뷰 활용하기
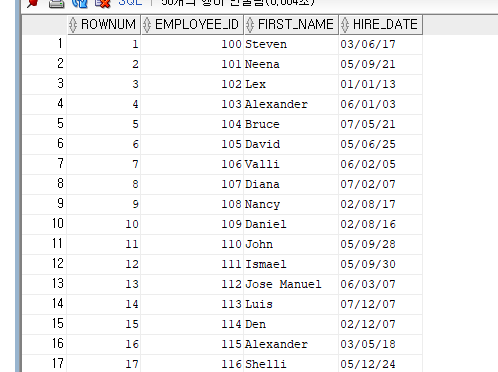
사원중에서 최근에 입사한 사원 5명(TOP-5)만을 얻어 오는 질의문을 작성한다. ROWNUM 칼럼을 이용한다.
ROWNUM 칼럼은 오라클에서 내부적으로 부여되는데 INSERT문에 의해 입력한 순서에, 따라 1 씩 증가되면서 값이 지정된다.
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES;
SELECT ROWNUM, EMPLOYEE_ID FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY HIRE_DATE DESC;
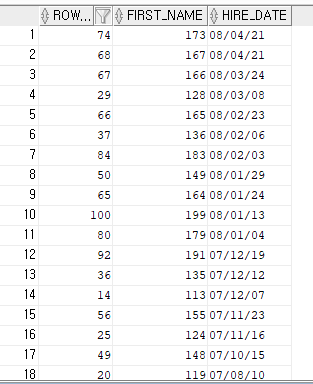
입사일을 기준으로 내림차순으로 정렬을 하였는데도 해당 행으 ROWNUM은 바뀌지 않는다.
데이터가 입력된 시점에서 결정되면 다시는 값이 바귀지 않기 떄문이다.
새로운 테이블에 입사일을 기준으로 내림차순 정렬한 쿼리문의 결과를 저장하면 최근에 입사한 사원순으로 ROWNUM 컬럼 값이 1부터 부여된다.
CREATE OR REPLACE VIEW VIEW_HIRE
AS
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY HIRE_DATE DESC;
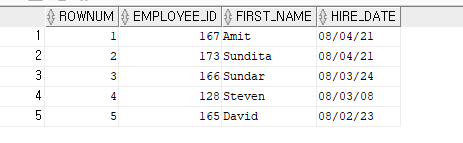
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM VIEW_HIRE;
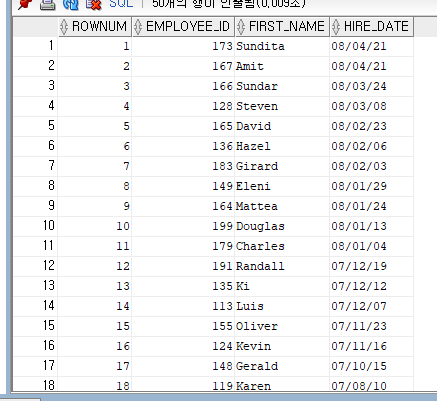
최근 입사일 순으로 TOP 5명을 출력하기
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM VIEW_HIRE
WHERE HIRE_DATE <= 5;
1) 인라인 뷰로 TOP-N 구하기
인라인 뷰는 SQL 문장에서 사용하는 서브 쿼리의 일종으로 보통 FROM 절에 위치해서 테이블처럼 사용하는 것이다. 인라인 뷰란 메인 쿼리의 SELECT 문의 FROM 절 내부에 사용된 서브 쿼리문을 말한다.
CREATE VIEW로 생성하는 것이 아니라 인라인 뷰는 SQL문 내부에 뷰를 정의하고 이를 테이블 처럼 사용한다.
