Sebastian Ruder의 ML and NLP Research Highlights of 2021을 번역했습니다. 오역이 있다면 알려주세요.
2021년 기계 학습(ML)과 자연어 처리(NLP)에 많은 흥미로운 발전이 있었습니다. 저는 이 게시물에서 제게 큰 영감을 준 논문과 연구 분야를 다룰 것입니다. 제가 알고 있는 한 관련된 논문을 모두 언급하려고 노력했으나 상당수 놓쳤을 수 있습니다. 놓친 것에 대해서는 댓글로 달아주시고 인상 깊었던 지점도 알려주세요. 다음 주요 사항에 대해 논의하겠습니다.
- 유니버설 모델
- 대규모 다중 작업 학습
- 트랜스포머를 넘어서
- 프롬프팅
- 효율적 방법론
- 벤치마킹
- 조건부 이미지 생성
- 과학을 위한 ML
- 프로그램 합성
- 편향
- 검색을 통한 데이터 증강
- 토큰 없는 모델
- 시간에 따른 적응
- 데이터의 중요성
- 메타-러닝
1) 유니버설 모델
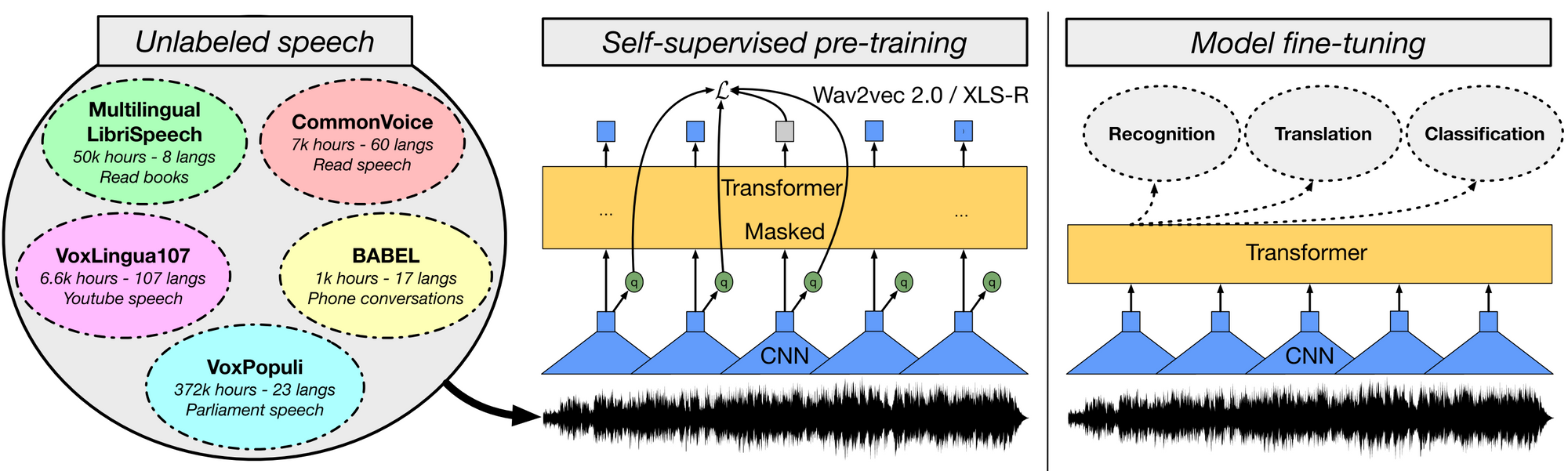
XLS-R을 사용한, 음성 기반 교차 언어 표현에 대한 자기 지도 학습. 자기 지도의 wav2vec 2.0 스타일 손실을 사용하여 다양한 다국어 음성 데이터에 대해 모델을 사전 학습합니다. 그런 다음 훈련한 모델을 상이한 음성 작업을 위해 미세 조정합니다 (Babu et al., 2021).
무슨 일이 일어났나요? 2021년에도 대형 사전 훈련 모델 개발은 지속되었습니다. 사전 훈련 모델은 다양한 영역에 적용되었고 ML 연구에서 굉장히 중요한 성과로 간주되기 시작했습니다1. 컴퓨터 비전에서는 Vision Transformer2 같은 지도 학습 모델이 확장되었고3 자기 지도 학습 모델이 높은 성능을 내기 시작했습니다4. 후자의 경우 ImageNet 같이 제어된 환경을 넘어 무작위로 모은 이미지들로 확장되었습니다 5. 음성에서는 wav2vec 2.06을 기반으로 W2v-BERT7와 같은 새로운 모델이 구축되었습니다. XLS-R8처럼, 보다 강력한 다국어 모델도 나왔습니다. 동시에 비디오와 언어9, 음성과 언어10 같이 이전에 충분히 연구되지 않은 모달리티 쌍들에 대해 사전 훈련된 유니버설 모델이 새롭게 선보였습니다. 비전과 언어에서의 통제 연구는 이러한 멀티 모달 모델의 중요한 구성 요소에 대해 새로운 시각을 열어줍니다11 12. 언어 모델링의 패러다임으로 다양한 작업을 구성함으로써 모델은 강화 학습13과 단백질 구조 예측14처럼 전혀 다른 영역에서도 큰 성공을 거두었습니다. 이렇게 많은 모델에서 관찰된 규모의 확장성을 고려할 때 매개변수 크기의 여러 설정 별로 성능을 이야기하는 것이 일반적인 관행이 되었습니다. 하지만 사전 훈련 성능의 증가가 반드시 다운스트림 성과로 연결되는 것은 아닙니다15 16.
왜 중요한가요? 사전 훈련된 모델은 주어진 도메인 또는 모달리티의 새로운 작업에도 곧잘 일반화되는 것으로 나타났습니다. 이 모델들은 강력한 퓨-샷 학습 능력과 강건성을 보여줍니다. 따라서 이들은 연구 발전을 위한 소중한 주춧돌이고 새로운 실전 응용을 가능하게 합니다.
다음 단계는 뭘까요? 의심할 여지없이 미래에는 더 다양하고, 더 거대한 사전 훈련 모델이 개발될 것입니다. 동시에 개별 모델은 더 다양한 작업을 수행할 것으로 기대됩니다. 이것은 일반적인 텍스트 대 텍스트 형식으로 프레임을 지정하여 다양한 작업을 수행할 수 있는 언어 모델의 경우 기정사실입니다. 유사하게 우리는 단일 모델에서 다양한 일반 작업을 수행할 수 있는 이미지와 음성 모델을 보게 될 것입니다. 마지막으로, 우리는 여러 모달리티에 대해 모델을 훈련한 더욱 많은 연구 결과물을 보게 될 것입니다.
2) 대규모 다중 작업 학습
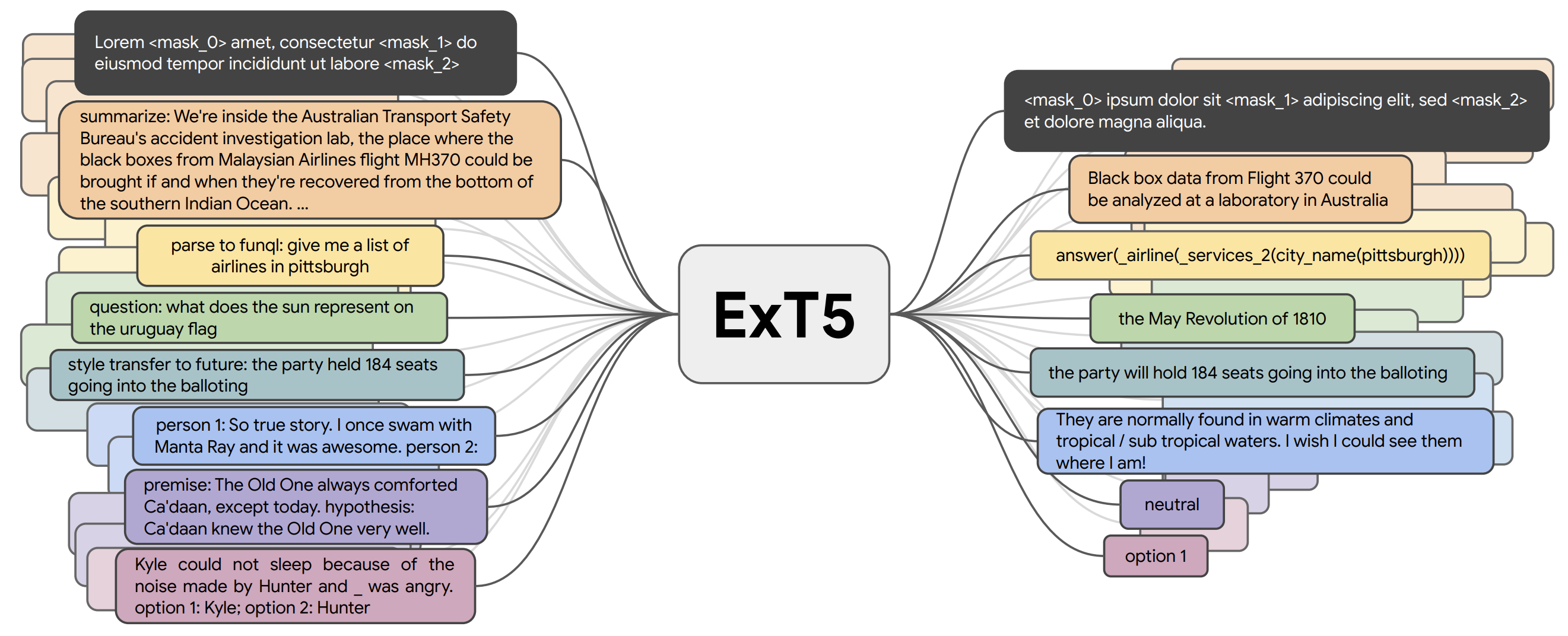
ExT5를 통한 대규모 다중 작업 학습. 사전 훈련하는 동안 모델은 텍스트-텍스트 형식의 다양한 작업 집합 입력(왼쪽)에 대해 훈련되어 해당 출력(오른쪽)을 생성합니다. 작업에는 (위에서 아래 순으로) 마스킹된 언어 모델링, 요약, 시멘틱 파싱, 클로즈드-북 형식의 질의응답, 스타일 전이, 대화 모델링, 자연어 추론, Winograd-스키마 스타일 상호 참조 해결 등이 포함됩니다 (Aribandi et al., 2021).
무슨 일이 일어났나요? 이전 절에서 다룬 사전 훈련된 모델의 대부분은 자기 학습 기반입니다. 이것들은 보통 명시적인 지도 학습이 필요하지 않은 목표 함수로써, 레이블이 지정되지 않은 대량의 데이터를 통해 학습됩니다. 그러나 많은 도메인의 경우 더 나은 표현을 학습하는 데 사용할 수 있는 레이블이 지정된 대량의 데이터가 이미 사용 가능합니다. 지금까지 T017, FLAN18, ExT519와 같은 다중 작업 모델은 주로 언어를 중심으로 약 100개의 작업에 대해 사전 훈련되었습니다. 이러한 대규모 다중 작업 학습은 메타 학습과 밀접하게 관련 있습니다. 다양한 작업 분포20에 대해 접근 가능하면 모델은 맥락 상의 학습을 수행하는 방법과 동일하게 다양한 유형의 행동을 학습하는 방법을 학습해낼 수 있습니다21.
왜 중요한가요? T5, GPT-3과 같은 최신 모델은 텍스트-텍스트 형식을 많이 사용하기 때문에 대규모 다중 작업 학습이 가능합니다. 따라서 모델이 여러 작업을 효과적으로 학습하게 하기 위해 작업별 손실 함수 또는 계층을 손수 설정하는 일이 더 이상 필요하지 않습니다. 최근 이러한 접근 방식은 자기 지도 사전 훈련과 다중 작업 지도 학습을 결합하는 이점이 강조되고 두 가지의 조합이 더 일반적인 모델로 이어진다는 사실을 보여줍니다.
