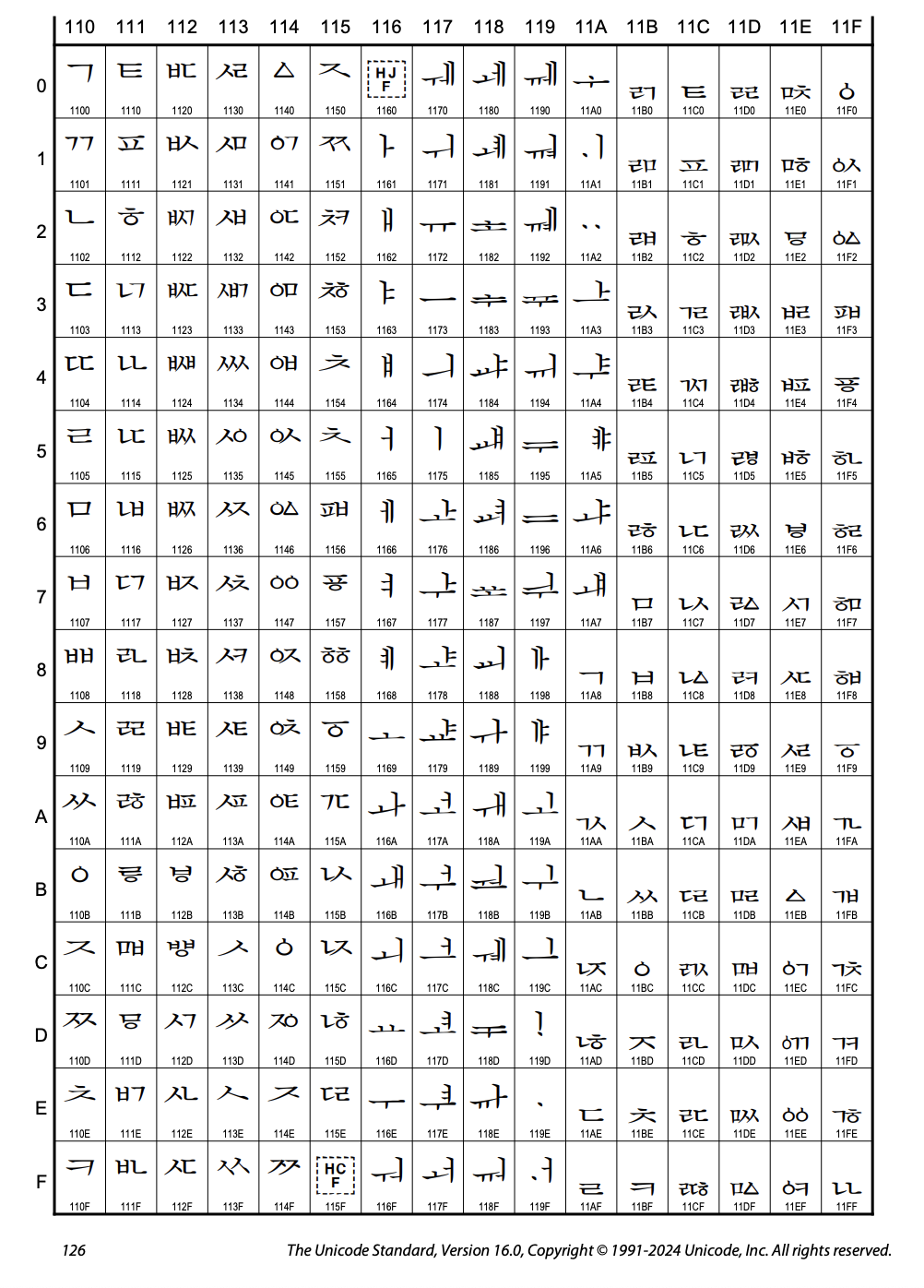
한글은 유니코드에서 다음과 같이 배정되어 있다:
한글 자모: U+1100 ~ U+11FF
한글 호환 자모: U+3130 ~ U+318F
한글 조합 자모: U+3200 ~ U+321F
한글 음절: U+AC00 ~ U+D7AF
예를 들어, '가'라는 글자는 유니코드에서 U+AC00으로 표현된다. '힣'은 U+D7A3있다. 이런 방식으로 11,172개의 한글 음절이 모두 개별적인 코드포인트를 가지고 있다.
