
제가 데이터 과학자, ML 엔지니어로 현업 일을 하면서 조사하고 정리한 AI & ML 컴퓨터 비전 2015년 이후 주요 논문 또는 SOTA급 리스트입니다. 따라서 리서치에서 바라보는 기준과는 다를 수 있습니다. 혹시 제가 놓친, 관련 분야의 중대한 논문이 있다면 댓글로 부탁드리겠습니다. ☺️
- 논문 인용 횟수는 2022년 7월 기준입니다. 주기적으로 업데이트합니다.
- (제가 TF 밖에 모르는 바보라서...) 구현물은 우선 TensorFlow나 TF 호환 라이브러리 기준으로 찾았고 없는 경우 공식 코드 리포지토리 등을 링크했습니다.
1. 공통
- Cosine Decay Schedule with Restarts
- 논문: SGDR: Stochastic Gradient Descent with Warm Restarts (2016년, 3,507회 인용)
- 분류: 훈련 기법, 학습률 스케줄링
- 1줄 요약: 학습률 스케줄을 코사인 곡선 형태로 감소 + 점차 길어지는 주기의 재시작 조건
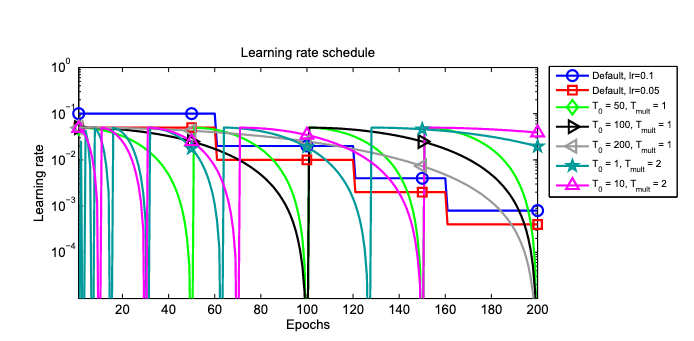
- 구현물: tf.keras.optimizers.schedules.CosineDecayRestarts
- Grad-CAM
- 논문: Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization (2016년, 9,826회 인용)
- 분류: 설명가능성
- 1줄 요약: 입력 이미지를 특정 레이블로 분류하는데 영향을 가장 많이 준 공간적 특성 = 컨볼루션 최종 레이어 피쳐 맵 활성화 값의 채널 별 가중 평균이 큰 지역일수록 (이때 가중치는 활성화 값에 대한 해당 레이블 소프트맥스 인풋 값의 그래디언트입니다.)
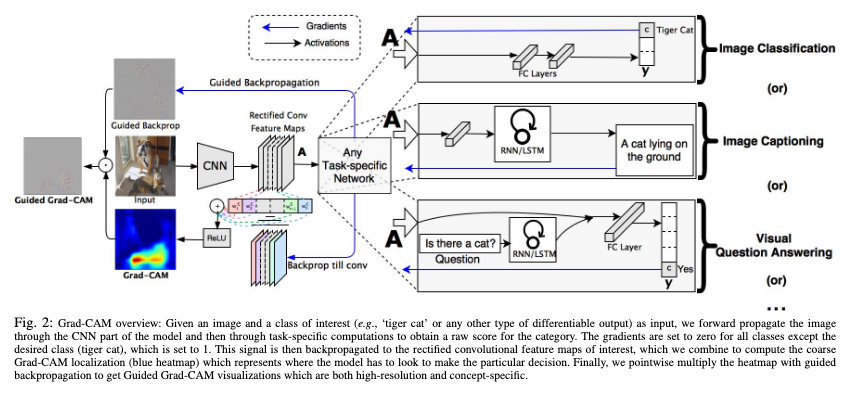
- 구현물: Grad-CAM Class Activation Visualization (Keras 예제)
- Stochastic Depth
- 논문: Deep Networks with Stochastic Depth (2016년, 1,702회 인용)
- 분류: 규제 기법, 드롭아웃
- 1줄 요약: 스킵 연결은 놔두고 레이어의 컨볼루션 변환 연결 쪽을 삭제할지 미니 배치마다 무작위로 결정
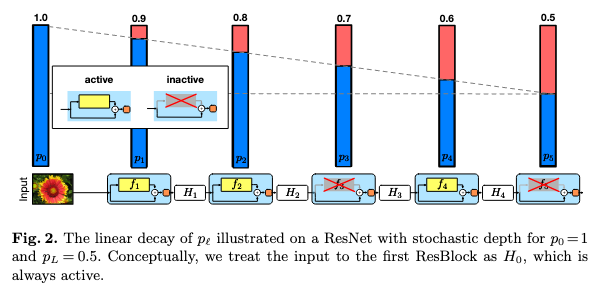
- 구현물: tfa.layers.StochasticDepth
- AdamW & AdamWR
- 논문: Decoupled Weight Decay Regularization (2017년, 3,924회 인용)
- 분류: 훈련 기법, 옵티마이저
