
이 글은 검색 시스템에 대한 개인 학습 내용을 꾸준히 정리하여 올립니다.
Elasticsearch & OpenSearch
동작 방식과 함께 알아보는 최적의 Amazon OpenSearch Service 사이징
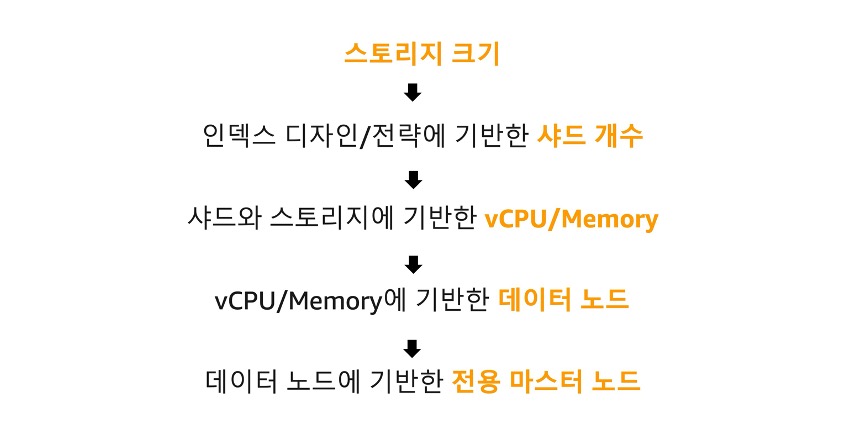
- Amazon OpenSearch Service 아키텍처
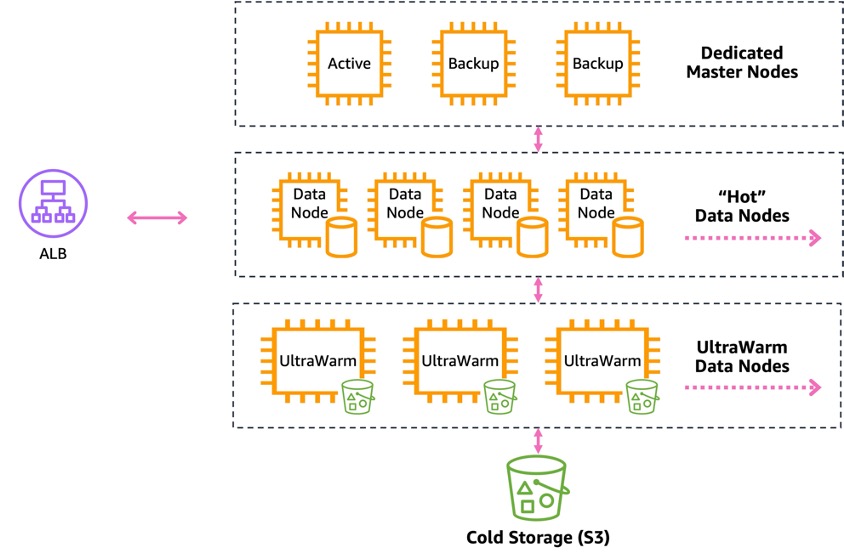
- OpenSearch Service 도메인은 전용 마스터 노드, Hot 데이터 노드, UltraWarm 및 Cold 데이터 스토리지로 구성됨
- 전용 마스터 노드: 클러스터 관리 작업 전담 (노드/인덱스/샤드 추적, 상태 업데이트 등)
- Hot 데이터 노드: 실제 인덱싱된 데이터 저장 및 검색/쿼리 수행
- UltraWarm/Cold 스토리지: 접근 빈도가 낮은 데이터 저장
- OpenSearch 내부 구조
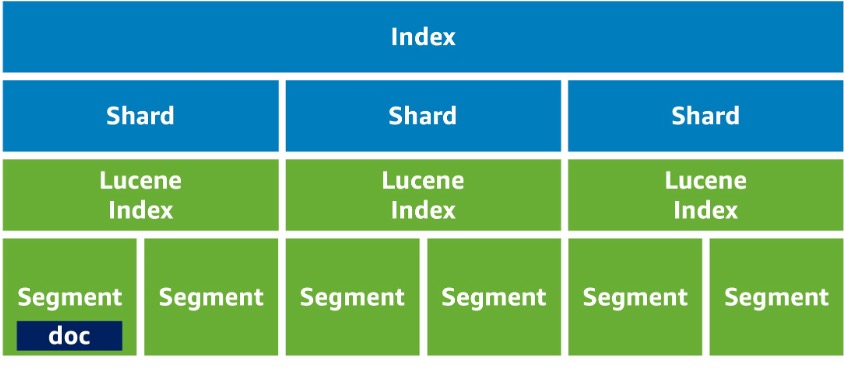
- 문서(Document): JSON 형식의 최소 데이터 단위
- 인덱스(Index): 문서들의 전체 데이터 세트
- 샤드(Shard): 인덱스를 분할한 단위, Lucene 인덱스와 1:1 매핑
- 세그먼트(Segment): Lucene 인덱스가 문서를 나누는 단위
- 샤드 구성
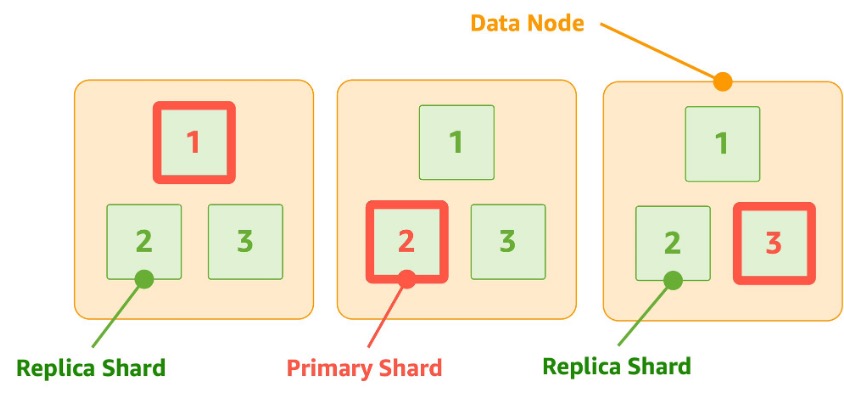
- 기본 샤드(Primary Shard)와 복제본 샤드(Replica Shard)로 구성
- 기본 샤드: 오리지널 데이터 보관, 실제 검색/쿼리 수행
- 복제본 샤드: 기본 샤드의 복제본, 내구성 및 처리량 향상에 사용
- 기본 샤드 개수 결정 시 고려사항:
- 데이터 크기, 인덱스 패턴, 노드 개수 등 고려
- 일반적으로 50GB 이하로 구성 (대규모 데이터의 경우 100GB까지 가능)
- 데이터 노드 개수의 배수로 구성 권장
- 복제본 샤드: 가용성을 고려해 구성 (일반적으로 2개 권장)
- 스토리지 옵션

- Hot: 빠른 액세스, 인덱싱/업데이트 가능, 높은 성능/비용
- UltraWarm: S3 기반 읽기 전용 스토리지, 중간 성능/비용
- Cold: 저빈도 액세스 데이터 장기 보관, 낮은 성능/비용