UTF-8이란 무엇인가?
- UTF-8은 유니코드 문자를 저장하고 전송하는 데 사용되는 인코딩 방식이다.
가변 길이 인코딩:
UTF-8은 문자에 따라 1바이트에서 4바이트까지 가변 길이를 사용한다.
ASCII(영문, 숫자, 일부 기호)는 1바이트로 표현되고, 한글과 같은 비ASCII 문자는 2~3바이트로 표현된다.
특징: 기존 ASCII와 호환 가능, 효율적인 저장 공간 사용.
작동 방식 예시:
'A' (U+0041): 1바이트로 표현 -> 01000001
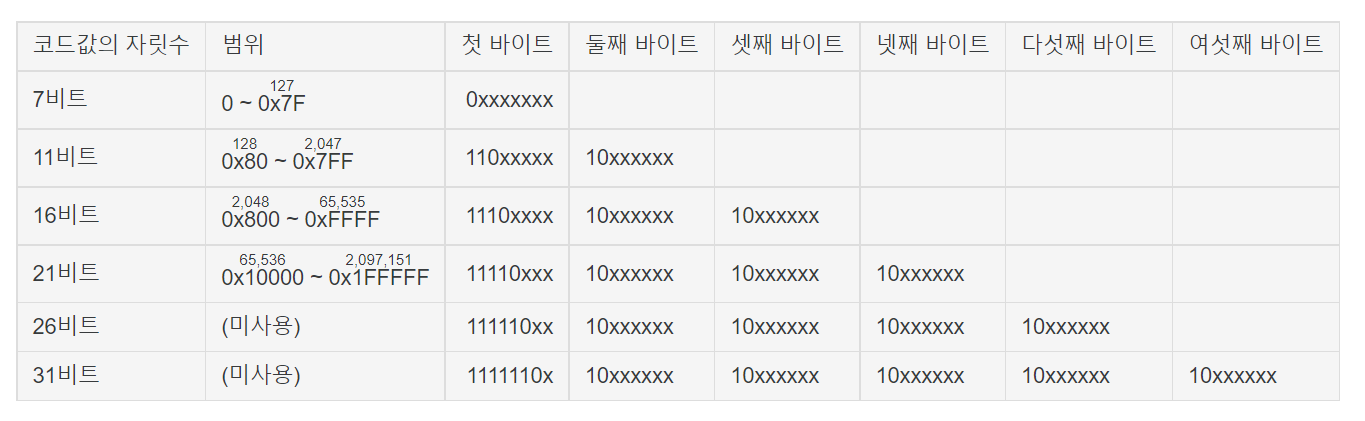
유니코드에서 UTF-8로의 변환 과정
UTF-8은 가변 길이 인코딩 방식이다. 문자마다 필요한 바이트 수가 다르다.
(1) 유니코드 값 확인
모든 문자는 유니코드에서 고유한 번호를 가지고 있다.
예를 들어, '가'의 유니코드 값은 U+AC00입니다.
(2) 2진수로 변환
유니코드 값을 16진수에서 2진수로 변환합니다.
U+AC00 = 10101100 00000000 (16비트)
(3) UTF-8 규칙 적용
UTF-8은 유니코드 값을 바이트로 나누어 표현한다.
밑에 그림과 같이 표현가능
(4) 비트 배치
유니코드 값을 규칙에 따라 나누고 필요한 위치에 채운다.
'가' = 10101100 00000000 → 1110xxxx 10xxxxxx 10xxxxxx
11101010 10110000 10000000 (EAB080)