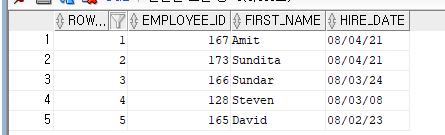
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM (SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY HIRE_DATE DESC)
WHERE ROWNUM <= 5 ; --인라인 뷰
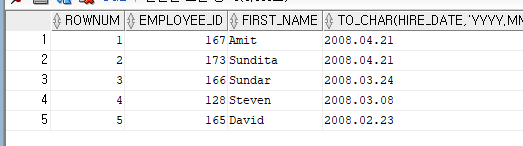
--서브쿼리에 이름을 붙여주고 인라인 뷰로 사용 시 서브쿼리의 이름으로 FROM 절에 기술 가능
--같은 서브쿼리가 여러 번 사용될 경우 중복 작성을 피할 수 있고 실행속도도 빨라진다는 장점이 있음.
WITH TOPN_HIRE
AS
(SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY HIRE_DATE DESC)
SELECT ROWNUM, EMPLOYEE_ID, FIRST_NAME , TO_CHAR(HIRE_DATE, 'YYYY.MM.DD')
FROM TOPN_HIRE
WHERE ROWNUM <= 5;
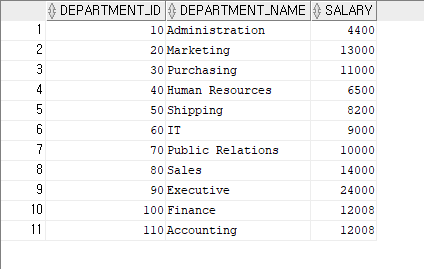
--EMPLOYEES 테이블과 DEPARTMENTS 테이블을 조회하여 부서번호와 부서별 최대 급여 및 부서명을 출력하세요
인라인 뷰를 이용하여 결과값을 나타냄
SELECT E.DEPARTMENT_ID,D.DEPARTMENT_NAME ,E.SALARY
FROM( SELECT DEPARTMENT_ID,MAX(SALARY) SALARY
FROM EMPLOYEES GROUP BY DEPARTMENT_ID ) E ,DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID;
아래는 조인을 이용하여 나타낸 것이다
SELECT E.DEPARTMENT_ID, D.DEPARTMENT_NAME , E.SALARY
FROM (SELECT DEPARTMENT_ID, MAX(SALARY) SALARY
FROM EMPLOYEES GROUP BY DEPARTMENT_ID
) E INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
--[문제] EMPLOYEES 테이블에서 급여가 자신이 속한 부서의 평균 급여보다 많이받는
--사원의 부서번호, 이름 급여를 출력하는 SELECT문을 작성하시오.
-- 인라인 뷰 형태로
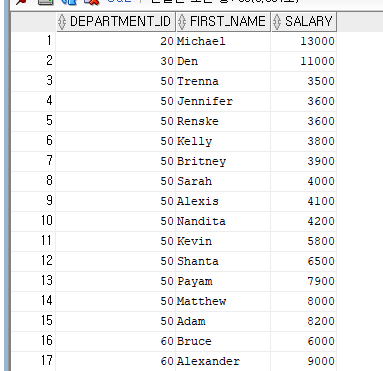
SELECT E.DEPARTMENT_ID,E.FIRST_NAME, E.SALARY
FROM EMPLOYEES E INNER JOIN (SELECT DEPARTMENT_ID, AVG(SALARY) D_SALARY
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID) D
ON E.DEPARTMENT_ID = D.DEPARTMENT_ID
WHERE E.SALARY > D.D_SALARY
ORDER BY E.DEPARTMENT_ID;
WITH DEPT_SAL
AS
(SELECT DEPARTMENT_ID, AVG(SALARY) D_SALARY
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID)
SELECT E.DEPARTMENT_ID, E.FIRST_NAME, E.SALARY
FROM EMPLOYEES E INNER JOIN DEPT_SAL D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID
WHERE E.SALARY > D.D_SALARY
ORDER BY E.DEPARTMENT_ID;
WITH
서브쿼리에 이름을 붙여주고 인라인 뷰로 사용 시 서브쿼리의 이름으로 FROM절에 기술 가능하다
같은 서브쿼리가 여러번 사용될 경우 중복 작성을 피할 수 있고 실행속도도 빨라진다는 장점
순위 함수
특정 컬럼을 기준으로 크기에 따른 순위를 구하는 함수들이다. RANK() OVER(), DENSE_RANK() OVER(), ROW_NUMBER() OVER() 가 존재한다. 그룹내에서 순위는 RANK() OVER(PARTITION~) 함수 사용한다.