- 스토리지 크기 예측 시 고려사항:
- 공통: 인덱스 매핑 정보에 따른 10% 오버헤드
- Hot: 복제본 수, OS 예약 공간(5%), OpenSearch Service 오버헤드(20% 또는 20GB)
- UltraWarm/Cold: 인덱스 오버헤드만 고려
- 인스턴스 타입 선택
- 전용 마스터 노드
- 클러스터 크기, 인덱스/샤드 개수에 따라 선택
- 3개 구성 권장 (쿼럼 방식 복원 지원)
- 데이터 노드 (Hot)
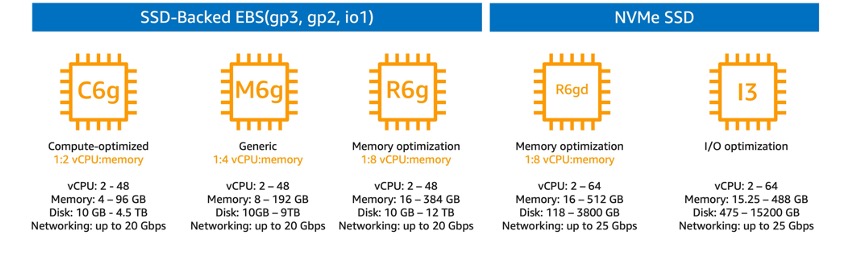
- 예상 스토리지 사용량과 필요 샤드 개수 고려
- 최소 2개, 권장 3개 이상 구성
- C, M, R, I 패밀리 중 선택 (일반적으로 M 패밀리 권장)
- UltraWarm 노드
- ultrawarm1.medium.search 또는 ultrawarm1.large.search 중 선택
- 관리 가능 스토리지 크기, vCPU/메모리, 캐싱 스토리지 크기 고려
- 전용 마스터 노드
- 성능 최적화 및 모니터링
- CloudWatch 지표 (CPUUtilization, JVMMemoryPressure 등) 모니터링
- 인스턴스 유형 변경 및 추가를 통한 반복적 테스트 권장
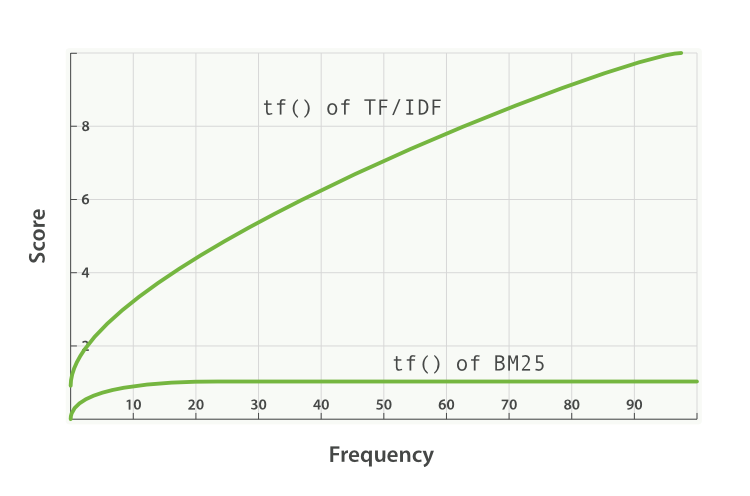
실용적인 BM25 - 제2부: BM25 알고리즘과 변수
- BM25 알고리즘 구조
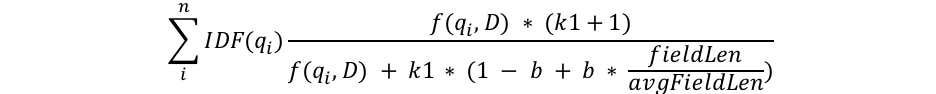
- qi: i번째 쿼리(토큰화된) 단어
- 역문서 빈도(IDF) 계산
- IDF 수식
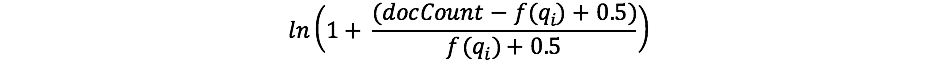
- docCount: 샤드(또는 여러 샤드)에서 필드 값을 가진 총 문서 수
- f(qi): i번째 쿼리 단어를 포함하는 문서 수
- 드문 단어에 대해 더 높은 가중치 부여
- IDF 수식
- 문서 길이 정규화
- fieldLen/avgFieldLen 비율 사용
- 평균보다 긴 문서는 점수가 감소, 짧은 문서는 점수가 증가
- Elasticsearch에서는 단어 수 기준으로 길이 계산
- 변수 b의 역할
- 문서 길이 정규화의 영향력 조절
- b가 클수록 문서 길이의 영향이 커짐
- Elasticsearch 기본값: 0.75
