이 글은 Text2SQL에 대한 개인 학습 내용을 꾸준히 정리하여 올립니다.
1. 논문
CodeS: Towards Building Open-Source Language Models for Text-to-SQL (2024)
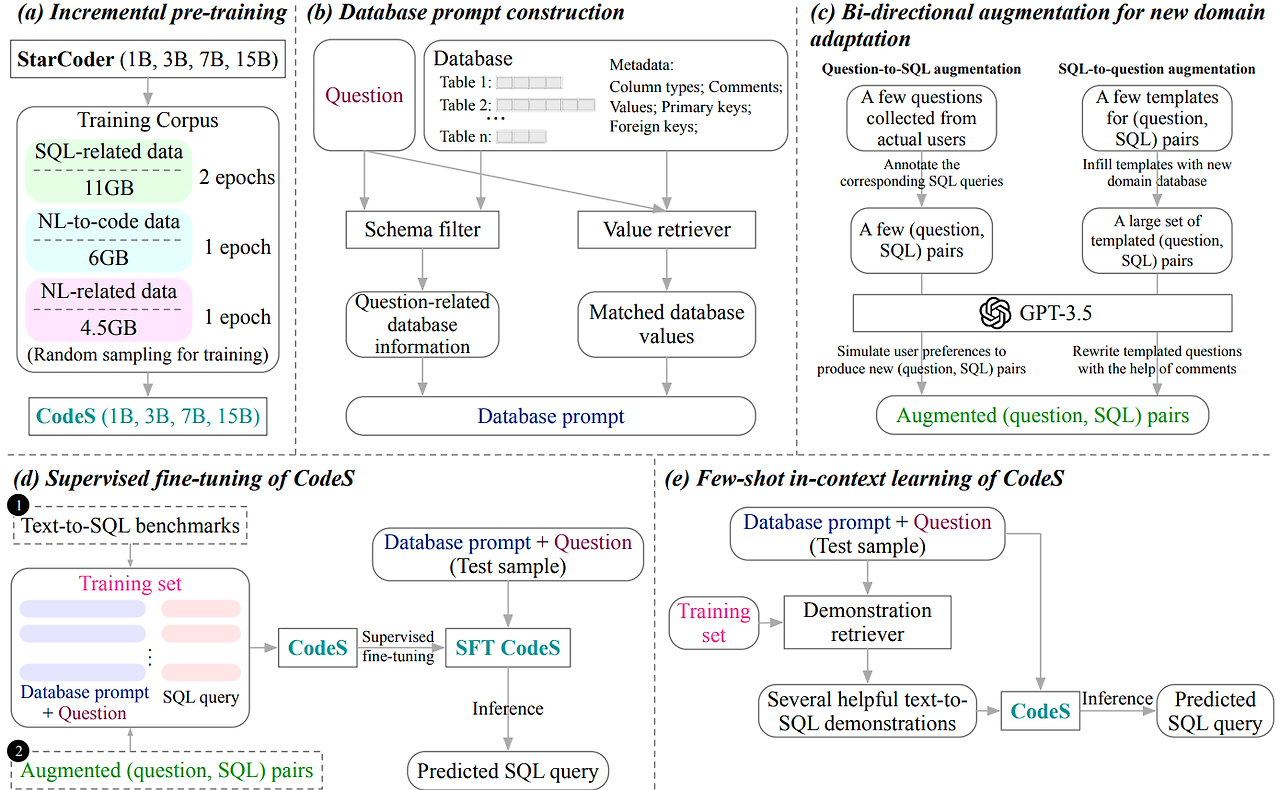
- CodeS 모델 개발
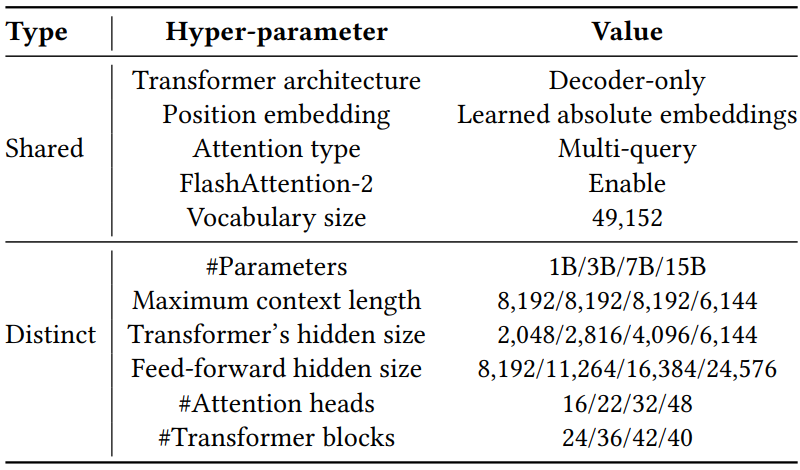
- 기반 모델: StarCoder (오픈소스 코드 생성 모델)
- 모델 구조: 디코더 전용 트랜스포머 구조
- 모델 크기: 10억, 30억, 70억, 150억 파라미터
- 어휘 크기: 49,152
- 위치 임베딩: 학습된 절대 위치 임베딩
- 어텐션 유형: 멀티 쿼리 어텐션 사용
- 플래시 어텐션 2 적용으로 긴 컨텍스트 처리 가능 (최대 8,192 토큰, 단 150억 모델은 6,144 토큰)
- 사전 학습 말뭉치 구성
- SQL 관련 데이터 (11GB): StarCoder 사전 학습 말뭉치의 SQL 부분
- 자연어-코드 변환 데이터 (6GB)
• CoNaLa, StaQC: Stack Overflow에서 추출한 자연어-파이썬, 자연어-SQL 쌍
• CodeAlpaca-20k: 코드 관련 명령 이행 데이터
• Jupyter-structured-clean-dedup: 코드와 설명이 포함된 주피터 노트북
• NL-SQL-458K: 자체 제작 데이터셋 (SQL 쿼리 추출 후 GPT-3.5로 질문 생성) - 자연어 관련 데이터 (4.5GB):
• Alpaca-cleaned, Unnatural-instructions: 단일 턴 대화 데이터
• UltraChat: 다중 턴 대화 데이터
- 점진적 사전 학습 세부사항
- 최적화 목표: 언어 모델링 (다음 토큰 예측)
- 옵티마이저 알고리즘: AdamW (β1=0.9, β2=0.95, ε=10^-8)
- 학습률: 5e-5, 가중치 감소: 0.1
- 학습률 스케줄러: 코사인 감소 (웜업 없음)
- 배치 크기: 4백만 토큰
- 그래디언트 클리핑: 1.0
- 메모리 최적화: DeepSpeed Zero-3, BF16 혼합 정밀도
- 학습 시간: 10억 (1.5일), 30억 (3일), 70억 (8일), 150억 (16일)
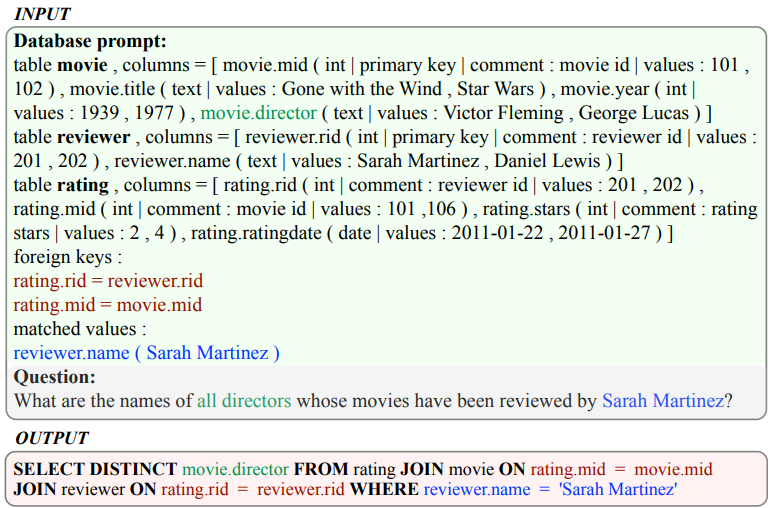
- 데이터베이스 프롬프트 구성 기법

- 스키마 필터
• 스키마 항목 분류기 학습 (AUC 척도로 평가)
• 상위 k1개 테이블, 각 테이블당 상위 k2개 컬럼 선택 - 값 검색기
• BM25 색인으로 초기 후보 값 추출 (Lucene 라이브러리 사용)
• 최장 공통 부분 문자열 알고리즘으로 최종 매칭 - 메타데이터 포함
• 컬럼 데이터 유형, 설명, 대표값 (DISTINCT 쿼리로 2개 추출)
• 기본키/외래키 관계 정보
- 스키마 필터
- 양방향 데이터 증강 기법
- 질문-SQL 방향
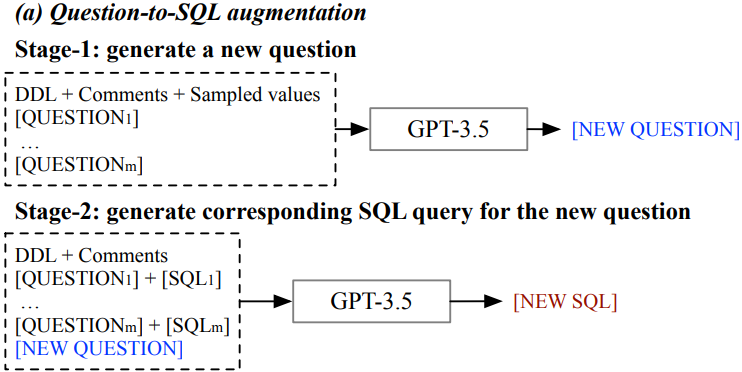
• 실제 사용자 질문 소수 수집 및 SQL 수동 레이블링
• GPT-3.5로 유사 질문-SQL 쌍 생성 (높은 온도 값 설정) - SQL-질문 방향
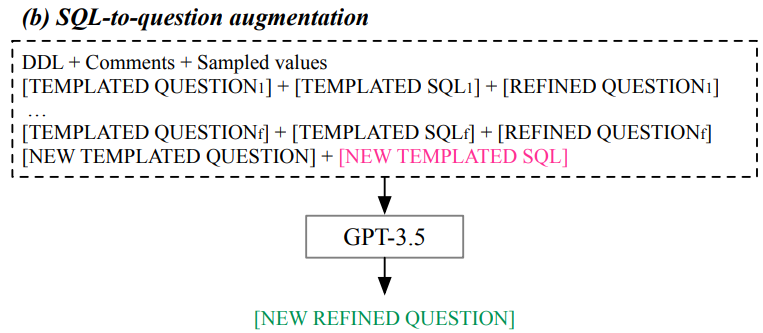
• Spider 벤치마크에서 75개 일반적 SQL 템플릿 추출
• 새 DB 스키마로 템플릿 채우기
• GPT-3.5로 자연스러운 질문으로 변환
