컴퓨팅 사고 문제
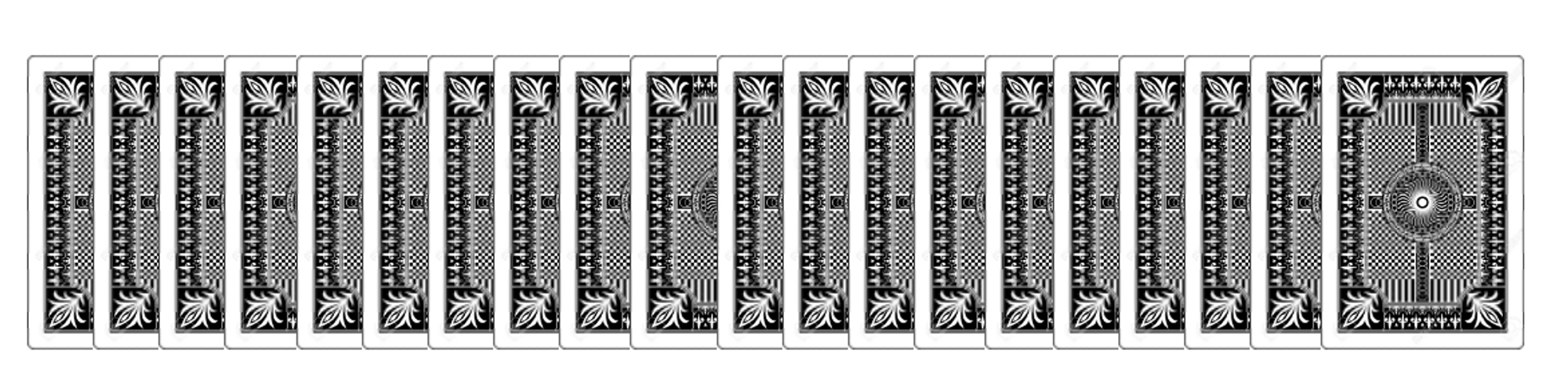
- 무작위로 선택된 20장의 카드를 뒷면이 보이게 놓는다[배열]
- 뒷면이 보이는 카드 중 하나를 뒤집고 그 카드 오른쪽에 있는 카드도 뒤집는다.
a. 뒷면인 카드만 뒤집을 수 있다.
b. 단, 오른쪽 맨 끝의 카드를 고를 때에는 그 카드만 뒤집는다. - 뒷면이 보이는 카드가 남아 있는 동안 2번을 계속 반복 한다.
- 결국엔 모든 카드가 앞면이 된다.
- 그 이유를 증명하라.
처음 이 문제를 들었을 때,
처음 앞면으로 뒤집는 카드가 어느 카드던간에 언젠가 맨 왼쪽 카드를 한번만 뒤집고 건들이지 않게 된다면 나머지 카드로 무슨 짓을 하던 결국 다 앞면이 되겠다고 생각했다.
영화의 답은,
- 뒷면의 카드를 1, 앞면으로 보이는 카드를 0 정의
- 10011010 처럼 2진수 배열(리스트) 형태로 정의할 수 있음
- 10011010
- 11이 붙어 있는 경우 00
- 10이 붙어 있는 경우 01
- 10000001 처럼 감소가 됨
- 3번을 계속 반복하면 2진수 배열은 모두 0으로 됨
문제의 의도와 나의 처음 든 생각이 맞는지는 모르지만 문제를 빠르게 분석하고 답을 도출할 수 있는 사고력을 컴퓨팅 사고력이라고 하니 단련하면 늘겠구나 싶었다.
자료구조와 알고리즘의 관계
자료구조는 데이터를 상황에 맞게 효율적으로 다루기 위한 데이터 저장/보관 방법이다.
자료구조가 특정 상황에 맞는 연장이라면 알고리즘은 능률 좋은 목수라고 보면 된다.
