
1. EDA란?
(1) EDA의 정의
EDA (Exploratory Data Analysis)는 탐색적 데이터 분석으로, 데이터를 다양한 각도에서 관찰하며 데이터를 이해하는 과정을 의미한다.
(2) EDA의 필요성
EDA가 필요한 이유는 다음과 같다.
- 데이터의 잠재적인 문제 발견
- 데이터의 패턴 발견
- 자료수집/추가자료수집을 위한 기반
- 통계 도구 결정을 위한 데이터 파악
(3) EDA의 대상
- 일변량 (Univariate): EDA를 통해 파악하려는 변수가 1개인 경우
- 목적: 데이터를 설명하고 패턴 찾기 - 다변량 (Multi-variate): EDA를 통해 파악하려는 변수가 여러개인 경우
- 목적: 변수들 간의 관계 파악
(4) EDA의 종류
- 시각화 (Graphic): 차트나 그림 등을 이용하여 데이터를 확인하는 방법
- 비시각화 (Non-Graphic): 주로 summary statistics로 데이터를 확인하는 방법
(5) EDA의 유형
- 일변량 비시각화 (Uni-Non Graphic)
- 일변량 비시각화 (Uni-Non Graphic)
- 다변량 비시각화 (Muti-Non Graphic)
- 다변량 시각화 (Muti-Graphic)
(6) EDA의 단계
🔹전체적인 데이터 분석
- 분석의 목적에 맞는 변수가 무엇인지 확인
- 데이터형 확인
- 데이터의 오류/누락 확인
🔹데이터의 개별 속성값 확인
- 개별 데이터를 관찰하여 전체적인 추세와 특이사항 관찰
- 개별 속성에 어떤 통계 지표가 적절한지 결정
🔹속성 간 관계 분석
- 시각화를 통해 속성 간 관계 분석
- 상관계수를 통한 상관관계 파악
2. EDA 연습
(1) 데이터 불러오기
EDA 실습을 위해 https://github.com/CSSEGISandData/COVID-19 에서 코로나 바이러스 데이터를 다운로드 받았다. 이중, 2020/3/31의 데이터를 활용할 예정이다.
import pandas as pd doc = pd.read_csv("03-31-2020.csv",encoding='utf-8-sig')