- 질문-SQL 방향
- 모델 사용 방식
- 퓨샷 샘플을 통한 컨텍스트 내 학습
• 질문 패턴 인식을 통한 샘플 검색기 개발
• SimCSE 모델로 질문 유사도 계산 - 지도 학습 미세 조정
• 4 에폭, 배치 크기 128, 학습률 5e-6
• 최대 컨텍스트 길이 4,096 토큰
• 코사인 감소 + 5% 선형 웜업 적용
- 퓨샷 샘플을 통한 컨텍스트 내 학습
- 평가 지표
- 실행 정확도 (EX): 생성된 SQL의 실행 결과가 정답과 일치하는지 평가
- 테스트 스위트 정확도 (TS): 여러 DB 인스턴스에서 일관되게 정확한지 평가
- 유효 효율성 점수 (VES): 정확한 SQL의 실행 효율성 평가
- 코드
PET-SQL: A Prompt-Enhanced Two-Round Refinement of Text-to-SQL with Cross-Consistency (2024)
- 목적
- 텍스트를 SQL로 변환하는 Text-to-SQL 태스크의 성능을 향상시키기 위한 새로운 프레임워크 제안
- 대규모 언어 모델(LLM)을 활용하여 복잡한 데이터베이스 정보와 사용자 의도를 더 잘 처리하고자 함
- 주요 방법론
- 새로운 프롬프트 표현 방식 도입
- 스키마 정보와 테이블의 무작위 샘플 셀 값을 포함
- SQL 쿼리 생성을 위한 LLM 지시에 활용
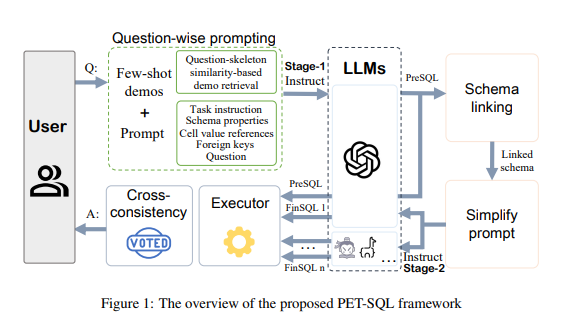
- 두 단계 프레임워크
- 첫 번째 단계
- 질문(엔티티 제거하여 스켈레톤만 추출)-SQL 쌍을 검색하여 퓨샷 샘플로 사용
- LLM에 예비 SQL(PreSQL) 생성 지시
- 두 번째 단계
- PreSQL에서 언급된 엔티티를 파싱하여 스키마 링킹 수행
- 링크된 스키마로 프롬프트 정보 간소화
- LLM에 최종 SQL(FinSQL) 생성 지시
- 첫 번째 단계
- 교차 일관성 도입
- 단일 LLM 내 자체 일관성 대신 여러 LLM 간 교차 일관성 사용
- 다양한 LLM의 결과를 종합하여 정확도 향상
- 새로운 프롬프트 표현 방식 도입
- 주요 혁신점
- 참조 강화 표현(Reference-Enhanced Representation, RE_p) 프롬프트
- 최적화 규칙(OR), 셀 값 참조(CV), 외래 키 선언(FK) 포함
- 기존 프롬프트 방식 대비 성능 향상
- PreSQL 기반 스키마 링킹
- LLM에 직접 스키마 추측 대신 SQL 생성 후 파싱하는 방식
- 스키마 링킹 정확도 향상 및 프롬프트 간소화
- 교차 일관성
- 다양한 LLM의 결과를 낮은 온도에서 종합
- 단일 모델의 자체 일관성보다 우수한 성능
- 참조 강화 표현(Reference-Enhanced Representation, RE_p) 프롬프트
- 실험 결과
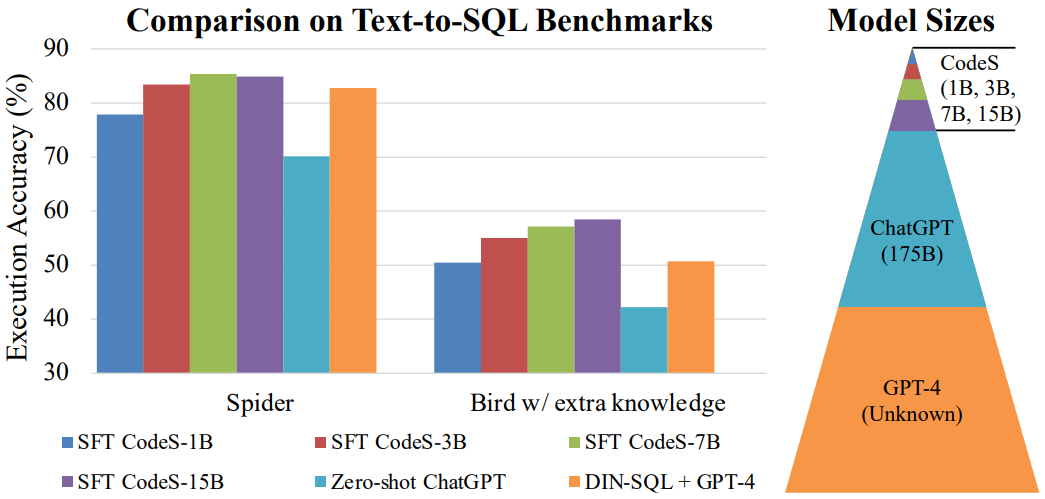
- Spider 벤치마크에서 87.6%의 실행 정확도 달성 (기존 최고 성능 대비 1% 향상)
- 다양한 LLM에서 일관된 성능 향상 확인
- 프롬프트 디자인, 스키마 링킹, 교차 일관성의 효과성 검증
- 결론
- PET-SQL 프레임워크는 Text-to-SQL 태스크에서 유망한 결과를 보여줌
- 프롬프트 강화와 LLM 간 교차 일관성 활용이 성능 향상에 기여
- 향후 Text-to-SQL 연구의 새로운 방향 제시
- 코드
Text2SQL is Not Enough: Unifying AI and Databases with TAG (2024)
