1) 알고리즘이란?
Q. 다음과 같이 숫자로 이루어진 배열이 있을 때, 이 배열 내에서 가장 큰 수를 반환하시오.
[3, 5, 6, 1, 2, 4] # 6을 반환하면 된다.
- 하지만 만약 배열 내의 수가 1억 개라면, 어떻게 가장 큰 숫자를 빠르게 고를 수 있을까?
- 내 컴퓨터가 후져서 램이 너무 작다면?
- 알고리즘은 이런 상황이 주어졌을 때, 최악의 상황을 예상해서 답을 도출하는 시간을 기하급수적으로 줄일 수 있도록 가장 적은 양의 계산으로 돌아갈 수 있도록 효율적인 방법을 찾는 과정이다.
2) 알고리즘 기초
EXAMPLE. 최빈값 찾기
Q. 다음과 같은 문자열을 입력받았을 때, 어떤 알파벳이 가장 많이 포함되어 있는지 반환하시오
"hello my name is sparta"
해결책 2개. 둘 중에 뭐가 나을까?
import string
from pprint import pprint
text = 'hello, this is sparta'
# 해결책 1 : 21 번 연산
counter = {}
for char in text:
if not char.isalpha():
continue
if char in counter:
counter[char] += 1
else:
counter[char] = 1
pprint(counter)
# 해결책 2 : 26(알파벳 소문자 갯수) * 21 번 연산
counter2 = {}
for lo in string.ascii_lowercase:
for char in text:
if lo == char:
if lo in counter2:
counter2[lo] += 1
else:
counter2[lo] = 1
pprint(counter2)
# for문이 중첩된다 싶으면 한번은 의심해봐야함.> 점근 표기법
알고리즘의 성능을 수학적으로 표기하는 방법 = 알고리즘의 “효율성”을 평가하는 방법
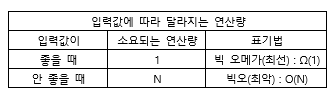
- 빅오(Big-O)표기법 : 최악의 성능이 나올 때 어느 정도의 연산량이 걸리는지 표기
- 빅 오메가(Big-Ω) 표기법 : 최선의 성능이 나올 때 어느 정도의 연산량이 걸리는지에 대해 표기 (거의 안 씀)
- 위 최빈값 찾기 해결책 코드를 점근 표기법으로 표기하면,
1번 코드 - 빅오 표기법 : O(N)
2번 코드 - 빅오 표기법 : O(N^2)
EXAMPLE. 배열에서 특정 요소 찾기
Q. 다음과 같은 숫자로 이루어진 배열이 있을 때, 이 배열 내에 특정 숫자가 존재한다면 True, 존재하지 않다면 False 를 반환하시오.
[3, 5, 6, 1, 2, 4]
def is_number_exist(num, arr):
for el in arr: # array 의 길이만큼 아래 연산이 실행
if num == el: # 비교 연산 1번 실행
return True
return False
- 첫 번째 원소부터 찾으면 한 번에 찾을 수 있지만 : 총 1의 시간 복잡도를 가진다.(최선)
- 마지막 원소에서 찾으면 input(입력값)의 길이(N)만큼 연산 이후에 찾게 된다. : 총 N의 시간 복잡도를 가진다. (최악)
- 빅오(최악) : O(N)
- 빅 오메가(최선) : Ω(1)
- 알고리즘 성능은 항상 동일한 것이 아니라 입력값에 따라서도 달라질 수 있다.
- 따라서, 자료가 어떤 값을 가지고 있는지, 어떤 패턴을 이루는 데이터인지에 따라서 어떤 알고리즘이 좋은 알고리즘인지가 달라질 수 있다.
- 알고리즘에서는 대부분의 입력값이 최선의 경우일 가능성은 굉장히 적을 뿐더러, 최악의 경우를 대비해야 하기 때문에 거의 모든 알고리즘을 빅오 표기법으로 분석한다.
3) 시공간 복잡도
> 시간 복잡도
입력값과 문제를 해결하는 데 걸리는 시간과의 상관관계
ex) 입력값이 2배로 늘어났을 때 문제를 해결하는 데 걸리는 시간은 몇 배로 늘어나는지를 보는 것
> 공간 복잡도
입력값과 문제를 해결하는 데 걸리는 공간과의 상관관계
ex) 입력값이 2배로 늘어났을 때 문제를 해결하는 데 걸리는 공간은 몇 배로 늘어나는지를 보는 것
EXAMPLE. 알파벳 찾기
import string
# string.ascii_lowercase = 'abce...z'
def get_idx_naive(word): # word: 'backjoon'
# result = [-1(a=0번째), -1(b=1번째), -1(c=2번째), ..., -1(z=25번째)]
result = [-1]*len(string.ascii_lowercase) # result = {list : 26}[-1,-1,-1,...,-1]
for i in range(len(word)): # i: 0 i를 0부터 7까지 돌린다.