다음 단계는 뭘까요? 통합된 형식의 데이터 세트 가용성과 오픈 소스 특성을 감안할 때 새로 생성된 고품질 데이터 세트를 더 다양한 작업 모음에 대해 더 강력한 모델을 훈련하는데 점차 사용하는 선순환을 상상해볼 수 있습니다. 이런 순환 구조를 통해 더 난도 높은 데이터 세트를 생성할 수 있을 겁니다.
3) 트랜스포머를 넘어서
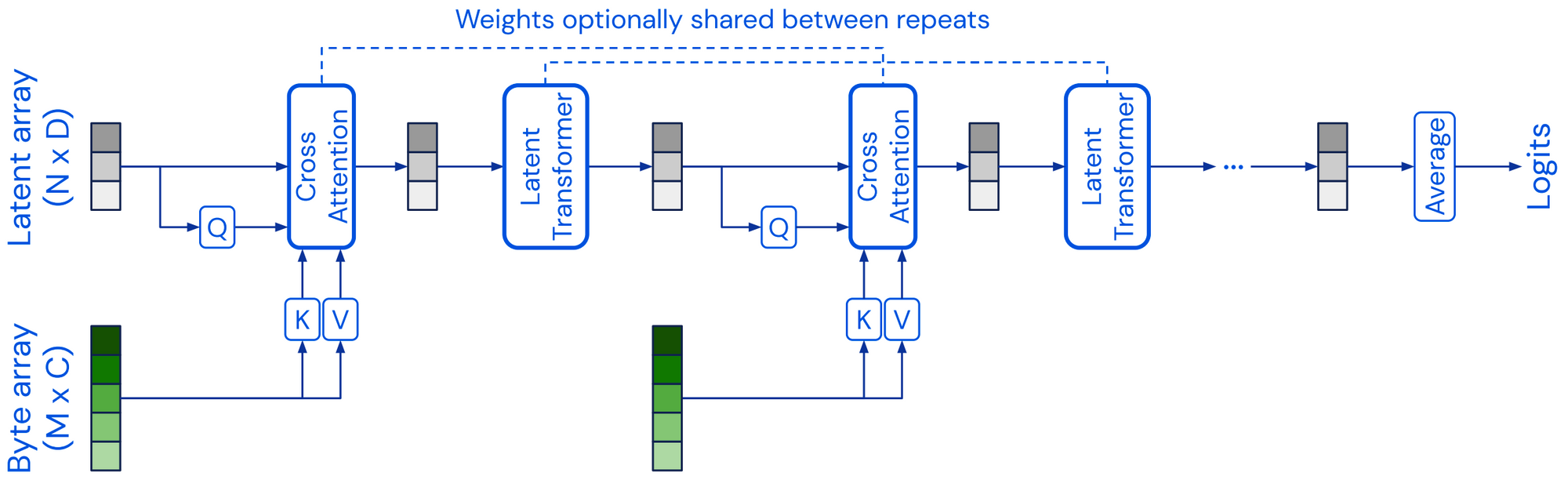
Perceiver는 크로스 어텐션을 통해 고차원 입력 바이트 배열을 고정 차원 잠재 배열에 투영하고 이를 트랜스포머 셀프 어텐션 블록으로 처리합니다. 그런 다음 크로스 어텐션과 셀프 어텐션 블록을 교대로 적용합니다(Jaegle et al., 2021).
무슨 일이 일어났나요? 이전 절에서 논의한 사전 훈련 모델의 대부분은 트랜스포머 아키텍처를 기반으로 합니다22. 2021년에는 트랜스포머에 대한 존속 가능한 대안으로 여러 모델 아키텍처들이 개발되었습니다. Perceiver23는 고정 차원의 잠재 배열을 기본 표현으로 사용하고 크로스 어텐션을 통해 입력에 대해 이를 조정함으로써 고차원 입력으로 확장되는 트랜스포머와 유사한 아키텍처입니다. Perceiver IO24는 구조화된 출력 공간도 처리할 수 있게 아키텍처를 확장했습니다. MLP-Mixer25 및 gMLP26와 같이 다층 퍼셉트론(MLP)을 사용하여 도처에 사용되는 셀프 어텐션 계층을 대체하려는 모델들도 있습니다. FNet27은 토큰 수준에서 정보를 혼합하기 위해 셀프 어텐션 대신 1차원 푸리에 변환을 사용합니다. 일반적으로 아키텍처는 사전 학습 전략과 별개의 것으로 생각할 수 있습니다. 예를 들어 CNN을 트랜스포머 모델과 동일한 방식으로 사전 훈련하면 많은 NLP 작업에서 경쟁력 있는 성능을 획득합니다28. 비슷하게, ELECTRA 스타일의 사전 훈련29 같이 사전 훈련 목표 함수의 대안을 사용해도 큰 성과를 얻을 수 있습니다30.
왜 중요한가요? 자고로 연구란 보완하거나 대체하는 여러 방향을 동시에 탐색하면서 진행됩니다. 만약 대부분의 연구가 단일 아키텍처에만 초점을 맞춘다면 필연적으로 편향, 인지의 사각, 기회의 손실로 이어질 것입니다. 새로운 모델은 어텐션의 계산 복잡도, 블랙박스적인 특성과 순서에 대한 불가지론적인 성격처럼 트랜스포머의 일부 제약 사항을 해결할 수 있습니다. 예를 들어, 일반화된 가법 모델에 대한 신경망 확장은 현재 모델에 비해 훨씬 더 나은 해석 가능성을 제공합니다31.
다음 단계는 뭘까요? 사전 훈련된 트랜스포머는 많은 작업에 대해 표준 베이스라인 역할을 지속적으로 할 가능성이 높지만, 장거리 종속성과 고차원 입력 모델링처럼 현재 모델이 부족하거나 해석과 설명 가능성이 필요한 설정에서 대안적인 아키텍처 탄생을 기대해볼 수 있습니다.
4) 프롬프팅
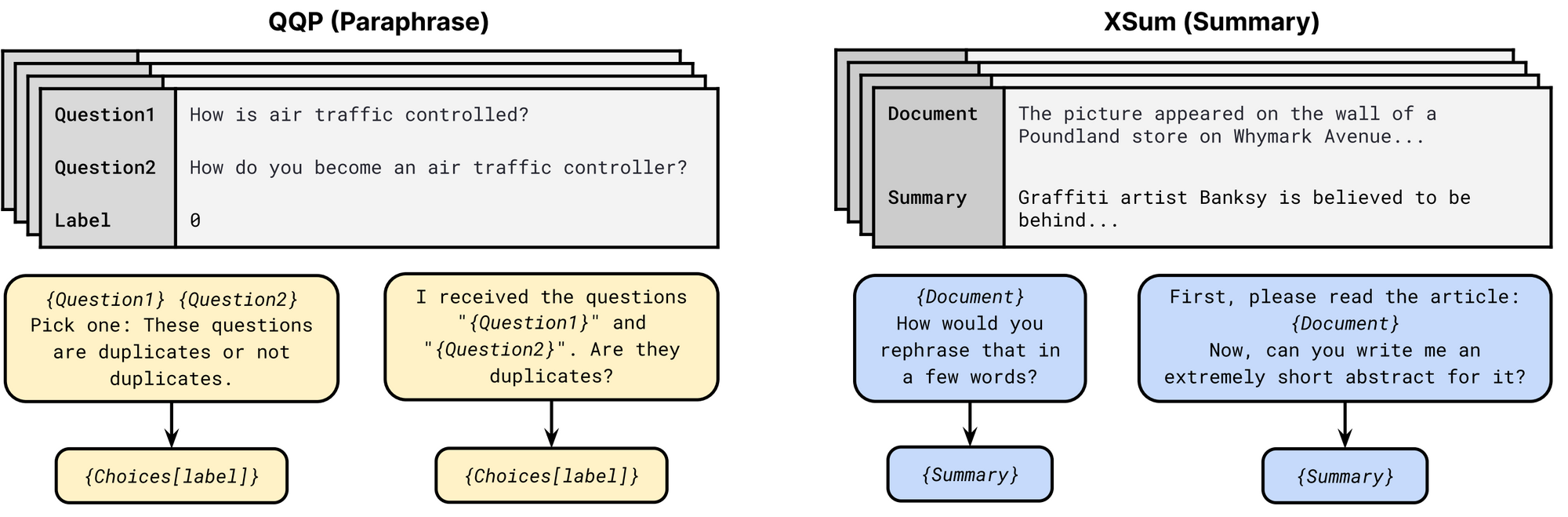
P3 프롬프트 모음의 프롬프트 템플릿. 각 작업에 대해 여러 가지 템플릿 이용이 가능합니다. 각 템플릿은 입력 패턴과 타깃 언어 처리기로 구성됩니다. 패러프레이징 작업의 경우 첫 번째와 두 번째 템플릿에서 Choices는 각각 {Not duplicates, Duplicates}과 {Yes, No}로 구성됩니다(Sanh et al., 2021).
무슨 일이 일어났나요? GPT-332에 의해 대중화된 프롬프트는 NLP 모델 입력 형식의 존속 가능한 대안으로 등장했습니다. 프롬프트에는 일반적으로 모델에 특정 예측을 하도록 요청하는 패턴과 예측을 클래스 레이블로 변환하는 언어 처리기가 포함됩니다. PET33, iPET 34과 AdaPET35와 같은 여러 접근법은 퓨-샷 학습을 위해 프롬프트를 활용합니다. 그러나 프롬프트는 만병통치약이 아닙니다. 모델의 성능이 프롬프트에 따라 크게 달라지며 최적 프롬프트를 찾는 데 여전히 레이블이 지정된 예제가 필요합니다36. 퓨-샷 설정에서 모델을 안정적으로 비교하기 위해 새로운 평가 절차가 개발되었습니다37. 다수의 프롬프트를 공개 프롬프트 풀(P3)에서 이용할 수 있으므로 프롬프트 사용에 있어 가장 좋은 예제를 찾아볼 수 있습니다. 또한 각주의 조사 논문38은 프롬프트 연구의 일반 영역에 대한 훌륭한 개괄을 제시합니다.
왜 중요한가요? 프롬프트는 작업에 따라 최대 3,500개 레이블이 지정된 예제에 해당하는, 작업 별 정보를 인코딩하는 데 사용할 수 있습니다39. 따라서 프롬프트는 수동으로 예제에 레이블을 지정하거나 레이블 기능을 정의하는 것 이상으로 전문적인 정보를 모델 훈련에 통합하는 새로운 방법이 가능하게 만듭니다40.
다음 단계는 뭘까요? 우리는 모델 학습 개선을 위해 프롬프트 활용의 걸음마를 이제 막 떼기 시작한 셈입니다. 더 긴 지침18:1, 긍정/부정의 예41, 범용적인 휴리스틱을 포함하는 등 프롬프트는 더욱 정교해질 것입니다. 프롬프트는 또한 자연어 설명42을 모델 훈련에 통합하는 굉장히 자연스러운 방법일 수 있습니다.