- 1줄 요약: ① AdamW: Adam에서 L2 규제 항과 별도로 가중치 감쇠를 한번 더 적용한 것, ② AdamWR: AdamW에서 가중치 감쇠의 크기를 총 파라미터 업데이트 횟수에 비례해 정규화한 것

- 구현물: tfa.optimizers.AdamW
- MixUp
- 논문: mixup: Beyond Empirical RIsk Minimization (2017년, 4,050회 인용)
- 분류: 규제 기법, 데이터 증강
- 1줄 요약: 한 쌍의 이미지 픽셀과 레이블을 가중 평균해서 신규 샘플 생성하는 식으로 모델 학습

- 구현물: MixUp Augmentation for Image Classification (Keras 예제)
- Bag of Tricks
- 논문: Bag of Tricks for Image Classification with Convolutional Neural Networks (2018년, 847회 인용)
- 분류: 기타
- 1줄 요약: (1) 효율적 훈련 기법 ① 배치 크기 ↑이면 학습률 ↑ ② 학습률 웜업 ③ BN의 감마 0으로 초기화 ④ 편향 벡터에 대한 가중치 감쇠 X ⑤ 낮은 정밀도 연산 (2) 모델 개량: ResNet 변종 제안 (3) 정확도 향상 위한 훈련 기법 ① Cosine 학습률 스케줄링 ② LS ③ 지식 증류 ④ mixup
- DropBlock
- 논문: DropBlock: A Regularization Method for Convolutional Networks (2018년, 656회 인용)
- 분류: 규제 기법, 드롭아웃
- 1줄 요약: 피쳐 맵에 대해 미리 정한 개수로 특정 범위를 드롭시킴
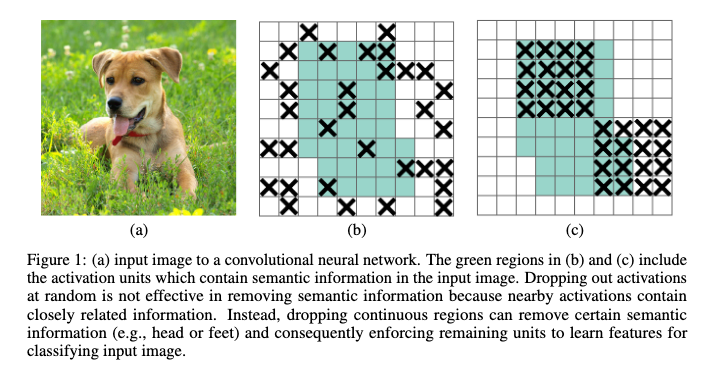
- 구현물: tf.keras.layers.SpatialDropout2D (1D, 3D도 존재)
- Group Normailzation
- 논문: Group Normailzation (2018년, 2,196회 인용)
- 분류: 규제 기법, 정규화
- 1줄 요약: BN의 변종, 배치 단위 아닌 전체 피쳐 맵 × 그룹핑한 채널 단위에 대해 정규화
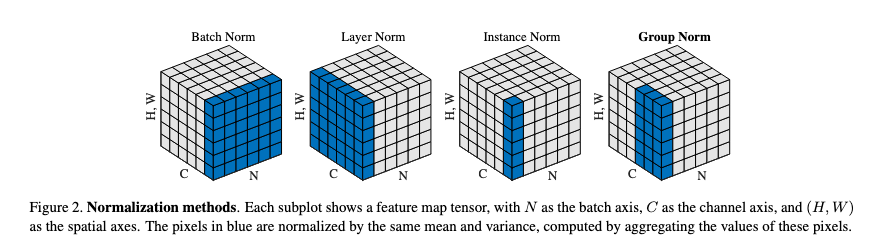
- 구현물: tfa.layers.GroupNormalization
- SWA
- 논문: Averaging Weights Leads to Wider Optima and Better Generalization (2018년, 672회 인용)
- 분류: 훈련 기법, 옵티마이저
- 1줄 요약: 학습 중간 과정에서 얻는 모델 가중치를 계속 이동 평균해나감 → 모델 앙상블 효과

- 구현물: tfa.optimizers.SWA
- CutMix