문제 1
- 3개의 값에 대한 평균 구하기 (평균: 자료 전체의 합을 자료의 개수로 나눈 값)
- 88
- 93
- 95
# 답 1) 데이터를 변수에 저장 (변수)
a = 88
b = 93
c = 95
avg = (a + b + c) / 3
print(avg)// 처음 이 문제를 봤을 때, 배웠던 것을 활용해보려고 머리를 굴려봤지만 뚜렷하게 떠오르는 생각이 없었다. 너무 의욕만 앞선게 아닌가 싶다. 단순하게 생각해봤다면 이 답은 생각할 수 있을 것이다.
# 답 2) 데이터들을 리스트에 저장 (배열)
arr = [88, 93, 95]
avg = 0
for i in arr:
avg += i
avg = avg / len(arr) (= avg /= len(arr))
print(avg)// 이 문제는 '리스트가 있으면 반복해야겠다'라는 생각은 들었지만 반복문 안의 식을 어떻게 구성해야하는지도 생각이 안 났고, 반복문을 돌리고 난 값에 새로운 값을 할당해주는 방법도 생각하지 못했다. 꼭 이 방법이 아니어도, 변수가 여러 개 등장하는 방법도 있지만 최대한 간단하고 효율적인 방법을 생각하는 사고가 중요한 것 같다.
문제 2
- 4개의 값에 대한 평균 구하기/N개
- 88
- 93
- 95
- 100
// 문제 1번을 보고 혼자 풀어봤다.
# 답 1) 변수 활용
a = 88
b = 93
c = 95
d = 100
avg = (a + b + c + d) / 4
print(avg)# 답 2) 배열 활용
arr = [88, 93, 95, 100]
avg = 0
for i in arr:
avg += i
avg /= len(arr)
print(avg)// 자료구조가 어떻게 되어있는지에 따라서 답을 도출하기 위한 식인 알고리즘이 다르다는 것을 쉽게 느낄 수 있었던 것 같다. 평균을 구하기 위해 나누기를 하는 것에서 나누기의 기능이 어떤 식으로 굴러가는지 이해해야하고 코딩에서도 각 식의 기능을 정확히 알아야 자료구조를 봤을 때 어떤 식을 써야하는지 감이 올 것 같다.
좋은 알고리즘이란 문제를 해결하는 가장 합리적인 방법
# 배열 활용 version 1)
arr = [88, 93, 95]
sum_ = 0
sum_ += arr[0]
sum_ += arr[1]
sum_ += arr[2]
average = sum_ / len(arr)
print(average)# 배열 활용 version 2
arr = [88, 93, 95]
average = 0
for i in arr:
average += i
average /= len(arr)
print(average)- 적합한 자료구조를 쓰더라도 알고리즘에 따라 코드의 질이 달라질 수 있다.
공간 복잡도 : 프로그램을 실행 및 완료하는데 필요한 저장 공간의 양
시간 복잡도 : 특정 알고리즘이 어떤 문제를 해결하는데 걸리는 시간
- 공간 복잡도는 컴퓨터 저장공간의 기술 발달로 시간복잡도에 비해 상대적으로 중요하지 않음.
- 시간 복잡도는 컴퓨터 사양이나 컴퓨터 기술 발전에 따라 시간이 상이하기 때문에 보통 연산량이 많은 반복문으로 시간 복잡도를 예측해보곤 한다.
- 만약 for문을 사용하여 배열 [1,2,3,4,5]를 순회한다고 했을 때,
- 빅오메가(Big-Ω): 반복문이 돌면서 (1)에서 딱 답이 도출되는 최선의 경우
- 빅세타(Big-Θ) : 평균(중간)(3)
- 빅-오(Big-O): 배열의 길이만큼 순회를 해야 하는 최악의 경우(5)
- 시간 복잡도를 표현하는 방법은 최악의 경우로 나타낸다.
- 예를 들어, '어떤 입력이 주어지더라도 알고리즘의 수행시간이 얼마 이상은 넘지 않는다'라는 상한(Upper Bound)의 느낌이다. 그래서 시간 복잡도는 특별한 알고리즘 제외 주로 빅-오(Big-O) 표기법을 사용한다.
- 빅세타(Big-Θ)는 평균적인 수행 시간, 빅오메가(Big-Ω)는 가장 빠른 수행 시간을 분석하며, 최적의 알고리즘을 찾는데 활용한다.