- 단어 빈도(f(qi,D))와 k1 변수
- f(qi,D): 문서 D에서 i번째 쿼리 단어의 출현 횟수
- k1: 단어 빈도 포화 특성 결정
- k1이 높을수록 추가 출현 단어의 점수 기여도가 증가
- Elasticsearch 기본값: 1.2
Amazon OpenSearch Service의 검색 엔진으로서의 기능 설명
Amazon OpenSearch Service, 한국어 분석을 위한 ‘노리(Nori)’ 플러그인 활용
- Amazon OpenSearch Service의 노리(Nori) 플러그인
- 한국어 텍스트 분석을 위한 오픈 소스 플러그인
- OpenSearch 1.0 이상 버전에서 사용 가능
- 도메인 구성 시 선택적으로 설치 가능
- 노리 플러그인 구성 요소
- nori_tokenizer: 한국어 형태소 분석 토크나이저
- nori_part_of_speech: 품사 선택을 위한 토큰 필터
- nori_readingform: 한자를 한글로 변경하는 토큰 필터
- lowercase: 소문자 변환 토큰 필터
- 분석기 동작 순서
- 캐릭터 필터 (Character filters)
- 토크나이저 (Tokenizer)
- 토큰 필터 (Token filters)
- 노리 분석기 사용 방법
- OpenSearch Dashboards의 Dev Tools 또는 API 호출을 통해 사용
- _analyze API를 통한 토큰화 결과 확인 가능
- 인덱스 생성 및 매핑
- 필드 타입을 'text'로 지정하고 분석기를 'nori'로 설정
- 검색 기능
- match 쿼리를 사용한 전문 검색 지원
- 검색 시 지정된 분석기를 통해 쿼리 문장도 토큰화
- Okapi BM25 알고리즘 기반 검색 수행
- 커스텀 분석기 구성
- nori_tokenizer를 기반으로 사용자 정의 캐릭터 필터와 토큰 필터 조합 가능
- 인덱스 settings에서 커스텀 분석기 정의 가능
- 노리 토크나이저 설정 옵션
- decompound_mode: 복합명사 처리 방식 (none, discard, mixed)
- discard_punctuation: 구두점 처리 여부
- user_dictionary: 사용자 정의 사전 적용
- user_dictionary_rules: 인라인 사용자 사전 규칙 정의