①RANK() OVER()
순위 부여시 중복값(같은값)이 발생되면 중복 값의 갯수만큼 건너 뛰고 다음 순위 부여한다.
예를 들어 90,80,80,80,70이면 순위는 1,2,2,2,5 로 부여한다.
--사원테이블에서 30번 부서에 소속된 사원 중에서 급여를 가장 많이 받는 순으로
--사원번호, 사원명, 급여 ,순위를 부여하여 출력해 주세요.
select EMPLOYEE_ID AS 사원번호, FIRST_NAME AS 사원명, SALARY AS 입사일자,
RANK() OVER(ORDER BY SALARY DESC) AS 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;--사원테이블에서 60번 부서에 소속된 사원 중에서
--입사년도가 가장 빠른 순부터 사원번호,사원명,입사일자,순위를 부여하여 출력해 주세요.
SELECT EMPLOYEE_ID AS 사원번호 , FIRST_NAME AS 사원명 , HIRE_DATE AS 입사일자,
RANK() OVER(ORDER BY HIRE_DATE DESC) AS 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;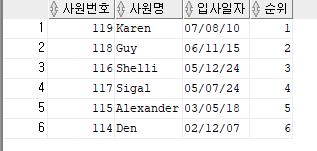
--사원테이블에서 급여를 가장많이받는 순으로 순위를 부여하고 상위 3명만 출력해 봅시다.
SELECT SALARY_RANK,
FIRST_NAME, SALARY
FROM ( SELECT FIRST_NAME, SALARY
,RANK() OVER(ORDER BY SALARY DESC) AS SALARY_RANK
FROM EMPLOYEES
ORDER BY SALARY DESC)
--WHERE ROWNUM <= 3;
WHERE SALARY_RANK <=3;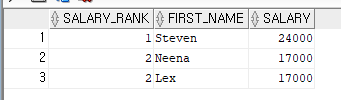
② DENSE_RANK() OVER()
-사원테이블에서 30번 부서에 소속된 사원 중에서 급여를 가장 많이 받는 순으로
--사원번호, 사원명, 급여, 순위를 부여하여 출력해 주세요.
SELECT EMPLOYEE_ID 사원번호, FIRST_NAME 사원명, SALARY 입사일자,
DENSE_RANK() OVER(ORDER BY SALARY DESC) 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;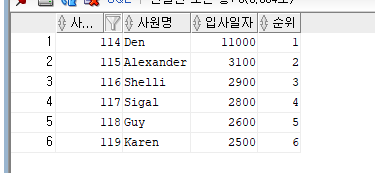
③ ROW_NUMBER() OVER()
-- ROW_NUMBER()
-- 사원테이블에서 30번 부서에 소속된 사원 중에서 급여를 가장 많이 받는 순으로
-- 사원번호, 사원명, 급여, 번호를 부여하여 출력해 주세요.
SELECT EMPLOYEE_ID 사원번호, FIRST_NAME 사원명, SALARY 급여
,ROW_NUMBER() OVER(ORDER BY SALARY DESC) 순위
FROM EMPLOYEES
WHERE DEPARTMENT_ID = 30;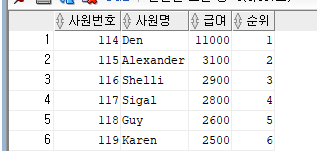
④PATITION BY
오라클에서 그룹함수를 사용할 때 PARTITION BY를 사용하여 그룹으로 묶어서 연산을 할 수 있다. GROUP BY 절을 사용하지 않고, 조회된 각 행에 그룹으로 집계된 값을 표시할 때 OVER 절과 함께 PARTITION BY 절을 사용하면 된다.