char = word[i] # char: 'b', 단어의 몇 번째 알파벳을 가지고 반복문을 돌릴건지 멈춰 놓고 보자.
for j in range(len(string.ascii_lowercase)): # j: 0
lo = string.ascii_lowercase[j] # lo: 'a' (char와 같지 않으니까 넘어가고) j: 1 lo: 'b'
if result[j] == -1 and char == lo: # 'result[j] == -1'를 검사하는 이유 : 알파벳이 연속해서 있을 때, 앞에 것이 이미 반복문을 돌았는지 확인하기 위해서
result[j] = i # char: 'b' lo: 'b'이기 때문에 result리스트의 j: 1(0번째에 a돌고 1번째 b도는 중)번째 요소를 i: 0으로 바꿔준다.
# print(result) # [1, 0, -1, -1, 2, -1, -1, -1, -1, 4, 3, -1, -1, 7, 5, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
print(' '.join( # 사이사이에 ' '공백을 넣어서 합쳐라.
[str(num) for num in result]) # result 리스트를 돌면서 숫자들을 str로 바꿔서 join 합쳐라.
) # 1 0 -1 -1 2 -1 -1 -1 -1 4 3 -1 -1 7 5 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
def get_idx(word):
# point 1. ord
# point 2. O(n^2) -> O(n)
result = [-1]*len(string.ascii_lowercase)
for i in range(len(word)):
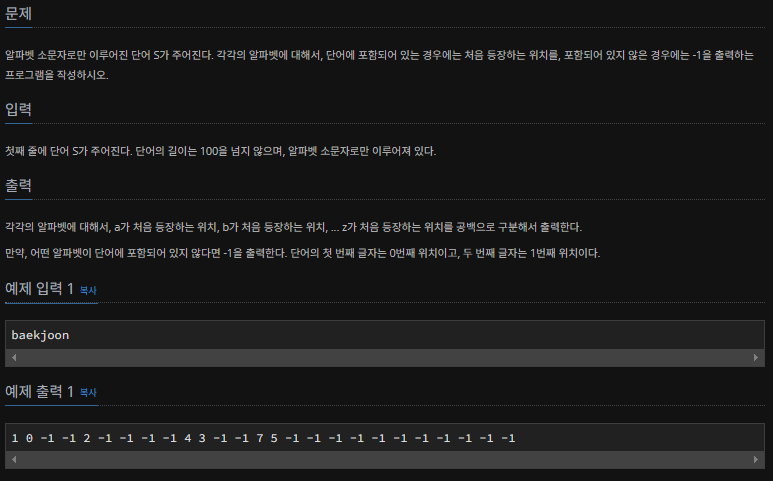
idx = ord(word[i]) - 97 # ord: 문자(알파벳 대소문자) -> 숫자 ex) a -> 97, b -> 98 ... ord('b') - ord('a') = 1
if result[idx] == -1: # 한번도 업데이트 된 적이 없으면, =가리킨 적이 없으면, =등장한 적이 없으면,
result[idx] = i # 그 위치를 적어줘라. ex) idx = 1(b) b에 i: 1을 적어준다.
# idx는 내가 가리키고 있는 알파벳의 위치
print(' '.join([str(num) for num in result]))
get_idx_naive('baekjoon')
get_idx('baekjoon')
- 아스키 코드
- 알고리즘은 시공간 복잡도를 더 효율적으로 다루기 위한 방법론
- for 반복문 = n
- O(n^2)을 O(n)으로 줄이는게 궁극적인 목표
4) 연결 리스트
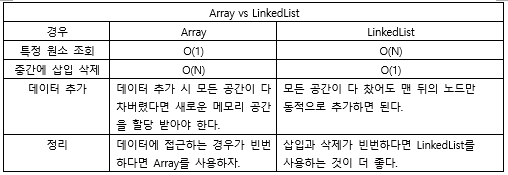
>> 어레이 vs 연결리스트
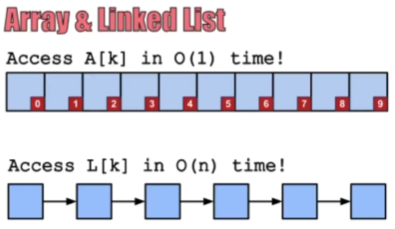
- 어레이: 파이썬의 리스트. 접근 쉬움, 삽입 어려움. (파이썬의 리스트)
- 연결리스트: 직접 구현. 접근 어려움, 삽입 쉬움.
