🥚 파이썬 라이브러리를 활용하여 그래프 그리기
1. 패키지 불러오기
import numpy as np
from matplotlib import pyplot as plt-
numpy : 파이썬에서 다차원 배열을 다루고 수학적 연산을 수행하는 데 사용되는 라이브러리
-
Matplotlib : 데이터 시각화와 그래프 그리기를 위한 라이브러리
-
pyplot 모듈 : 그래프를 그리는 데 사용
2. Numpy를 사용하여 임의의 데이터 생성
data = np.random.randint(-100, 100, 50)"data"라는 변수에 -100부터 99까지의 범위에서 무작위로 선택된 50개의 정수(중복 포함) 배열을 생성
3. Matplotlib를 사용하여 "data" 배열의 누적 합계를 시각화
plt.plot(data.cumsum())
plt.show()-
data.cumsum() : "data" 배열의 각 요소에 대한 누적 합계를 반환
-
plot() : Pandas의 그래프 그리기 함수
-
plt.plot(data.cumsum()) : 누적 합계 데이터를 그래프로 그립니다. 이 그래프는 x축은 데이터 포인트의 인덱스(0부터 시작)를 나타내고, y축은 해당 인덱스까지의 데이터 누적 합계를 나타냅니다.
-
plt.show() : 그래프를 화면에 표시
🐣 pandas_datareader로 데이터를 데이터프레임(표)과 그래프로 출력
1. 패키지 설치
!pip install pandas_datareader2. 삼성전자 1-3분기 주식 데이터를 받아 데이터프레임 출력
- 야후 삼성전자 주식 데이터 : https://finance.yahoo.com/quote/005930.KS
from pandas_datareader import data as pdr
import yfinance as yfin
yfin.pdr_override()
df = pdr.get_data_yahoo('005930.KS', start='2020-01-01', end='2020-09-30')
print('row count:', len(df))
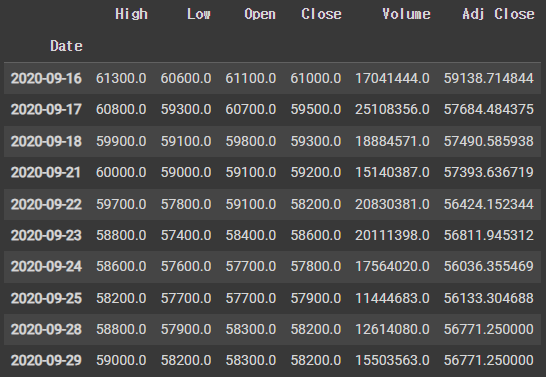
df.tail(10)-
pandas_datareader : 데이터를 가져오기 위한 라이브러리
-
yfinance : Yahoo Finance 데이터에 액세스하기 위한 라이브러리
-
yfinance.pdr_override() : pandas_datareader를 yfinance로 오버라이딩하여 pandas_datareader가 Yahoo Finance를 사용하여 데이터를 가져올 수 있게 합니다.
-
pdr.get_data_yahoo() 함수 : 주어진 종목 코드('005930.KS', 삼성전자 주식)와 기간('2020-01-01'에서 '2020-09-30')에 해당하는 주식 데이터를 Yahoo Finance에서 가져옵니다.
-
df : 데이터프레임(DataFrame)인 "df"에 주식 데이터가 저장됩니다. 이 데이터프레임은 날짜, 시가, 고가, 저가, 종가, 거래량 등의 주식 데이터 열을 포함합니다.
-
df.tail(10) : 데이터프레임의 끝에서 10개의 데이터 포인트를 출력. 이로써 데이터의 마지막 10일치 주식 데이터를 확인할 수 있습니다.
