Python Package
- 가상환경(venv : 패키지를 담아두는 공구함)
같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해, 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는 격리된 실행 환경이다. 요구사항이 다른 여러 프로젝트를 한 컴퓨터에서 진행해야하는 경우 각 프로젝트별 가상환경을 만들면 충돌없이 관리할 수 있다.
파이썬 패키지 설치
1) 가상환경 생성
Visual Studio code - 터미널(Ctrl+백틱)
- 윈도우는
python -m venv venv - 맥은
python3 -m venv venv
-> 프로젝트 폴더에 venv 폴더가 생성된다.
2) 가상환경 활성화
- 윈도우는
./venv/Scripts/activate - 맥은
source venv/bin/activate
-> 터미널에서 실행해보면 (venv)라고 뜬다.
3) 패키지(외부 라이브러리) 설치하기
가상환경이 활성화된 상태에서 터미널에 pip install requests
-> requests라는 라이브러리가 가상환경에 설치된다.
Requests 라이브러리
가상환경에서 pip install로 설치한 라이브러리(ex. requests)는 Fetch(서버에서 데이터를 가져옴)와 같은 역할을 한다.
EXAMPLE) 서울시 대기 OpenAPI에서, 중구의 미세먼지 값을 가져와보자.
1) HTML 구조를 파악한다.
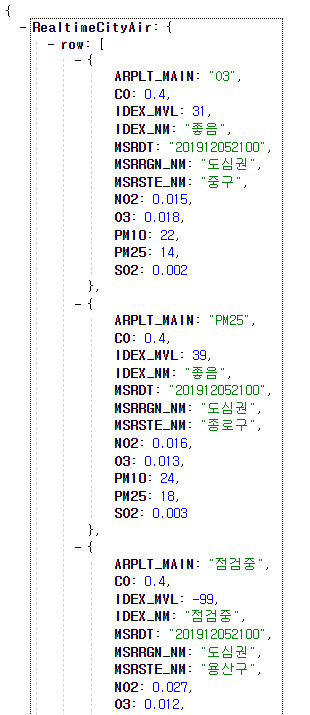
2) 설치된 requests 라이브러리를 import해서 서울시 대기 OpenAPI 자료를 json형식으로 가져온다(get).
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
-> requests라는 라이브러리를 만든 사람이 정한 규칙(양식)이다.3) 터미널에 가져온(get) json형식의 API 결과를 print해보자.
print(rjson)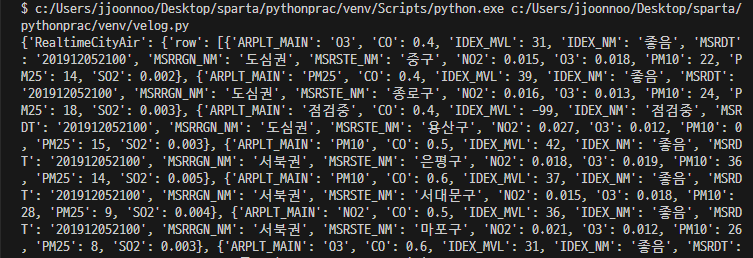
4) [RealtimeCitiAir][row]의 중구(Index 0번째) IDEX_MVL값을 가져온다.
print(rjson['RealtimeCityAir']['row'][0]['IDEX_MVL'])
# 31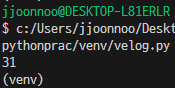
5) 모든 구의 IDEX_MVL 값 프린트하기 (반복문)
rows = rjson['RealtimeCityAir']['row']
# 반복문을 넣기 위해 저 데이터를 자료로 한 변수를 지정
for a in rows:
gu_name = a['MSRSTE_NM']
gu_mise = a['IDEX_MVL']
print(gu_name, gu_mise)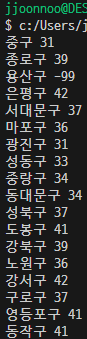
6) IDEX_MVL 값이 40 미만인 구의 이름과 미세먼지 수치 프린트하기
rows = rjson['RealtimeCityAir']['row']
for a in rows:
if a['IDEX_MVL'] < 40:
print (a['MSRSTE_NM'], a['IDEX_MVL'])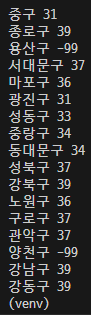
웹스크래핑(크롤링 : HTML 중에 어떤 부분을 골라 가져오는 것)
웹 스크래핑(web scraping)은 웹 페이지에서 원하는 부분의 데이터를 수집해오는 것이다.
스크래핑(scraping - 데이터 스크래핑(data scraping)) : 크롤링과 유사 개념으로 소프트웨어를 통해 대상 웹사이트와 같은 데이터 소스에서 데이터 자체를 추출하여 특정 형태로 저장하는 것이다.
크롤링 : 크롤러(크롤링을 위해 개발된 소프트웨어)는 주어진 인터넷 주소(URL)에 접근하여 관련된 URL을 찾아내고, 찾아진 URL들 속에서 또 다른 하이퍼링크(hyperlink)들을 찾아 분류하고 저장하는 작업을 반복함으로써 여러 웹페이지를 돌아다니며 어떤 데이터가 어디에 있는지 색인(index)을 만들어 데이터베이스(DB)에 저장하는 역할을 한다.
