크롤링이란?
- 웹 페이지에서 필요한 데이터를 추출해내는 작업
- 웹 페이지는 정보를 HTML 문서로 표현
- HTML을 얻기 위해 requests 라이브러리, 가져온 HTML을 분석하기 위해 BeautifulSoup 라이브러리를 사용
BeautifulSoup 라이브러리

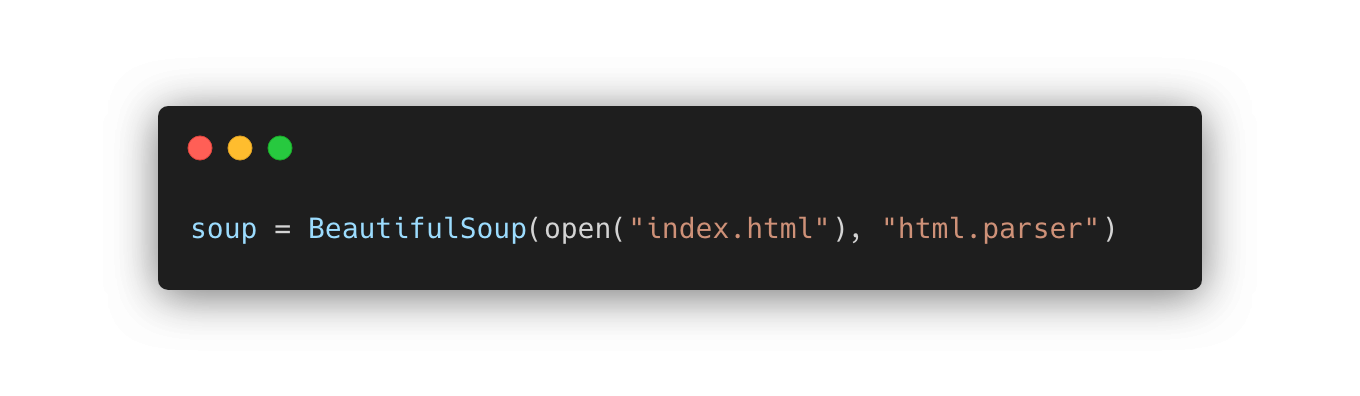
- HTML 파일로 BeautifulSoup 객체를 만들 수 있음
"html.parser": HTML을 분석하라고 알려줌find, find_all: HTML 태그 추출find: 추출한 HTML 태그 하나를 얻음find_all: HTML 태그를 여러 개 담고 있는 리스트를 얻음class_매개변수에 값을 저장함으로써 특정 클래스를 가진 태그 추출get_text(): 태그가 갖고 있는 텍스트를 얻을 수 있음
requests 라이브러리
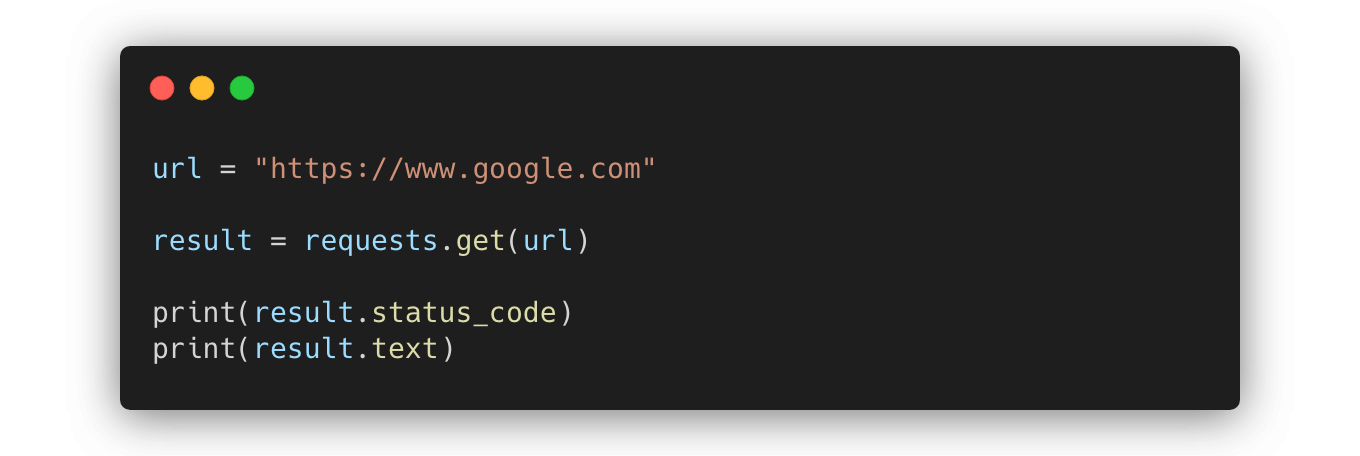
get: 정보를 조회하기 위한 요청- 지정한 URL로 GET 요청을 보냈고, 서버에서는 요청을 받아 처리한 후 result 변수에 응답을 보냄
status_code: 요청의 결과를 알 수 있음text: 요청 성공 시 해당 웹 사이트의 HTML을 얻을 수 있음
