지금까지는 구문들을 절차에 따라 작성하기만 했다면, 이제는 유지보수성을 증가시킬 방법에 대해 고민할 차례가 되었다.
전체 코드를 여러 파트로 나누고, 관리하는 방법에 대해 알아보자!
🌻 모듈화
1. 모듈
1) 전체 프로그램을 구성하는 코드를 여러 파트로 분리한 하나의 파츠를 의미
2) 각 모듈은 논리적 또는 기능적으로 분리되어 독립적인 일을 수행할 수 있어야 함
3) 모듈화는 경험치가 중요하기 때문에 숙련자를 통해 다양한 인사이트를 얻고 구현력을 높이는 것이 중요
4) 함수와 클래스: 프로그램의 모듈화를 위한 도구
2. 함수
▶ 함수란?
1) 일련의 과정(기능)에 이름을 붙인 것
2) 서브루틴, 프로시저와 동의어
3) 객체지향 프로그래밍에서 메소드 또한 유사한 개념
4) 장점: 같은 기능을 수행하는 구문을 중복하여 작성하지 않아도 되므로 프로그램의 모듈성을 높일 수 있음
▶ 함수의 작동
1) 함수 호출 시 함수 내부의 구문들이 모두 실행
2) 함수의 실행이 끝난 후 함수를 호출한 지점으로 돌아가 반환값을 줌
- 반환값이 없는 함수도 있다!!
3) 사용할 위치 이전에 선언해야했던 객체와 달리 함수는 사용 위치 이후에 선언해도 호출 가능
▶ 함수의 선언 (문법)
1) return-type identifier (parameter-list) { body }
int Max(int a, int b) // header
{
// body
int result = (a > b) ? a : b;
return result;
}
void Write(string message)
{
Console.WriteLine(message);
}
- 함수는 header와 body로 나눌 수 있음
- return-type: 함수를 실행한 후 반환되는 데이터의 타입
- identifier(식별자): 함수의 이름
- parameter-list: 파라미터(매개변수)로 사용할 것들의 목록
→ 매개변수 또한 객체임
→ 함수는 0개 이상의 매개변수를 가질 수 있음 - body: 헤더 이후 블록 내의 구문들
2) 함수는 헤더와 바디로 나눌 수 있음
3) 다른 선언 방식
int Max(int a, int b) => (a > b) ? a : b;- 위와 같은 형식으로 선언할 경우 => 이후의 구문을 실행하여 얻은 데이터를 반환
▶ 매개변수 (Parameter)
1) 함수의 body에서 활용하는 변수
2) 함수를 호출할 때 알맞은 매개변수를 함께 넘겨줘야 함
3) 인자: 매개변수의 초기값을 의미 (즉, 실질적인 데이터)
▶ return
1) 호출자(caller)
- 호출자란 함수를 호출하여 사용하는 주체
- Main 함수에서 특정 함수를 호출했다면, 호출된 함수의 호출자는 Main()
2) 피호출자(Calle)
- 호출자에 의해 실행된 함수
3) return
- 호출자에게 데이터(반환값)를 전달
- return-type이 void인 함수는 반환값이 없음
▶ 함수의 오버로딩 (Function Overloading)
1) 하나의 함수에서 매개변수의 개수와 타입을 다양하게 사용할 수 있도록 선언하는 방식
- 가장 기본 형식으로 함수를 선언할 시 정해진 매개변수의 갯수와 타입을 준수하여 호출하지 않는 경우 컴파일 오류 발생
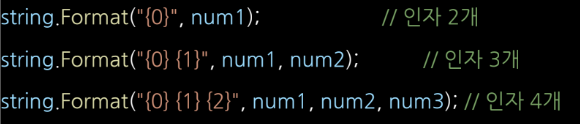
- 위와 같이 같은 함수에 필요에 따라 다양한 매개변수를 전달해도 오류없이 사용할 수 있음
2) 가변인자 (Variadic Argument)
- 개수와 타입이 변할 수 있는 매개변수
params키워드를 사용하여 매개변수가 가변인자라는 것을 알림- 몇개의 매개변수가 들어오더라도 그 크기의 배열을 생성하여 매개변수로 보냄
- 호출부에서 인자를 전달하지 않는 경우, 크기가 0인 배열이 전달
- 그 인수 배열은 일반 배열을 다루는 방식으로 사용하면 됨
▶ 스택 프레임
'어떻게 함수를 실행한 후 호출한 원래 위치로 실행 흐름이 돌아올 수 있는걸까?'