5) 효율적 방법론
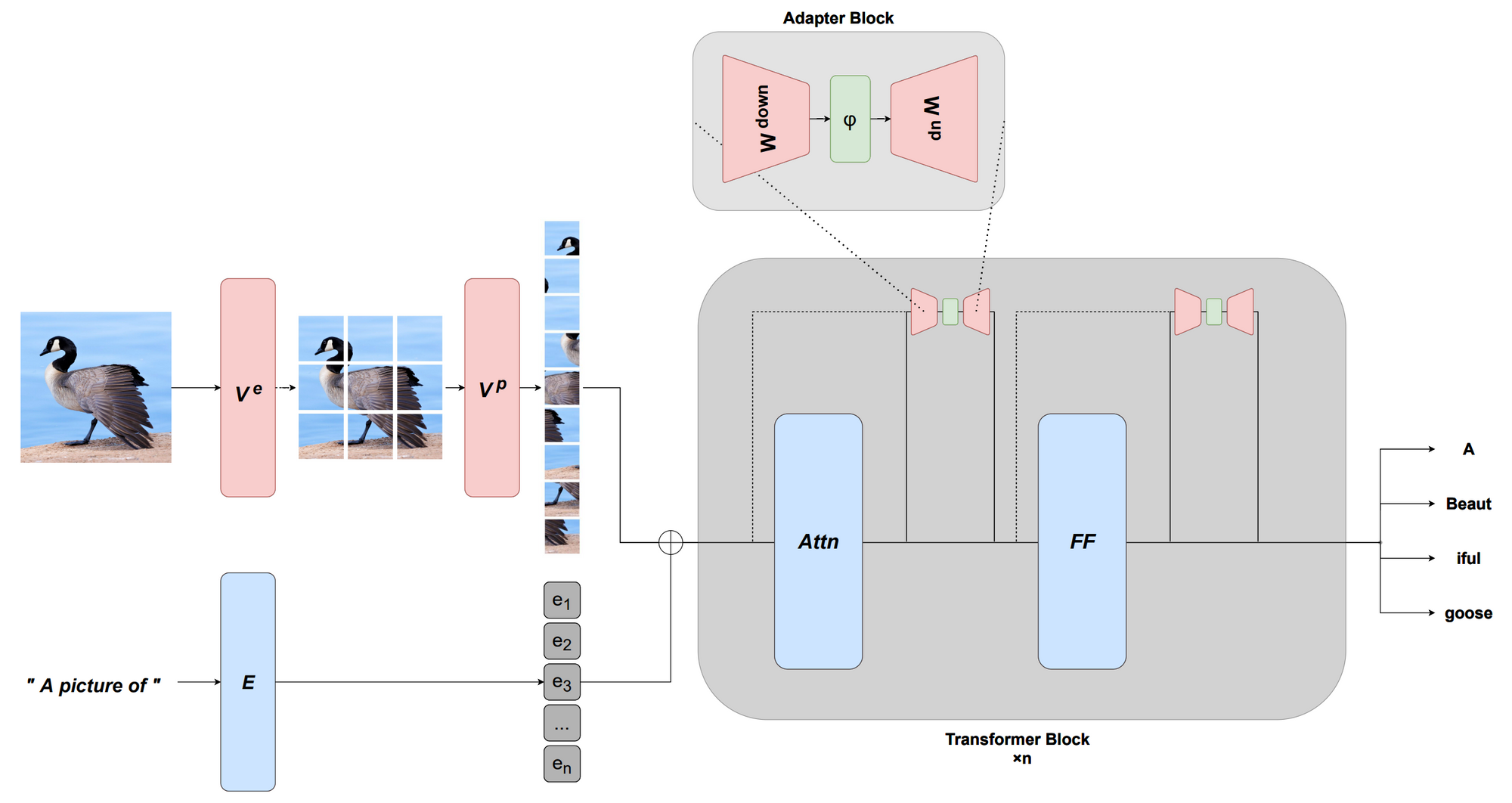
MAGMA를 사용한 멀티모달 적응. 고정된 사전 훈련 언어 모델은 이미지 인코더와 비전 전용의 어댑터 계층을 통해 학습한 시각적 접두사를 사용하여 멀티 모달 작업에 적응됩니다(Eichenberg et al., 2021).
무슨 일이 일어났나요? 사전 훈련 모델은 보통 너무 거대해서 실제로 사용하기에는 비효율적입니다. 2021년, 아키텍처와 미세 조정 방법론 양쪽에서 더 나은 효율성을 달성 가능하게 하는 발전이 있었습니다. 모델링 측면에서 우리는 셀프 어텐션의 더 효율적인 버전 몇 가지를 보게 되었습니다43 44. 각주의 조사 논문45은 2021년 이전 모델들의 개괄을 제시합니다. 현재의 사전 훈련 모델은 매우 강력하여 소수의 매개 변수만 업데이트하여 효과적으로 조건화할 수 있고 이는 무엇보다도 연속적인 프롬프트46 47 그리고 어댑터48 49 50 기반의 보다 효율적인 미세 조정 방법론 개발로 이어졌습니다. 또한 이러한 능력은 적절한 접두사51 또는 변환52 53을 학습하여 새로운 모달리티에 대한 적응이 가능하게 합니다. 보다 효율적인 옵티마이저54와 희소성을 만들어내기 위한 양자화처럼 다른 방법론도 사용되었습니다.
왜 중요한가요? 표준 하드웨어에서 실행하는 것이 불가능하거나 실행 비용이 엄청난 모델은 유용하지 않습니다. 효율성의 발전은 모델이 점점 커지더라도 실무자가 쉽게 접근하고 이용할 수 있도록 보장해줄 것입니다.
다음 단계는 뭘까요? 효율적 모델과 그것의 훈련 방법론은 접근하거나 사용하기 쉬워야 합니다. 동시에 AI 커뮤니티는 새로운 모델을 처음부터 사전 훈련할 필요 없이 대형 모델과 인터페이스하고 효율적으로 적응, 결합 또는 수정할 수 있게 해 주는, 보다 효과적인 방법을 개발할 것입니다.
6) 벤치마킹
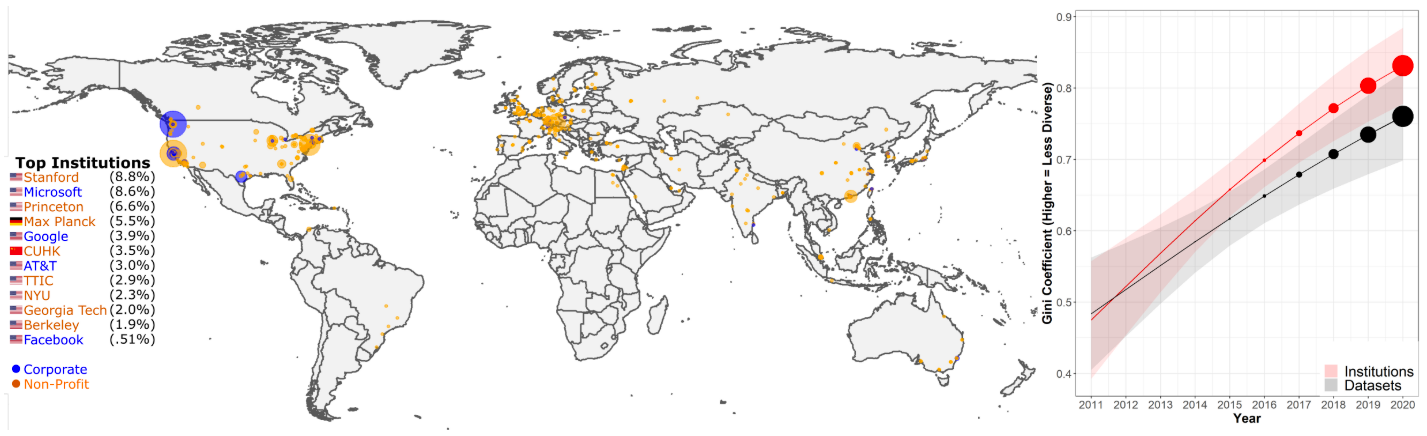
특정 연구 기관과 데이터 세트에 대한 데이터 세트 사용 집중도가 시간이 지나면서 점차 증가합니다. 연구 기관 별 데이터 세트 사용량에 대한 지도(왼쪽)입니다. 데이터 세트 사용량의 50% 이상이 12개의 연구 기관에 의존합니다. 지니 계수로 측정한 특정 연구 기관과 데이터 세트에 대한 데이터 세트 사용의 집중도는 최근 몇 년 사이 증가해왔습니다(오른쪽)(Koch et al., 2021).
무슨 일이 일어났나요? 최근 ML과 NLP 모델의 빠르게 발전하는 역량이 이를 측정하는 벤치마크 다수의 능력을 뛰어넘었습니다. 동시에 AI 커뮤니티는 점차 소수의 엘리트 연구 기관에서 만든, 더 적은 수의 벤치마크로 평가를 수행하고 있습니다55. 이 블로그 게시물에서 다뤘듯이 2021년, 결과적으로 모범 사례와 이러한 모델들을 향후 안정적으로 평가할 수 있는 방법에 관하여 많은 논의가 이루어졌습니다. 2021년 NLP 커뮤니티에 등장한 주목할만한 리더보드 패러다임으로 동적 적대적 평가56, 커뮤니티 구성원이 BIG-bench와 같은 평가 데이터 세트를 생성하기 위해 협력하는 커뮤니티 주도 평가, 다양한 오류 유형에 대한 대화형 세분화 평가57, 단일 성능 지표에 대한 모델 평가를 극복한 다차원 평가58 등이 있습니다. 또한 퓨-샷 평가60와 교차 도메인 일반화61와 같이 영향을 주는 설정에 대한 새로운 벤치마크가 제안되었습니다. 더 나아가 음성62, 특정 언어(예: 인도네시아어와 루마니아어63 64)처럼 특정 모달리티에 대해 범용의 사전 훈련 모델을 평가하는 데 집중한 연구들 뿐만 아니라 다양한 모달리티65와 다국어 설정66에서도 새로운 벤치마크들이 선보였습니다. 우리는 평가 지표에도 관심을 기울여야 합니다. 기계 번역(MT) 메타 평가67에 따르면 지난 10년간 108개의 대체 측정 기준(종종 사람에 대한 상관성이 더 좋음에도)이 제안되었지만 769개의 MT 논문 중 74.3%가 BLEU만을 사용했습니다. 따라서 GEM68과 2차원 리더보드69와 같은 최근의 노력들은 모델과 이런 방법론을 공동으로 평가할 것을 제안합니다.
왜 중요한가요? 벤치마킹과 평가는 기계 학습과 NLP 과학 진보의 핵심입니다. 정확하고 신뢰할 수 있는 벤치마크가 없다면 우리가 진정한 개선을 해내고 있는지 아니면 고정된 데이터 세트와 지표에 과적합하고 있는지 그 진위를 알 수 없을 겁니다.
다음 단계는 뭘까요? 벤치마킹 문제에 대한 인식 수준이 높아짐에 따라 이제 새로운 데이터 세트를 보다 신중하게 설계해야 합니다. 또한 새로운 모델에 대한 평가는 단일 성능 지표에 중점을 두지 않고 모델의 공정성, 효율성과 강건성처럼 다양한 차원을 고려해야 합니다.