>> 클래스 : 코드를 모아둔 것.
class Person:
def __init__(self, name):
self.name = name
def sayhello(self, to):
print(f"hello {to}, I'm {self.name}")
rtan = Person("rtanny")
rtan.sayhello("hanghae")>> 연결리스트의 구현
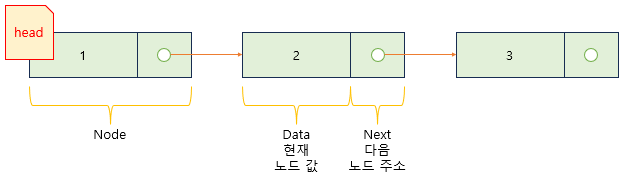
- 연결리스트 : 현재 값와 다음 값의 주소가 반복
네모 상자 1개 + 화살표 1개
class ListNode:
# def __init__(self, val=0, None) : 기본값을 지정하는 문법
def __init__(self, val, next): # 받을 값. self: (생성한 인스턴스 객체)나 val: 값 next: 다음 값의 주소
self.val = val # 받은 값을 저장. self.val = val: 나의 value = 값
self.next = next # self.next = next: 나의 next = 다음 값 주소
1. 리스트를 입력 받음.class LinkedList: # 삽입, 삭제 기능이 있어야함.
def __init__(self):
self.head = None # 3번째 메모리 박스로 접근하려면 1번째 박스로 가서 순차적으로 접근할 수 밖에 없는데 이때, 1번째 박스를 head라고 하자.
# 'None': 아직 아무 데이터도 안 들어왔다. (or ListNode(None,None))
def append(self, val):
if not self.head: # 만약, head가 없으면
self.head = ListNode(val, None) # 다음 값(요소)은 없고 입력 받은 값을 넣어주는 ListNode를 만들어서 head라고 하자.
return # 왜 다음은 없는 ListNode 박스를 만드냐 : 하나하나 붙여주는데 마지막 박스에는 다음 값을 넣어주기 전까지는 화살표(다음 값의 주소)는 None일 것이다.
node = self.head # 내가 바라보고 있는 노드를 head라고 한다.
while node.next: # node에 다음이 있는 한, 화살표가 존재하는 한
node = node.next # 다음으로 계속 넘어감. while문이 끝났을 때 바라보고 있는 node는 제일 끝 node일 것.
node.next = ListNode(val, None) # ListNode 박스를 새로 하나 만들어서 다음 node에 붙여준다. = append
2. self.head가 없으면 ListNode 박스를 넣음.
3. head가 이미 있다면, 쭉 넘어가서 마지막에 박스를 넣어준다.
lst = [1,2,3] # LinkedList화 시켜보자.
l1 = LinkedList() # LinkedList 객체를 하나 만든다.
for e in lst:
l1.append(e) # lst에 있는 모든 요소를 l1에 append하고 node들에 어떻게 들어가 있는지 보자.
print(l1)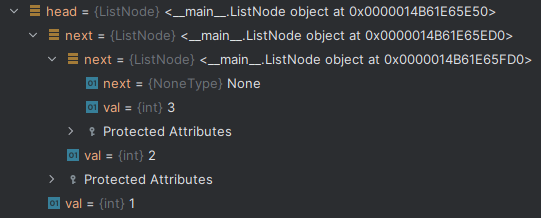
- lst의 요소 123이 순차적으로 들어가 있고 next도 순차적으로 들어가있다.
>> Example. 팰린드롬 연결 리스트
- 팰린드롬 : (회문) 앞뒤 어느 방향으로 읽어도 동일하게 읽히는 역반복 구조
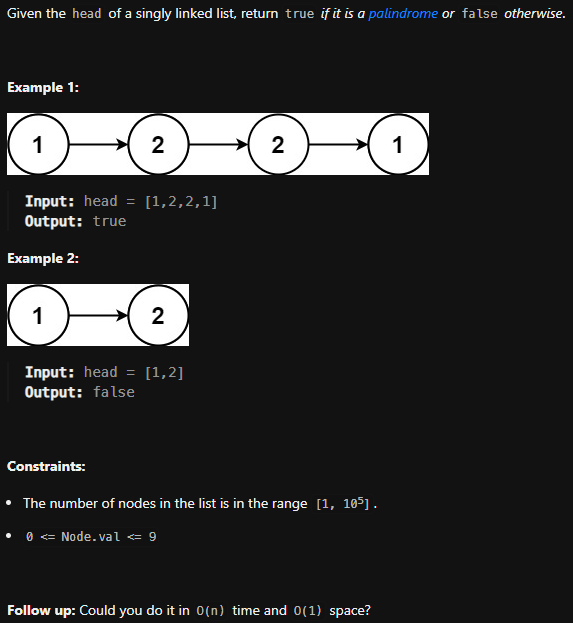
from linkedlist.prac import isPalindrome
from linkedlist.structures import LinkedList
l1 = LinkedList()
for num in [1, 2, 2, 1]:
l1.append(num)
l2 = LinkedList()
for num in [1, 2]:
l2.append(num)
assert isPalindrome(l1.head) # assert : (확언) True인지 False인지 알려줌.