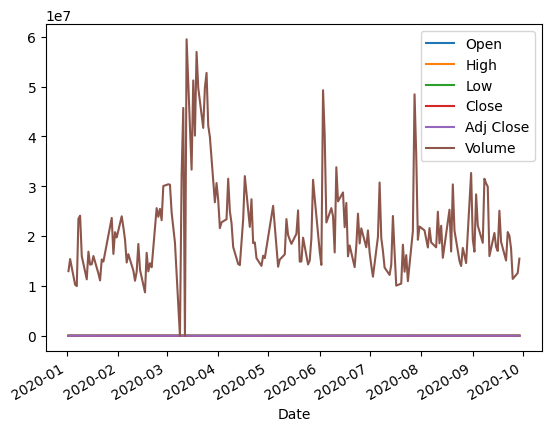
3. 주식의 종가 데이터를 그래프로 그리기
df['Adj Close'].plot()그래프는 Matplotlib를 사용하여 생성되며, 주식의 종가 변동을 시각적으로 나타냅니다.
🐤 선형회귀(Linear Regression) 실습
TensorFlow 1.x 버전
1. 선형 회귀 모델을 구현하기 위한 초기 설정 및 모델 변수를 정의
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x_data = [[1, 1], [2, 2], [3, 3]]
y_data = [[10], [20], [30]]
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2])
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1])
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W')
b = tf.Variable(tf.random.normal(shape=(1,)), name='b')-
TensorFlow : 기계 학습과 딥러닝 모델을 구축하고 학습시키는 데 사용되는 오픈 소스 라이브러리로 이 라이브러리를 활용하여 데이터 분석, 이미지 처리, 자연어 처리 등 다양한 인공지능 작업을 수행할 수 있습니다.
-
tf.compat.v1.disable_eager_execution() : TensorFlow 2.x에서 Eager Execution을 비활성화하고 TensorFlow 1.x와 유사한 실행 모델을 사용하기 위한 설정. Eager Execution이 비활성화된 경우, TensorFlow 그래프를 빌드하고 세션에서 실행해야 합니다.
-
tf.compat.v1.placeholder : TensorFlow 그래프 내에서 데이터를 주입하기 위한 플레이스홀더(Placeholder)를 생성하는 부분
-
tf.compat.v1 모듈 : TensorFlow 1.x 스타일의 기능과 API를 TensorFlow 2.x에서 계속 사용할 수 있도록 지원. v1 모듈을 사용하면 TensorFlow 1.x와 유사한 방식으로 코드를 작성할 수 있으며, 이를 통해 TensorFlow 2.x에서도 1.x와의 호환성을 유지하면서 기존의 코드를 사용할 수 있습니다.
-
placeholder : TensorFlow 그래프 내에서 플레이스홀더는 나중에 실제 데이터를 넣을 수 있는 공간
-
tf.float32 : 데이터 타입
-
[None, 1] : 행은 가변적인 크기를 가질 수 있고, 열은 1개인 2D 텐서(tensor : 다차원 배열)
-
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W') : TensorFlow에서 가중치(W) 변수를 생성하고 정규 분포를 따르는 난수로 초기화하는 부분
-
tf.Variable 함수 : TensorFlow에서 변수를 생성
-
tf.random.normal 함수 : 정규 분포를 따르는 난수로 초기화.
-
shape 매개변수를 통해 텐서의 모양을 지정. 여기서는 (2, 1) 모양을 가진 2행 1열의 행렬을 생성.
-
name 매개변수를 사용하여 변수에 이름을 부여. 모델을 디버깅하거나 모델 구조를 시각화할 때 유용
-
b = tf.Variable(tf.random.normal(shape=(1,)), name='b') : b라는 이름의 편향 변수를 생성하고 정규 분포를 따르는 난수로 초기화
2. 선형 회귀 모델의 가설(hypothesis) 및 손실(cost) 함수, 그리고 경사 하강법 옵티마이저를 정의
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - Y))
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)-
hypothesis : 선형 회귀 모델의 가설. 가설은 입력 데이터 X와 모델의 가중치(W) 및 편향(b)을 사용하여 계산
-
tf.matmul(X, W) : 입력 데이터 X와 가중치 W 간의 행렬 곱셈을 수행하고, 그 결과에 편향 b를 더합니다.