- 논문: CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (2019년, 1,700회 인용)
- 구분: 규제 기법, 데이터 증강
- 1줄 요약: Cut-and-Paste, 즉 이미지의 일부분을 다른 이미지의 패치로 채워서 신규 샘플 생성 (레이블도 이미지 조합 비율에 따라 가중 평균)
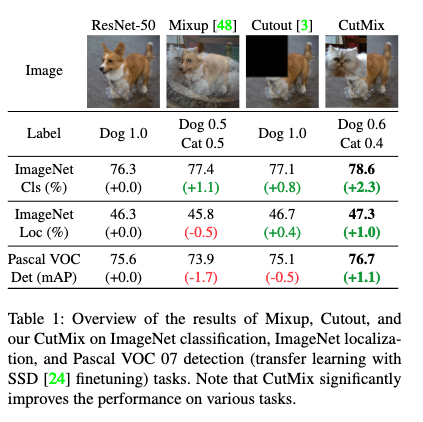
- 구현물: CutMix Data Augmentation for Image Classification (Keras 예제)
- Label Smoothing
- 논문: When Does Label Smoothing Help? (2019년, 882회 인용)
- 분류: 규제 기법, 손실 함수
- 1줄 요약: 원-핫 레이블을 작은 상수만큼 (1에서) 빼고 (0에) 더하여 소프트 레이블로 평활화
- 구현물: tf.keras.losses.CategoricalCrossentropy의 인자로 구현 (BCE도 존재)
- Lookahead
- 논문: Lookahead Optimizer: k Steps Forward, 1 Step Back (2019년, 423회 인용)
- 분류: 훈련 기법, 옵티마이저
- 1줄 요약:
- 구현물: tfa.optimizers.Lookahead
- RAdam
- 논문: On the Variance of the Adaptive Learning Rate and Beyond (2019년, 1,032회 인용)
- 분류: 훈련 기법, 옵티마이저
- 1줄 요약: 적응형 학습률일 때 해가 종종 로컬 미니마에 빠지는 이유? 학습 초기에 분산이 커서 → Adam에서 매 단계 학습률 분산이 상수로 유지되도록 정규화 항을 곱해줌

- 구현물: tfa.optimizers.RectifiedAdam
- RandAugment
- 논문: RandAugment: Practical Automated Data Augmentation with a Reduced Search Space (2019년, 1,038회 인용)
- 분류: 규제 기법, 데이터 증강
- 1줄 요약: 여러 데이터 증강 변환의 최적 조합에 대한 결정을 단 2가지 변수, 적용할 변환의 개수와 변환의 강도로 파라미터화하여 탐색 → AutoAugment류보다 연산량은 크게 줄면서 비슷한 성능

- 구현물: augmenters.collections.RandAugment, RandAugment for Image Classification for Improved Robustness (Keras 예제)
- SAM
- 논문: Sharpness-Aware Minimization for Efficiently Improving Generalization (2020년, 268회 인용)
