join
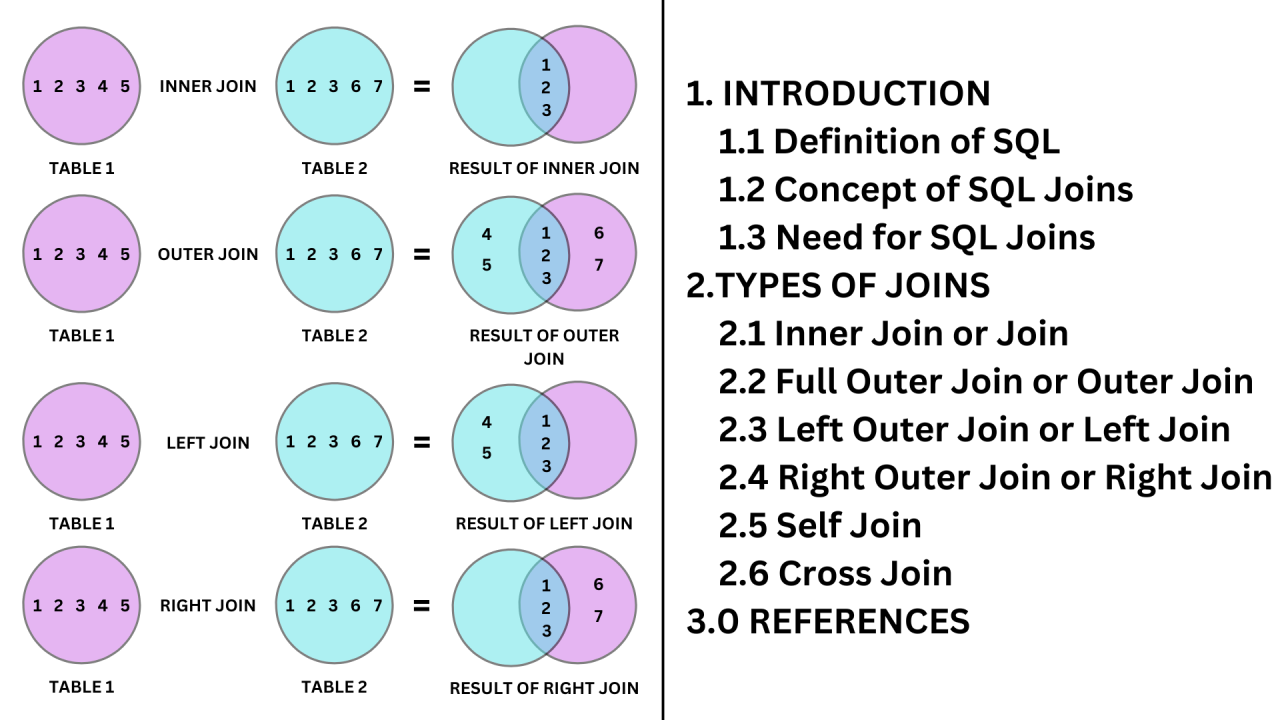
SQL문 연습2
# 현재 세션에서 `ONLY_FULL_GROUP_BY` 모드 끄기
SET SESSION sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
SET sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
# a6 DB 삭제/생성/선택
DROP DATABASE IF EXISTS a6;
CREATE DATABASE a6;
USE a6;
# 부서(홍보, 기획)
CREATE TABLE dept (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT null
);
INSERT INTO dept SET name = '홍보';
INSERT INTO dept SET name = '기획';
SELECT * FROM dept;
# 사원(홍길동/홍보/5000만원, 홍길순/홍보/6000만원, 임꺽정/기획/4000만원)
CREATE TABLE USER (
userId int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL,
deptId int UNSIGNED NOT NULL,
salary int UNSIGNED NOT NULL,
regDate datetime NOT null DEFAULT now()
);
INSERT INTO USER SET name = "홍길동", deptId = 1, salary = 5000;
INSERT INTO USER SET name = "홍길순", deptId = 1, salary = 6000;
INSERT INTO USER SET name = "임꺽정", deptId = 2, salary = 4000;
SELECT * FROM USER;
# 사원 수 출력
SELECT count(*) AS '사원수' FROM USER;
# 가장 큰 사원 번호 출력
SELECT max(userId) AS '가장 큰 사원 번호' FROM USER;
# 가장 고액 연봉
SELECT max(salary) AS '가장 고액 연봉' FROM USER;
# 가장 저액 연봉
SELECT min(salary) AS '가장 저액 연봉' FROM USER;
# 회사에서 1년 고정 지출(인건비)
SELECT sum(salary) AS '1년 고정 지출(인건비)' FROM USER;
# 부서별, 1년 고정 지출(인건비)
SELECT dept.name AS '부서', sum(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 최고연봉
SELECT dept.name AS '부서', max(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 최저연봉
SELECT dept.name AS '부서', min(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 평균연봉
SELECT dept.name AS '부서', avg(salary) AS '평균(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 부서명, 사원리스트, 평균연봉, 최고연봉, 최소연봉, 사원수
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId;
## V3(V2에서 평균연봉이 5000이상인 부서로 추리기)
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
HAVING `평균연봉` > 5000;
## V4(V3에서 HAVING 없이 서브쿼리로 수행)
### HINT, UNION을 이용한 서브쿼리
# SELECT *
# FROM (
# SELECT 1 AS id
# UNION
# SELECT 2
# UNION
# SELECT 3
# ) AS A
SELECT * FROM (
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
) AS D WHERE D.`평균연봉` >= 5000;
SELECT D.name AS '부서', U.name AS '이름', max(U.salary) AS '연봉', U.regDate AS '입사일' FROM `user` AS U JOIN dept AS D ON D.id = U.deptId, GROUP BY deptId;
SELECT `부서명`, U.name, `최고연봉`, U.regDate AS '입사일' FROM (
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
) AS D
INNER JOIN `user` AS U
WHERE U.salary = D.`최고연봉`;
# 1단계 : 각 부서별 최고연봉자의 연봉을 구한다.
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId;
# 2단계 : 사원테이블과 부서테이블(서브쿼리)을 조인한다.
SELECT D.* FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user`;