-
cost : 모델의 손실 함수. 여기에서는 평균 제곱 오차(Mean Squared Error, MSE)를 사용
-
tf.square(hypothesis - Y) : 예측값과 실제값의 차이를 제곱한 값
-
tf.reduce_mean 함수 : 제곱 오차들의 평균을 계산
-
tf.compat.v1.train 모듈 : TensorFlow v1에서 사용되던 훈련 관련 함수와 클래스를 포함하는 모듈로 경사 하강법 옵티마이저를 생성할 수 있습니다.
-
optimizer : 모델을 학습시키기 위한 최적화 알고리즘을 정의. 여기에서는 경사 하강법(GradientDescent) 옵티마이저를 사용
-
learning_rate 매개변수를 통해 학습률(learning rate)을 설정. 경사 하강법은 모델의 파라미터인 W와 b를 조정하여 손실 함수를 최소화하는 방향으로 업데이트
-
minimize(cost) : 손실 함수(cost)를 최소화하도록 모델의 파라미터를 조정하겠다는 의미
=> 선형 회귀 모델의 학습을 정의하고, 손실 함수를 최소화하기 위해 경사 하강법을 사용
3. TensorFlow v1 스타일로 작성된 선형 회귀 모델을 학습하고 테스트
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
for step in range(50):
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data})
print('Step: %2d\t loss: %.2f\t' % (step, c))
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}))-
with tf.compat.v1.Session() as sess : TensorFlow 세션을 열고 sess로 세션에 접근 (TensorFlow v1 스타일에서는 세션을 열어 그래프를 실행 / TensorFlow v2에서는
eager execution 모드가 기본으로 활성화) -
sess.run(tf.compat.v1.global_variables_initializer()) : TensorFlow에서 변수를 사용하기 전에 모든 변수를 초기화
-
c, W, b, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data}) : cost, W, b, 그리고 optimizer를 실행하여 손실 함수 값(cost)과 가중치(W) 및 편향(b)을 업데이트
-
feed_dict : 데이터를 모델에 공급
-
print('Step: %2d\t loss: %.2f\t' % (step, c)) : 각 학습 단계에서 손실 값을 출력
-
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]}) : 학습된 모델을 사용하여 입력 X에 대한 예측을 출력. 여기서는 [4, 4]를 입력으로 제공하고 해당 입력에 대한 예측 값을 출력
-
학습 단계(Step)와 손실(loss) 값을 출력
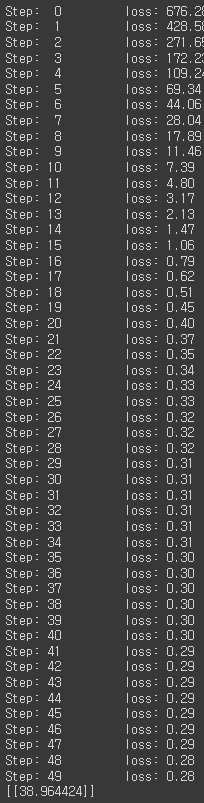
=> 학습이 진행됨에 따라 손실 값이 감소 : 모델이 학습 데이터에 대한 예측과 실제 값 간의 오차를 줄이고 있는 것을 의미합니다. 마지막 학습 단계에서 손실 값은 약 0.28로 수렴하였으며, 이는 모델이 입력 [4, 4]에 대한 예측을 수행하기에 충분히 좋은 상태임을 나타냅니다. 학습된 모델을 사용하여 새로운 입력에 대한 예측을 수행할 수 있습니다.