1) 함수의 동작에 필요한 모든 데이터를 저장한 공간 (Stack)
- 함수에 전달된 인자들, 반환값, body에서 사용할 객체 등
- 매개변수로 전달한 인자들도 각 인자를 다루는 레지스터, 스택에 저장해 이용하는 방식인데, 처음부터 네번째까지의 인자는 레지스터를 통해 전달하고 다섯번째 이후는 스택 메모리를 통해 전달
- 스택을 통해 인자를 저장할 때는 8byte를 사용
→ 이러한 규칙을 정해둔 것이 호출규약
2) 정적 메모리 할당 방식
- 프로그램 실행 전 컴파일 단계에서 필요한 크기만큼 메모리를 확보
- 즉, 함수가 몇 바이트의 메모리를 사용할지는 컴파일 단계에서 미리 파악 가능
- 파악한 크기만큼의 공간을 함수 호출시 스택에 미리 확보하고, 하나의 데이터 값을 저장할 때마다 확보해둔 메모리 영역의 주소를 통해 접근하여 사용
- 함수의 작동이 끝나면, 다시 그 메모리 영역을 반환 (데이터를 아예 삭제하는 것은 아님)
3) 스택 메모리 할당 방식
- BasePointer Register (rbp): 스택 메모리의 시작 주소(SP)를 저장하는 레지스터
- StackPointer Register (rsp): 스택 메모리의 끝 주소(BP)를 저장하는 레지스터
- 두가지 레지스터에 스택 메모리의 시작과 끝 주소를 저장하고, SP - BP를 통해 크기를 알 수 있음
- 예를들어 BP가 0x1234, SP가 0x1224라고 할 때 스택 프레임의 크기는 16byte
→ 스택은 메모리 주소가 감소하는 방향으로 진행하므로, 시작 주소가 더 큰 값의 주소
▶ 호출 규약
: 인수를 전달하는 규칙을 정한 것
1) 32bit 아키텍쳐를 주로 사용할 때는 호출규약이 다양했지만, 64bit 아키텍쳐를 많이 사용하게 되면서 호출규약이 통일됨
2) .Net Calling Convention
- .Net에서의 호출 규약
- 처음부터 네번째까지의 인수는 레지스터를 통해 전달, 다섯번째부터는 스택을 통해 전달
- 스택에 인수를 전달할 때는 8byte를 사용
- 정적 할당 후 레지스터에 저장된 인자를 스택으로 옮김
- 스택 메모리에 저장되어있던 인자는 주소 계산을 통해 가져옴
- 결과 데이터(반환값)는 EAX와 ECX 레지스터를 사용해 가져옴
🌻 객체의 속성
1. 범위 (Scope)
1) 지역변수
: 유효한 영역(블록) 내에서만 사용할 수 있는 변수
- 객체는 선언된 블록 내에서만 유효함
do
{
int i = 20;
} while(i = 20);
// 오류 -> { } 내에서만 유효하기 때문에 i를 조건으로 사용하려면 블록 밖에 선언해줘야 함2) 전역변수
: 어디서든 사용할 수 있는 변수
2. 수명 (Life Time)
: 객체가 유효한 시간
1) 지역변수의 수명
- 지역변수는 범위를 벗어나면 유효하지 않음
- 따라서 유효한 범위까지가 지역변수의 수명
3. 인자 전달 방식
▶ Call By Value
1) 인자 값의 복사본을 전달하는 방식
2) 원본에 영향을 주지 않음
3) 어떠한 키워드 등을 붙이지 않았을 때 기본적인 전달 방식은 Call By Value
// 값타입을 Call By Value 방식으로 전달한 예시
// 얕은 복사, 깊은 복사 개념이 적용되지 않는다
static void Main()
{
int num = 10;
Foo(num);
void Foo(int x) // num의 데이터 10으로 int x를 초기화
{
x = 20; // 원본 num에 영향 미치지 않음
}
}// 참조타입을 Call By Value 방식으로 전달한 예시
// 얕은 복사가 일어난다
int[] arr = {1, 2, 3};
Boo(arr);
void Boo(int[] x) // arr에 저장된 실질적인 데이터인 [0]의 주소가 복사되어 전달
{
x[0] = 10; // 참조 타입은 주소가 전달되므로 원본 배열의 값에 영향을 미침