빅-O 표기법 종류
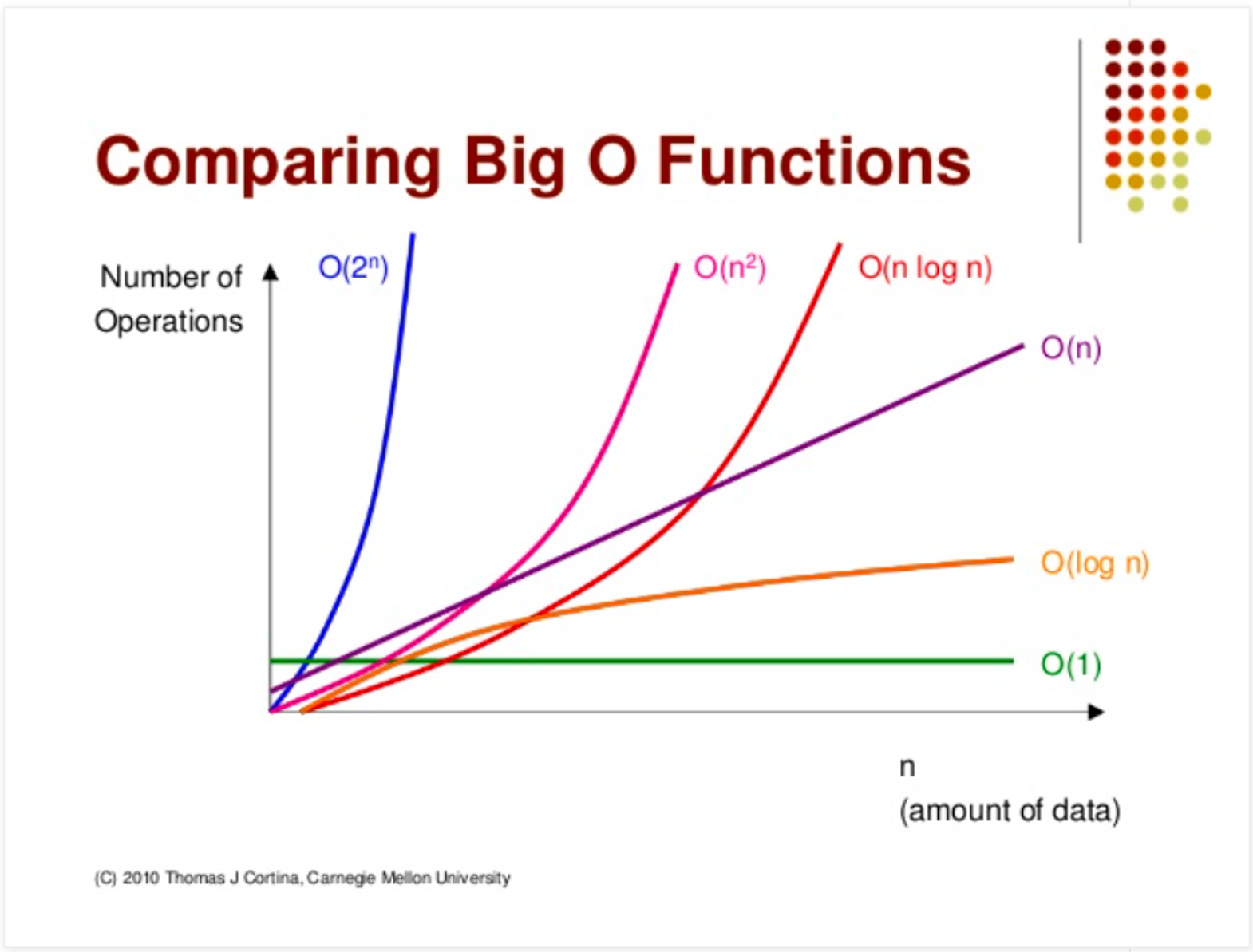
1. O(1)(상수 복잡도)
# 데이터양과 상관없이 항상 일정한 연산량을 갖는 알고리즘
# 그래프 : 데이터의 양과 상관없이 작동의 수가 일정하다.
def fourth_element(arr):
print(f"네 번째 요소는 {arr[3]}임.")