- 배경 및 문제 정의
- 기존 Text-to-SQL 시스템의 한계
- 관계 대수로 표현 가능한 제한된 질문만 처리 가능
- 복잡한 의미론적 추론이나 세계 지식이 필요한 질문에는 대응 어려움
- RAG 방식의 한계
- 단순 조회 수준의 질문에만 적합
- 대규모 데이터에 대한 추론 능력 제한적
- 실제 사용자 질문의 복잡성
- 도메인 지식, 세계 지식, 정확한 계산, 의미론적 추론의 조합이 필요
- 기존 Text-to-SQL 시스템의 한계
- TAG(Table-Augmented Generation) 모델 제안
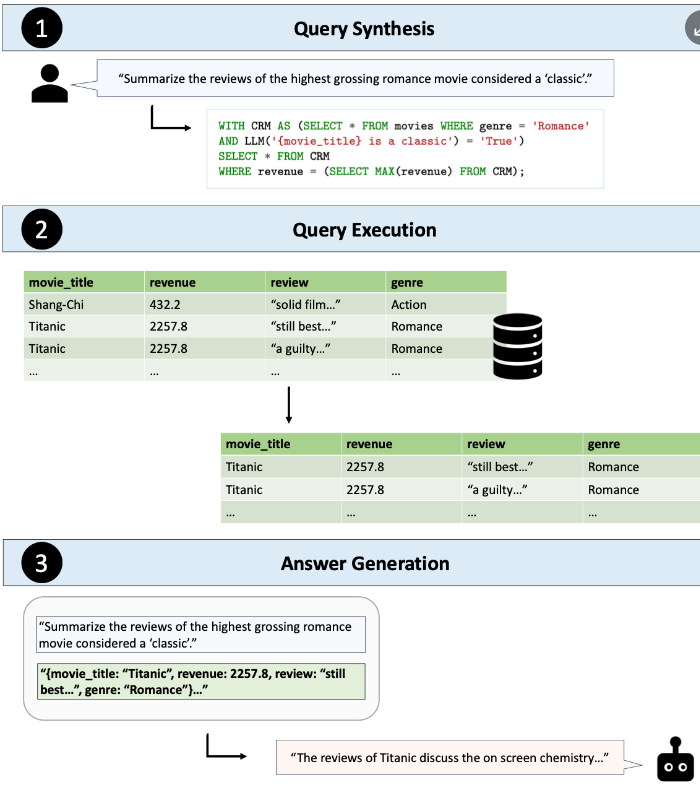
- 3단계 프로세스
- 쿼리 합성
- 자연어 질문을 실행 가능한 DB 쿼리로 변환
- LLM의 의미론적 추론 능력 활용
- 쿼리 실행
- DB 시스템에서 쿼리를 효율적으로 실행
- 관련 데이터 검색
- 답변 생성
- 검색된 데이터와 원래 질문을 바탕으로 LLM이 자연어 답변 생성
- 쿼리 합성
- 특징
- LLM의 추론 능력과 DB 시스템의 계산 능력 결합
- 기존 Text-to-SQL 및 RAG 방식을 포괄하는 일반화된 모델
- 3단계 프로세스
- 벤치마크 구축
- BIRD 데이터셋 기반
- 다양한 도메인과 쿼리 유형 포함
- 80개의 수정된 복잡한 질문
- 40개: 세계 지식이 필요한 질문
- 40개: 의미론적 추론이 필요한 질문
- 쿼리 유형
- 일치 기반, 비교, 순위, 집계 쿼리 각 20개씩
- BIRD 데이터셋 기반
- 실험 설계
- 비교 대상
- Text-to-SQL
- RAG
- 검색 + LM 순위 매기기
- Text-to-SQL + LM
- 수작업으로 구현한 TAG
- 평가 지표
- 정확도(정확한 일치 비율)
- 실행 시간
- 비교 대상
- 실험 결과
- 정확도
- 기존 방식들: 20% 이하의 정확도
- 수작업 TAG: 전체적으로 55% 정확도
- 비교 쿼리에서 TAG: 65% 정확도로 최고 성능
- 실행 시간
- TAG: 평균 2.94초로 다른 방식보다 최대 3배 빠름
- 쿼리 유형별 성능
- TAG는 순위 쿼리를 제외한 모든 유형에서 50% 이상의 정확도
- Text-to-SQL: LM 추론이 필요한 쿼리에서 특히 낮은 성능(10% 정확도)
- RAG 및 검색 + LM 순위 매기기: 정확한 계산이 필요한 쿼리에서 어려움
- 정확도
- 추가 분석
- 집계 쿼리에 대한 정성적 분석 제공
- TAG 시스템의 대량 데이터 집계 및 유익한 답변 생성 능력 강조
- 결론 및 향후 연구 방향
- TAG 모델의 우수성 입증
- 자동화된 TAG 시스템 구축을 위한 연구 기회 제시
- 실제 환경을 반영한 더 현실적인 벤치마크 개발 필요성 강조
C3: Zero-Shot Text-to-SQL with ChatGPT (2023)
DBCopilot: Scaling Natural Language Querying to Massive Databases (2023)
- DBCopilot의 핵심 아키텍처 및 접근 방식
• Schema-agnostic NL2SQL 문제를 두 단계로 분리- Schema Routing: 질의에 맞는 데이터베이스와 테이블 식별
- SQL Generation: 식별된 스키마를 기반으로 SQL 쿼리 생성
- Schema Routing의 주요 구성 요소