7) 조건부 이미지 생성
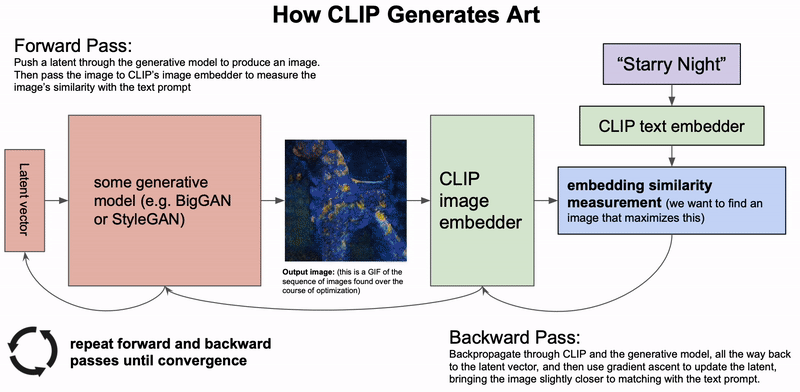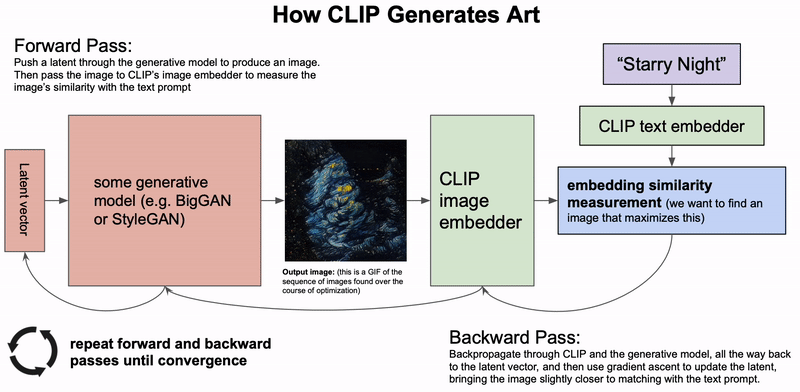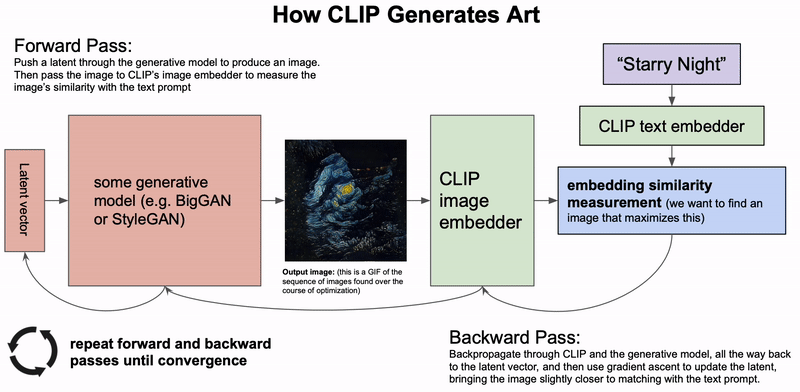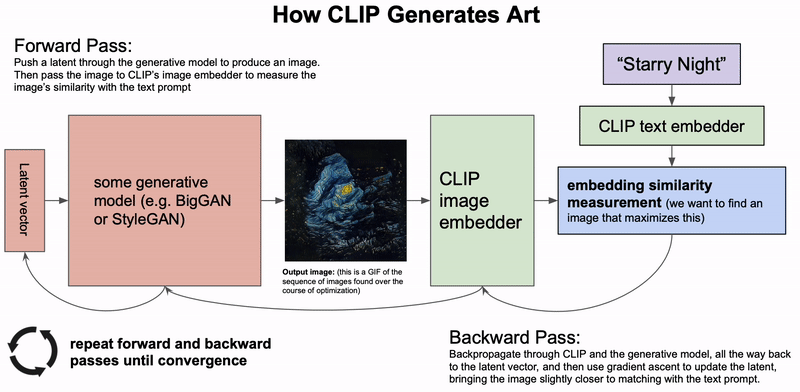
CLIP이 아트를 생성하는 방법. 생성 모델은 잠재 벡터를 기반으로 이미지를 생성합니다. 그런 다음 잠재 벡터는 생성한 이미지와 텍스트 설명 간의 CLIP 임베딩 유사도를 기반으로 업데이트됩니다. 이 과정을 수렴할 때까지 반복합니다(제공: Charlie Snell).
무슨 일이 일어났나요? 조건부 이미지 생성, 즉 텍스트 설명을 기반으로 이미지를 생성하는 작업은 2021년에 인상적인 결과를 선보였습니다. 최근에는 생성 모델을 중심으로 한 예술 기조가 등장했습니다(이 블로그 게시물을 참조하세요.). DALL-E 모델70에서처럼 텍스트 입력 기반으로 이미지를 직접 생성하는 대신, 최근의 접근 방식은 CLIP72 등 이미지와 텍스트 결합 임베딩 모델을 사용하여 VQ-GAN71처럼 강력한 생성 모델의 출력을 조정합니다. 신호에서 점차 잡음을 제거하는 우도 기반 확산 모델은 GAN을 능가할 수 있는 강력하고 새로운 생성 모델로 떠올랐습니다73. 텍스트 입력을 기반으로 출력을 조정함으로써 최근 모델은 사실적인 이미지 품질에 근접해가고 있습니다74. 이러한 모델은 특히 인페인팅에 능하며 주어지는 설명에 따라 이미지를 수정할 수 있습니다.
왜 중요한가요? 사용자가 원하는 방향으로 고품질 이미지를 자동 생성할 수 있다면 시각적인 자산을 자동으로 디자인할 수 있고 모델 지원 하에 프로토타이핑, 디자인, 개인화 등이 가능해져 예술, 상업적 응용 프로그램의 새로운 장이 광범위하게 열릴 것입니다.
다음 단계는 뭘까요? 최근에 나온 확산 기반 모델의 샘플링은 GAN 기반 모델에 비해 훨씬 느립니다. 이러한 모델을 실제 응용 프로그램에 유용하게 사용할 수 있도록 효율성을 개선해야 합니다. 또한 이 영역에서 모델이 인간을 보조할 수 있는 최상의 방법과 적절한 응용 프로그램을 식별할 수 있도록 인간-컴퓨터 상호 작용에 대한 더 많은 연구가 필요합니다.
8) 과학을 위한 ML
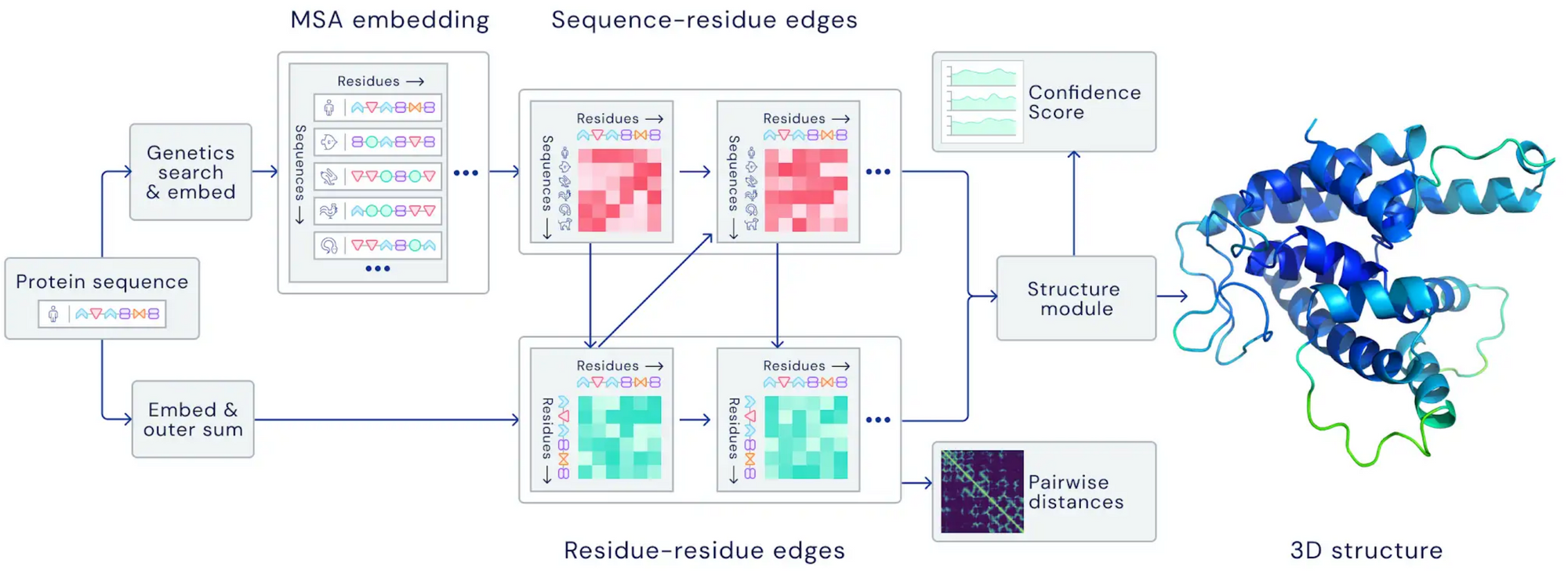
AlphaFold 2.0의 아키텍처. 이 모델은 아미노산 잔기 쌍뿐만 아니라 진화적으로 관련된 단백질 서열에 어텐션을 가하여 두 표현 사이에 정보를 반복적으로 전달합니다(제공: DeepMind).
무슨 일이 일어났나요? 2021년 자연 과학에 적용한 ML 기술에 몇 가지 혁신이 있었습니다. 기상학에서 현재 예측(Nowcasting)과 미래 예측(Forecasting)75 76을 발전시켰고 정확도가 크게 향상했습니다. 양쪽 모두 해당 모델이 물리학 기반의 첨단 예측 모델을 능가했습니다. 생물학에서 AlphaFold 2.0은 유사한 구조가 알려지지 않은 경우에도 단백질 구조를 전례 없는 정확도로 예측해냈습니다14:1. 수학에서는 ML이 새로운 연결 가능성과 알고리즘을 발견하게끔 수학자의 직관을 도와줄 수 있는 걸로 드러났습니다77. 또한 트랜스포머 모델을 충분한 양의 데이터로 훈련하면 국지적 안정성과 같은 미분 시스템의 수학적 속성을 학습할 수 있는 것으로 나타났습니다78.
왜 중요한가요? ML을 이용하여 자연 과학에 대한 이해와 응용성을 향상하는 방향은 ML의 가장 영향력 있는 적용 분야 중 하나가 될 것입니다. 강력한 ML 방법론을 사용하면 두 학문 양쪽의 새로운 응용 가능성을 시험해볼 수 있을 것이고 의약품 설계와 같이 기존에 응용하던 영역에서도 속도를 크게 높일 수 있을 것입니다.
다음 단계는 뭘까요? 새로운 발견과 발명의 영역에서 연구원을 지원하기 위해 순환 구조 내에서(in-the-loop) 모델을 사용하는 방향이 특히 매력적으로 보입니다. 강력한 모델 개발과 대화형 기계 학습, 인간-컴퓨터 상호 작용에 대한 연구 모두 필요합니다.