🐥 Keras를 사용하여 선형 회귀 모델을 구현
Keras는 TensorFlow의 상위 수준 API로, 딥러닝 모델을 더 쉽게 구축하고 학습할 수 있게 도와줍니다.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers.legacy import Adam, SGD
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(learning_rate=0.1))
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!-
Sequential 모델 : 층(layer)을 순차적으로 쌓아 나가는 가장 간단한 형태의 딥러닝 모델
-
Dense 레이어 : 하나의 뉴런을 가지며 입력과 출력을 모두 연결하는 선형 회귀 모델
-
Adam (Adaptive Moment Estimation) : 더 나은 수렴을 제공하는 경사 하강법 알고리즘 중 하나로, 학습률을 자동으로 조절하면서 모델을 효과적으로 학습시키는 데 사용됩니다. 학습률을 조정하는 데 더 많은 정보를 활용하며 일반적으로 더 빠른 수렴을 가능하게 합니다.
-
SGD (Stochastic Gradient Descent) : 확률적 경사 하강법. 데이터셋이 매우 크거나 모델이 복잡한 경우에서 모델을 학습시킬 때 랜덤하게 선택된 데이터 샘플로 경사 하강법을 수행하는 알고리즘. 간단하고 직관적이지만, 더 많은 조정이 필요할 수 있습니다.
-
x_data : 입력 데이터로, 모델에 입력되고 예측을 위해 사용됩니다.
-
y_data : 목표값(타겟)을 나타내며, 입력 데이터에 대한 원하는 출력값(예측하려는 값)으로 모델이 학습하는 데 사용됩니다.
-
model = Sequential([Dense(1)]) : Keras를 사용하여 모델을 정의하는 부분으로 Sequential 모델은 레이어를 순차적으로 쌓을 수 있도록 해줍니다. 이렇게 층을 쌓으면 입력 데이터가 첫 번째 레이어를 통과하고, 그 다음 레이어, 그리고 그 다음 레이어로 전달되며 최종적으로 출력을 생성합니다.
-
compile 메서드 : 모델을 설정합니다. loss 매개변수에는 손실 함수로 평균 제곱 오차(mean squared error)를 설정합니다. optimizer 매개변수에는 확률적 경사 하강법(SGD)을 사용하고 학습률(learning rate)을 0.1로 설정합니다.
=> 이 설정을 통해 모델은 MSE 손실을 최소화하는 방향으로 학습을 시작하며, SGD를 사용하여 모델의 가중치와 편향을 조정하면서 목표값에 가까운 예측을 만들어갑니다.
Train on 3 samples
Epoch 1/100
3/3 [==============================] - 0s 36ms/sample - loss: 508.8659
Epoch 2/100
3/3 [==============================] - 0s 2ms/sample - loss: 8.0772
Epoch 3/100
....
Epoch 99/100
3/3 [==============================] - 0s 964us/sample - loss: 0.0180
Epoch 100/100
3/3 [==============================] - 0s 621us/sample - loss: 0.0172
<tensorflow.python.keras.callbacks.History at 0x7f8863ba6c18>=> 1차원 데이터(x_data)를 사용하여 간단한 선형 회귀 모델을 학습하는 과정을 보여줍니다.
-
Train on 3 samples : 학습 데이터는 3개의 샘플을 사용합니다. (여기서 x_data와 y_data는 각각 3개의 샘플을 포함하고 있습니다.)
-
Epoch 1/100 : 첫 번째 에포크에서의 학습을 나타냅니다. 전체 학습 데이터를 한 번 모두 사용하여 가중치와 편향을 업데이트합니다.
-
loss: 508.8659: 첫 번째 에포크에서의 평균 제곱 오차(Mean Squared Error, MSE) 값입니다. 초기 무작위로 초기화된 모델의 예측과 실제 값 사이의 오차가 크기 때문에 손실이 큽니다.
-
Epoch 2/100, loss: 8.0772: 두 번째 에포크에서의 손실은 감소했습니다. 모델은 두 번째 에포크에서 가중치와 편향을 업데이트하면서 더 나은 예측을 만듭니다.
=> 이후 에포크가 진행됨에 따라 손실이 계속 감소하며, 모델은 더 나은 예측을 위해 가중치와 편향을 조정합니다.