// [0]의 주소가 복사되어 전달되고, 배열의 작동 방식은 그 저장된 주소로부터
// 몇칸이 떨어졌는지 확인하여 접근하기 때문에 실제 원본의 값이 변경되는 것
}▶ Call By Reference
1) 인자가 저장된 객체의 주소를 전달하는 방식
2) 주소를 통해 메모리 영역에 바로 접근할 수 있기에, 원본에 영향을 줄 수 있음
3) ref 키워드를 이용하여 인자의 주소값을 전달함을 명시
int num = 10;
Foo(num);
void Foo(ref int x)
{
x = 20; // ref를 이용해 주소를 전달했으므로, 원본인 num의 값이 변경됨
}4) in 키워드
- 읽기 전용으로 주소를 전달하는 방식
- Call By Reference 방식이지만, 함수 내에서 전달된 주소에 저장된 데이터(인자)에대한 변경이 불가능함을 명시적으로 나타냄
- 전달된 주소에 저장된 데이터(인자)를 변경하려할 경우 컴파일 오류 발생
- in을 통해 전달하는 변수는 반드시 초기화되어 있어야 함
5) out 키워드
- 함수는 기본적으로 0개 혹은 하나의 값을 반환할 수 있음
- 하지만 의도에따라 두가지 이상의 반환값이 필요할 때 out 키워드를 이용
- Call By Reference이되 함수에서 반환값 외에도 추가 데이터를 반환함을 명시적으로 나타냄
string CreateHuman(out int age) // 무조건적으로 반환할 데이터가 이거라는 걸 알리는 용도??
{
// 이름을 string으로 반환하고
// 나이를 int로 반환하고싶음
age = 35; // 이렇게 값을 넣어주지 않으면 함수 선언 자체에 컴파일 오류 발생
return "이름";
}
int hisAge;
string hisName = CreageHuman(out hisAge);
Console.WriteLine($"그의 이름은 {hisName}이며, 그의 나이는 {hisAge}입니다.");6) in과 out을 이용해 코드의 의도를 명확하게 표현할 수 있으며, 이에 대해 제대로 처리하지 않으면 컴파일 오류가 발생하기에 실수를 예방할 수 있음
struct Something // 이 타입의 객체는 160 바이트
{
public int[] Numbers = new int[40];
public Something() { }
}
Something Sum2(Something a, Something b)
{
return a + b;
}
// 160바이트짜리 메모리를 두개 전달하려 함
// 레지스터의 크기는 8byte이기 때문에 불가
// ref로 주소를 전달하면 160byte의 데이터를 복사하여 레지스터에 저장할 필요 없기 때문에 가능
Something Sum2(ref Something a, ref Something b)
{
return a + b;
}
// good
// 근데 만약 의도치 않은 기능이 있다면?
Something Sum2(ref Something a, ref Something b)
{
a = new Something();
return a + b;
}
// 단순히 두 값을 더하는 의도로 사용하려했는데, 실수로 body의 첫줄과 같은 코드가 들어가는 경우
// a의 실제 값이 변경되기 때문에 의도와 다른 동작이 실행됨 (컴파일 오류가 안나서 발견하기 어려움)
Something Sume2(in Something a, ref Something b)
{
a = new Something(); // a는 in을 통해 수정이 불가하다고 명시했기 때문에 컴파일 오류 발생
return a + b;
}
// 이와 같이 in 키워드를 사용하면, 위와 같은 상황에 대해 컴파일 오류가 발생하기 때문에
// 값의 변경이 없다는 의도를 명확히하면서 실수를 방지할 수 있고
// 160byte 자체를 복사하지 않아도 되는 call by reference의 효과도 얻을 수 있음