a = [1, 2, 3, 4, 5]
fourth_element(a) # 네 번째 요소는 4임.
b = [23, 4, 6, 34, 86, 85, 24, 2346, 85, 12124]
fourth_element(b) # 네 번째 요소는 34임.
c = [1,23,5,235,23,5,34,6,34,6,43,6,34,6,34,634,6,43,6,3,634]2. O(n)(선형 복잡도)
# 데이터양(n)과 비례해 연산량도 증가하는 알고리즘
# 그래프 : 데이터양(n)이 증가하면 연산수(n)도 비례해서 증가한다.
for i in range(n):
sum_ += i3. O(n²)(2차 복잡도)
# 데이터양이 증가할수록 데이터양의 제곱만큼 연산량 증가하는 알고리즘
# 보통 이중 for 문에서 수행 시간 분석하는 방법이다.
for i in range(n):
sum_ = 0
for j in range(n):
# 2n + n
sum_ += i 자료구조
1. 배열 : 같은 타입의 변수들로 이루어진 집합
-
메모리의 연속공간에 값이 채워져 있는 형태
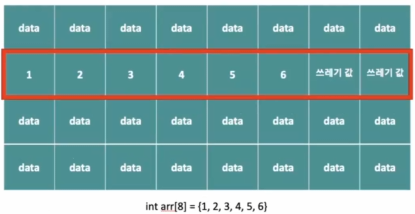
- int Array[8] = {1,2,3,4,5,6} : 숫자를 8개 저장한 배열을 선언

장점
- 검색 성능: 인덱스를 사용하여 원소에 바로 접근이 가능

- arr[2] (연산 1번) → 100 + 4(int byte*2) = 108번지 주소로 이동
- 배열의 시간복잡도 (상수시간 알고리즘) : O(1)
def fourth_element(arr):
print(f"네 번째 요소는 {arr[3]}임.")
a = [1, 2, 3, 4, 5]
fourth_element(a) # 네 번째 요소는 4임.
b = [23, 4, 6, 34, 86, 85, 24, 2346, 85, 12124]
fourth_element(b) # 네 번째 요소는 34임.단점
-
초기 선언된 사이즈만큼 메모리의 연속 공간이 필요하므로 작은 빈 공간은 버려지는 경우가 생겨 메모리 활용에 비효율적
-
연속된 빈 공간 중에 임의의 데이터값이 들어가서 자리를 차지한다면 이곳에 8개 요소를 가지는 배열은 저장을 못한다.
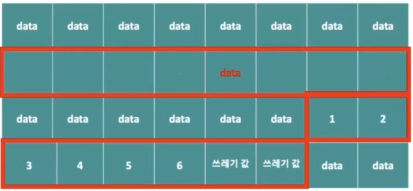
- 연속된 빈 공간을 찾아서 넣어줘야하는데 빈 공간들은 낭비가 된다.
-
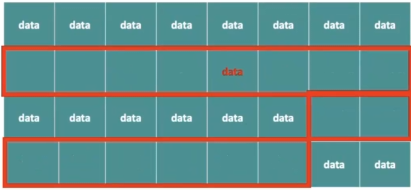
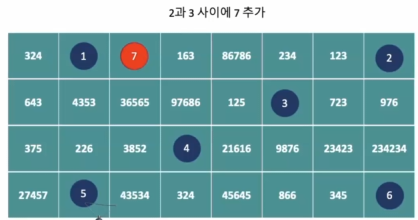
값의 삽입과 삭제에서 비효율적, 데이터 중간 지점에서 자료의 삽입, 삭제가 일어날 경우 다음 항목의 모든 값을 이동시켜야 한다.
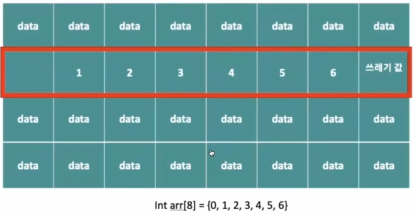
- 예를 들어,

- 4번부터 9번까지의 달걀을 하나씩 이동시킨 후 4번 계란을 넣어야 한다.