- Epoch 100/100, loss: 0.0172: 100번의 에포크 동안 학습이 진행되고, 손실은 0.0172로 매우 낮아집니다. 이것은 모델이 주어진 데이터에 대해 더 나은 예측을 수행할 수 있게 되었음을 의미합니다.
=> 따라서, 100번의 에포크 후에 모델은 입력값 x_data와 대응하는 출력값 y_data 간의 관계를 학습하게 되며, 모델이 예측한 결과는 입력값에 따라 10을 곱한 값에 근접하게 됩니다.
학습된 선형 회귀 모델을 사용하여 테스트 데이터 예측하기
y_pred = model.predict([[5]])
print(y_pred)
# [[49.588337]]🐓 캐글 선형회귀 실습
Kaggle (캐글)은 수많은 공개된 데이터셋과 각 데이터셋 별로 사람들이 분석한 결과들을 모아놓은 플랫폼으로 머신러닝 엔지니어가 레벨업 할 수 있는 던전이자, 사냥터입니다. 실제 데이터와 프로젝트를 통해 실력을 향상시킬 수 있는 유용한 자원을 제공합니다.
1. Kaggle API를 사용하기 위해 사용자 이름과 API 키를 설정
import os
os.environ['KAGGLE_USERNAME'] = 'hyeonwoongjang' # username
os.environ['KAGGLE_KEY'] = '...' # key2. 광고 데이터셋 다운로드
!kaggle datasets download -d ashydv/advertising-dataset3. 데이터셋 압축 해제
!unzip /content/advertising-dataset.zip4. 광고 데이터 예측 (Single-variable linear regression) - TV 광고 금액으로 Sales 예측하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split-
tensorflow.keras.models import Sequential : Sequential 모델은 Keras에서 신경망 모델을 간단하게 구축할 때 사용되는 클래스로, 모델의 각 레이어를 순차적으로 쌓아나가는 방식으로 모델을 정의합니다. 이 모델 클래스를 사용하면 순차적인 레이어를 간편하게 추가하고 컴파일하여 딥러닝 모델을 생성할 수 있습니다.
-
from tensorflow.keras.layers import Dense : TensorFlow와 Keras를 사용하여 딥러닝 모델을 구축할 때, 모델 내에 사용할 레이어 중 하나인 Dense 레이어를 가져오는 코드로, Dense 레이어는 fully connected 레이어로, 각 뉴런이 이전 레이어의 모든 뉴런과 연결된 레이어입니다. 이 레이어는 신경망의 구조에서 일반적으로 사용되며, 입력과 출력 사이의 모든 연결을 가집니다.
-
import numpy as np : 파이썬에서 수치 계산을 수행하는데 사용되는 매우 유용한 라이브러리
-
import pandas as pd : 데이터 조작 및 분석을 위한 강력한 도구와 데이터 구조를 제공하는 라이브러리
-
import matplotlib.pyplot as plt : 데이터 시각화를 위한 라이브러리로, 그래프 및 플롯을 그리는 데 사용
-
import seaborn as sns : Seaborn은 데이터 시각화를 위한 고수준 인터페이스를 제공하는 라이브러리로, Matplotlib과 함께 사용하여 데이터를 데이터 시각화 작업을 단순화하고 훨씬 더 매력적인 그래프를 생성할 수 있습니다.
-
from sklearn.model_selection import train_test_split : 데이터를 훈련 세트(Training Set)와 테스트 세트(Test Set)로 나누는 데 사용. 데이터 과학 및 머신러닝 작업에서 모델을 훈련하고 평가하는 데 매우 중요한 역할을 합니다.
5. 데이터셋 로드
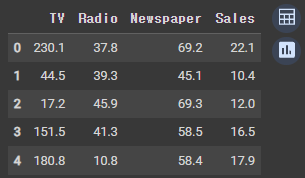
df = pd.read_csv('advertising.csv')
df.head(5)=> Pandas를 사용하여 'advertising.csv'라는 CSV 파일을 읽고, 데이터프레임으로 저장한 후, 데이터프레임의 처음 5개 행을 표시합니다.
