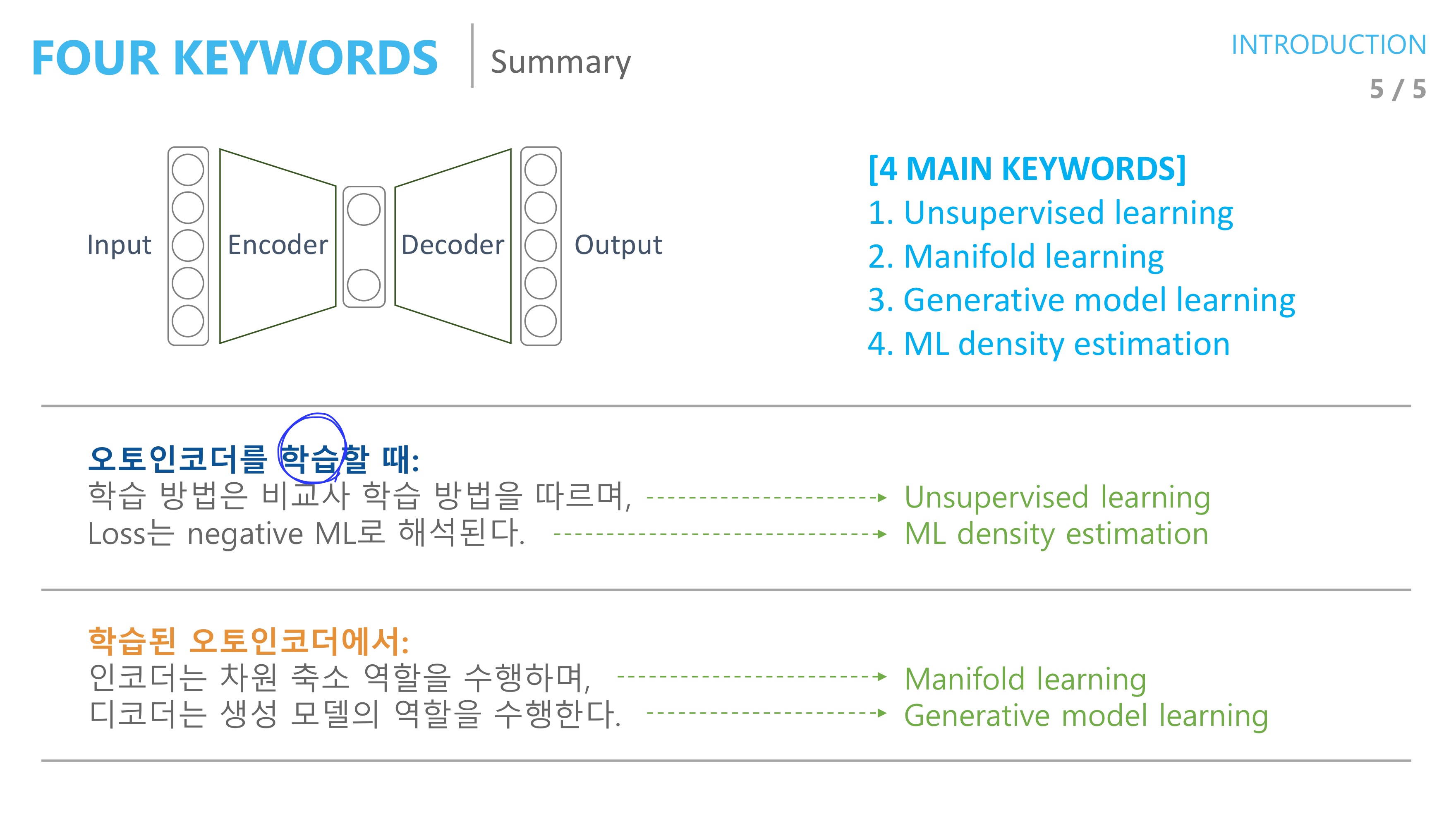
Autoencoder에는 크게 4가지 keyword 가 있으며 각각
1. Unsupervised learning
2. Mainfold learning
3. Generative model learning
4. ML density estimation
먼저 input 이 x일 때 output도 x이길 기대하기 때문에 unsupervised 방식이고 딥러닝의 흐름 중에 loss function을 Maximum likelihood 관점 즉 확률 분포라는 가정에서 바라보기 때문에 ML density estimaiton 방식이 존재한다