- 데이터를 읽어오는 과정에서 에러가 발생하는 경우
에러가 나는 데이터가 존재할 경우, error_bad_lines=False로 생략하는 것이 일반적이다
import pandas as pd doc = pd.read_csv("파일명", encoding='utf-8-sig', error_bad_lines=False)
- 특정 sheet의 데이터를 읽는 방법
pandas는 가장 앞 sheet의 데이터를 읽는다.
특정 sheet를 읽기 위한 방법은 다음과 같다.
pd.read_excel(파일명, sheet_name=sheet명)
(2) 전체적인 데이터 분석
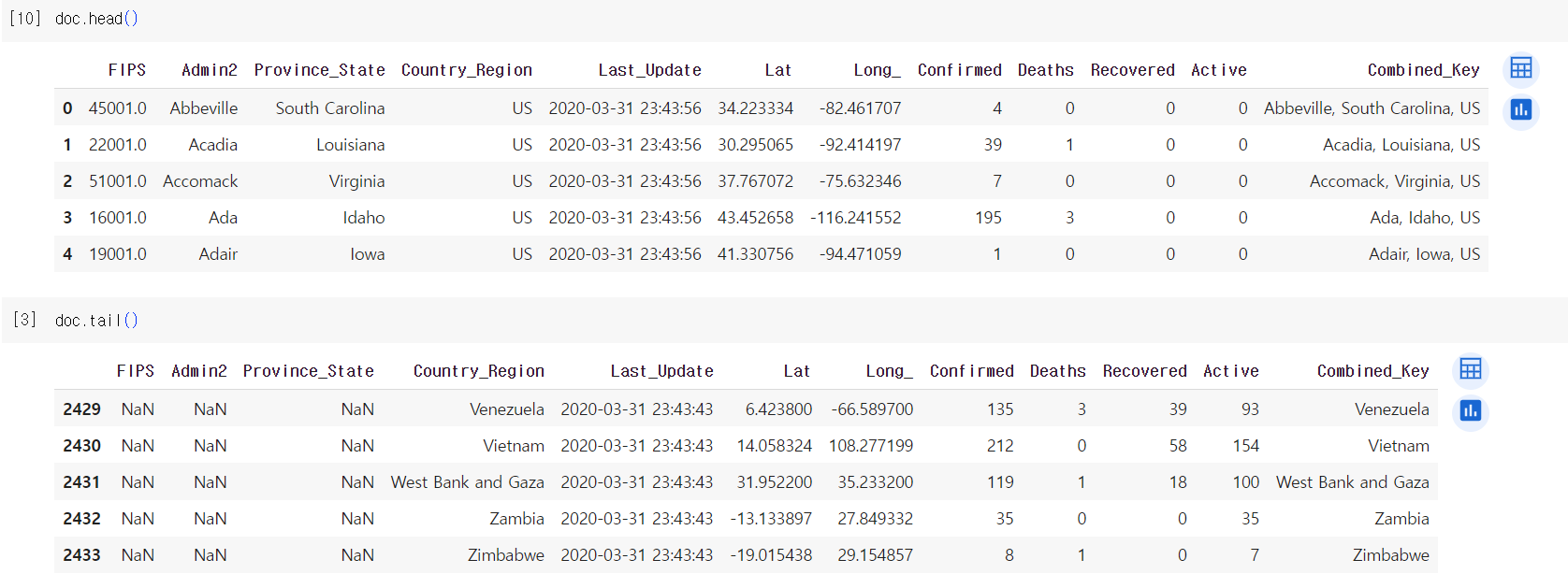
1) 데이터 일부 확인하기 (head, tail)
head(), tail()을 사용하여 가장 앞,뒤의 데이터를 5개 읽을 수 있다.
이런 과정을 거치는 이유는 데이터의 오류나 누락이 없는지 확인하기 위해서이다.
doc.head()
doc.tail()
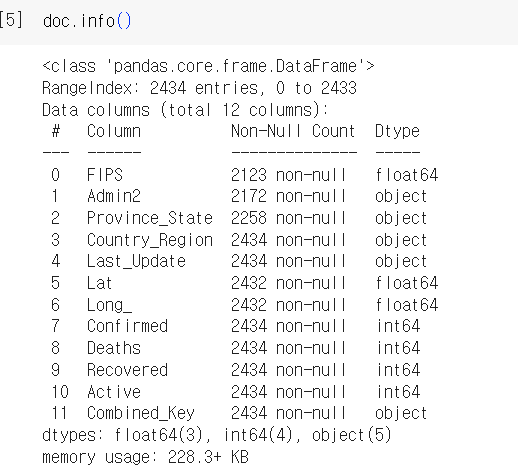
2) 데이터 정보 확인하기 (shape, info)
- shape를 통해 row,column 사이즈를 확인할 수 있다.
doc.shape

- info를 통해 컬럼별 데이터 타입과 실제 데이터 사이즈를 확인할 수 있다.
doc.info()
(3) 데이터의 개별 속성값 확인하기
1) 컬럼 이해하기 (columns)
doc.columns

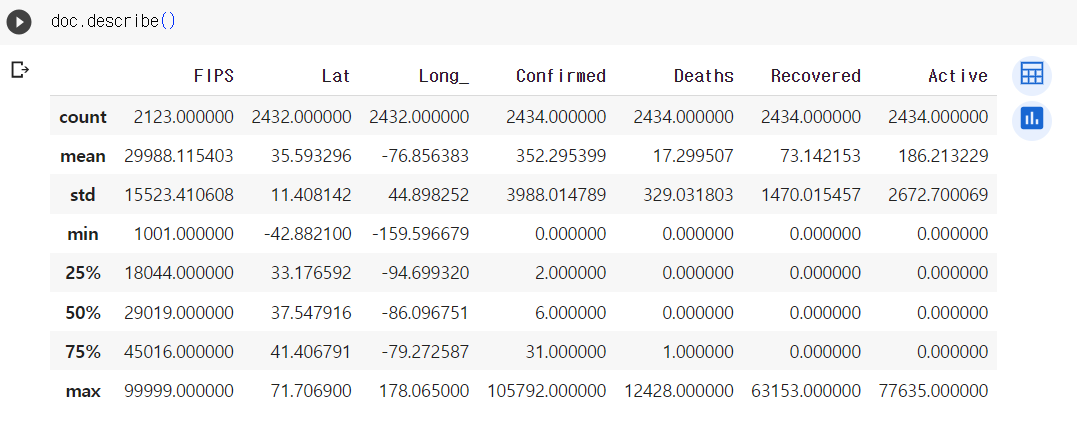
2) describe
속성이 숫자라면 describe을 통해 평균, 표준편차, 4분위수, 최대값, 최소값을 확인할 수 있다.
doc.describe()
(4) 속성 간 관계 분석
속성 간 상관관계는 corr을 통해 확인할 수 있다. 이때 디폴트는 피어슨 상관계수이다. 피어슨 상관계수는 선형 상관 관계를 조사하며,
- +1에 가까울수록 양의 선형 관계
- -1에 가까울수록 음의 선형 관계
- 0에 가까울수록 상관관계가 없음을 의미한다.
