JDBC 사용하기
JdbcTemplate 설정
jdbc template의 설정은 간단하다. Spring에서 DB를 사용하기 위해 만들었었던 DataSource Bean을 생성해주고, 생성한 DataSource를 파라미터로 하는 jdbcTemplate을 생성하는 생성자를 호출하면 된다.
@Configuration
public JdbcTemplateConfig {
@Bean
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setUsername("testsuer");
dataSource.setPassword("testuserpwd");
dataSource.setDriverClassName("org.mariadb.jdbc.Driver");
dataSource.setUrl("jdbc:mariadb://localhost:3306/test_db");
return dataSource;
}
@Bean
public JdbcTemplate jdbcTemplate(){
return new JdbcTemplate(dataSource());
}
}JdbcTemplate 사용
사용은 간단하다. JdbcTemplate의 빈을 주입받을 변수를 만들고 @AutoWired등을 이용해 Bean을 주입하면 된다.
아래의 코드는 JdbcTemplate을 이용한 간단한 예제 코드이다.
@Repository
@RequiredArgsConstructor
public BoardRepository {
static RowMapper<Board> boardRowMapper = (rs, rowNum) -> Board.builder()
.id(rs.getLong("id"))
.title(rs.getString("title"))
.content(rs.getString("content"))
.createdAt(LocalDate.parse(rs.getString("created_at")))
.build();
private final JdbcTemplate jdbcTemplate;
public List<Board> findAllBoards(){
}
public Board findBoardById(Long id){
return jdbcTemplate.query("", boardRowMapper);
}
}여기서 특이한 것은, JPA나 Connection 등을 사용할 때는 볼 수 없던, RowMapper<Object>의 존재이다. 하지만, 자세히 본다면 어떠한 기능을 하는지 쉽게 알 수 있다.
RowMapper<Object>는 쿼리의 결과물로 나온 결과 row를 객체로 매핑하는 함수이다.
테스트
Datasource Bean 설정
Database와 JdbcTemplate을 이용하기 위해 Datasource, JdbcTemplate 빈을 설정해준다.
@Configuration
public class Config{
@Bean
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setDriverClassName("org.mariadb.jdbc.Driver");
dataSource.setUrl("jdbc:mariadb://localhost:3306/test_db");
return dataSource;
}
@Bean
public JdbcTemplate jdbcTemplate() {
return new JdbcTemplate(dataSource());
}
}user 클래스 작성
// User.class
@Builder
public class User {
private Long id;
private String uid;
private String name;
private LocalDate createdAt;
}Repository 클래스 작성
@Repository
public class UserRepository{
static RowMapper<User> userRowMapper = (rs, rowNum) ->
User.builder()
.id(rs.getLong("id"))
.uid(rs.getString("uid"))
.name(rs.getString("name"))
.createdAt(LocalDate.parse(rs.getString("created_at")))
.build();
@Autowired
private JdbcTemplate template;
public List<User> getAllUser() {
return template.query("SELECT * FROM user", userRowMapper);
}
public User getOneUserById(Long id) {
return template.queryForObject("select * from user where id=" + id, userRowMapper);
}
public void saveUser(User user) {
template.execute("insert into user value (
" + user.getId() +
",'" + user.getUid() + "'" +
",'" + user.getName() + "'" +
",'" + user.getCreatedAt().toString() + "')");
}
}테스트 코드 작성
@SpringBootTest
public class JDBCTemplateTest{
@Autowired
UserRepository repository;
private User insertUser, insertUser2, insertUser3;
@BeforeEach
public void init() {
insertUser = User.builder()
.id(1L)
.uid("first")
.name("first_name")
.createdAt(LocalDate.now())
.build();
insertUser2 = User.builder()
.id(2L)
.uid("second")
.name("second_name")
.createdAt(LocalDate.now().minusMonths(2))
.build();
insertUser3 = User.builder()
.id(3L)
.uid("third")
.name("third_name")
.createdAt(LocalDate.now().minusMonths(3))
.build();
}
@Test
public void userSave() {
repository.saveUser(user1);
}
@Test
public void findUserById() {
User user = repository.getOneUserById(1L);
System.out.println(user.toString());
assertThat(user).isEqualTo(user1);
}
@Test
public void findAllUsers() {
System.out.println(repository.getAllUser());
}
}테스트 결과
findUserById()
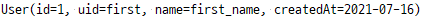
findAllUsers()

userSave()
위의 findAllUsers()메서드 결과에서, DB의 입력으로 넣었던 User 객체가 모두 프린트 된걸로 보아, 유저의 정보를 저장하는 메서드인 userSave()메서드 또한 잘 작동했음을 알 수 있다.
마무리
기존 JPA를 이용하여 손쉽게 데이터를 저장하였을 때와는 다르게 조회, 저장, 수정 삭제등 모든 쿼리를 손으로 짜야하는데다가 직접 매핑까지 해주어야 하기 때문에 쉽게 접근하기는 어려울 것 같다.
하지만, JPA가 자체적으로 생성하는 쿼리는 최적화가 잘 안되어 있을 뿐 아니라, 성능 측면에서도 튜닝된 쿼리와 비교하였을때 큰 차이가 난다고 한다. 이러한 이유에서라도 직접 쿼리를 작성하고 사용해보는 버릇을 들이는 것도 좋을 것 같다.

Configuration 부분 코드에서 궁금한 점이 있습니다.
bean 에 등록되는 DataSource instance와 JdbcTemplate에 사용되는 DataSource instance가 서로 다른 것 같습니다. 그래서 문제가 생기지 않을까 궁금합니다.