또한 기본적인 구조에서 encoder와 decoder 각각이 차원 축소 역할과 생성 역할을 하기 때문에 Manifold learning, Generative model learning 이기도 하다
Autoencoder가 가장 많이 사용되는 분야는 Manifold learning이다
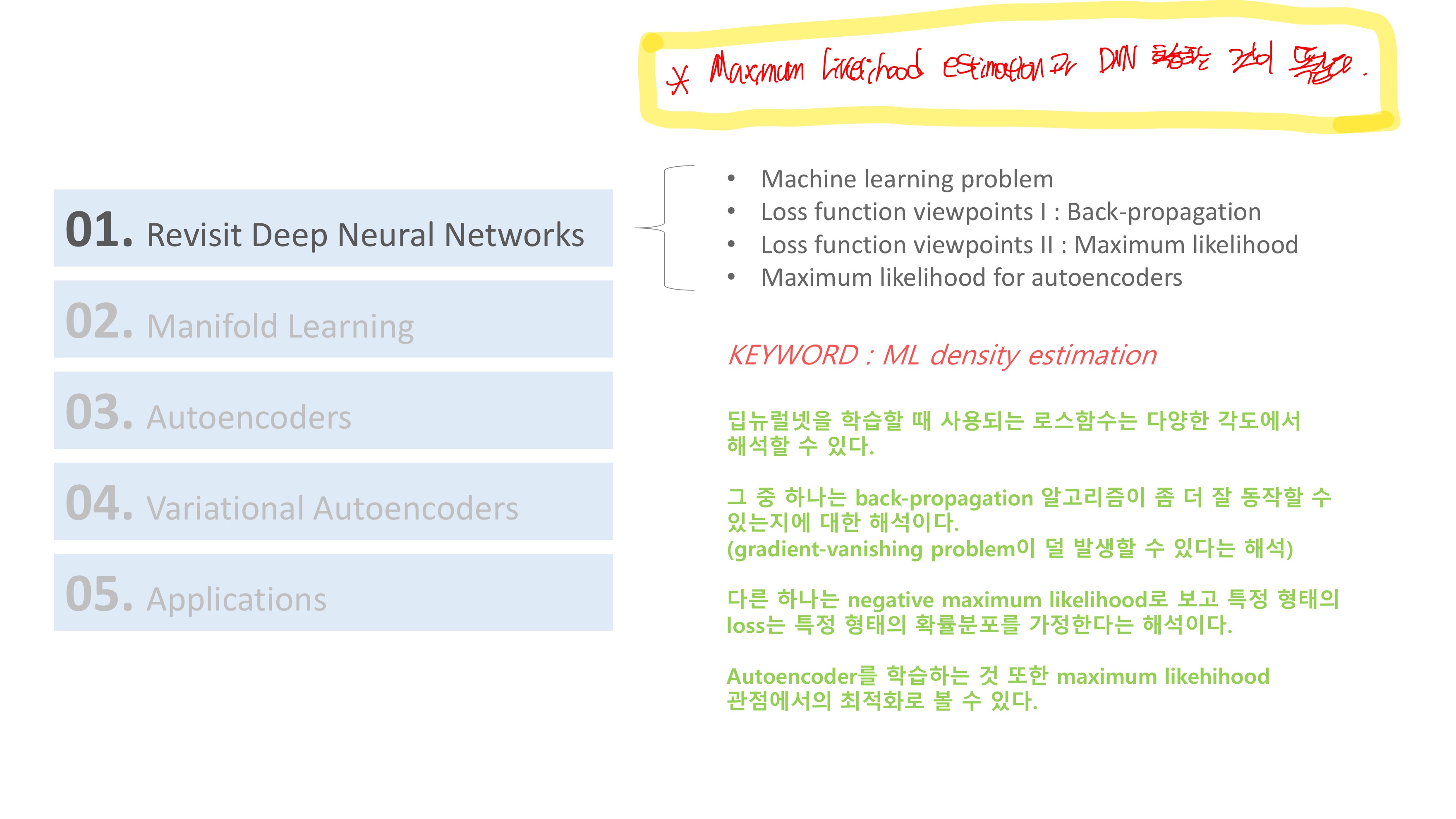
variation Autoencoder 의 경우에 Maximum Likelihood를 활용하는 부분이 있기 때문에 딥러닝의 전반적인 학습 과정과 loss function을 바라보는 2가지 관점을 설명하려고 한다.