그룹함수([칼럼]) OVER (PARTITION BY 칼럼1, 칼럼2...[ORDER BY 절]..)
--PARTITION BY
--부서별 급여의 합 출력
SELECT DEPARTMENT_ID,
SUM(SALARY)
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 30
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID;
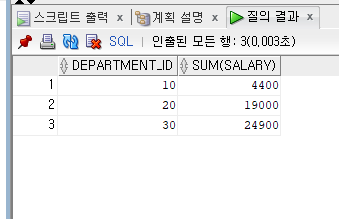
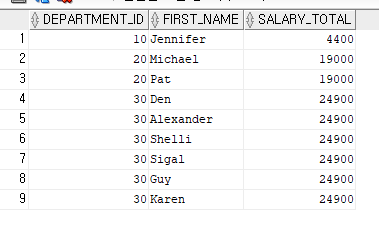
--부서번호와 사원명, 부서별 급여의 합을 함께 출력
SELECT DEPARTMENT_ID,
FIRST_NAME,
SUM(SALARY) OVER(PARTITION BY DEPARTMENT_ID) AS SALARY_TOTAL
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 30
ORDER BY DEPARTMENT_ID;위의 예제를 보면 데이터를 조회한 각 행에 그룹함수로 집계한 값을 추가로 각 행에 표시하며, 조회된 데이터는 GROUP BY 절을 사용하지 않았기 대문에 데이터가 변형되지 않는다.
--그룹함수를 사용할 때는 OVER 절을 함께 사용해야 하며,
--OVER 절 내부에 PARTITION BY 절을 사용하지 않으면 쿼리 결과 전체를 집계하며
--PARTITION BY 절을 사용하면 쿼리 결과에서 해당 칼럼을 그룹으로 묶어서 결과를 표시한다.
SELECT DEPARTMENT_ID,
FIRST_NAME,
SALARY,
SUM(SALARY) OVER(PARTITION BY DEPARTMENT_ID) AS DEPARTMENT_TOTAL,
SUM(SALARY) OVER() AS SALARY_TOTAL
FROM EMPLOYEES
WHERE DEPARTMENT_ID BETWEEN 10 AND 30
ORDER BY DEPARTMENT_ID;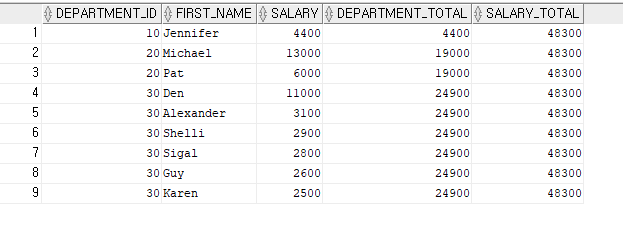
--각 부서에 소속된 사원전체가 아니라 각 부서별 한명의 사원만을 출력하고자 한다.
--이때 사원번호, 사원명, 직무번호, 급여, 부서번호를 조회해 봅시다.
-- 그전에 각 부서별로 번호를 부여해 봅시다.