• Schema Graph Construction- 데이터베이스와 테이블 간의 관계를 그래프로 모델링
- 포함 관계(Inclusion relations)와 테이블 관계(Table relations) 표현
- Primary-Foreign key 관계와 implicit Foreign-Foreign 관계 고려
• Schema Serialization - DFS(Depth-First Search) 기반 직렬화 알고리즘 사용
- 그래프의 구조적 정보를 유지하면서 스키마를 토큰 시퀀스로 변환
- 랜덤 순서가 아닌 구조적 관계를 고려한 순서로 직렬화
• Training Data Synthesis - Reverse schema-to-question generation 패러다임 도입
- 스키마 그래프에서 유효한 스키마를 샘플링
- 샘플링된 스키마에 대해 가상의 자연어 질의 생성
- Schema Router의 학습 및 추론
• 학습 방법- Seq2Seq 모델 기반의 스키마 라우터 구현
- 합성된 training data로 학습
- 질의-스키마 간 의미적 매핑을 파라미터화
• 추론 최적화 - Graph-based constrained decoding 사용
- Dynamic prefix tree로 유효한 노드 이름만 생성하도록 제한
- Diverse beam search로 다양한 후보 스키마 생성
- SQL Generation 전략
• 여러 가지 프롬프트 전략 실험- Best Schema Prompting: 가장 높은 확률의 스키마만 사용
- Multiple Schema Prompting: 여러 후보 스키마를 연결하여 사용
- Multiple Schema COT Prompting: Chain-of-thought 추론으로 스키마 선택
- 실험 및 성능
• 주요 성능 개선- 스키마 라우팅에서 기존 방법 대비 최대 19.88% 향상
- SQL 실행 정확도 7.35% 이상 개선
- 스키마와 질의 간 불일치가 있는 경우에도 강건한 성능 유지
- 기술적 장점
• 대규모 데이터베이스에 확장 가능
• 스키마 관계를 고려한 end-to-end 접근
• 수동 개입 없이 자동으로 학습 데이터 생성
• 기존 LLM 기반 NL2SQL 솔루션과 쉽게 통합 가능
DAIL-SQL: Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation (2023)
DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction (2023)
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL (2023)
RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL (2023)
2. 블로그
Build a Robust Text-to-SQL Solution Generating Complex Queries, Self-Correcting, and Querying, Diverse Data Sources (2024, AWS)
- 아키텍처 구성
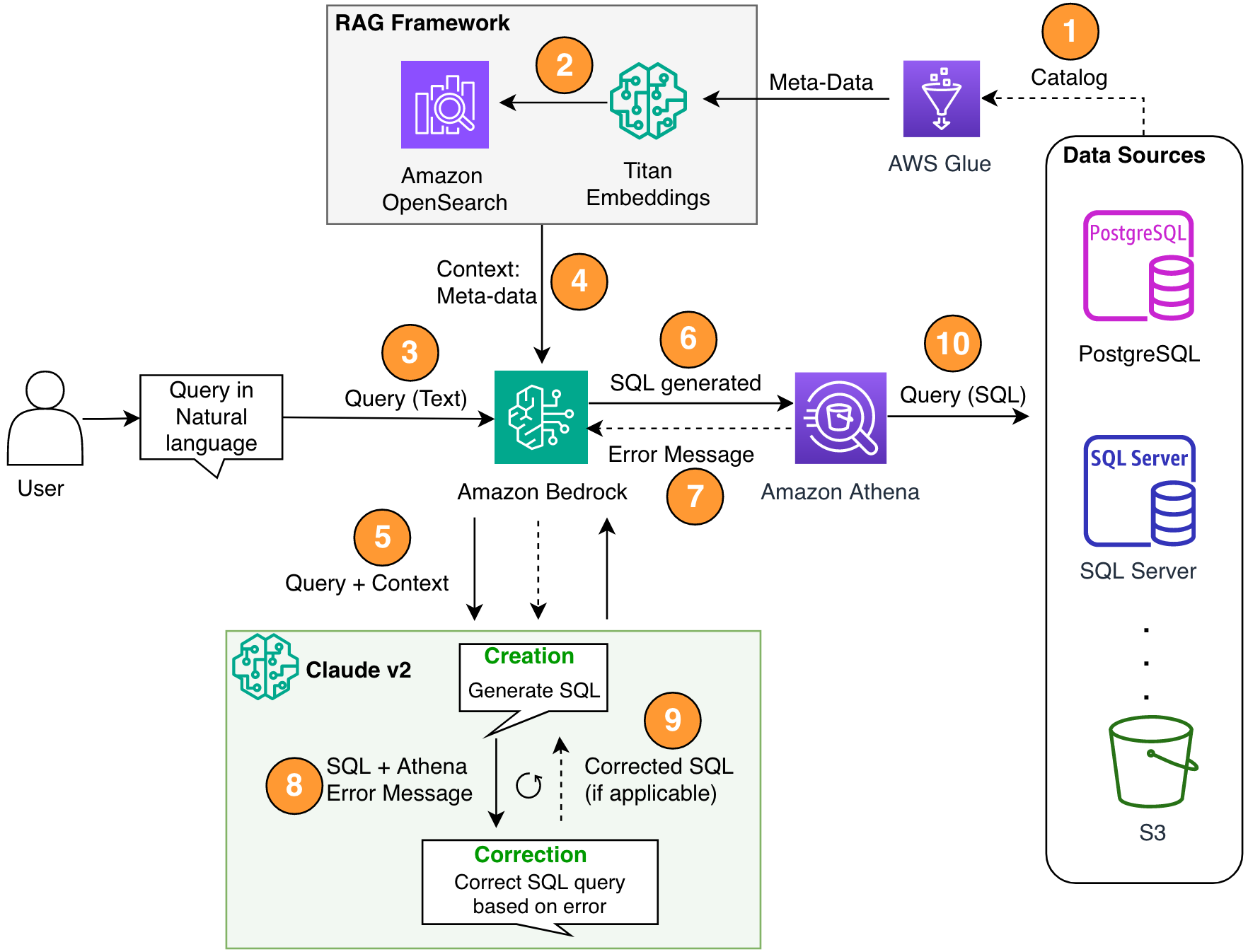
- Amazon Bedrock의 Anthropic Claude v2.1을 LLM으로 사용
- AWS Glue Data Catalog를 메타데이터 저장소로 활용
- Amazon Athena를 SQL 엔진으로 사용