6. 데이터셋 크기 살펴보기
print(df.shape)
# (200, 4)=> Pandas 데이터프레임인 'df'의 형태(shape)를 출력. 데이터프레임의 형태는 행과 열의 개수를 나타냅니다.
7. 데이터셋 살펴보기
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4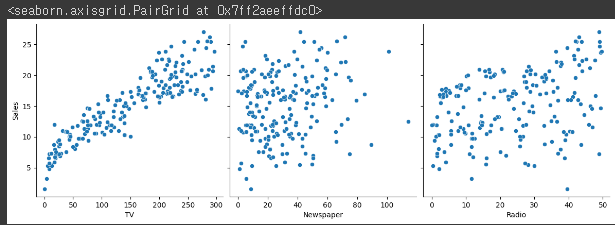
8. 데이터셋 가공
x_data = np.array(df[['TV']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
print(x_data.shape)
print(y_data.shape)
#
(200, 1)
(200,)=> Pandas 데이터프레임 'df'에서 열을 선택하고, 데이터 타입을 'np.float32'로 지정하여 데이터의 형태를 명시적으로 지정한 후 이를 Numpy 배열로 변환하여 변수에 저장합니다. 이렇게 하면 변수에는 데이터셋의 열 값을 포함하는 1차원 Numpy 배열이 됩니다.
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
#
(200, 1)
(200, 1)=> 변수에 저장된 배열의 형태를 변환합니다. 여기서 -1은 한 축(열)의 크기를 자동으로 계산하라는 의미이고, 1은 새로운 형태에서 각 행에 하나의 열이 있도록 지정합니다. 따라서 배열은 2D 배열이 되며 각 행에 하나의 열 값이 있는 형태로 변환됩니다.
9. 데이터셋 분할 (학습 데이터, 검증 데이터 및 테스트 데이터)
- 학습 데이터 60%, 검증 데이터 20%, 테스트 데이터 20%
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
x_train, x_test, y_train, y_test = train_test_split(x_train, y_train, test_size=0.25, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
#
(120, 1) (40, 1)
(120, 1) (40, 1)=> 전체 데이터셋이 100개의 샘플을 가지고 있다고 가정하면,
첫 번째 호출:
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)에서 학습 데이터(x_train, y_train)에 80개, 검증 데이터(x_val, y_val)에 20개로 할당됩니다.
두 번째 호출:
x_train, x_test, y_train, y_test = train_test_split(x_train, y_train, test_size=0.25, random_state=2021)에서는 앞서 나눠진 80개의 데이터 중에서 다시
x_train, x_test, y_train, y_test로 나눕니다. 그래서 80개의 0.75 즉, 3/4인 60개가 다시 학습 데이터로 사용되고 나머지 20개의 데이터가 테스트 데이터로 할당됩니다.
10. 신경망 모델 학습시키기
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(learning_rate=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)-> Sequential 모델을 생성하고, 이 모델에 하나의 Dense 레이어를 추가
-> 모델을 컴파일(손실 함수(loss)로 평균 제곱 오차(mean squared error)를 사용하고, Adam 최적화기(optimizer)를 사용하고, 학습률(learning rate)은 0.1로 설정 / Adam 최적화기는 모델을 훈련하는 데 사용)
-> model.fit(...)에서 x_train과 y_train 데이터를 사용하여 모델을 훈련 ( validation_data 매개변수를 사용하여 검증 데이터인 x_val과 y_val을 지정)
-> 각 에포크(epoch)가 끝날 때마다 모델의 성능이 검증 데이터에 대해 평가되고, 훈련 과정 중에 손실 및 정확도를 모니터링할 수 있습니다.
Epoch 1/100
5/5 [==============================] - 1s 116ms/step - loss: 78747.8581 - val_loss: 52665.7383
Epoch 2/100
5/5 [==============================] - 0s 12ms/step - loss: 43395.0104 - val_loss: 21185.8652
....