- 사용자 사전 관리
- Amazon S3를 통한 사용자 사전 업로드 지원
- 패키지 기능을 통한 사전 버전 관리 및 여러 도메인 공유 가능
- 기타 지원 기능
- _termvectors API를 통한 문서의 토큰 구성 확인
- 동의어 및 유사어 검색을 위한 추가 설정 가능
Amazon OpenSearch Service Hybrid Query를 통한 검색 기능 강화
- Hybrid Query 소개
- OpenSearch Service 2.11 버전부터 지원되는 새로운 기능
- Lexical Search(키워드 기반)와 Semantic Search(벡터 기반)를 결합하여 검색 관련성 개선
- 각 검색 방식의 장단점을 상호 보완하여 더 정확한 검색 결과 제공
- 구현 과정
- OpenSearch 도메인 생성 (버전 2.11 이상 선택)
- 테스트 데이터 준비 및 임베딩
- 인덱스 생성 및 데이터 색인
- Search Pipeline 생성 (normalization-processor 사용)
- Hybrid Query 구성 및 테스트
- 데이터 준비 및 임베딩
- 'multilingual-e5-large' 모델을 사용하여 텍스트 임베딩
- OpenSearch의 Neural Search를 위해 'msmarco-distilbert-base-task-b' 모델 사용
- RecursiveCharacterTextSplitter를 이용해 텍스트 청크 분할
- 인덱스 설정
- KNN 벡터 필드 설정 (1,024 차원)
- 한국어 텍스트 분석 위한 Nori 애널라이저 사용
- Search Pipeline 구성
- normalization-processor 사용하여 서로 다른 검색 방식의 스코어 정규화
- min_max 정규화 기법 적용
- arithmetic_mean을 이용한 가중치 결합 (예: 0.3과 0.7의 가중치)
- Hybrid Query 구조
- multi_match query: 키워드 기반 검색
- knn query 또는 neural query: 벡터 기반 검색
- 두 쿼리 결과를 결합하여 최종 순위 결정
- 성능 비교
- 단일 Semantic Search vs Hybrid Query 결과 비교
- bool query와 Hybrid Query의 차이점 설명