- 분류: 훈련 기법, 옵티마이저
- 1줄 요약: 기존 손실 함수에 근방의 평탄하지 않은 정도 Sharpness 를 추가

현재 EfficientNet-L2와 함께 사용해서 CIFAR-100의 SOTA
- 구현물: SAM: Sharpness-Aware Minimization for Efficiently Improving Generalization (공식: JAX)
2. 이미지 인식 Image Recognition
- DenseNet
- 논문: Densely Connected Convolutional Networks (2016년, 26,743회 인용)
- 1줄 요약: 이전 레이어들의 피쳐 맵을 누적 해서 다음 레이어 입력에 연결, 이때 대응하는 피쳐 맵을 더해주는 ResNet의 잔차 연결과 다르게 채널 축으로 결합 (Concatenation)
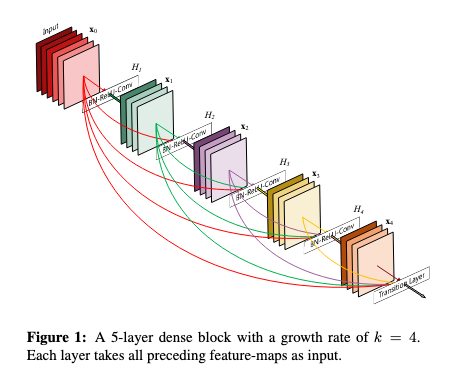
- 구현물: DenseNet (Keras App)
- MobileNet
- 논문: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (2017년, 14,002회 인용)
- 구분: 경량화
- 1줄 요약: Depthwise Separable Convolution을 주로 사용하여 연산량 낮춤, 이때 DSC는 ① 각 채널마다 (= 깊이 별) 컨볼루션 연산한 뒤 결합 ② 전체 채널에 대해 1 × 1 (= 점 별) 컨볼루션 연산, 이렇게 2단계 연산을 수행하는 것
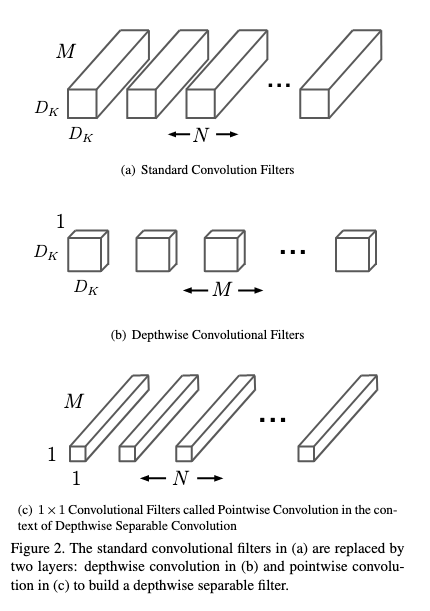
- 구현물: MobileNet, MobileNetV2, and MobileNetV3 (Keras App), Image (TF Hub)
- SENet
- 논문: Squeeze-and-Excitation Networks (2017년, 13,914회 인용)
- 구분:
- 1줄 요약:
- 구현물: (Gluon) SENet (PyTorch Image Models)
- MobileNet V2
- 논문: MobileNetV2: Inverted Residuals and Linear Bottlenecks (2018년, 10,410회 인용)
- 구분: 경량화
- 1줄 요약: DSC에서 점 별 컨볼루션으로 인한 채널 방향 연산량이 많다? 그럼 채널 수를 기본적으로 적게 (병목으로) 유지하자! 대신 정보 손실 적도록 블록 설계는, 채널 수 적은 피쳐 맵 → 채널 수 많은 DSC로 확장 → 다시 채널 수 적은 피쳐 맵으로 선형 투사하는 형태 → 여기에 잔차 연결 추가하면 (채널 두께의 변화가) 거꾸로 된 잔차 블록 완성 + ReLU6 사용