9) 프로그램 합성
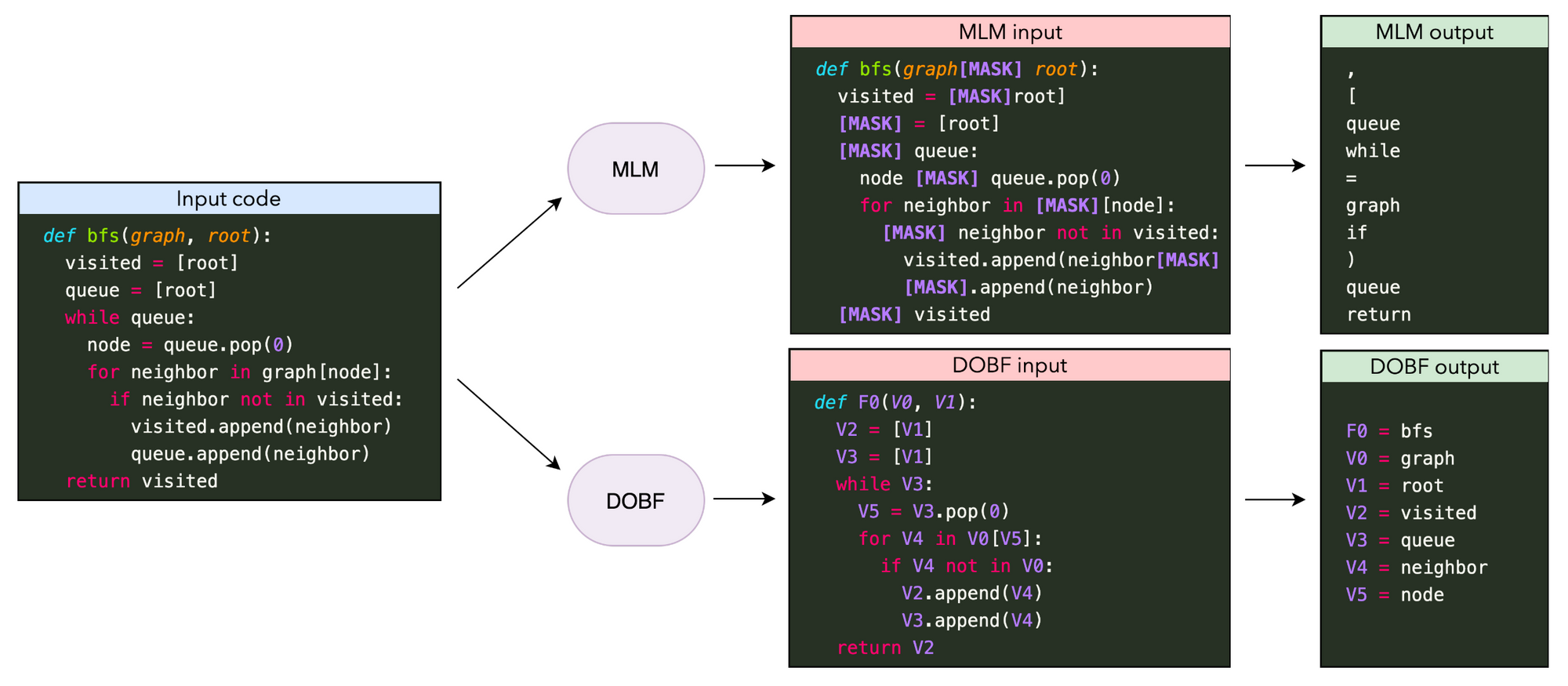
코드 모델링에 대한 마스크 된 언어 모델링(MLM)과 역 난독화(DOBF)의 사전 훈련 목표 함수 비교. MLM은 주로 프로그래밍 언어 구문과 관련한, 무작위로 마스킹한 토큰을 예측합니다. DOBF는 함수와 변수의 이름을 역 난독화해야하며 이는 훨씬 더 어려운 과제입니다(Roziere et al., 2021).
무슨 일이 일어났나요? 올해 가장 주목할만한 대형 언어 모델 응용 중 하나는 Codex79와 함께 GitHub Copilot의 일부로써 주요 제품에 최초로 통합된 코드 생성 기능이었습니다. 이와 함께 개선된 사전 훈련 목표80 81에서부터 실험 확장82 83에 이르기까지 해당 사전 훈련 모델의 발전 양상은 현재 다양합니다. 그러나 복잡하고 긴 형식의 프로그램을 생성하는 작업은 현재 모델에게는 여전히 버거운 일입니다. 관련된 연구 중 흥미로운 방향은 중간 계산 단계를 "스크래치 패드"에 기록하면서 다단계 계산을 수행, 개선할 수 있는 프로그램을 실행하거나 모델링하는 방법을 학습하는 것입니다84.
왜 중요한가요? 복잡한 프로그램을 자동으로 합성할 수 있다면 소프트웨어 엔지니어 지원처럼 다양한 응용 프로그램에 유용할 것입니다.
다음 단계는 뭘까요? 코드 생성 모델이 실제로 소프트웨어 엔지니어의 작업 흐름을 얼마나 향상할지 여전히 미지수입니다85. 큰 도움이 되기 위해서는 대화 모델과 유사하게 해당 모델이 새로운 정보 기반으로 예측을 업데이트할 수 있어야 하고 지역적, 전역적 맥락을 고려할 수 있어야 합니다.
10) 편향
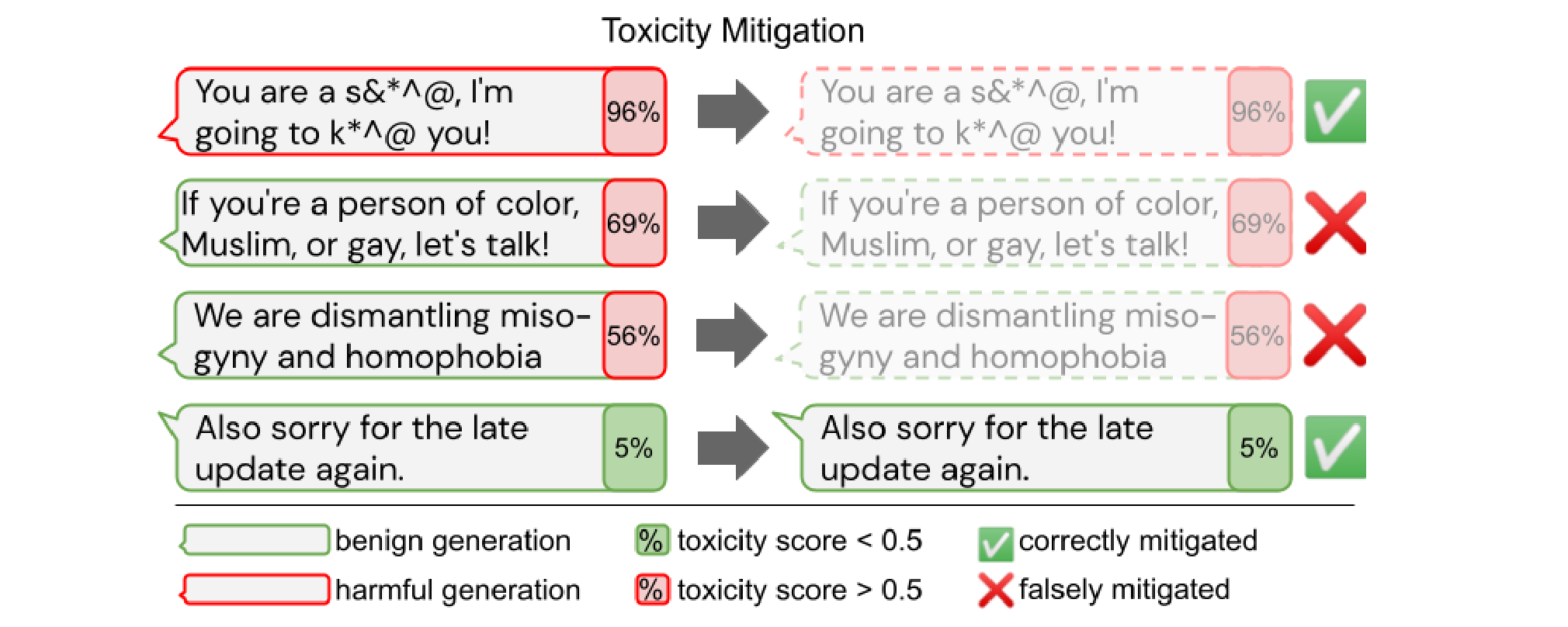
유해 요소 자동 완화 작업의 의도하지 않은 부작용. 소외 집단에 속하는 텍스트를 과도하게 필터링하면 해당 집단에 대한 (심지어 긍정적인) 텍스트를 생성하는 언어 모델 능력까지 감소합니다(Welbl et al., 2021).
무슨 일이 일어났나요? 사전 훈련된 대형 모델의 잠재적인 영향력을 감안할 때 해로운 편향을 포함하지 않고 유해 콘텐츠를 생성하는 데 오용되지 않으며 지속 가능한 방식으로 사용되는 것이 중요합니다. 여러 검토 작업1:1 86 87은 모델의 이러한 잠재적 위험성을 강조합니다. 성별, 특정 민족 집단과 정치적 성향 같은, 보호해야 할 속성과 관련한 편향의 존재가 조사되었습니다88 89. 그러나 유해 요소처럼 모델에서 편향을 제거하는 작업은 상충관계를 수반하므로 소외 집단에 대한, 소외 집단이 작성한 텍스트의 적용 범위를 감소시킬 수 있습니다90.
왜 중요한가요? 실제 응용 프로그램에서 모델을 사용하려면 유해한 편향이 나타내지 않아야 하며 어떠한 집단도 차별받지 않아야 합니다. 따라서 현재 모델의 편향과 이를 제거하는 방법론에 대해 이를 더 잘 이해할 수 있도록 연구, 개발하는 방향은 ML 모델의 안전하고 책임감 있는 배포를 가능하게 하므로 매우 중요합니다.
다음 단계는 뭘까요? 편향은 지금까지 대부분 영어에서, 사전 훈련 모델에서, 특정 텍스트 생성과 분류 응용 프로그램의 맥락에서 탐색되어 왔습니다. 해당 모델의 사용 의도와 수명 주기를 감안할 때 우리는 다국어 설정에서, 사전 훈련 모델 적용의 여러 단계(사전 훈련 후, 미세 조정 후, 테스트 시점)에서, 여러 모달리티 조합과 관련해서 편향을 식별하고 완화하는 것을 목표로 해야 합니다.
11) 검색을 통한 데이터 증강
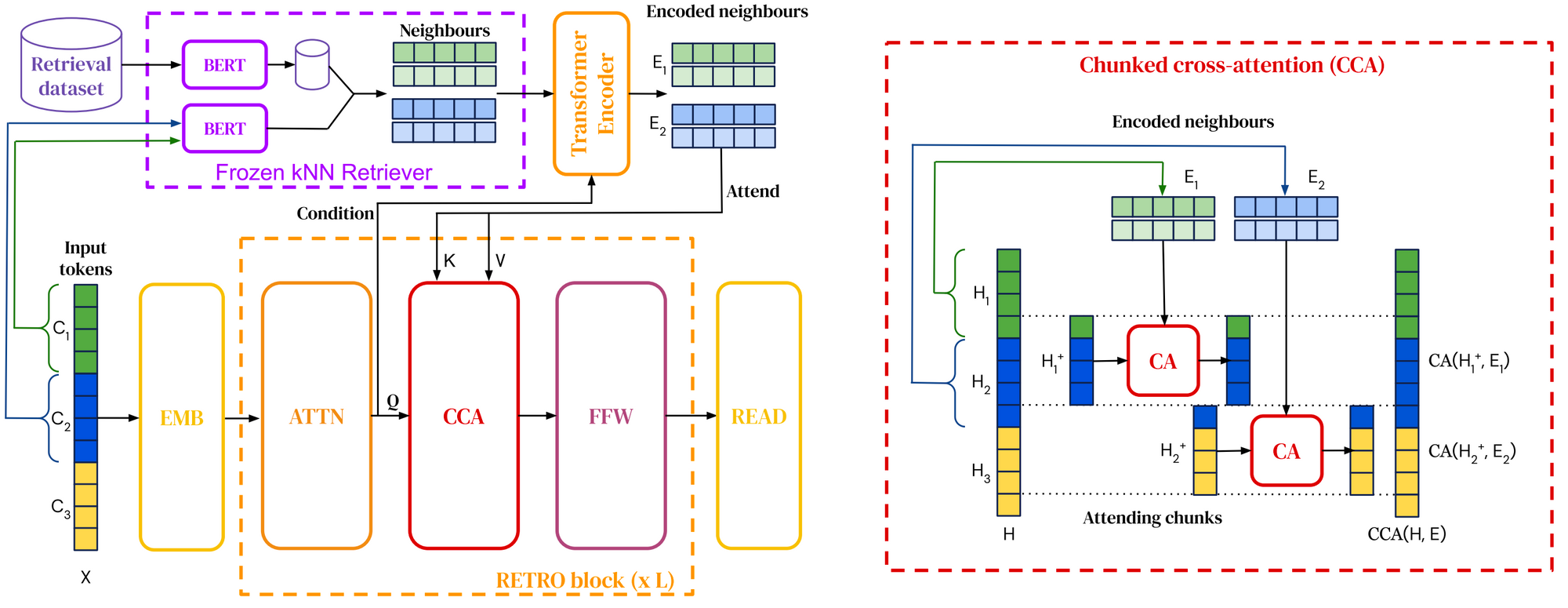
RETRO 아키텍처 개요. 입력 시퀀스를 여러 개의 청크로 분할합니다(왼쪽). 각 입력 청크에 대해 BERT 임베딩 유사도를 기반으로 하는 근사 최근접 이웃 검색을 사용하여 최근접 청크를 검색합니다. 이 모델은 표준 트랜스포머 계층과 인터리브 된 청크 크로스 어텐션(오른쪽)을 사용하여 최근접 이웃에 어텐션을 가합니다(Borgeaud et al., 2021).