# 3단계 : 사원테이블과 부서테이블(서브쿼리)을 조인할 때 사원의 연봉과 부서의 최고연봉이 일치해야한 다는 조건을 추가해서, 최고연봉자가 아닌 사람들이 자연스럽게 필터링 되도록 한다.
SELECT D.id AS '부서번호', U.name AS '사원명', D.maxSalary AS '연봉' FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user` AS U
WHERE U.salary = D.maxSalary;
# 4단계 : 추가 JOIN 을 통해서 부서명을 얻는다.
SELECT DD.name AS '부서명', U.name AS '사원명', D.maxSalary AS '연봉' FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user` AS U
INNER JOIN dept AS DD
ON DD.id = U.deptId
WHERE U.salary = D.maxSalary;
# a6 DB 삭제/생성/선택
DROP DATABASE IF EXISTS a6;
CREATE DATABASE a6;
USE a6;
# 부서(홍보, 기획, IT)
CREATE TABLE dept (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL
);
INSERT INTO dept SET name = "홍보";
INSERT INTO dept SET name = "기획";
INSERT INTO dept SET name = "IT";
SELECT * FROM dept;
# 사원(홍길동/홍보/5000만원, 홍길순/홍보/6000만원, 임꺽정/기획/4000만원)
## IT부서는 아직 사원이 없음
CREATE TABLE emp (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL,
deptId int UNSIGNED NOT NULL,
salary int UNSIGNED NOT NULL,
regDate datetime NOT NULL DEFAULT now()
);
INSERT INTO emp SET name = "홍길동", deptId = 1, salary = 5000;
INSERT INTO emp SET name = "홍길순", deptId = 1, salary = 6000;
INSERT INTO emp SET name = "임꺽정", deptId = 2, salary = 4000;
select * from emp;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력(IT 부서는 안나옴)
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력(IT 부서가 아직 사원이 없더라도, 1줄이라도 나오도록 해주세요, LEFT JOIN 필요)
## IT부서는 [IT, NULL, NULL] 으로 출력
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id;
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM emp AS E
RIGHT JOIN dept AS D
ON E.deptId = D.id;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력
## IT부서는 [IT, 0, -] 으로 출력
SELECT
D.name AS '부서명',
IfNULL(E.id, 0) AS '사원번호',
E.name AS '사원명'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id;
# 모든 부서별, 최고연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(max(E.salary), 0) AS '최고연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 모든 부서별, 최저연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(min(E.salary), 0) AS '최저연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 모든 부서별, 평균연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(avg(E.salary), 0) AS '평균연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 하나의 쿼리로 최고연봉자와 최저역연봉자의 이름과 연봉
SELECT
E.name AS '이름',
S.`최고연봉` AS '최고연봉',
S2.`이름` AS '이름',
S2.`최저연봉` AS '최저연봉'
FROM (
SELECT
max(salary) AS '최고연봉',
min(salary) AS '최저연봉'
FROM emp
) AS S
INNER JOIN emp AS E
INNER JOIN (
SELECT
E.name AS '이름',
S.`최저연봉` AS '최저연봉'
FROM (
SELECT
max(salary) AS '최고연봉',
min(salary) AS '최저연봉'
FROM emp
) AS S
INNER JOIN emp AS E
WHERE S.`최저연봉` = E.salary
) AS S2
WHERE S.`최고연봉` = E.salary;