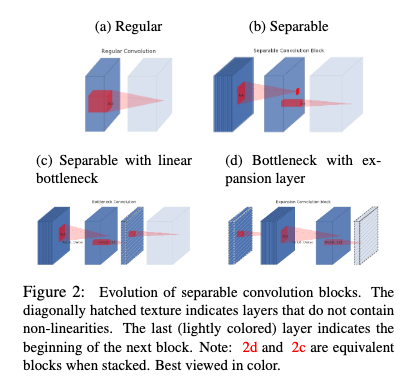
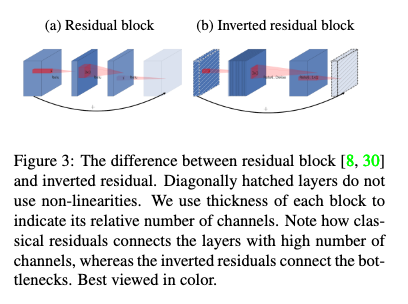
- 구현물: MobileNet, MobileNetV2, and MobileNetV3 (Keras App), Image (TF Hub)
- BiT
- 논문: Big Transfer (BiT): General Visual Representation Learning (2019년, 500회 인용)
- 구분: 전이 학습, ResNet (백본)
- 1줄 요약: 전이 학습 레시피 제시 ① 사전 훈련할 때: 대형 데이터셋에는 대형 모델 아키텍처 → BN 대신 GN과 WS 사용 ② 미세 조정할 때: 학습 시간 × 입력 해상도 × 믹스업 사용 여부 결정해주는 휴리스틱 규칙 제안
- 구현물: BiT (TF Hub), Image Classification Using BigTransfer (BiT) (Keras 예제)
- EfficientNet
- 논문: Rethinking Model Scaling for Convolutional Neural Networks (2019년, 7,463회 인용)
- 구분: NAS
- 1줄 요약: 정확도와 연산량은 신경망 깊이, 채널 너비, 입력 해상도의 함수로 정해지는 트레이드-오프 관계 → 정해진 연산량(FLOPS)에서 최적 정확도를 내는 이 3개 확장 인자의 값을 찾아내자 → 이것을 NAS로 (MnasNet 탐색과 유사하게) 찾은 베이스라인에 적용하면서 확장
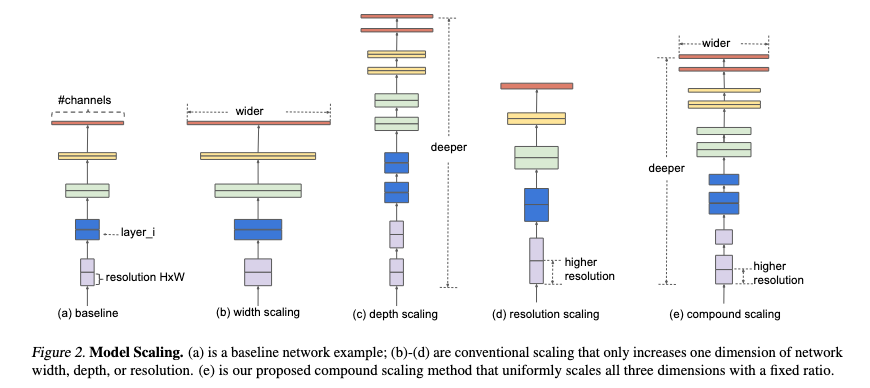
현재 SAM과 함께 사용해서 CIFAR-100의 SOTA
- 구현물: EfficientNet B0 to B7 (Keras App), EfficientNet (TF Hub), Image Classification via Fine-tuning with EfficientNet (Keras 예제)
- MobileNet V3
- 논문: Searching for MobileNetV3 (2019년, 2,391회 인용)
- 구분: 경량화, NAS
- 1줄 요약: ① 플랫폼-어웨어 NAS를 통해 블록 단위로 최적 아키텍처 탐색하고 NetAdapt를 통해 레이어 단위로 경량화함 ② 잔차 블록에 SE 모듈 추가 ③ 활성화 함수로 h-swish 사용
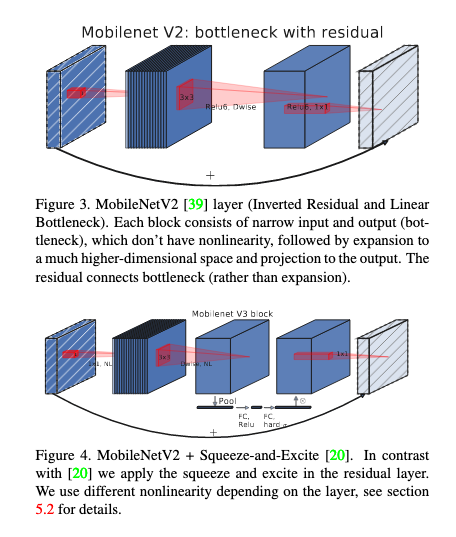
- 구현물: MobileNet, MobileNetV2, and MobileNetV3 (Keras App), Image (TF Hub)
- ViT