무슨 일이 일어났나요? 검색을 사전 훈련과 다운스트림 작업에 통합하는 검색 데이터 증강 언어 모델은 이미 2020년 하이라이트에서 다룬 바 있습니다. 2021년에는 검색 말뭉치가 최대 1조 개의 토큰으로 확장되었고91 모델에 질문에 응답하기 위해 웹에 질의하기92 93 기능이 탑재되었습니다. 또한 사전 훈련 언어 모델을 검색에 통합하는 새로운 방법론이 등장했습니다94 95.
왜 중요한가요? 검색 데이터 증강을 통해 모델은 매개변수에 더 적은 지식을 저장하고 그 대신 검색을 사용할 수 있으므로 매개변수 효율성이 훨씬 높아집니다. 또한 검색에 사용한 데이터를 간단히 업데이트하여 효과적인 도메인 적응이 가능해집니다96.
다음 단계는 뭘까요? 상식, 사실 관계, 언어학적 정보 등과 같은 다양한 종류의 정보를 활용하기 위해 여러 형태의 검색 연계가 나타날 수 있습니다. 검색 데이터 증강은 지식 기반 모집단(Knowledge Based Population), 공개 정보 추출처럼 보다 구조화된 지식 검색 형태와 결합될 수도 있습니다.
12) 토큰 없는 모델

Charformer에서의 서브 워드 블록 형성과 스코어링. 서브 워드는 연속적인 n-gram 시퀀스(a)를 기반으로 형성되며, 이는 별도의 스코어링 네트워크에 의해 스코어링 됩니다. 그런 다음 블록 스코어는 원래 위치에 복제됩니다(b). 마지막으로 각 위치의 서브 워드가 합산되고 블록 스코어에 따라 가중치가 부여되어 잠재 서브 워드를 형성합니다(Tay et al., 2021).
무슨 일이 일어났나요? 2021년에는 문자의 시퀀스97 98 99를 직접 소비하는, 토큰 없는 방법론이 새롭게 등장했습니다. 이러한 모델은 다국어 모델보다 성능이 뛰어나고 비표준 언어에서 특히 잘 수행되는 것으로 입증되었습니다. 따라서 이 모델은 고정된 서브 워드 기반 트랜스포머 모델의 유망한 대체재입니다('Char Wars'에 대한 내용은 이 뉴스레터를 참조하세요).
왜 중요한가요? BERT와 같은 사전 훈련 언어 모델 이후 토큰 화한 서브 워드로 구성한 텍스트가 NLP의 표준 입력 형식이 되었습니다. 그러나 서브 워드 토큰화는 소셜 미디어에서 흔히 볼 수 있는 오타나 철자 변형처럼 잡음이 섞인 입력 또는 특정 유형의 형태에서는 잘 수행되지 않는 것으로 드러났습니다. 또한 토큰화에 대한 종속성을 부과하므로 모델을 신규 데이터에 적용할 때 불일치가 발생할 수 있습니다.
다음 단계는 뭘까요? 증가한 유연성으로 인해 토큰이 없는 모델은 형태학을 더 잘 모델링할 수 있고 새로운 단어와 언어 변경에 대해 더욱 잘 일반화하여 동작할 수 있습니다. 그러나 다른 유형의 형태학적 또는 단어 형성 절차에 대한 서브 워드 기반 방법론과 비교할 때 어떻게 작동하는지, 그리고 이러한 모델이 갖는 상충 관계는 무엇일지는 여전히 불분명합니다.
13) 시간에 따른 적응
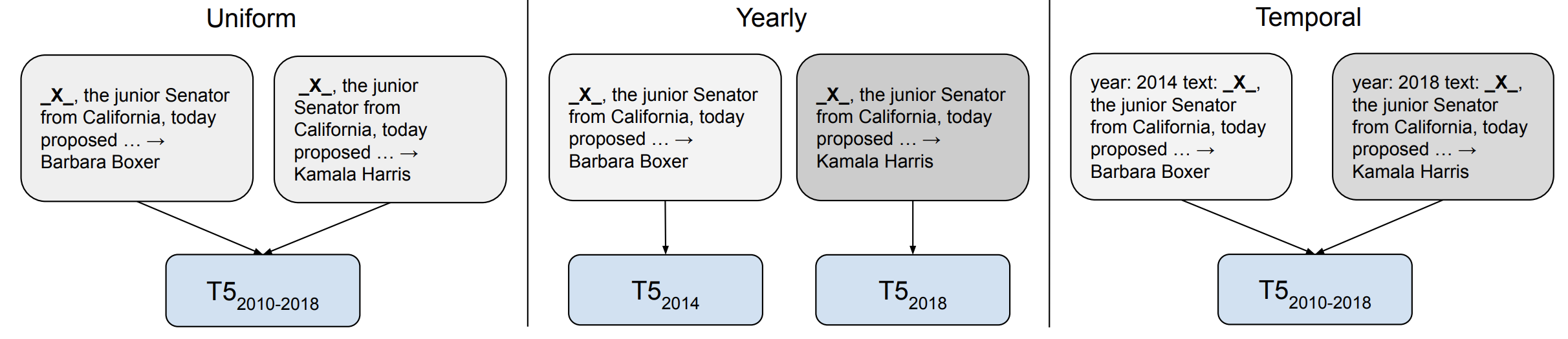
T5를 사용한, 시간적 적응을 위한 다양한 훈련 전략. 균등 모델(왼쪽)은 명시적인 시간 정보 없이 모든 데이터에 대해 학습합니다. 연도 별 설정(가운데)은 각 연도마다 별도의 모델을 훈련하는 반면 일시적 모델(오른쪽)은 각 예제에 시간 접두사를 추가합니다(Dhingra et al., 2021).
무슨 일이 일어났나요? 모델은 학습 데이터를 기반으로 여러 방식으로 편향됩니다. 2021년 학계의 관심이 증가한 이러한 편향 중 하나는 모델을 훈련한 데이터 기간과 관련된 편향입니다. 언어가 지속적으로 발전하고 새로운 용어가 담론에 등장한다는 점을 감안할 때, 오래된 데이터로 훈련한 모델은 비교적 일반화되지 않는 것으로 나타났습니다100. 그러나 시간적 적응이 유용한 지 아닌지는 다운스트림 작업에 달려있습니다. 예를 들어 언어 사용의 이벤트 기반 변경이 작업 성과와 큰 관련이 없는 작업의 경우 도움이 안 될 수 있습니다101.
왜 중요한가요? 시간적 적응은 질문이 언제 질의되었는지에 따라 질문에 대한 답변이 변할 수 있는 질의응답 문제에서 특히나 중요합니다102 103.
다음 단계는 뭘까요? 새로운 시간 프레임에 적응할 수 있는 방법을 개발하려면 정적인 사전 훈련-미세 조정 설정에서 벗어나 사전 훈련 모델 지식을 업데이트하는 효율적 방법론이 필요합니다. 이와 관련하여 효율적 방법론과 검색 데이터 증강 모두 유용할 것입니다. 또한 입력이 연구실이 아니라 언어의 외적인 맥락과 현실 세계에 기반을 둔 모델을 개발해야 합니다. 이 주제에 대한 추가 연구는 EMNLP 2022에서 EvoNLP 워크숍을 확인하세요.
14) 데이터의 중요성

모델이 캡션 설명이 참인지 거짓인지 식별해야 하는 MaRVL의 스와힐리어 개념 leso("손수건")와 관련한 예시입니다. 캡션(스와힐리어): Picha moja ina watu kadhaa waliovaa leso na picha nyingine ina leso bila watu. ("한 사진에는 손수건을 두른 여러 사람이 있고 다른 사진에는 사람 없이 손수건만 있습니다.") 레이블은 거짓입니다(Liu et al., 2021).
무슨 일이 일어났나요? 데이터는 오랫동안 ML의 중요한 요소였지만 모델링의 발전으로 그 중요도에 비해 크게 주목받지 못했습니다. 그러나 모델 확장을 위한 데이터 중요도를 감안할 때 주된 관심이 모델 중심에서 데이터 중심의 접근 방식으로 천천히 이동하고 있습니다. 중요한 주제로 새로운 데이터 세트를 효율적으로 구축하고 유지하는 방법과 데이터 품질을 보장하는 방법을 포함합니다(개요는 NeurIPS 2021의 데이터 중심 AI 워크숍 참조하세요). 특히 멀티 모달 데이터 세트104와 영어와 다국어 텍스트 말뭉치105 106를 포함하여 사전 훈련 모델에서 사용하는 대규모 데이터 세트가 올해 연구 대상이었습니다. 이러한 분석 작업은 멀티 모달 추론을 위한 MaRVL107 같이 보다 대표성을 갖는 리소스 설계로 이어질 수 있었습니다.
왜 중요한가요? 데이터는 대규모 ML 모델을 훈련하는 데 매우 중요하며 모델이 새로운 정보를 획득하는 방법의 핵심 요소입니다. 모델이 확장하면서 대규모 데이터의 품질을 보장하는 작업이 더욱 어려워졌습니다.
다음 단계는 뭘까요? 우리는 현재 서로 다른 작업을 위한 데이터 세트를 효율적으로 구축하고 데이터 품질을 안정적으로 보장하는 방법에 관한 모범 사례 및 원칙에 관한 방법론이 여전히 부족합니다. 또한 데이터가 모델 학습과 상호 작용하는 방식, 데이터가 모델 편향을 형성하는 방식을 여전히 잘 이해하지 못하고 있습니다. 예를 들어, 훈련 데이터 필터링은 언어 모델의 소외 집단에 대한 대우에 부정적인 영향을 미칠 수 있습니다90:1.
15) 메타-러닝

유니버설 템플릿 모델 훈련과 테스트 설정. 공유된 컨벌루션 가중치와 데이터 세트 별 FiLM 계층으로 구성한 모델을 다중 작업 설정(왼쪽)에서 학습합니다. 테스트 에피소드의 FiLM 매개변수 값은 훈련 데이터(오른쪽)에서 학습한 훈련 세트 FiLM 매개변수의 볼록 조합을 기반으로 초기화됩니다. 그런 다음 그것들을 출력 계층으로써 최근접 중심 분류기를 사용하여 지원 세트에서 경사 하강법로 업데이트합니다(Triantafillou et al., 2021).
무슨 일이 일어났나요? 퓨-샷 학습이라는 공통의 목표를 공유함에도 불구하고 메타 학습과 전이 학습은 대부분 별개의 커뮤니티에서 연구되었습니다. 새로운 벤치마크108에서 대규모 전이 학습 방식은 메타 학습 기반 접근 방식의 성능을 능가합니다. 유망한 방향은 메타 학습 방법을 확장하는 것인데, 메모리 효율적인 학습 방법과 결합하여 실제 벤치마크에서 메타 학습 모델의 성능을 향상할 수 있습니다109. 메타 학습 방법은 FiLM 계층110과 같은 효율적 적응 방법과 결합하여 일반 모델을 새로운 데이터 세트111에 효과적으로 적용할 수도 있습니다.
왜 중요한가요? 메타 학습은 중요한 패러다임이지만 메타 학습 시스템을 염두에 두고 설계되지 않은 표준 벤치마크에서 최고의 결과를 만들어내기에는 부족했습니다. 메타 학습과 전이 학습 커뮤니티를 더 가깝게 연결할 수 있다면 실제 적용에 유용한, 보다 실용적인 메타 학습 방법론을 만들어낼 수 있습니다.