최신 pandas에서는 corr()이 자동으로 문자컬럼을 제외해주지 않기 때문에 numeric_only=True를 추가해야 한다.
doc.corr(numeric_only=True)
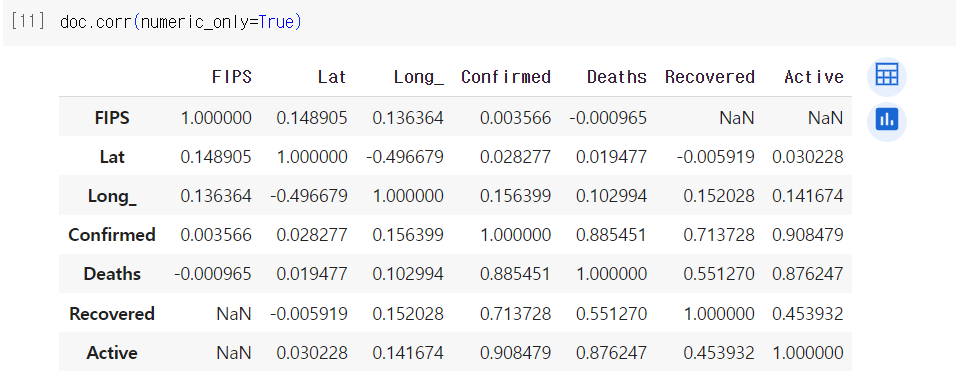
위의 결과를 통해 confirmed, deaths, recovered, active 간의 상관관계가 유의미하다는 것을 확인할 수 있다.
데이터를 시각화하면 이러한 상관관계를 더 가시적으로 확인할 수 있다.
(5) 데이터 시각화
데이터 시각화를 위해 기존에는 matplotlib, seaborn을 주로 사용했다. 하지만 최근에는 plotly를 주로 사용하는 추세이다. 코드에 대한 설명은 다음과 같다.
- %matplotlib inline: 주피터 노트북 상에서 그래프를 표현하기 위해 특별한 명령을 해주어야 함
- data=테이블형: 데이터셋(데이터프레임)
- annot=True: 박스 안에 값 표시
- fmt='0.2f': 박스 안에 표시될 값의 표시 형식 설정 (0.2f 는 소숫점 두자릿수를 의미함)
- linewidths=0.5: 박스와 박스 사이의 간격 설정
- cmap='Blues': 색상 선택
%matplotlib inline import matplotlib.pyplot as plt import seaborn as sns plt.figure(figsize=(5,5)) sns.heatmap(data = doc.corr(), annot=True, fmt = '.2f', linewidths=0.5, cmap='Blues')

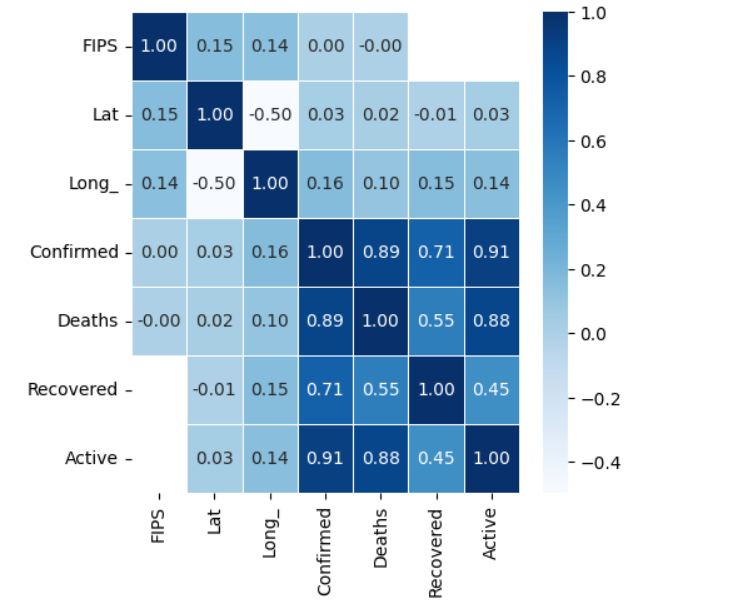
이를 통해 예상과 같이 confirmed, deaths, recovered, active 간의 상관관계가 유의미하다는 것을 확인할 수 있다.