- 논문: An Image is Worth 16x16 Words: Transformer for Image Recognition at Scale (2020년, 5,406회 인용)
- 구분: 트랜스포머
- 1줄 요약:
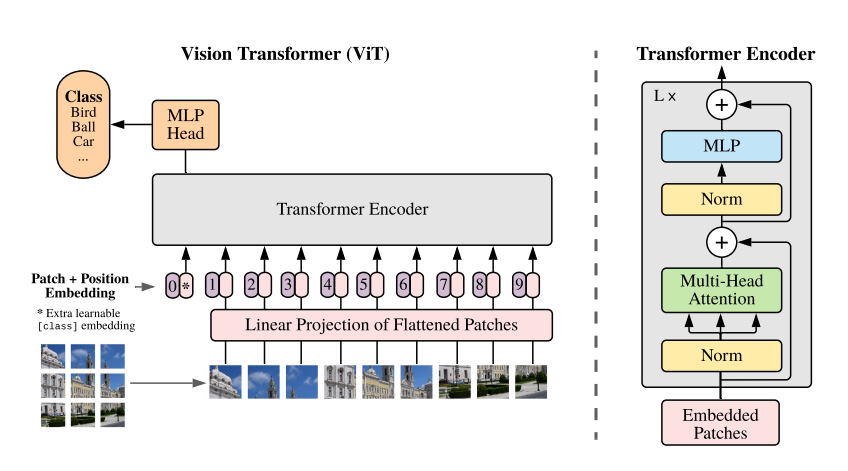
현재 ViT-H/14가 CIFAR-10의 SOTA
- 구현물: ViT (TF MG), Image Classification with Vision Transformer (Keras 예제)
- DeiT
- 논문: Training Data-Efficient Image Transformers & Distillation through Attention (2021년, 1,280회 인용)
- 구분:
- 1줄 요약:
- 구현물: DeiT (TF MG)
- EfficientNet V2
- 논문: EfficientNetV2: Smaller Models and Faster Training (2021년, 297회 인용)
- 구분:
- 1줄 요약:
- 구현물: EfficientNetV2 B0 to B3 and S, M, L (Keras App), EfficientNetV2 (TF Hub)
- ResNet-RS
- 논문: Revisiting ResNets: Improved Training and Scaling Strategies (2021년, 91회 인용)
- 구분: ResNet (백본)
- 1줄 요약: ResNet에 ① 훈련과 규제 최신 기법 적용 (Cosine 학습률 스케줄링 + 가중치 지수 이동 평균 + LS + SD + RandAugment + SE 블록) ② 확장 전략 수정하여 모델 탐색 = 채널 너비 대신 깊이 위주로 키우고 입력 해상도는 천천히 확장
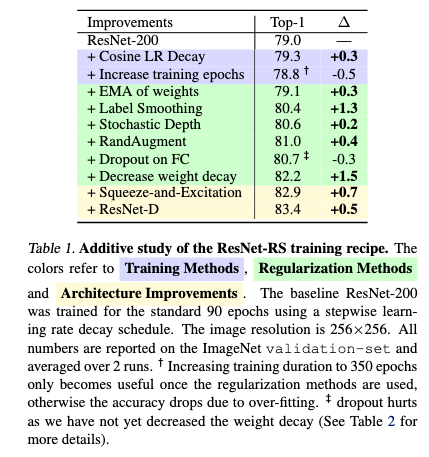
- 구현물: ResNet-RS (TF MG)
- SwinTransformer
- 논문: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (2021년, 2,014회 인용)
- 구분:
- 1줄 요약:
- 구현물: Image Classification with Swin Transformers (Keras 예제)
- SwinTransformer V2
- 논문: Swin Transformer V2: Scaling Up Capacity and Resolution (2021년, 96회 인용)
- 구분:
- 1줄 요약:
- ConvNeXt
- 논문: A ConvNet for the 2020s (2022년, 690회 인용)
- 구분:
- 1줄 요약:
3. 객체 탐지 Object Detection
- Faster R-CNN