SELECT EMPLOYEE_ID
,FIRST_NAME
,JOB_ID
,SALARY
,DEPARTMENT_ID
,ROW_NUMBER() OVER(PARTITION BY DEPARTMENT_ID ORDER BY EMPLOYEE_ID) AS RNUM
FROM EMPLOYEES
ORDER BY DEPARTMENT_ID;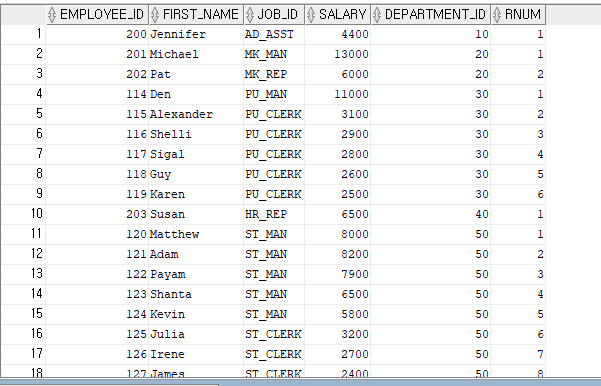
SELECT EMPLOYEE_ID,FIRST_NAME, DEPARTMENT_ID,HIRE_DATE
FROM(SELECT ROW_NUMBER() OVER(PARTITION BY DEPARTMENT_ID ORDER BY EMPLOYEE_ID)
AS RNUM,
EMPLOYEE_ID, FIRST_NAME , DEPARTMENT_ID, HIRE_DATE
FROM EMPLOYEES) DATA
WHERE DATA.RNUM = 1;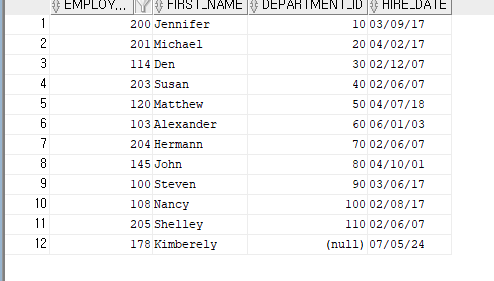

eclips sql develope 데이터 연동
package exam_jdbc;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
public class BooksInsertTest {
//입력수정삭제는 resultset이없음
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
//추후 키보드로 입력받아 데이터 저장을 위해
String title, publisher, year;
int price;
title = "오늘부터 개발자";
publisher = "천그루숲";
year = "2021";
price = 15000;
try {
conn = ConnectDatabase.makeConnection("javauser","java1234");
//Statement 사용방법
stmt = conn.createStatement();
StringBuffer sb = new StringBuffer();
sb.append("INSERT INTO Books (book_id, title, publisher, year, price) " );
sb.append("VALUES (books_seq.nextval, '" + title + "','" + publisher);
sb.append("','" + year + "',"+ price + ")");
System.out.println(sb.toString());
int insertCount = stmt.executeUpdate(sb.toString()); // 쿼리무 실행하여 적용된 행의 반환
if ( insertCount ==1) { //입력이 정상적으로 완료되면 반환값 1
System.out.println("레코드 추가 성공");
}else {
System.out.println("레코드 추가 실패");
}
}catch(SQLException e) {
System.err.println("[쿼리문 ERROR] \n" + e.getMessage());
}finally{
try {
if(stmt != null) stmt.close();
if(conn != null) conn.close();
}catch(Exception en) {
en.printStackTrace();
}
}
}
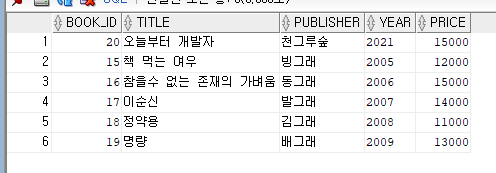
}위 예제 실행시
title, publisher ,year, price 의 값들이 sql develope 의 books 테이블에 레코드로
들어가는걸 확인 할 수 있다.