- 추가 기능
- min_score 설정을 통한 결과 필터링
- 필드별 가중치 부여 (예: title 필드에 2배 가중치)
- 실용적 조언
- 데이터 특성에 따라 각 쿼리 유형의 가중치 조정 필요
- 지속적인 실험과 최적화 과정 권장
Introducing Semantic Capability in LinkedIn's Content Search Engine (2024, LinkedIn)
OpenSearch에서 수십억 규모 검색을 위한 적합한 k-NN 알고리즘을 선택하기
Learning to Rank
From RankNet to LambdaRank to LambdaMART: An Overview (2010, Microsoft)
검색어 의도에 맞는 상품 검색 결과 보여주기 (2022, SSG.COM)
- 검색 엔진 기반
- Elasticsearch 사용
- 기본 TF-IDF 및 BM25 유사도 대신 커스텀 랭킹 모델 적용
- 초기 랭킹 모델
- 정적 부스팅 기반 랭킹 모델 사용
- Elasticsearch의 함수 스코어 쿼리(Function Score Query) 활용
- 상품 속성(브랜드, 카테고리 등)에 따른 가중치 부여
- Learning to Rank (LTR) 모델 도입
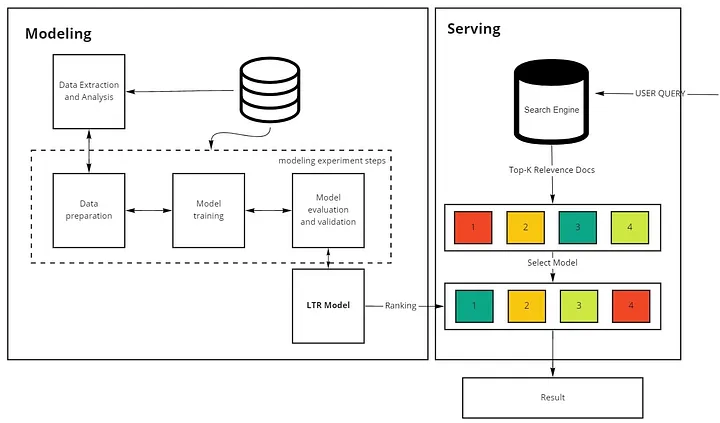
- XGBoost 알고리즘 사용 (LambdaMART 방식)
- 카테고리별로 개별 모델 구축
- Elasticsearch LTR 플러그인 활용
- 학습 데이터 구성
- 검색 로그의 클릭 데이터를 기반으로 한 자동 라벨링
- 상품 자체 특성과 검색어-상품 간 연관성을 나타내는 피처 정의
- 모델 평가 방법
- NDCG 지표 사용
- 오프라인 평가와 실제 검색 결과 검수 병행
- 기술적 이슈 해결
- GPU 활용으로 학습 속도 개선 (CPU 대비 17.8배 빠른 학습)
- 모델 크기 최적화를 통한 검색 엔진 부하 관리
- 운영 및 모니터링
- 카테고리별 순차적 모델 적용
- CTR 모니터링을 통한 성과 측정
- 향후 개선 계획
- A/B 테스트 도입
- 피처 및 타겟 개선
- 랭킹 모델 배포 자동화 파이프라인 구축
- LTR 모델 알고리즘 고도화
참고

Sr. Data Scientist at AWS