- Amazon OpenSearch Serverless를 벡터 데이터베이스로 활용
- RAG 구현
- AWS Glue 메타스토어에서 테이블 및 스키마 설명을 검색
- Titan-Text-Embeddings 모델을 사용하여 메타데이터를 임베딩으로 변환
- OpenSearch Serverless에 임베딩을 저장하여 지식 베이스 구축
- 멀티스텝 자가 수정 루프
- 생성된 SQL 쿼리를 Athena로 전송하여 구문 오류 확인
- Athena 오류 메시지를 활용하여 LLM 프롬프트 개선
- 오류 수정을 위해 여러 번의 반복 수행 가능
- SQL 생성 프로세스
- 사용자 질문 입력 받기
- RAG 프레임워크를 통해 관련 메타데이터 검색
- 컨텍스트와 질의를 결합하여 LLM에 전송
- LLM이 SQL 쿼리 생성
- Athena로 구문 검증
- 필요시 오류 수정 루프 실행
- 최종 SQL을 Athena로 실행하여 결과 생성
- 데이터 소스 처리
- Amazon S3를 주 데이터 저장소로 사용
- Athena의 커넥터를 활용하여 다양한 데이터 소스 쿼리 가능 (예: CloudWatch Logs, DynamoDB, DocumentDB 등)
- 구현 세부사항
- 파이썬과 Boto3 SDK 사용
- JSON 로더를 이용한 문서 로딩
- OpenSearchVectorSearch 클래스를 사용한 벡터 검색 구현
- Athena 클라이언트를 통한 쿼리 실행 및 결과 처리
- 오류 처리 및 개선
- Athena 응답을 기반으로 한 SQL 쿼리 자가 수정
- 컬럼 타입, 조인 조건, CTE 사용 등에 대한 세부 지침 포함
- 확장성
- 다양한 데이터 소스에 대한 Athena 페더레이티드 쿼리 지원
- 사용자 피드백이나 샘플 쿼리를 통한 추가 개선 가능성 언급
Generating Value from Enterprise Data: Best Practices for Text2SQL and Generative AI (2024, AWS)
- Text2SQL의 주요 구성 요소
- NLP
- 사용자 입력 질문 분석
- 주요 요소와 의도 추출
- 구조화된 형식으로 변환
- SQL 생성
- 추출된 세부 정보를 SQL 구문에 매핑
- 유효한 SQL 쿼리 생성
- 데이터베이스 쿼리
- AI 생성 SQL을 데이터베이스에서 실행
- 결과 검색 및 사용자에게 반환
- NLP
- LLM 활용
- SQL 포함 코드 생성 능력 활용
- 자연어 질문 이해 및 해당 SQL 쿼리 생성
- 인 컨텍스트 학습 및 파인 튜닝 설정 적용
- 프롬프트 엔지니어링 고려사항
- 명확하고 직관적인 프롬프트 제공
- 데이터베이스 스키마 정보 포함
- 주석이 달린 예제 포함 (자연어 프롬프트와 해당 SQL 쿼리)
- RAG 활용
- 최적화 및 모범 사례
- 캐싱
- 파싱된 SQL 및 인식된 쿼리 프롬프트 캐싱
- 대기 시간 개선, 비용 통제, 표준화
- 모니터링
- 쿼리 파싱, 프롬프트 인식, SQL 생성, 결과에 대한 로그 및 메트릭 수집
- 구체화 뷰(Materialized views) vs. 테이블
- 일반적인 Text2SQL 쿼리를 위한 구체화 뷰 사용
- SQL 생성 단순화 및 성능 향상
- 데이터 리프레시
- 구체화 뷰의 주기적 리프레시
- 배치 또는 증분 리프레시 접근 방식 사용
- 중앙 데이터 카탈로그
- 조직의 데이터 소스에 대한 단일 창 뷰 제공