preparedStatement
Connection 객체의 prepareStatement()메소드를 사용하여 객체 생성
(쿼리문 인자 설정)
SQL문장이 미리 컴파일 되고 실행 시간동안 인수 값을 위한 공간을
호가보한다는 점에서 Statement와 다름
각각의 인수에 대해 위치홀더(?)[?또는 바인딩 변수 라함)] 를 사용하여 SQL문장을 정의할 수 있게 함
예시
PreparedStatement pstmt = null;
try{
String query = "INSERT INTO member)id, password, name)
VALUES(?,?,?)";
pstmt = conn.prepareStatement(query);
pstmt.setString(1,"javauser");
pstmt.setString(2,"java1234");
pstmt.setString(3,"홍길동");
}catch(SQLException e) {e.printStackTrace();}Prepared Statement는 SQL문의 구조는 동일하나 조건이 다른 문장을 변수 처리함으로써 항상 SQL문을 동일하게 처리할 수 있는 인터페이스이다.
SQL문 전송하게 되면 오라클은 내부적으로 PARSING →EXECUTE PLAN → FETCH 작업 을 한다.
똑같은 SQL문을 전송하면 LIBRARY CACHE에 저장된 SQL문과 비교하여 SQL문이 동일하다면 파싱한 결과와 EXECUTE PLAN을 그대로 사용하게 되며, 그 결과 또한 디스크에서 |/O로 읽어오지 않지 않고 데이터 버퍼 캐시에 저장된 메모리에서 읽어 오기 때문에 결과를 가져오는 작업 또한 빠르다고 할 수 있다.
preparedStatement로 SQL문을 처리하게 되면 LIBRARY CACHE에 저장된
작업을 재사용 함으로써 수행 속도를 좀 더 향상시킬 수 있다.
PreparedStatement사용방법
String sql = "select employee_id, first_name from employees
where employee_id = ?";
PreparedStatement pstmt = conn.prepareStatement(sql);
pstmt.setInt(1, 120);
// ?의 순번
ResultSet rs = pstmt.executeQuery();PreparedStatement는 SQL문을 작성할 때 컬럼값을 실제로 지정하지 않고, 변수 처리 함으로서
DBMS을 효율적으로 사용한다.
Preparedstatement의 SQL문은 SQL문의 구조는 같은데 조건이 수시로 변할 때 조건의 변수처리를 "?: 하는데 이를 바인딩 변수라 한다.
바인딩 변수는 반드시 컬럼명이 아닌 컬럼값이 와야 한다는 것이다. 바인딩 변수의 순서는 "?"의 개수에 의해 결정이 되는데 시작 번호는 1부터 시작하게 된다.
바인딩 변수에 값을 저장하는 메서드는 오라클의 컬럼 타입에 따라 지정해 주면 된다. PrparedStatement 인터페이스에는 바인딩 변수에 값을 저장하는 setXXX() 메서드를 제공하고있다.
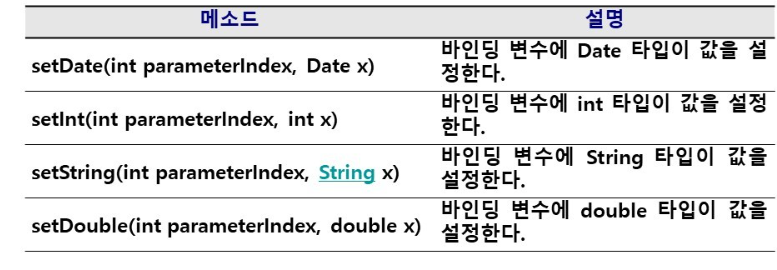
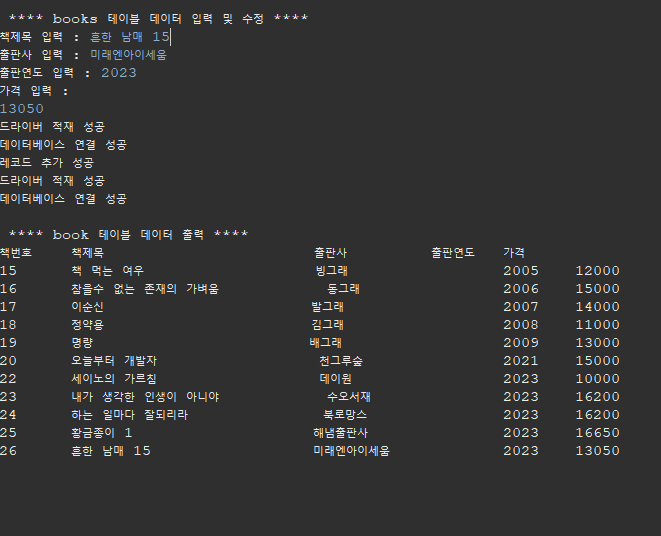
아래 코드는 사용자에게 입력받은 책 정보를 prepareStatement를 통해 레코드를 추가하고
추가한 책 정보를 콘솔에 테이블로 나타내는 코드이다.