# 현재 세션에서 `ONLY_FULL_GROUP_BY` 모드 끄기
## 영구적으로 설정되는 것은 아닙니다.
SET SESSION sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
SET sql_mode = (SELECT REPLACE(@@sql_mode, 'ONLY_FULL_GROUP_BY', ''));
# a6 DB 삭제/생성/선택
DROP DATABASE IF EXISTS a6;
CREATE DATABASE a6;
USE a6;
# 부서(홍보, 기획)
CREATE TABLE dept (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT null
);
INSERT INTO dept SET name = '홍보';
INSERT INTO dept SET name = '기획';
SELECT * FROM dept;
# 사원(홍길동/홍보/5000만원, 홍길순/홍보/6000만원, 임꺽정/기획/4000만원)
CREATE TABLE USER (
userId int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL,
deptId int UNSIGNED NOT NULL,
salary int UNSIGNED NOT NULL,
regDate datetime NOT null DEFAULT now()
);
INSERT INTO USER SET name = "홍길동", deptId = 1, salary = 5000;
INSERT INTO USER SET name = "홍길순", deptId = 1, salary = 6000;
INSERT INTO USER SET name = "임꺽정", deptId = 2, salary = 4000;
SELECT * FROM USER;
# 사원 수 출력
SELECT count(*) AS '사원수' FROM USER;
# 가장 큰 사원 번호 출력
SELECT max(userId) AS '가장 큰 사원 번호' FROM USER;
# 가장 고액 연봉
SELECT max(salary) AS '가장 고액 연봉' FROM USER;
# 가장 저액 연봉
SELECT min(salary) AS '가장 저액 연봉' FROM USER;
# 회사에서 1년 고정 지출(인건비)
SELECT sum(salary) AS '1년 고정 지출(인건비)' FROM USER;
# 부서별, 1년 고정 지출(인건비)
SELECT dept.name AS '부서', sum(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 최고연봉
SELECT dept.name AS '부서', max(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 최저연봉
SELECT dept.name AS '부서', min(salary) AS '1년 고정 지출(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 평균연봉
SELECT dept.name AS '부서', avg(salary) AS '평균(인건비)' FROM USER INNER JOIN dept ON USER.deptId = dept.id GROUP BY deptId;
# 부서별, 부서명, 사원리스트, 평균연봉, 최고연봉, 최소연봉, 사원수
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId;
## V3(V2에서 평균연봉이 5000이상인 부서로 추리기)
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
HAVING `평균연봉` > 5000;
## V4(V3에서 HAVING 없이 서브쿼리로 수행)
### HINT, UNION을 이용한 서브쿼리
# SELECT *
# FROM (
# SELECT 1 AS id
# UNION
# SELECT 2
# UNION
# SELECT 3
# ) AS A
SELECT * FROM (
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
) AS D WHERE D.`평균연봉` >= 5000;
SELECT D.name AS '부서', U.name AS '이름', max(U.salary) AS '연봉', U.regDate AS '입사일' FROM `user` AS U JOIN dept AS D ON D.id = U.deptId, GROUP BY deptId;
SELECT `부서명`, U.name, `최고연봉`, U.regDate AS '입사일' FROM (
SELECT
D.name AS '부서명',
GROUP_CONCAT(U.name) AS '사원리스트',
TRUNCATE(avg(U.salary),0) AS '평균연봉',
max(U.salary) AS '최고연봉',
min(U.salary) AS '최소연봉',
count(*) AS '사원수'
FROM `user` AS U
INNER JOIN dept AS D
ON U.deptId = D.id
GROUP BY deptId
) AS D
INNER JOIN `user` AS U
WHERE U.salary = D.`최고연봉`;