2. 연결 리스트(Linked list) : 배열의 단점을 보완하기 위하여 만들어짐.
-
선언할때 크기를 지정하지 않으며 주소로 계속 연결하여 연속된 공간이 필요하지 않아 빈 공간을 활용할 수 있음
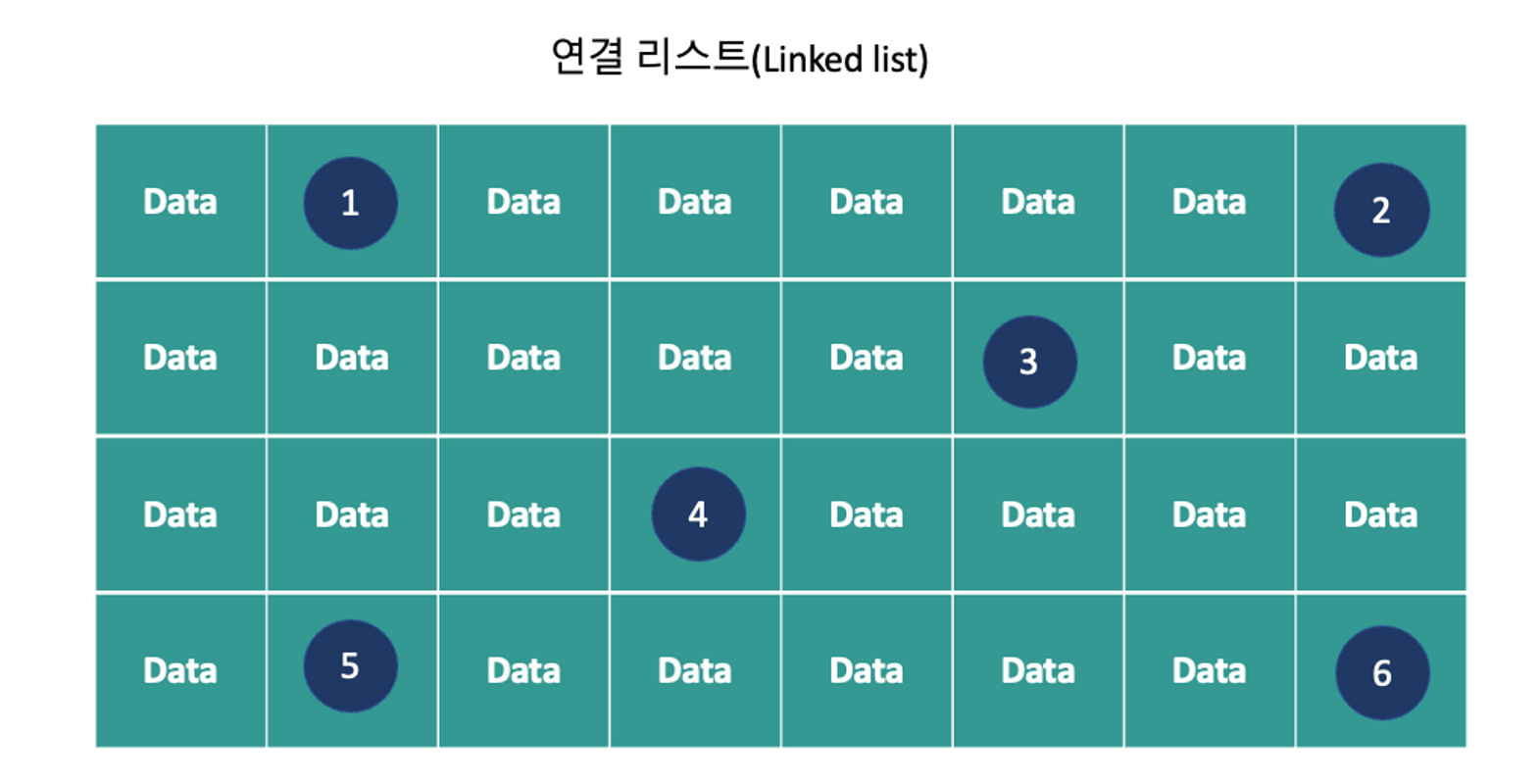
- 각 요소들 분산해서 메모리에 저장을하고 각 요소에 다음 값의 주소를 알면 해결
장점
- 각 요소가 다음 요소의 주소를 알고 있어 값을 찾거나 추가/삭제하는 속도가 배열에 비해 빠름
- 요소들 사이에 값을 추가해주고 싶을 때, 빈 메모리 공간 중 아무 곳에 넣어줄 수 있다.