- LLM의 정확한 테이블 및 스키마 선택 지원
- 캐싱
- 아키텍처 패턴
- 프롬프트 엔지니어링
- 테이블 및 스키마 세부 정보와 샘플 쿼리가 포함된 프롬프트 사용
- Amazon Bedrock 또는 JumpStart 파운데이션 모델 활용
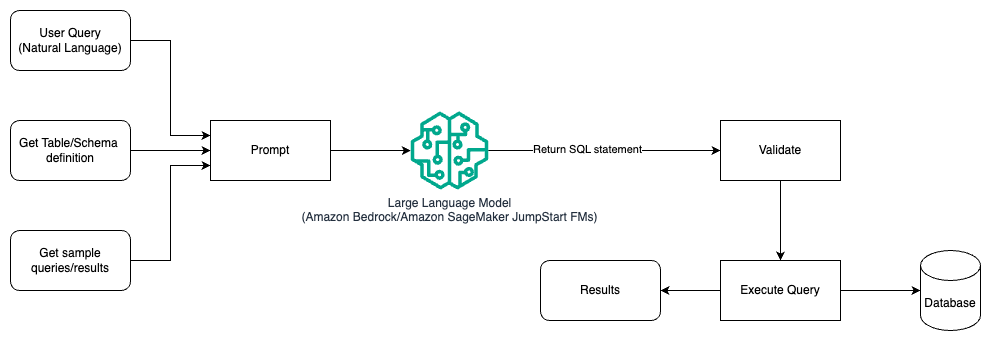
- 프롬프트 엔지니어링 및 파인튜닝
- 도메인별 데이터셋으로 LLM 파인튜닝
- SageMaker JumpStart 사용

- 프롬프트 엔지니어링 및 RAG
- 중앙 데이터 카탈로그의 벡터 임베딩 사용
- Amazon Titan Embeddings 또는 Cohere Embed on Amazon Bedrock 활용
- 벡터 데이터베이스로 Vector Engine for Amazon OpenSearch Serverless, pgvector 확장 기능이 있는 PostgreSQL용 Amazon RDS, 또는 Amazon Kendra 사용
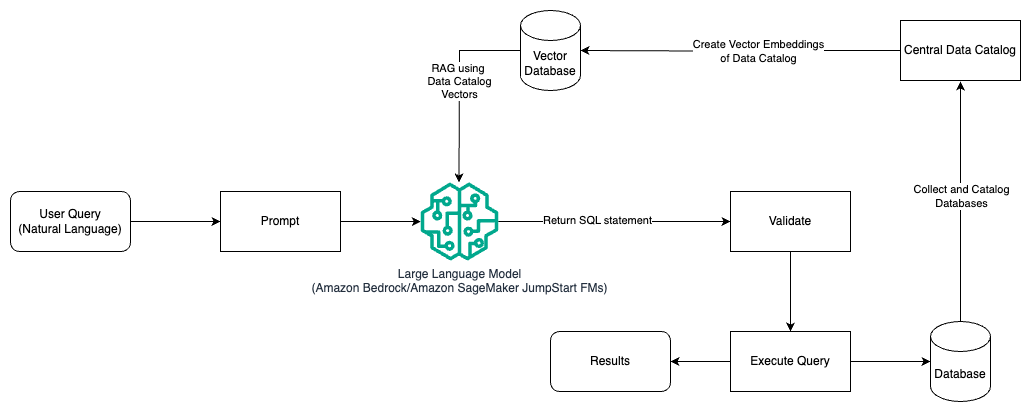
- 프롬프트 엔지니어링
How We Built Text-to-SQL at Pinterest (2024, Pinterest)
- 초기 버전 아키텍처
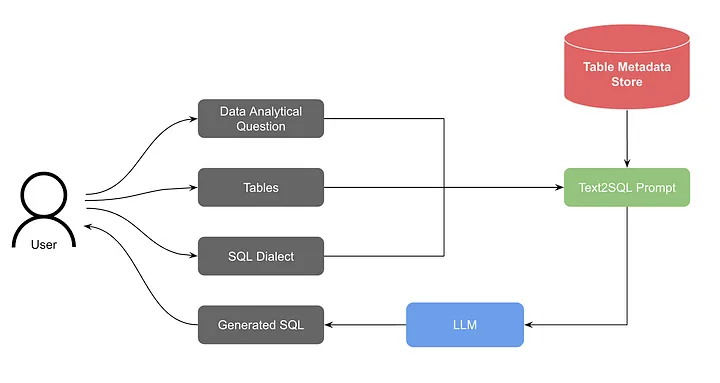
- 사용자의 분석 질문과 선택된 테이블을 입력으로 받음
- 테이블 메타데이터 스토어에서 관련 스키마 정보 검색
- 질문, SQL 방언, 테이블 스키마를 조합하여 프롬프트 생성
- LLM을 통해 SQL 쿼리 생성
- WebSocket을 이용한 스트리밍 응답 구현
- 테이블 스키마 처리
- 테이블명, 설명, 컬럼 정보(이름, 타입, 설명) 포함
- 낮은 카디널리티 컬럼의 고유 값 정보 추가하여 정확도 향상
- 컨텍스트 윈도우 제한 대응
- 축소된 테이블 스키마 버전 사용
- 메타데이터 태그 기반 컬럼 제외
- 응답 스트리밍
- WebSocket 사용
- LangChain의 부분 JSON 파싱 활용
- 평가 및 학습
- Spider 데이터셋으로 초기 성능 평가
- 실제 사용자 상호작용 관찰 (첫 번째 생성 SQL 수용률 20%에서 40%로 향상)
- AI 지원으로 작업 완료 속도 35% 개선
- RAG 통합
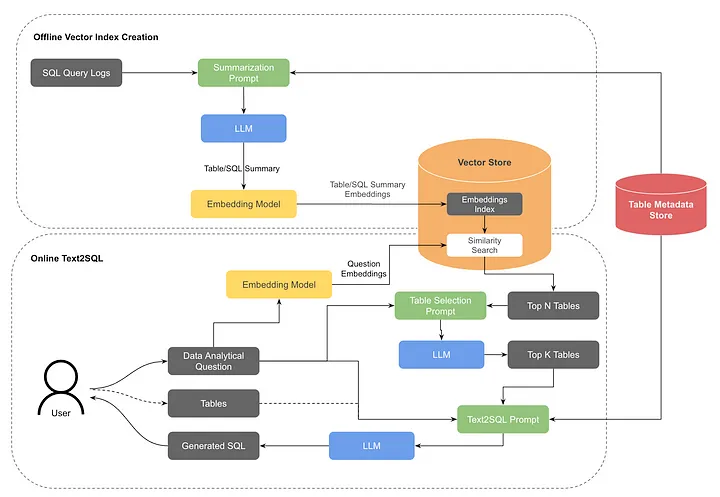
- 테이블 요약과 과거 질의에 대한 벡터 인덱스 생성
- 사용자 질의를 임베딩으로 변환하여 유사도 검색 수행
- LLM을 사용해 상위 K개의 가장 관련성 높은 테이블 선택
- 오프라인 벡터 인덱스 생성
- 테이블 요약 및 쿼리 요약 문서 임베딩
- 상위 티어 테이블만 인덱싱하여 고품질 데이터셋 사용 촉진
- NLP 기반 테이블 검색
- OpenSearch를 벡터 스토어로 사용
- 테이블 및 쿼리 벡터 인덱스에 대한 유사도 검색 수행
- 간단한 점수 집계 전략 사용 (테이블 요약에 더 높은 가중치 부여)
- 테이블 재선택
- LLM을 사용해 상위 N개 테이블 중 가장 관련성 높은 K개 선택
- 사용자 검증 후 SQL 생성 단계로 진행
- 평가 및 향후 개선 방향
- 오프라인 데이터를 사용한 테이블 검색 컴포넌트 평가
- 메타데이터 개선, 실시간 인덱스 업데이트, 유사도 검색 및 점수 전략 개선
- 쿼리 검증, 사용자 피드백 수집, 실제 환경을 반영한 벤치마크 개발 등
LLM for Text2SQL: Paper Notes and Thoughts Beyond Paper (2024)