- 논문: Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015년, 45,711회 인용)
- 구분: 2 스테이지, VGG (백본)
- 1줄 요약: (1) 추론 단계 ① RPN: 백본 컨볼루션 최종 레이어의 픽셀 당 9개의 앵커 박스 배정하고 객체가 포함될 확률과 BB 오프셋 출력 → 객체 확률로 앵커 필터링한 후 NMS 적용하여 RoI 리스트 최종 결정 ② 최종 레이어에 RoI 풀링 적용해서 고정 크기의 피쳐 맵 추출 → 클래스 확률과 BB 오프셋 출력
(2) 훈련 단계 ① 앵커 중 IoU가 가장 높거나 0.7 이상이면 양성 클래스, IoU가 0.3 이하면 음성 클래스 할당 ② 이미지 당 256개 앵커 샘플링하되 양성과 음성 비율은 1:1 ③ 해당 미니 배치마다 다중 손실(= 클래스 분류 손실 + BB 회귀 손실) 구해서 학습 (RPN과 Fast R-CNN 축에 대해 다른 한 축을 고정하고 번갈아가며 학습함)
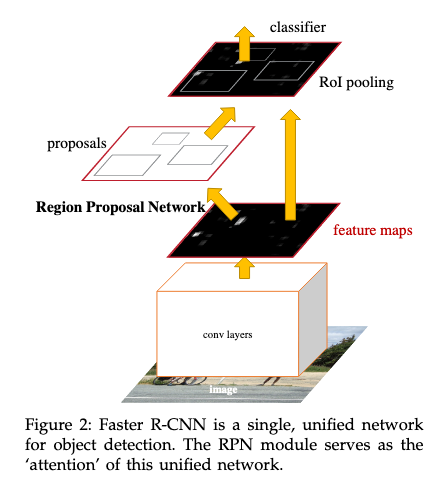
- 구현물: TensorFlow 2 Detection Model Zoo (TF2 OD API)
- YOLO
- 논문: You Only Look Once: Unified, Real-Time Object Detection (2015년, 26,506회 인용)
- 구분: 1 스테이지, GoogLeNet (백본)
- 1줄 요약: 실시간 추론 달성, 그러나 작은 크기의 객체 검출 능력 떨어짐
(1) 추론 단계: 이미지를 7 × 7 그리드로 나누고 백본의 FC 통과한 최종 레이어 피쳐 맵도 동일한 크기로 구성 → 각 그리드 셀마다 2쌍의 BB 좌표와 신뢰도(= 객체가 포함될 확률 × IoU), 1쌍의 클래스 확률 출력하고 NMS 적용
(2) 훈련 단계: 다중 손실(= 객체 중심 좌표 존재하는 그리드 셀, ∀ BB의 좌표 + 신뢰도 + 클래스 확률 오차에 객체 존재하지 않는 ∀ 그리드 셀, ∀ BB의 신뢰도 오차 추가함) 구해서 학습
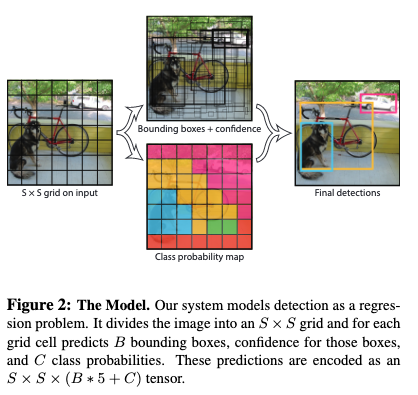
- SSD
- 논문: SSD: Single Shot MultiBox Detector (2015년, 22,926회 인용)
- 구분: 1 스테이지, VGG (백본)
- 1줄 요약: (1) 추론 단계: 컨볼루션 레이어 거치면서 6개의 멀티 스케일 피쳐 맵 추출 → 각 피쳐 맵의 그리드 셀마다 복수 개의 디폴트 박스 (≂ 앵커 박스) 배정하고 BB 오프셋과 클래스 확률 출력하고 NMS 적용
(2) 훈련 단계 ① 디폴트 중 IoU 0.5 이상이면 양성, 미만이면 음성 클래스 할당 ② HNM + 양성과 음성 비율은 1:3 ③ 다중 손실(= 클래스 분류 손실 + BB 회귀 손실) 구해서 학습