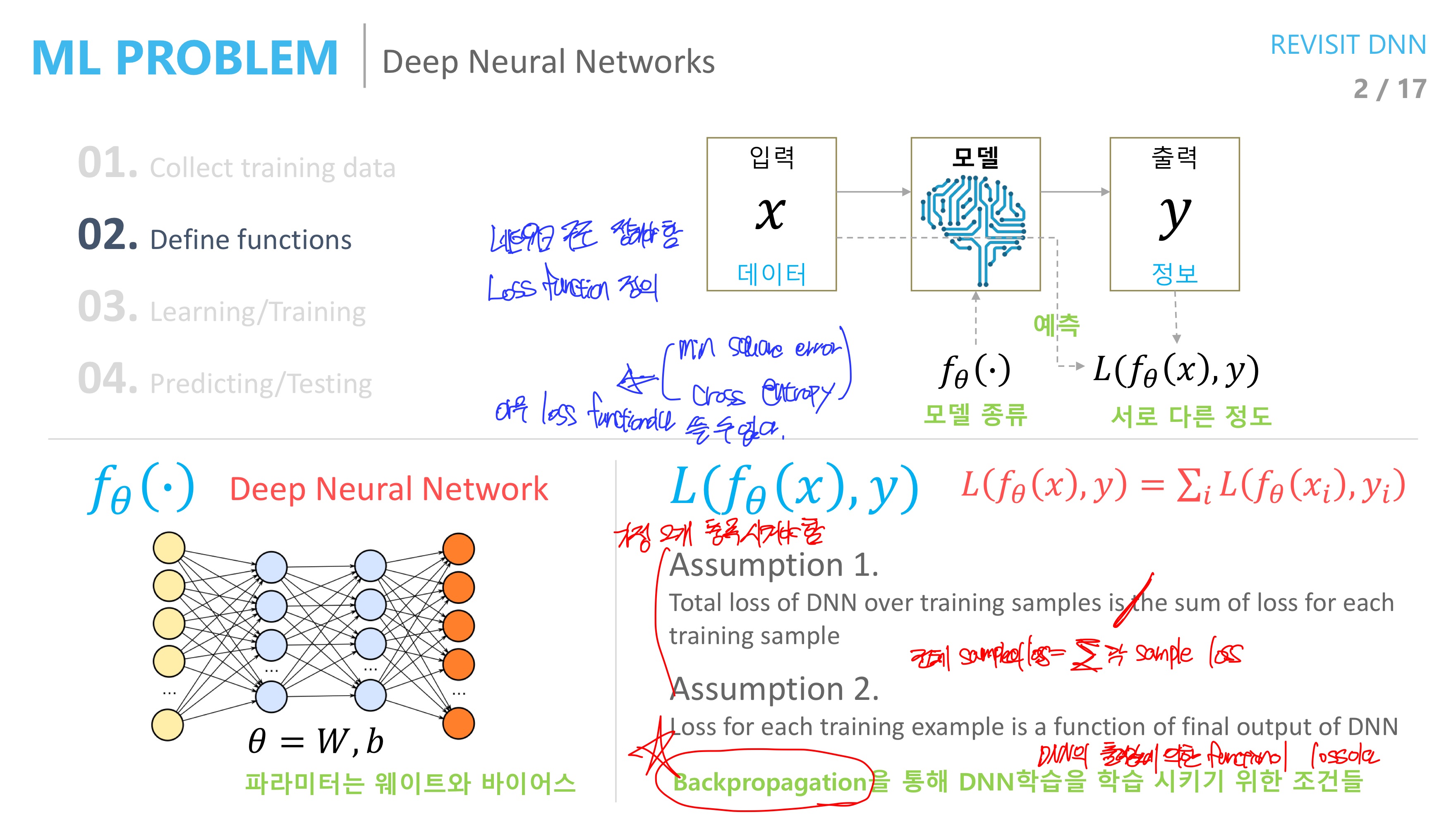
딥러닝의 전반적인 과정에 대해 살펴보면 결정해야 할 사항들이 몇 가지 있다.