assert not isPalindrome(l2.head)
# 만들어진 연결리스트가 팰린드롬인지 아닌지 판볋하는 isPalindrom()이라는 함수를 만들자.def isPalindrome(head): # 함수는 head를 넘겨받음.
arr = [] # 연결리스트에 있는 값들을 빈 리스트에 넣어서 값을 하나하나 비교해 볼 것이다.
if not head: # 만약 head가 없다면 : 빈 연결리스트이다.
return True # True를 반환
node = head # 첫 node가 head
while node:
arr.append(node.val)
node = node.next # node의 값을 head부터 다음 node로 순차적으로 확인하면서 값들을 arr에 넣는다.
while len(arr) > 1: # 대칭인지 보려면 적어도 두 개의 값이 필요하기 때문에 길이가 1보다는 커야함.
if arr.pop(0) != arr.pop(): # 제일 앞의 것을 꺼내고 제일 뒤의 것을 꺼내서 한 번이라도 같지 않으면,
return False # False를 반환
return True # 모든 조건을 통과하면 True를 반환
# pop() : 요소 꺼내기
arr = [1,2,3,4]
arr.pop() # 4
arr.pop(0) # 1
arr = [2,3]5) 스택 : 한쪽 끝으로만 자료를 넣고 뺄 수 있는 자료 구조.
> 스택이란 자료 구조는 "빨래통"?
제일 먼저 넣은 빨래는 가장 밑의 빨래로 가장 나중에 뺄 수 있고, 가장 나중에 넣은 빨래는 가장 위의 빨래로 제일 먼저 뺄 수 있다.
이런 자료 구조를 Last In First Out 이라고 해서 LIFO(후입선출) 라고 부른다.
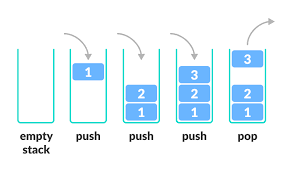
[출처 : 까망 하르방 티스토리]
> 스택을 쓰는 이유
내가 했던 행동들을 순서대로 쌓아두고 있기 때문에 바로 전으로 돌아가고 싶을 때 Ctrl+Z 처럼 활용이 가능함.
> 구현 : 세 가지(push, pop, is_empty) 메소드가 필요함.
# 기본 테스트 스캐치
def test_node(): # 값이 들어가는 박스(node)
assert Node(1, None).item == 1 # Node(내가 가진 값, 가리키고 있는 곳).item == 1(내가 가진 값 표시)
def test_stack(): # 스택 선언
stack = Stack() # 스택 만들기
stack.push(1) # 자료(데이터) 순서대로 넣기
stack.push(2)
stack.push(3)
stack.push(4)
stack.push(5)
assert stack.pop() == 5 # 자료(데이터) 후입선출로 빼기
assert stack.pop() == 4
assert stack.pop() == 3
assert stack.pop() == 2
assert stack.pop() == 1
assert stack.pop() is None
assert stack.is_empty() # 비어있는지 확인. 비어있으면 True.class Node: # Node의 정보
def __init__(self, item, next): # Node가 가져야 하는 것들 item = 내가 어떤 값을 가져야하는지, next = 내가 가리키는게 뭔지
self.item = item # 내 값은 item이다.
self.next = next # 내가 가리키고 있는 것은 next이다.
class Stack: # 스택의 정보
def __init__(self): # 일단 쌓인게 없으니 top이 비었다는 것을 표시
self.top = None
def push(self, value): # Node를 만들어 넣어주는데 받은 value(값)을 넣어주고 새로운 탑이 되는 이 Node가 가리키는 것은 기존에 있던 top이다.
self.top = Node(value, self.top)
def pop(self):
if self.top is None: # top이 없으면 꺼낼게 없으니 None을 반환
return None # top을 꺼낸 후 다음 top이 없을 때 오류나는 것을 방지하기 위한 코드
node = self.top # top이 있다면 제일 위에 있는 top을 꺼내고
self.top = self.top.next # 다음 top이 top이 된다.
return node.item # 꺼낸 top의 값을 반환
def is_empty(self): # top이 비어있는지 아닌지를 판단해서 반환
return self.top is None>> 6) 유효한 괄호
# Point
짝이 맞는 괄호는 True, 아니면 False