Query

- 웹 서버에 GET 요청을 보낼 때 조건에 맞는 정보를 표현하기 위한 변수
requests의 get메소드로 GET 요청을 보낼 때 params 매개변수에 딕셔너리를 전달함으로써 쿼리를 지정- q라는 변수에 elice 라는 값이 담겨, 전체 데이터 중 elice라는 키워드로 검색한 결과만을 보여줌
태그와 속성
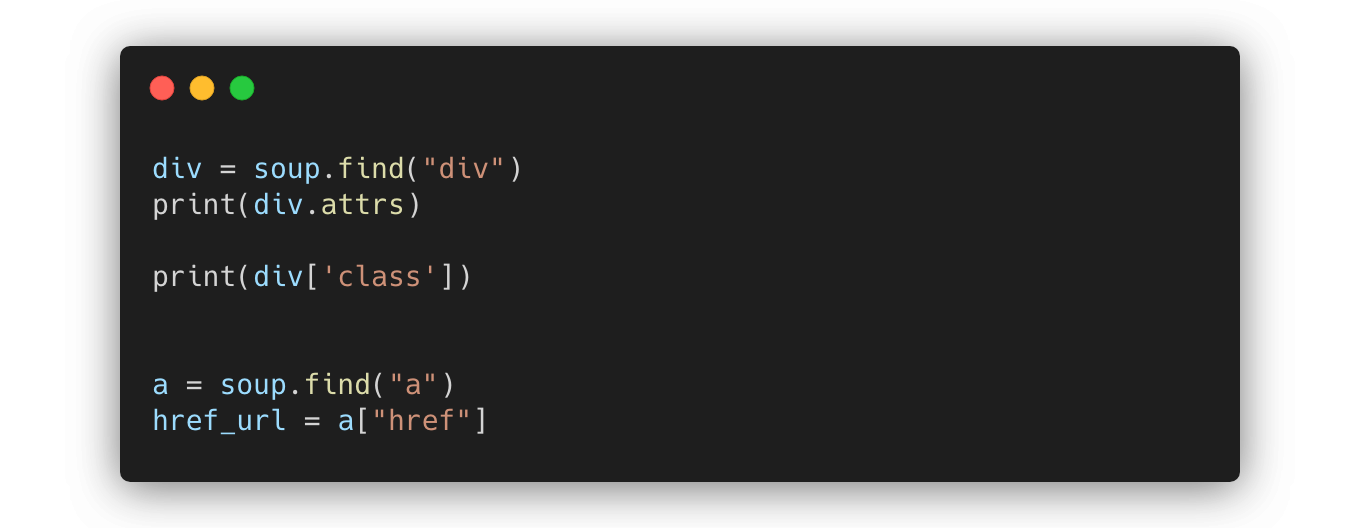
attrs: 어떤 태그의 속성이 무엇이 있는지 확인할 때 attrs 멤버변수를 출력div['class']: attrs 딕셔너리의 키로 인덱싱해 태그의 속성에 접근a["href"]: href 속성을 이용해 웹 페이지에 존재하는 하이퍼링크의 URL을 얻을 수 있음
Children, Name
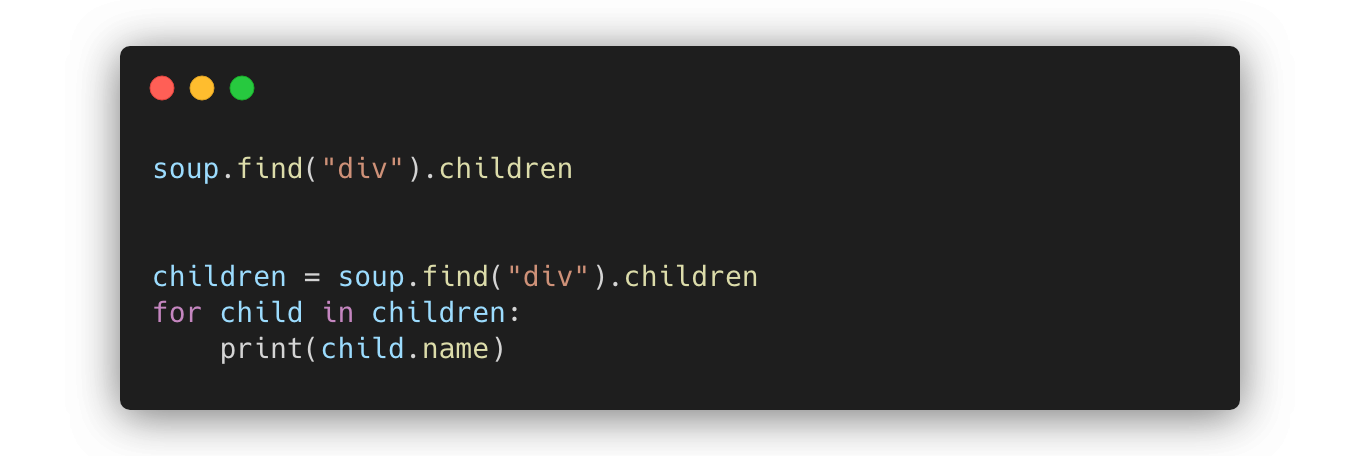
soup.find("div").children: 어떤 div 태그를 찾고, 해당 div 태그에 포함된 태그들의 리스트를 얻음name: 태그의 이름을 알고 싶을 때 사용하며 태그가 존재하지 않는 경우에는 None 값을 얻음
출처
K-Digital Training x 엘리스, 인공지능 서비스 기획 1기
.png)