네트워크의 구조를 설정해야 할 것이고 최종 출력과 실제 y값의 차이를 최소화 하기 위한 loss function도 정의 해야 한다.
loss function으로서는 크게 1.mean squared error 2. cross entropy 2가지가 존재하며 이 2가지 밖에 존재하지 않는 이유는 loss function이 2가지 가정을 만족해야 하기 때문이다.
이 2가지 가정은 딥러닝 모델을 학습하기 위해서 핵심적인 학습 방법인 backpropagation을 성립시키기 위해서이다.

그렇다면 loss function의 최소값을 구하는 방법은 Gradient Descent 라고 하고 L(Δθ+θ) < L(θ) 일 때 마다 θ를 update 시키고 L(Δθ+θ) = L(θ) 일 때 멈추게 된다. Δθ는 learning rate를 사용하여 조금씩 값을 바꾸게 한다. (테일러 전개 상황에서 1차 미분값까지만 활용했기 때문에)
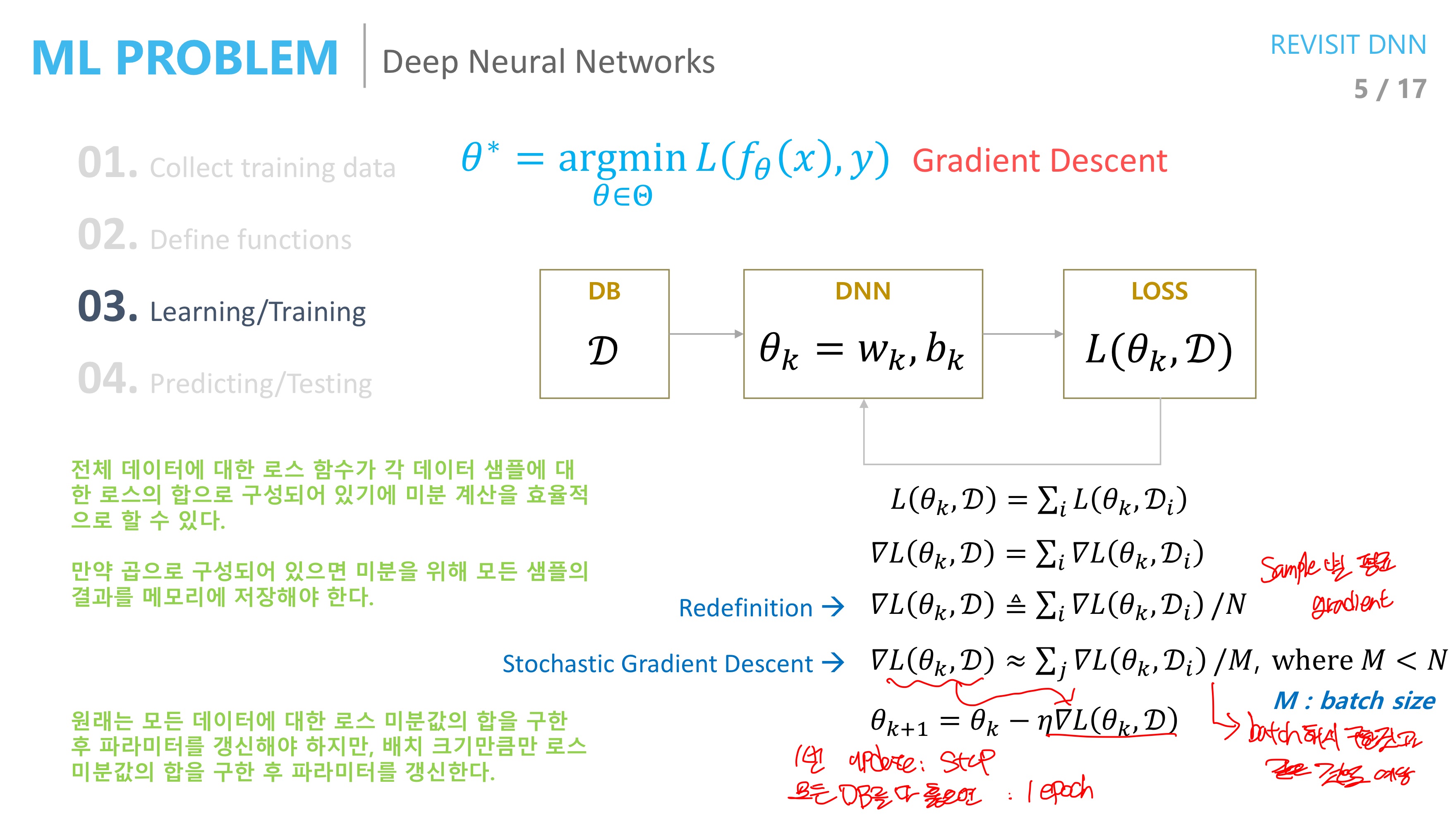
원래라면 모든 데이터에 대한 loss function 미분값을 다 더해서 parameter를 갱신해야 하지만 현실적으로 계산량이 너무 많기 때문에 위 수식 과정을 거쳐서 M개의 batch 크기만큼의 미분값의 평균을 구한 뒤에 이를 갱신에 활용한다
1번의 update를 step이라 하고
모든 data를 다 훑으면 1 epoch이라 한다

특정 layer에서 parameter를 갱신하고
다음 layer에서는 activation function의 미분값만큼 곱해지기에 paramter가 변하는 정도가 점점 작아지게 된다 -> gradient vanishing problem