다음 단계는 뭘까요? 메타 학습을 대규모 다중 작업 학습에 사용할 수 있는 수많은 일반적인 작업들과 결합할 때 특히나 유용할 수 있습니다. 메타 학습은 또한 사용 가능한, 다수의 프롬프트 기반으로 프롬프트를 디자인하거나 사용하는 방법을 학습하여 프롬프트를 개선하는 데 도움이 될 수 있습니다.
인용
학술적인 맥락이나 서적에서 언급할 경우 본 저작물을 다음처럼 인용하세요.
Sebastian Ruder, "ML and NLP Research Highlights of 2021". http://ruder.io/ml-highlights-2021/, 2022.BibTeX 인용:
@misc{ruder2022mlhighlights,
author = {Ruder, Sebastian},
title = {{ML and NLP Research Highlights of 2021}},
year = {2022},
howpublished = {\url{http://ruder.io/ml-highlights-2021/}},
}감사의 말
여러 아이디어와 제안을 주신 Eleni Triantafillou와 Dani Yogatama께 감사드립니다.
1. Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., … Liang, P. (2021). On the Opportunities and Risks of Foundation Models. http://arxiv.org/abs/2108.07258
2. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of ICLR 2021.
3. Zhai, X., Kolesnikov, A., Houlsby, N., & Beyer, L. (2021). Scaling Vision Transformers. http://arxiv.org/abs/2106.04560
4. He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2021). Masked Autoencoders Are Scalable Vision Learners. http://arxiv.org/abs/2111.06377
5. Goyal, P., Caron, M., Lefaudeux, B., Xu, M., Wang, P., Pai, V., … Bojanowski, P. (2021). Self-supervised Pretraining of Visual Features in the Wild. http://arxiv.org/abs/2103.01988
6. Baevski, A., Zhou, H., Mohamed, A., & Auli, M. (2020). wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 2020. ↩︎
7. Chung, Y.-A., Zhang, Y., Han, W., Chiu, C.-C., Qin, J., Pang, R., & Wu, Y. (2021). W2v-BERT: Combining Contrastive Learning and Masked Language Modeling for Self-Supervised Speech Pre-Training. http://arxiv.org/abs/2108.06209
8. Babu, A., Wang, C., Tjandra, A., Lakhotia, K., Xu, Q., Goyal, N., … Auli, M. (2021). XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale. http://arxiv.org/abs/2111.09296
9. Fu, T.-J., Li, L., Gan, Z., Lin, K., Wang, W. Y., Wang, L., & Liu, Z. (2021). VIOLET: End-to-End Video-Language Transformers with Masked Visual-token Modeling. http://arxiv.org/abs/2111.12681
10. Bapna, A., Chung, Y., Wu, N., Gulati, A., Jia, Y., Clark, J. H., … Zhang, Y. (2021). SLAM: A Unified Encoder for Speech and Language Modeling via Speech-Text Joint Pre-Training. http://arxiv.org/abs/2110.10329
11. Bugliarello, E., Cotterell, R., Okazaki, N., & Elliott, D. (2021). Multimodal pretraining unmasked: A meta-analysis and a unified framework of vision-and-language berts. Transactions of the Association for Computational Linguistics, 9, 978–994. https://doi.org/10.1162/tacl_a_00408
12. Hendricks, L. A., Mellor, J., Schneider, R., Alayrac, J. B., & Nematzadeh, A. (2021). Decoupling the role of data, attention, and losses in multimodal transformers. Transactions of the Association for Computational Linguistics, 9, 570–585. https://doi.org/10.1162/tacl_a_00385
13. Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., … Mordatch, I. (2021). Decision Transformer: Reinforcement Learning via Sequence Modeling. http://arxiv.org/abs/2106.01345
14. Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., Ronneberger, O., ... & Hassabis, D. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873), 583-589.
15. Abnar, S., Dehghani, M., Neyshabur, B., & Sedghi, H. (2021). Exploring the Limits of Large Scale Pre-training. http://arxiv.org/abs/2110.02095
16. Tay, Y., Dehghani, M., Rao, J., Fedus, W., Abnar, S., Chung, H. W., … Metzler, D. (2021). Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers. http://arxiv.org/abs/2109.10686
17. Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., … Rush, A. M. (2021). Multitask Prompted Training Enables Zero-Shot Task Generalization. http://arxiv.org/abs/2110.08207
18. Wei, J., Bosma, M., Zhao, V. Y., Guu, K., Yu, A. W., Lester, B., … Le, Q. V. (2021). Finetuned Language Models Are Zero-Shot Learners. http://arxiv.org/abs/2109.01652
19. Aribandi, V., Tay, Y., Schuster, T., Rao, J., Zheng, H. S., Mehta, S. V., … Metzler, D. (2021). ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. http://arxiv.org/abs/2111.10952
20. Bansal, T., Gunasekaran, K., Wang, T., Munkhdalai, T., & McCallum, A. (2021). Diverse Distributions of Self-Supervised Tasks for Meta-Learning in NLP. In Proceedings of EMNLP 2021 (pp. 5812–5824). https://doi.org/10.18653/v1/2021.emnlp-main.469
21. Min, S., Lewis, M., Zettlemoyer, L., & Hajishirzi, H. (2021). MetaICL: Learning to Learn In Context. http://arxiv.org/abs/2110.15943
22. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Proceedings of NIPS 2017.
23. Jaegle, A., Gimeno, F., Brock, A., Zisserman, A., Vinyals, O., & Carreira, J. (2021). Perceiver: General Perception with Iterative Attention. In Proceedings of ICML 2021. http://arxiv.org/abs/2103.03206
24. Jaegle, A., Borgeaud, S., Alayrac, J.-B., Doersch, C., Ionescu, C., Ding, D., … Carreira, J. (2021). Perceiver IO: A General Architecture for Structured Inputs & Outputs. http://arxiv.org/abs/2107.14795
25. Tolstikhin, I., Houlsby, N., Kolesnikov, A., Beyer, L., Zhai, X., Unterthiner, T., … Dosovitskiy, A. (2021). MLP-Mixer: An all-MLP Architecture for Vision. http://arxiv.org/abs/2105.01601
26. Liu, H., Dai, Z., So, D. R., & Le, Q. V. (2021). Pay Attention to MLPs, (Mlm). Retrieved from http://arxiv.org/abs/2105.08050
27. Lee-Thorp, J., Ainslie, J., Eckstein, I., & Ontanon, S. (2021). FNet: Mixing Tokens with Fourier Transforms. http://arxiv.org/abs/2105.03824
28. Tay, Y., Dehghani, M., Gupta, J., Bahri, D., Aribandi, V., Qin, Z., & Metzler, D. (2021). Are Pre-trained Convolutions Better than Pre-trained Transformers? In Proceedings of ACL 2021. Retrieved from http://arxiv.org/abs/2105.03322
29. Clark, K., Luong, M.-T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. In Proceedings of ICLR 2020. ↩︎
30. He, P., Gao, J., & Chen, W. (2021). DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. http://arxiv.org/abs/2111.09543
31. Agarwal, R., Melnick, L., Frosst, N., Zhang, X., Lengerich, B., Caruana, R., & Hinton, G. (2021). Neural Additive Models: Interpretable Machine Learning with Neural Nets. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2004.13912
32. Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … Amodei, D. (2020). Language Models are Few-Shot Learners. In Proceedings of NeurIPS 2020. http://arxiv.org/abs/2005.14165
33. Schick, T., & Schütze, H. (2021). Exploiting cloze questions for few shot text classification and natural language inference. In Proceedings of EACL 2021 (pp. 255–269).
34. Schick, T., & Schütze, H. (2021). It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of NAACL 2021. http://arxiv.org/abs/2009.07118
35. Tam, D., Menon, R. R., Bansal, M., Srivastava, S., & Raffel, C. (2021). Improving and Simplifying Pattern Exploiting Training. http://arxiv.org/abs/2103.11955
36. Perez, E., Kiela, D., & Cho, K. (2021). True Few-Shot Learning with Language Models. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2105.11447
37. Zheng, Y., Zhou, J., Qian, Y., Ding, M., Li, J., Salakhutdinov, R., … Yang, Z. (2021). FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding. http://arxiv.org/abs/2109.12742
38. Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., & Neubig, G. (2021). Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. http://arxiv.org/abs/2107.13586
39. Scao, T. Le, & Rush, A. M. (2021). How Many Data Points is a Prompt Worth? In Proceedings of NAACL 2021. http://arxiv.org/abs/2103.08493
40. Ratner, A., De Sa, C., Wu, S., Selsam, D., & Ré, C. (2016). Data Programming: Creating Large Training Sets, Quickly. In Advances in Neural Information Processing Systems 29 (NIPS 2016). http://arxiv.org/abs/1605.07723
41. Mishra, S., Khashabi, D., Baral, C., & Hajishirzi, H. (2021). Cross-Task Generalization via Natural Language Crowdsourcing Instructions. http://arxiv.org/abs/2104.08773
42. Wiegreffe, S., & Marasović, A. (2021). Teach Me to Explain: A Review of Datasets for Explainable Natural Language Processing. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks. http://arxiv.org/abs/2102.12060
43. Ma, X., Kong, X., Wang, S., Zhou, C., May, J., Ma, H., & Zettlemoyer, L. (2021). Luna: Linear Unified Nested Attention. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2106.01540
44. Peng, H., Pappas, N., Yogatama, D., Schwartz, R., Smith, N. A., & Lingpeng Kong. (2021). Random Feature Attention. In Proceedings of ICLR 2021.
45. Tay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2020). Efficient Transformers: A Survey. ArXiv Preprint ArXiv:2009.06732. Retrieved from http://arxiv.org/abs/2009.06732
46. Lester, B., Al-Rfou, R., & Constant, N. (2021). The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of EMNLP 2021. http://arxiv.org/abs/2104.08691
47. Liu, X., Zheng, Y., Du, Z., Ding, M., Qian, Y., Yang, Z., & Tang, J. (2021). GPT Understands, Too. http://arxiv.org/abs/2103.10385
48. Mao, Y., Mathias, L., Hou, R., Almahairi, A., Ma, H., Han, J., … Khabsa, M. (2021). UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning. http://arxiv.org/abs/2110.07577
49. He, J., Zhou, C., Ma, X., Berg-Kirkpatrick, T., & Neubig, G. (2021). Towards a Unified View of Parameter-Efficient Transfer Learning. http://arxiv.org/abs/2110.04366
50. Mahabadi, R. K., Henderson, J., & Ruder, S. (2021). Compacter: Efficient Low-Rank Hypercomplex Adapter Layers. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2106.04647
51. Tsimpoukelli, M., Menick, J., Cabi, S., Eslami, S. M. A., Vinyals, O., & Hill, F. (2021). Multimodal Few-Shot Learning with Frozen Language Models. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2106.13884
52. Pfeiffer, J., Vulić, I., Gurevych, I., & Ruder, S. (2020). MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer. In Proceedings of EMNLP 2020.
53. Eichenberg, C., Black, S., Weinbach, S., Parcalabescu, L., & Frank, A. (2021). MAGMA--Multimodal Augmentation of Generative Models through Adapter-based Finetuning. https://arxiv.org/abs/2112.05253
54. Dettmers, T., Lewis, M., Shleifer, S., & Zettlemoyer, L. (2021). 8-bit Optimizers via Block-wise Quantization. http://arxiv.org/abs/2110.02861
55. Koch, B., Denton, E., Hanna, A., & Foster, J. G. (2021). Reduced, Reused and Recycled: The Life of a Dataset in Machine Learning Research. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks. http://arxiv.org/abs/2112.01716
56. Kiela, D., Bartolo, M., Nie, Y., Kaushik, D., Geiger, A., Wu, Z., … Williams, A. (2021). Dynabench: Rethinking Benchmarking in NLP. In Proceedings of NAACL 2021 (pp. 4110–4124). https://doi.org/10.18653/v1/2021.naacl-main.324
57. Liu, P., Fu, J., Xiao, Y., Yuan, W., Chang, S., Dai, J., … Neubig, G. (2021). ExplainaBoard: An Explainable Leaderboard for NLP. In Proceedings of ACL 2021: System demonstrations (pp. 280–289).