package exam_jdbc;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Scanner;
public class PreparedStatementTest {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
String title, publisher, year;
int price;
System.out.println("\n **** books 테이블 데이터 입력 및 수정 ****");
System.out.print("책제목 입력 : ");
title = input.nextLine();
System.out.print("출판사 입력 : ");
publisher = input.nextLine();
System.out.print("출판연도 입력 : ");
year = input.nextLine();
System.out.println("가격 입력 : ");
price = input.nextInt();
addBook(title, publisher, year, price);
input.close();
readAllbook();
}
public static void addBook(String title, String publisher, String year, int price) {
Connection con = ConnectDatabase.makeConnection("javauser","java1234");
PreparedStatement pstmt = null;
try {
StringBuffer sb = new StringBuffer();
sb.append("INSERT INTO books (book_id, title, publisher, year, price) ");
sb.append("VALUES (books_seq.nextval,?,?,?,?)");
pstmt = con.prepareStatement(sb.toString());
pstmt.setString(1, title);
pstmt.setString(2, publisher);
pstmt.setString(3, year);
pstmt.setInt(4, price);
int insertCount = pstmt.executeUpdate();
if(insertCount == 1) {
System.out.println("레코드 추가 성공");
}else
System.out.println("레코드 추가 실패");
}catch (SQLException e) {
System.out.println(e.getMessage());
System.exit(0);
}finally {
try {
if(pstmt != null) { pstmt.close();}
if(con != null) {con.close();}
}catch(Exception ex) {
ex.printStackTrace();
}
}
}
private static void readAllbook() {
Connection con = ConnectDatabase.makeConnection("javauser","java1234");
PreparedStatement pstmt = null;
ResultSet rs = null;
try {
StringBuffer sb = new StringBuffer();
sb.append("select book_id, title, publisher, year, price ");
sb.append("from books order by book_id");
pstmt = con.prepareStatement(sb.toString());
rs = pstmt.executeQuery();
System.out.println("\n **** book 테이블 데이터 출력 ****");
System.out.printf("%s\t%-20s\t%6s\t%12s\t%s\n","책번호","책제목","출판사","출판연도","가격");
while(rs.next()) {
System.out.printf("%d\t", rs.getInt("book_id"));
System.out.printf("%-26s", rs.getString("title"));
System.out.printf("%-13s\t", rs.getString("publisher"));
System.out.printf("%s\t", rs.getString("year"));
System.out.printf("%d\n", rs.getInt("price"));
}
}catch (SQLException e) {
System.err.println("[쿼리문 ERROR] \n" + e.getMessage());
}finally {
try {
if(rs != null) { rs.close();}
if(pstmt != null) { pstmt.close();}
if(pstmt != null) {pstmt.close();}
}catch(Exception ex) {
ex.printStackTrace();
}
}
}
public class BookPreparedStatementTest{
public static void showMenu() {
System.out.println("선택하세요...");
System.out.println("1. 데이터 입력");
System.out.println("2. 데이터 삭제");
System.out.println("3. 데이터 검색");
System.out.println("4. 프로그램 종료");
System.out.print("선택: ");
}