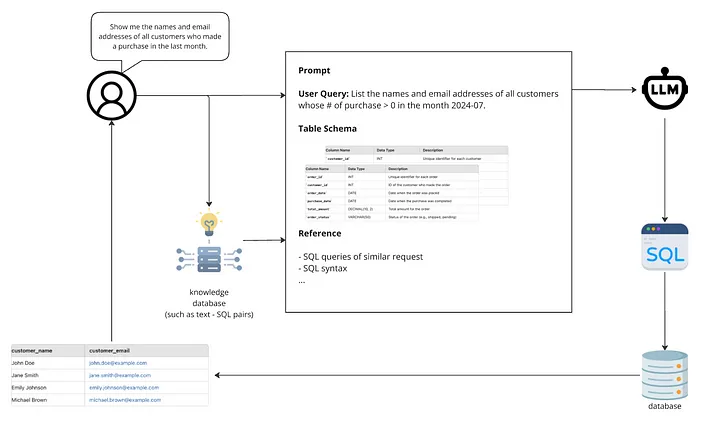
- 일반적인 Text2SQL 워크플로우
- 사용자 요청 접수
- 프롬프트 템플릿 구성
- 관련 테이블 스키마 및 컬럼 정의 가져오기
- 지식 데이터베이스에서 정보 수집
- LLM에 완성된 프롬프트 전송
- SQL 스크립트 생성 및 실행
- 결과를 사용자에게 반환
- 주요 최적화 영역
- 프롬프트 엔지니어링
- 파인튜닝
- 프롬프트 엔지니어링 기법
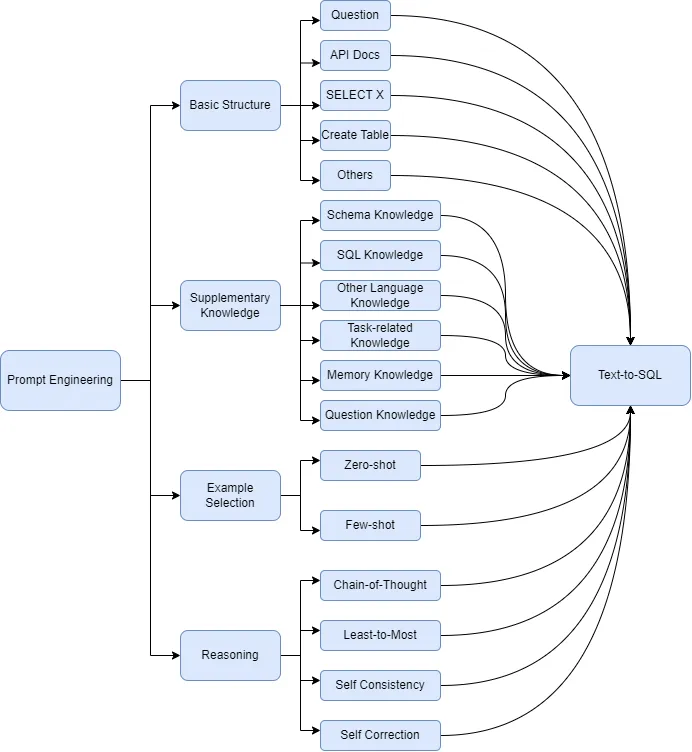
- 기본 구조: 자연어 문제와 데이터베이스 스키마 포함
- 보충 지식: 스키마, SQL, 작업 특정 지식 추가
- 예제 선택: 제로샷 vs 퓨샷 접근법
- 추론: Chain of Thought, Least-to-Most, Self-Consistency, Self-Correction
- 파인튜닝 관련
- 새로운 데이터셋 준비 방법
- LoRA, QLoRA 등의 기법
- 모델 평가 방법: 메트릭 분석, 카테고리 분석, LLM 기반 분석
- 주요 연구 논문 및 접근법
- DIN-SQL: 작업 분해 및 자체 수정
- C3SQL: 제로샷 프롬프트 설정에 초점
- DAIL-SQL: 기존 프롬프트 엔지니어링 방법의 종합 비교
- DBCopilot: 대규모 데이터베이스에 대한 자연어 질문 확장
- MAC-SQL: 멀티 에이전트 협업 프레임워크
- PET-SQL: 프롬프트 강화 2라운드 개선 및 교차 일관성
- 실제 적용 시 고려사항
- 목표 사용자 정의의 중요성
- 고품질 쿼리 수집 방법
- 대규모 데이터 웨어하우스에서의 스키마 연결 문제
- 모호한 컬럼 이름 처리
- 인간 개입(Human-in-Loop) 필요성
- 데이터 프라이버시 문제
- SQL 실행 책임 문제
- 자체 수정 또는 품질 판단 메커니즘
- 향후 시도해볼 만한 프레임워크
- DB-GPT-Hub
- DAMO-ConvAI
QueryGPT – Natural Language to SQL Using Generative AI (Uber, 2024)
- 아키텍처
- 초기 버전
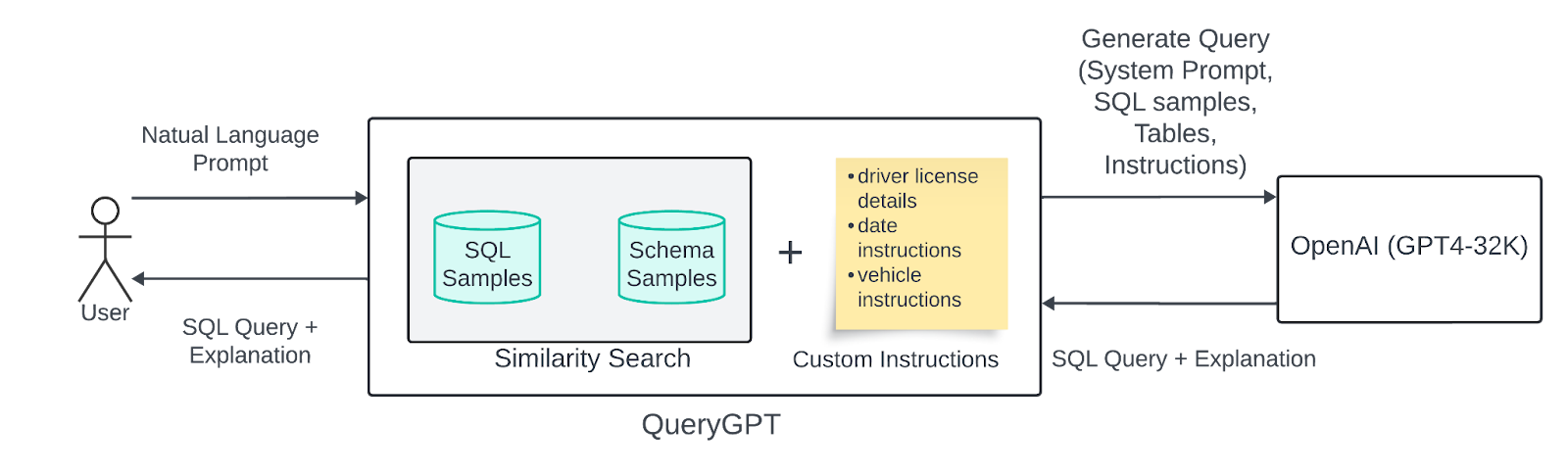
- RAG을 사용해 관련 샘플 검색
- 사용자의 자연어 입력을 벡터화하여 유사도 검색 수행
- 7개의 핵심 테이블과 20개의 SQL 쿼리를 샘플 데이터로 사용
- 스키마 샘플, SQL 샘플, 사용자 입력, Uber 업무 지침을 LLM에 전달
- 현재 버전
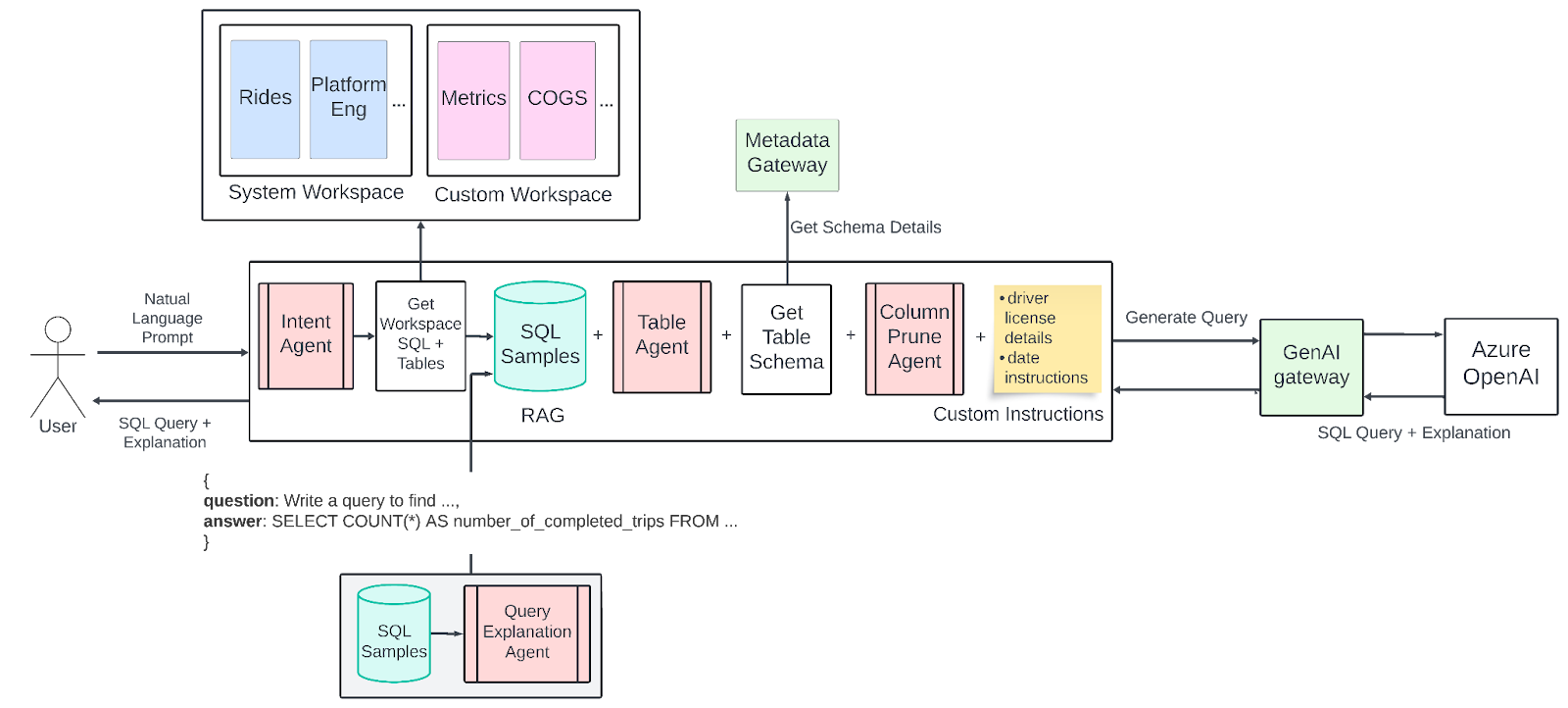
- 작업 공간 개념 도입 (특정 업무 영역에 맞춘 SQL 샘플과 테이블 모음)
- 의도 판단 에이전트: 사용자 질문을 업무 영역/작업 공간에 연결
- 테이블 선택 에이전트: 쿼리 생성에 사용할 적절한 테이블 선택
- 컬럼 정리 에이전트: 불필요한 컬럼을 제거하여 토큰 사용량 최적화
- 초기 버전
- 사용된 기술
- LLM
- 벡터 데이터베이스
- 유사도 검색 (k-최근접 이웃)
- 퓨샷 프롬프팅
- 개선 사항
- 향상된 RAG 구현
- 사용자 의도 이해를 위한 중간 단계 도입
- 대규모 스키마 처리 개선
- 평가 방법
- 표준화된 평가 절차 개발
- 실제 질문-SQL 답변 쌍 수동 선별
- 다양한 제품 흐름에 대한 평가 (기본, 분리 측정)