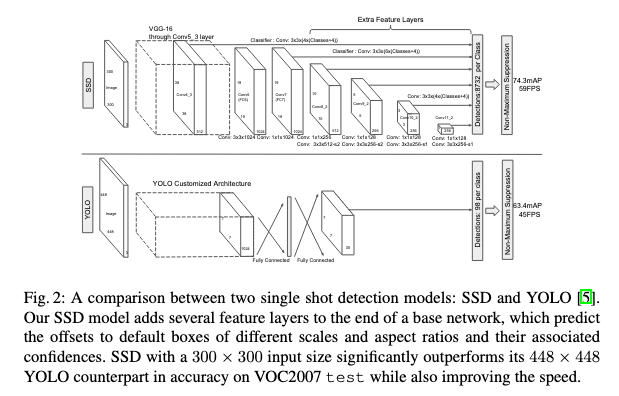
- 구현물: TensorFlow 2 Detection Model Zoo (TF2 OD API)
- YOLO V2
- 논문: YOLO9000: Better, Faster, Stronger (2017년, 13,045회 인용)
4. 영상 분할 Segmentation, 그 외
5. 이미지 생성 Image Generation
- CLIP
- 논문: Learning Transferable Visual Models From Natural Language Supervision (2021년, 3,798회 인용)
- 구분: 멀티모달
- 1줄 요약: 인터넷에서 이미지 및 텍스트 쌍 수집 → 이미지 인코더 (ResNet 또는 ViT) 통해 이미지 임베딩 & 텍스트 인코더 (트랜스포머) 통해 텍스트 임베딩한 후 코사인 유사도 계산, 이를 통해 이미지와 텍스트 조합 별로 교차 엔트로피 손실 구하여 훈련 (= 대조 학습) → 파인 튜닝 없이 제로 샷 예측 (예: 클래스에 대한 텍스트 후보 만들고 텍스트 인코더로 벡터화한 후 이미지 벡터와 유사도 가장 높은 것 선택)
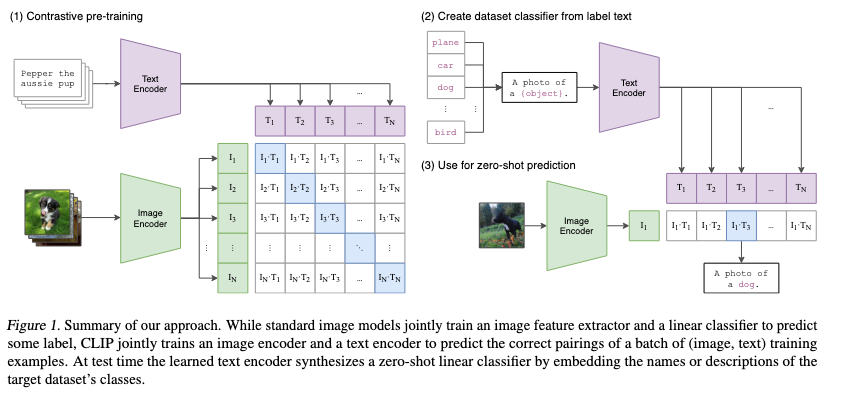
- 구현물: CLIP, OpenCLIP (PyTorch)
6. 파이썬 라이브러리 모음
- Albumentations: Github Star 10.6k, 데이터 증강, PyTorch, TensorFlow
- Augmentor: Github Star 4.8k, 데이터 증강
- Detectron2: Github Star 21.5k, 객체 탐지, 영상 분할, PyTorch
- EinOps: Github Star 5.3k, 딥러닝 연산, PyTorch, TensorFlow
- imgaug: Github Star 12.8k, 데이터 증강
- LabelMe: Github Star 8.8k, 객체 탐지와 영상 분할 어노테이션
- OpenMMLab: 이미지 인식, 객체 탐지, 영상 분할 등, PyTorch
- PyTorch Image Models: Github Star 19.7k, 이미지 인식, PyTorch
- Segmentation Models: Github Star 4k, 영상 분할, TensorFlow
- Segmentation Models PyTorch: Github Star 6k, 영상 분할, PyTorch
- TensorFlow 2 Object Detection API: 객체 탐지, TensorFlow
- TTAch: Github Star 0.7k, TTA, PyTorch

Sr. Data Scientist at AWS