Loss function에 대한 2가지 관점
Backpropagation
1. Mean Square Error
parameter 값을 갱신해 나갈 때에 activation function의 미분값들이 계속해서 곱해지기 때문에 w,b의 초기값에 영향을 많이 받게 된다.
2. Cross Entropy
출력 레이어에서의 에러값에 activation function의 미분값이 곱해지지 않아서 gradient vanishing problem 에서 좀 더 자유롭다 (학습이 좀 더 빨리 된다)
따라서 Backpropagetion 관점에서만 본다면 Cross Entropy loss function이 좀 더 유리하다고 할 수 있다
Maximum Likelihood

확률 분포는 정해지고 확률 분포를 구성하는 매개변수 값들을 적절히 변경시켜서 주어진 y값이 나올 확률이 최대가 되게끔 하는 방식(예를 들어, 가우시안 분포라고 하면 평균과 표준편차를 특정 값으로 정하면 특정 X 분포에서의 확률값들이 가장 높게 나오는 느낌 -> P(X|θ)가 최대가 되는 θ찾기)
y가 연속적인 분포라고 가정 & MLE => MSE 를 최소화 시키는 것과 동치
y가 이산적인 분포라고 가정 & MLE => CE 를 최소화 시키는 것과 동치

Reference
slide - https://www.slideshare.net/NaverEngineering/ss-96581209
영상(1/3) - https://youtu.be/o_peo6U7IRM
유투브 Naver d2의 영상을 바탕으로 정리하였습니다