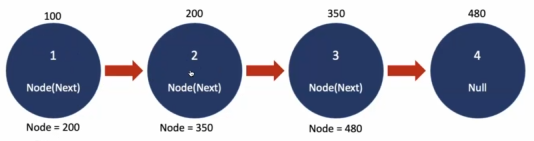
단점
- 특정 원소로 바로 접근이 불가 : 첫 번째 주소(Head)부터 차례대로 순차 접근해야 한다.
- 배열의 장점이 연결리스트의 단점이 된다.
- 배열
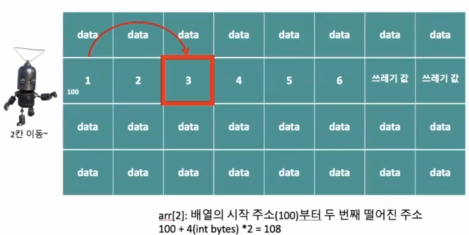
- 원하는 주소로 가고 싶을 때, 주소를 계산해서 바로 접근이 가능함
- 연결 리스트
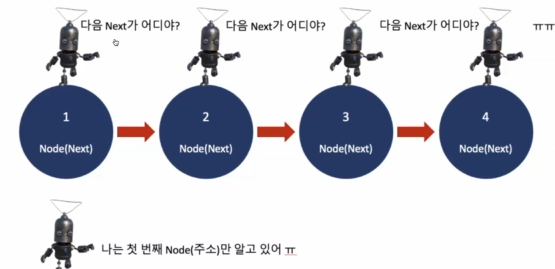
- 각 요소는 다음 요소의 주소밖에 알지 못한다. 그래서 원하는 요소를 찾기 위해서는 찾을 때까지 순차적으로 반복할 수 밖에 없다.
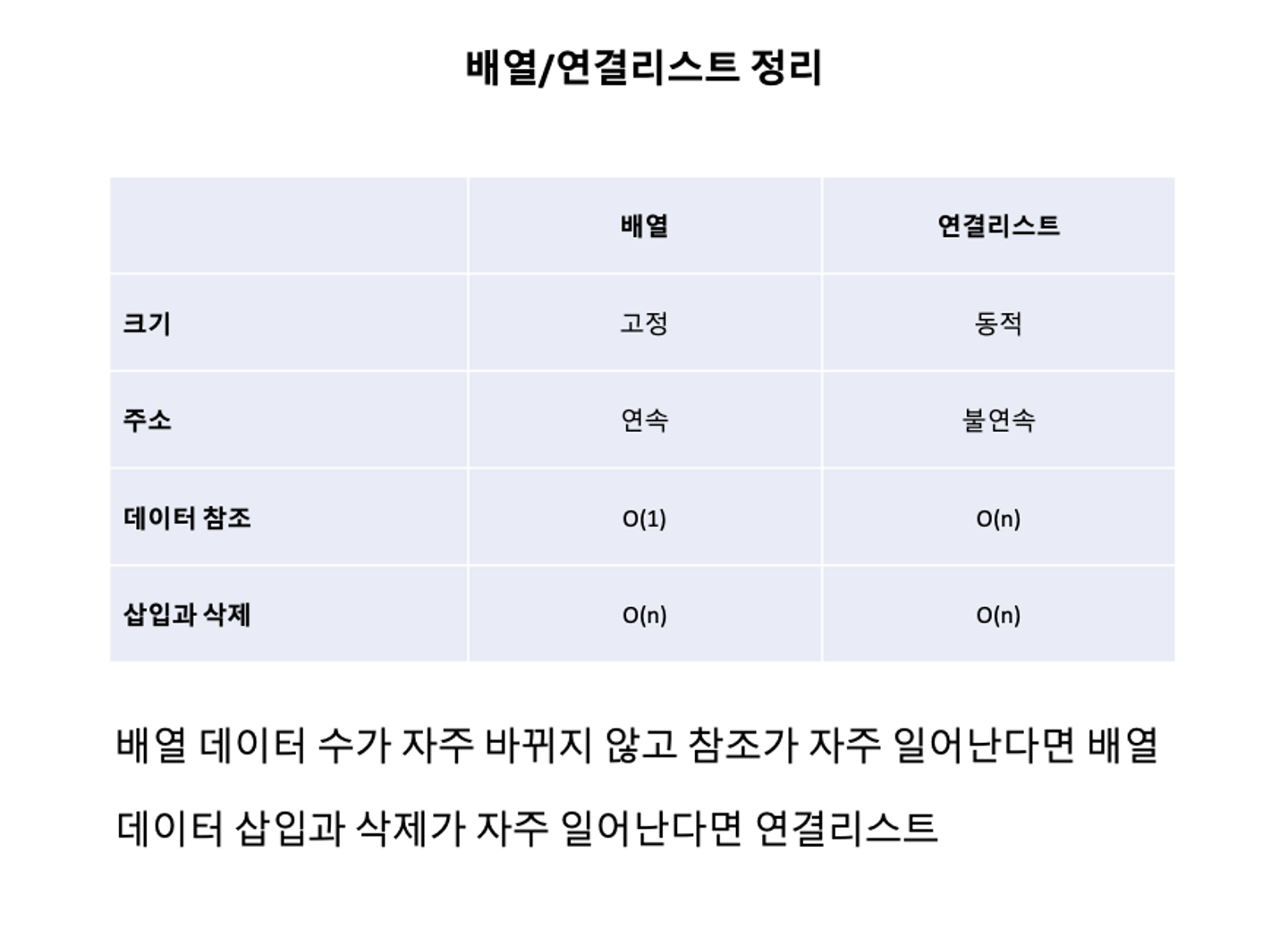
배열/연결리스트 정리
배열/연결리스트 알고리즘 문제
문제 1
- 합격자 수 구하기
- 합격 컷트 라인은 60점
- 점수 : [80, 40, 90, 55, 94, 30, 60, 44]
- answer = 합격자 수(4)
- 스캐치
- 점수 리스트(score)와 합격 컷트라인(cl)를 변수로 받는 함수 선언
- 합격자 수(answer)에 값 0을 할당
- for in 반복문으로 score리스트를 순회하면서 score리스트 안 요소가 합격 컷트라인(cl)보다 같거나 크면 합격자 수(answer)를 += 1
- 합격자 수(answer)를 반환(return)
- 기본 코드
def count_passer(score, c):
answer = 0
return answer
# [80, 40, 90, 55, 94, 30, 60, 44]
print(count_passer([80, 40, 90, 55, 94, 30, 60, 44], 60))- 정답
def count_passer(score, cl):
answer = 0
for a in score:
if a >= cl:
answer += 1
return answer
print(count_passer([80, 40, 90, 55, 94, 30, 60, 44], 60))
# 4문제 2
-
최소값 구하기(index)
- nums의 길이 3 < = n < = 100,000
- 시간복잡도 (상수시간 알고리즘) : O(n)
- 배열의 nums 원소는 정수
- 배열의 원소는 중복된 값이 없다.
- [23, 20, 73, 98, 11, 4, 288]

- nums의 길이 3 < = n < = 100,000
-
스캐치
- 최소값은 두 개의 숫자 이상이 있어야 구할 수 있다.
- 숫자 배열의 nums 원소는 정수니까 0이 포함이 안되는데 왜 길이가 3이상이지..? 2이상이어야하는거 아닌가..
-
기본 코드
def minimum_value(nums):
answer = 0
return answer
# [23, 20, 73, 98, 11, 4, 288]
print(minimum_value([23, 20, 73, 98, 11, 4, 288]))- 정답