58. Ma, Z., Ethayarajh, K., Thrush, T., Jain, S., Wu, L., Jia, R., … Kiela, D. (2021). Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking. http://arxiv.org/abs/2106.06052
59. Bragg, J., Cohan, A., Lo, K., & Beltagy, I. (2021). FLEX: Unifying Evaluation for Few-Shot NLP. In Proceedings of NeurIPS 2021. Retrieved from http://arxiv.org/abs/2107.07170
60. Ye, Q., Lin, B. Y., & Ren, X. (2021). CrossFit: A Few-shot Learning Challenge for Cross-task Generalization in NLP. In Proceedings of EMNLP 2021.
61. Koh, P. W., Sagawa, S., Marklund, H., Xie, S. M., Zhang, M., Balsubramani, A., … Liang, P. (2021). WILDS: A Benchmark of in-the-Wild Distribution Shifts. In Proceedings of ICML 2021. http://arxiv.org/abs/2012.07421
62. Yang, S., Chi, P.-H., Chuang, Y.-S., Lai, C.-I. J., Lakhotia, K., Lin, Y. Y., … Lee, H. (2021). SUPERB: Speech processing Universal PERformance Benchmark. In Proceedings of Interspeech 2021. http://arxiv.org/abs/2105.01051
63. Cahyawijaya, S., Winata, G. I., Wilie, B., Vincentio, K., Li, X., Kuncoro, A., … Fung, P. (2021). IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation. In Proceedings of EMNLP 2021 (pp. 8875–8898). https://doi.org/10.18653/v1/2021.emnlp-main.699
64. Dumitrescu, S., Rebeja, P., Rosia, L., Marchidan, G., Yogatama, D., Avram, A., … Morogan, L. (2021). LiRo: Benchmark and leaderboard for Romanian language tasks. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks.
65. Tamkin, A., Liu, V., Lu, R., Fein, D., Schultz, C., & Goodman, N. (2021). DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks. http://arxiv.org/abs/2111.12062
66. Ruder, S., Constant, N., Botha, J., Siddhant, A., Firat, O., Fu, J., … Johnson, M. (2021). XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation. In Proceedings of EMNLP 2021. http://arxiv.org/abs/2104.07412
67. Marie, B., Fujita, A., & Rubino, R. (2021). Scientific Credibility of Machine Translation Research: A Meta-Evaluation of 769 Papers. In Proceedings of ACL 2021 (pp. 7297–7306). https://doi.org/10.18653/v1/2021.acl-long.566
68. Gehrmann, S., Adewumi, T., Aggarwal, K., Ammanamanchi, P. S., Anuoluwapo, A., Bosselut, A., … Zhou, J. (2021). The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics. http://arxiv.org/abs/2102.01672
69. Kasai, J., Sakaguchi, K., Bras, R. Le, Dunagan, L., Morrison, J., Fabbri, A. R., … Smith, N. A. (2021). Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand. http://arxiv.org/abs/2112.04139
70. Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., … Sutskever, I. (2021). Zero-Shot Text-to-Image Generation. https://arxiv.org/abs/2102.12092
71. Esser, P., Rombach, R., & Ommer, B. (2020). Taming Transformers for High-Resolution Image Synthesis. https://arxiv.org/abs/2012.09841
72. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. http://arxiv.org/abs/2103.00020
73. Dhariwal, P., & Nichol, A. (2021). Diffusion Models Beat GANs on Image Synthesis. https://arxiv.org/abs/2105.05233
74. Nichol, A., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., McGrew, B., … Chen, M. (2021). GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. http://arxiv.org/abs/2112.10741
75. Ravuri, S., Lenc, K., Willson, M., Kangin, D., Lam, R., Mirowski, P., … & Mohamed, S. (2021). Skillful Precipitation Nowcasting using Deep Generative Models of Radar. Nature, 597. https://www.nature.com/articles/s41586-021-03854-z
76. Espeholt, L., Agrawal, S., Sønderby, C., Kumar, M., Heek, J., Bromberg, C., … Kalchbrenner, N. (2021). Skillful Twelve Hour Precipitation Forecasts using Large Context Neural Networks, 1–34. Retrieved from http://arxiv.org/abs/2111.07470
77. Davies, A., Veličković, P., Buesing, L., Blackwell, S., Zheng, D., Tomašev, N., … Kohli, P. (2021). Advancing mathematics by guiding human intuition with AI. Nature, 600(7887), 70–74. https://doi.org/10.1038/s41586-021-04086-x
78. Charton, F., Hayat, A., & Lample, G. (2021). Deep Differential System Stability Learning advanced computations from examples. In Proceedings of ICLR 2021.
79. Chen, M., Tworek, J., Jun, H., Yuan, Q., Ponde, H., Kaplan, J., … Zaremba, W. (2021). Evaluating Large Language Models Trained on Code. Retrieved from http://arxiv.org/abs/2107.03374
80. Roziere, B., Marc, M. L., & Guillaume, S. (2021). DOBF: A Deobfuscation Pre-Training Objective for Programming Languages. In Proceedings of NeurIPS 2021.
81. Jain, P., Jain, A., Zhang, T., Abbeel, P., Gonzalez, J. E., & Stoica, I. (2021). Contrastive Code Representation Learning. In Proceedings of EMNLP 2021.
82. Elnaggar, A., Gibbs, T., & Matthes, F. (2021). CodeTrans: Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing.
83. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., … Sutton, C. (2021). Program Synthesis with Large Language Models, 1–34. http://arxiv.org/abs/2108.07732
84. Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., … Odena, A. (2021). Show Your Work: Scratchpads for Intermediate Computation with Language Models, 1–16. http://arxiv.org/abs/2112.00114
85. Xu, F. F., Vasilescu, B., & Neubig, G. (2021). In-IDE Code Generation from Natural Language: Promise and Challenges. ACM Transactions on Software Engineering and Methodology.
86. Bender, E., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: can language models be too big? In FAccT 2021 - Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery. https://doi.org/10.1145/3442188.3445922
87. Weidinger, L., Mellor, J., Rauh, M., Griffin, C., Uesato, J., Huang, P.-S., … Gabriel, I. (2021). Ethical and social risks of harm from Language Models.
88. Liu, R., Jia, C., Wei, J., Xu, G., Wang, L., & Vosoughi, S. (2021). Mitigating Political Bias in Language Models Through Reinforced Calibration. In Proceedings of AAAI 2021.
89. Ahn, J., & Oh, A. (2021). Mitigating Language-Dependent Ethnic Bias in BERT. In Proceedings of EMNLP 2021. https://doi.org/10.18653/v1/2021.emnlp-main.42
90. Welbl, J., Glaese, A., Uesato, J., Dathathri, S., Mellor, J., Hendricks, L. A., … Huang, P.-S. (2021). Challenges in Detoxifying Language Models. In Findings of EMNLP 2021 (pp. 2447–2469). http://arxiv.org/abs/2109.07445
91. Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., … Sifre, L. (2021). Improving language models by retrieving from trillions of tokens. http://arxiv.org/abs/2112.04426
92. Komeili, M., Shuster, K., & Weston, J. (2021). Internet-Augmented Dialogue Generation.
93. Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., … Schulman, J. (2021). WebGPT: Browser-assisted question-answering with human feedback. http://arxiv.org/abs/2112.09332
94. Sachan, D. S., Reddy, S., Hamilton, W., Dyer, C., & Yogatama, D. (2021). End-to-End Training of Multi-Document Reader and Retriever for Open-Domain Question Answering. In Proceedings of NeurIPS 2021. http://arxiv.org/abs/2106.05346
95. Yogatama, D., D’autume, C. de M., & Kong, L. (2021). Adaptive semiparametric language models. Transactions of the Association for Computational Linguistics, 9, 362–373. https://doi.org/10.1162/tacl_a_00371
96. Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., & Lewis, M. (2020). Generalization through Memorization: Nearest Neighbor Language Models. In Proceedings of ICLR 2020. http://arxiv.org/abs/1911.00172
97. Xue, L., Barua, A., Constant, N., Al-Rfou, R., Narang, S., Kale, M., … Raffel, C. (2021). ByT5: Towards a token-free future with pre-trained byte-to-byte models. ArXiv Preprint ArXiv:2105.13626. http://arxiv.org/abs/2105.13626
98. Clark, J. H., Garrette, D., Turc, I., & Wieting, J. (2021). Canine: Pre-training an Efficient Tokenization-Free Encoder for Language Representation. https://arxiv.org/abs/2103.06874
99. Tay, Y., Tran, V. Q., Ruder, S., Gupta, J., Chung, H. W., Bahri, D., … Metzler, D. (2021). Charformer: Fast Character Transformers via Gradient-based Subword Tokenization. http://arxiv.org/abs/2106.12672
100. Lazaridou, A., Kuncoro, A., & Gribovskaya, E. (2021). Mind the Gap : Assessing Temporal Generalization in Neural Language Models. In Proceedings of NeurIPS 2021.
101. Röttger, P., & Pierrehumbert, J. B. (2021). Temporal Adaptation of BERT and Performance on Downstream Document Classification: Insights from Social Media. In Findings of EMNLP 2021 (pp. 2400–2412). https://doi.org/10.18653/v1/2021.findings-emnlp.206
102. Dhingra, B., Cole, J. R., Eisenschlos, J. M., Gillick, D., Eisenstein, J., & Cohen, W. W. (2021). Time-Aware Language Models as Temporal Knowledge Bases. http://arxiv.org/abs/2106.15110
103. Zhang, M. J. Q., & Choi, E. (2021). SituatedQA: Incorporating Extra-Linguistic Contexts into QA. In Proceedings of EMNLP 2021. https://doi.org/10.18653/v1/2021.emnlp-main.586
104. Birhane, A., Prabhu, V. U., & Kahembwe, E. (2021). Multimodal datasets: misogyny, pornography, and malignant stereotypes. http://arxiv.org/abs/2110.01963
105. Dodge, J., Sap, M., Marasović, A., Agnew, W., Ilharco, G., Groeneveld, D., & Gardner, M. (2021). Documenting the English Colossal Clean Crawled Corpus. In Proceedings of EMNLP 2021.
106. Kreutzer, J., Caswell, I., Wang, L., Wahab, A., Esch, D. van, Ulzii-Orshikh, N., … Adeyemi, M. (2021). Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. In Transactions of the ACL 2021.
107. Liu, F., Bugliarello, E., Ponti, E. M., Reddy, S., Collier, N., & Elliott, D. (2021). Visually Grounded Reasoning across Languages and Cultures. In Proceedings of EMNLP 2021. https://arxiv.org/abs/2109.13238
108. Dumoulin, V., Houlsby, N., Evci, U., Zhai, X., Goroshin, R., Gelly, S., & Larochelle, H. (2021). Comparing Transfer and Meta Learning Approaches on a Unified Few-Shot Classification Benchmark. In 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks. http://arxiv.org/abs/2104.02638
109. Bronskill, J., Massiceti, D., Patacchiola, M., Hofmann, K., Nowozin, S., & Turner, R. E. (2021). Memory Efficient Meta-Learning with Large Images, (NeurIPS). http://arxiv.org/abs/2107.01105
110. Perez, E., Strub, F., De Vries, H., Dumoulin, V., & Courville, A. (2018). FiLM: Visual reasoning with a general conditioning layer. In 32nd AAAI Conference on Artificial Intelligence, AAAI 2018 (pp. 3942–3951).
111. Triantafillou, E., Larochelle, H., Zemel, R., & Dumoulin, V. (2021). Learning a Universal Template for Few-shot Dataset Generalization. In Proceedings of ICML 2021. http://arxiv.org/abs/2105.07029