5/5 [==============================] - 0s 13ms/step - loss: 8.7217 - val_loss: 10.4845
Epoch 100/100
5/5 [==============================] - 0s 15ms/step - loss: 8.6977 - val_loss: 10.3789
<tensorflow.python.keras.callbacks.History at 0x7f9e89ece128>11. 검증 데이터로 예측하기
y_pred = model.predict(x_val)
plt.scatter(x_val, y_val)
plt.scatter(x_val, y_pred, color='r')
plt.show()-
y_pred = model.predict(x_val) : 모델을 사용하여 검증 데이터 x_val에 대한 예측값을 계산하여 y_pred 변수에 저장
-
plt.scatter(x_val, y_val) : 검증 데이터 x_val와 실제 레이블 y_val을 산점도로 나타냅니다. 이렇게 하면 실제 데이터 포인트가 그래프에 표시됩니다.
-
plt.show() : 그래프를 화면에 출력합니다.
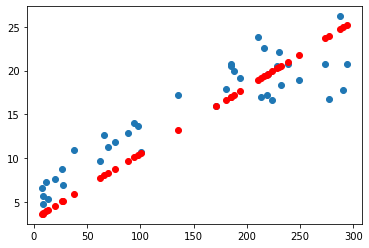
12. TV, Newspaper, Radio 광고 금액으로 Sales 예측하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('advertising.csv')
x_data = np.array(df[['TV', 'Newspaper', 'Radio']], dtype=np.float32)
y_data = np.array(df['Sales'], dtype=np.float32)
x_data = x_data.reshape((-1, 3))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape)
print(y_train.shape, y_val.shape)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=Adam(learning_rate=0.1))
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)- TV 데이터 예측 그래프
plt.scatter(x_val[:, 0], y_val)
plt.scatter(x_val[:, 0], y_pred, color='r')
plt.show()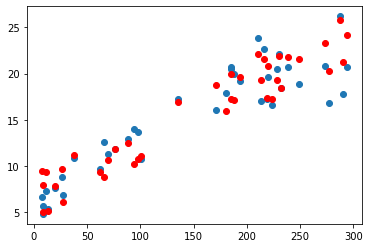
- Newspaper 데이터 예측 그래프
plt.scatter(x_val[:, 1], y_val)
plt.scatter(x_val[:, 1], y_pred, color='r')
plt.show()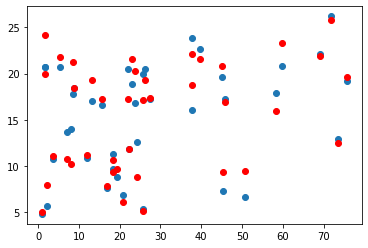
- Radio 데이터 예측 그래프
plt.scatter(x_val[:, 2], y_val)
plt.scatter(x_val[:, 2], y_pred, color='r')
plt.show()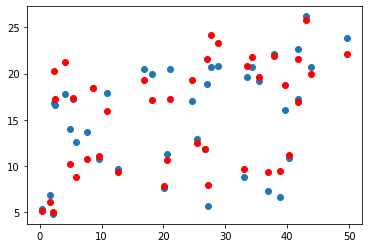
=> 데이터셋이 다차원 데이터인 경우, 각 열은 해당 특성을 나타내며, 특성 간의 관계와 모델의 예측을 시각적으로 분석할 수 있습니다.
주어진 데이터셋을 사용하여 간단한 신경망 모델을 생성하고 훈련하는 과정을 진행했습니다. 데이터셋은 'x_data'와 'y_data'로 구성되며, 이를 학습, 검증 및 테스트 데이터로 나누었습니다. 모델은 평균 제곱 오차 손실 함수를 사용하고 Adam 최적화기를 활용하여 훈련되었습니다. 이후, 검증 데이터를 활용하여 모델의 예측값을 시각화하고, 특성과 모델 예측값의 관계를 분석해봤습니다.
🥚🐣🐤🐥🐓🐔