# 1단계 : 각 부서별 최고연봉자의 연봉을 구한다.
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId;
# 2단계 : 사원테이블과 부서테이블(서브쿼리)을 조인한다.
SELECT D.* FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user`;
# 3단계 : 사원테이블과 부서테이블(서브쿼리)을 조인할 때 사원의 연봉과 부서의 최고연봉이 일치해야한 다는 조건을 추가해서, 최고연봉자가 아닌 사람들이 자연스럽게 필터링 되도록 한다.
SELECT D.id AS '부서번호', U.name AS '사원명', D.maxSalary AS '연봉' FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user` AS U
WHERE U.salary = D.maxSalary;
# 4단계 : 추가 JOIN 을 통해서 부서명을 얻는다.
SELECT DD.name AS '부서명', U.name AS '사원명', D.maxSalary AS '연봉' FROM (
SELECT
U.deptId AS id,
max(U.salary) AS maxSalary
FROM `user` AS U
GROUP BY U.deptId
) AS D
INNER JOIN `user` AS U
INNER JOIN dept AS DD
ON DD.id = U.deptId
WHERE U.salary = D.maxSalary;
# a6 DB 삭제/생성/선택
DROP DATABASE IF EXISTS a6;
CREATE DATABASE a6;
USE a6;
# 부서(홍보, 기획, IT)
CREATE TABLE dept (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL
);
INSERT INTO dept SET name = "홍보";
INSERT INTO dept SET name = "기획";
INSERT INTO dept SET name = "IT";
SELECT * FROM dept;
# 사원(홍길동/홍보/5000만원, 홍길순/홍보/6000만원, 임꺽정/기획/4000만원)
## IT부서는 아직 사원이 없음
CREATE TABLE emp (
id int UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name varchar(50) NOT NULL,
deptId int UNSIGNED NOT NULL,
salary int UNSIGNED NOT NULL,
regDate datetime NOT NULL DEFAULT now()
);
INSERT INTO emp SET name = "홍길동", deptId = 1, salary = 5000;
INSERT INTO emp SET name = "홍길순", deptId = 1, salary = 6000;
INSERT INTO emp SET name = "임꺽정", deptId = 2, salary = 4000;
select * from emp;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력(IT 부서는 안나옴)
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM emp AS E
INNER JOIN dept AS D
ON E.deptId = D.id;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력(IT 부서가 아직 사원이 없더라도, 1줄이라도 나오도록 해주세요, LEFT JOIN 필요)
## IT부서는 [IT, NULL, NULL] 으로 출력
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id;
SELECT
D.name AS '부서명',
E.id AS '사원번호',
E.name AS '사원명'
FROM emp AS E
RIGHT JOIN dept AS D
ON E.deptId = D.id;
# 전 사원에 대하여, [부서명, 사원번호, 사원명] 양식으로 출력
## IT부서는 [IT, 0, -] 으로 출력
SELECT
D.name AS '부서명',
IfNULL(E.id, 0) AS '사원번호',
E.name AS '사원명'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id;
# 모든 부서별, 최고연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(max(E.salary), 0) AS '최고연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 모든 부서별, 최저연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(min(E.salary), 0) AS '최저연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 모든 부서별, 평균연봉, IT부서는 0원으로 표시
SELECT
D.name AS '부서명',
IFNULL(avg(E.salary), 0) AS '평균연봉'
FROM dept AS D
LEFT JOIN emp AS E
ON E.deptId = D.id
GROUP BY D.name;
# 하나의 쿼리로 최고연봉자와 최저역연봉자의 이름과 연봉
SELECT
E.name AS '이름',
S.`최고연봉` AS '최고연봉',
S2.`이름` AS '이름',
S2.`최저연봉` AS '최저연봉'
FROM (
SELECT
max(salary) AS '최고연봉',
min(salary) AS '최저연봉'
FROM emp
) AS S
INNER JOIN emp AS E
INNER JOIN (
SELECT
E.name AS '이름',
S.`최저연봉` AS '최저연봉'
FROM (
SELECT
max(salary) AS '최고연봉',
min(salary) AS '최저연봉'
FROM emp
) AS S
INNER JOIN emp AS E
WHERE S.`최저연봉` = E.salary
) AS S2
WHERE S.`최고연봉` = E.salary;

https://develop-chick.tistory.com/ 첫번째 블로그