- 정확도, 응답 시간 등의 지표 추적
- 기술적 난제와 해결책
- 토큰 크기 문제: 컬럼 정리 에이전트로 해결
- 환각(오류 생성) 문제: 입력 최적화, 대화형 모드 도입, 검증 에이전트 실험
- 사용자 입력 품질 문제: 입력 확장기 도입 고려
- 사용된 모델
- OpenAI GPT-4 Turbo (128K 토큰 제한)
- 성과
- 300명의 일일 활성 사용자
- 78%의 사용자가 쿼리 작성 시간 단축 보고
State of Text2SQL (2024)
- Text2SQL의 역사와 발전
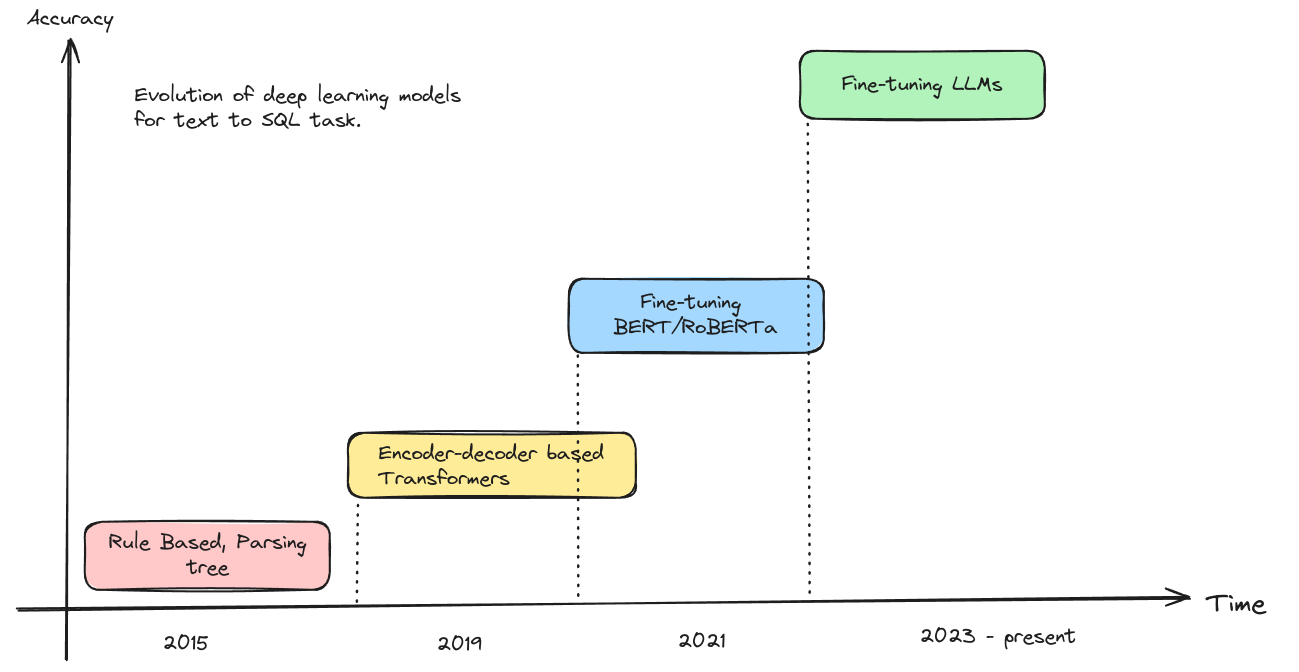
- 2015년부터 연구 시작, 초기에는 파싱 트리와 규칙 기반 접근법 사용
- 2019년 이후 LSTM, Transformer 기반 모델 등장
- 2021년부터 BERT, RoBERTa 등 사전 훈련된 언어 모델 미세조정 방식 채택
- 현재는 GPT, Llama 등 LLM 기반 접근법이 주류
- 주요 데이터셋
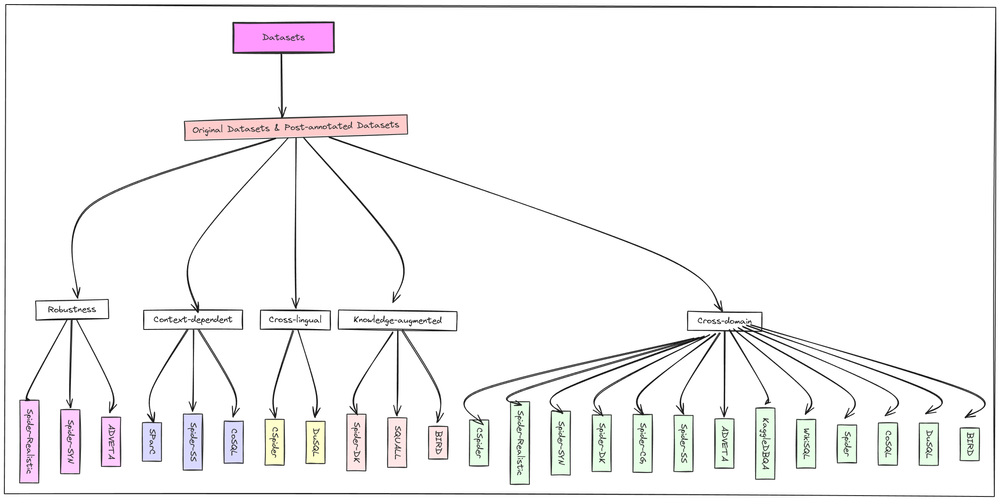
- 벤치마크용: Spider, BIRD, SParC, KaggleDBQA 등
- 미세조정용: WikiSQL, BIRD 등
- 데이터셋 유형
- 크로스 도메인
- 지식 증강
- 맥락 의존적
- 평가 방법 및 지표
- 내용 매칭 기반 평가
- 컴포넌트 매칭: SQL 문의 각 구성 요소를 추출하여 비교 (F1 점수 사용)
- 정확 매칭: 모든 구성 요소가 100% 일치해야 정답으로 간주
- 실행 기반 평가
- 실행 정확도(EX): 생성된 SQL 쿼리 실행 결과와 정답 비교
- 유효 효율성 점수(VES): 쿼리의 정확성과 성능 최적화 정도를 평가
- 내용 매칭 기반 평가
- 현재 모델 및 기술
- 인 컨텍스트 학습
- 단순 프롬프팅: 제로샷 또는 퓨샷 설정
- 분해: 복잡한 질문을 단순한 하위 질문으로 분해
- 프롬프트 최적화: 프롬프트 품질 및 구조 개선
- 추론 강화: Chain-of-Thought, Program-of-Thought 등 고급 추론 기법 사용
- 실행 개선: SQL 실행 결과를 피드백으로 활용하여 개선
- 파인튜닝
- 데이터 증강: 기존 데이터를 변형하여 추가 학습 예제 생성 (DAIL-SQL, SymbolLM, CodeS)
- 분해 기법: 복잡한 작업을 관리 가능한 하위 작업으로 분할
- 인 컨텍스트 학습
- 향상된 벤치마크 접근
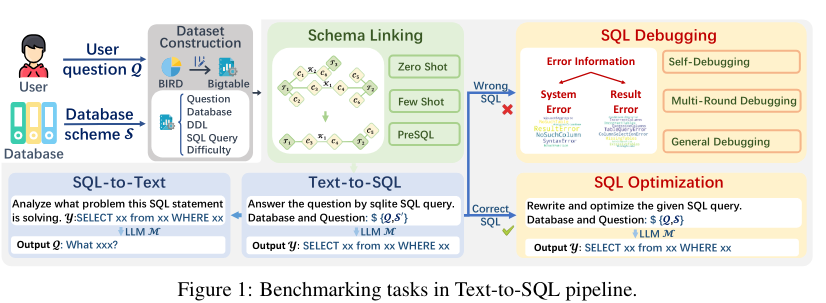
- 5가지 SQL 태스크 포함한 새로운 데이터셋
- 최적화된 프롬프트 사용
- 다중 라운드 생성과 자체 디버깅
- 엔드-투-엔드 평가 파이프라인
- 에이전트 프레임워크
- MAC-SQL
1) Decomposer 에이전트: 퓨샷 Chain-of-Thought 추론으로 Text-to-SQL 쿼리 생성
2) Selector 에이전트: 관련 데이터베이스 스키마 부분 식별
3) Refiner 에이전트: 외부 도구를 사용하여 오류 있는 SQL 쿼리 개선- GPT-4를 기반으로 하며, 오픈소스 모델 SQL-Llama를 미세조정하여 유사한 성능 달성
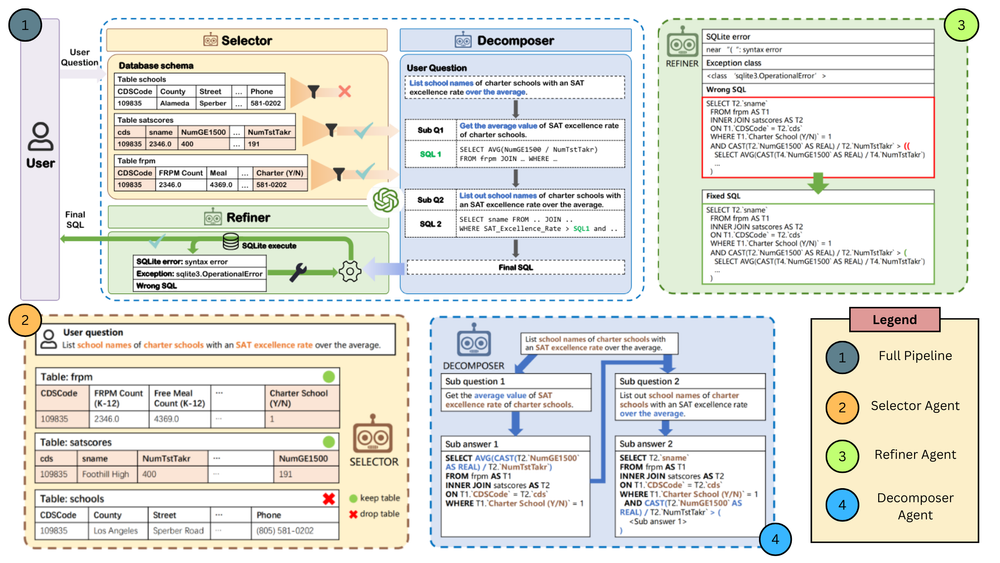
- GPT-4를 기반으로 하며, 오픈소스 모델 SQL-Llama를 미세조정하여 유사한 성능 달성
- MAC-SQL
3. 참조

Sr. Data Scientist at AWS