EXAMPLE) 웹스크래핑 해보기 (영화 제목)
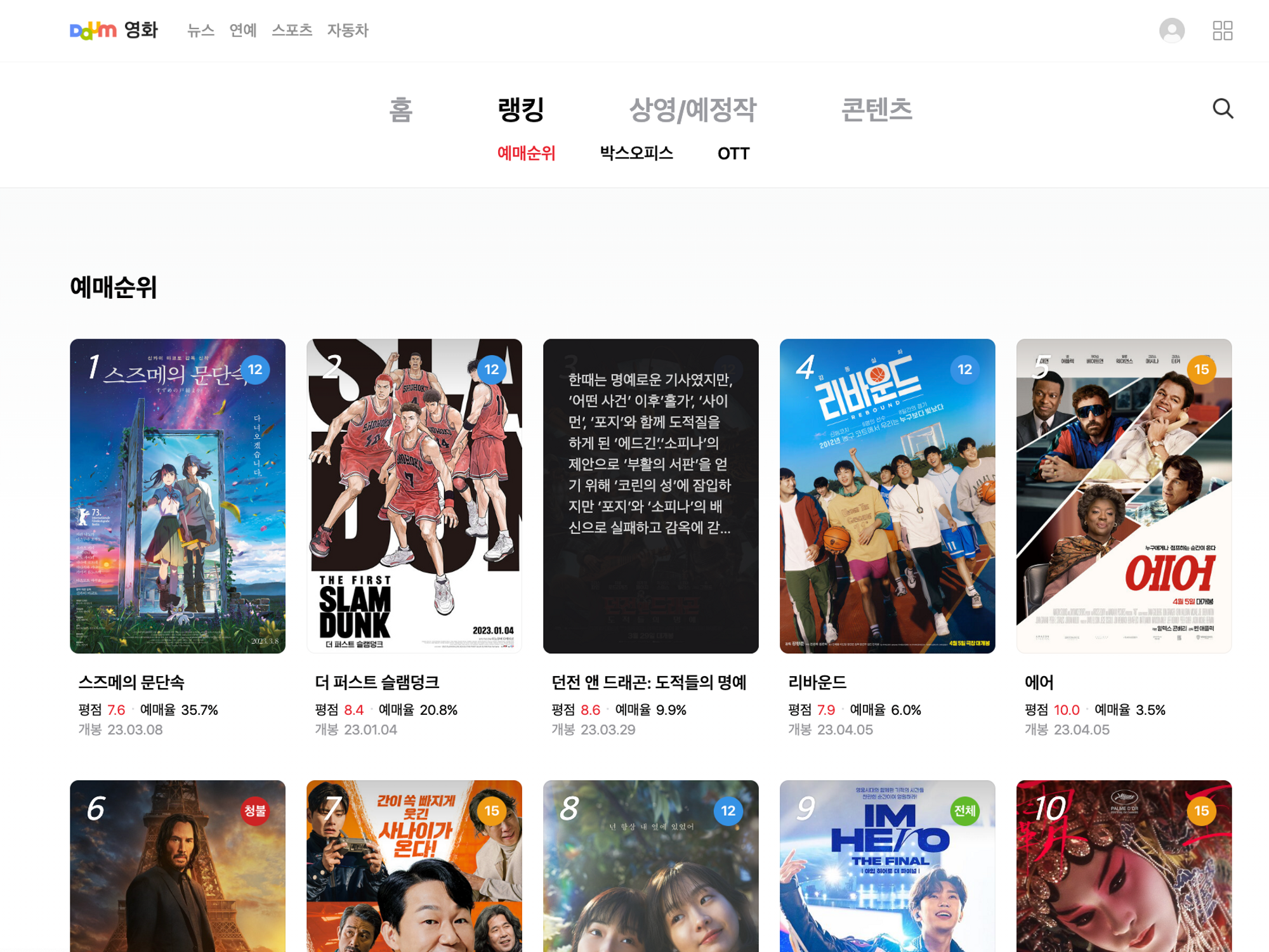
https://movie.daum.net/ranking/reservation
1) 개발자 도구에서 HTML 구조 파악
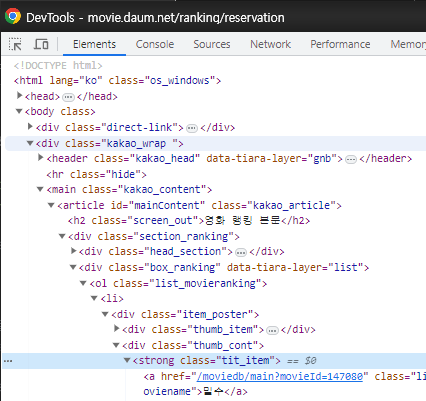
2) 패키지(라이브러리) 추가 설치 (beautifulsoup4 - bs4)
터미널에 가상환경이 활성화 되어 있는지 확인한 후 pip install bs4를 입력
-> bs4는 원하는 특정 부분을 빨리 골라낼 수 있게 도와주는 라이브러리
3) 크롤링 기본 세팅 코드 입력하고 프린트로 결과 확인
import requests
from bs4 import BeautifulSoup
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만든다.
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers) # URL을 읽어서 HTML를 받아옴
soup = BeautifulSoup(data.text, 'html.parser') # 파싱 용이해진 html이 text 형태로 담김
print(soup)
4) select / select_one의 사용
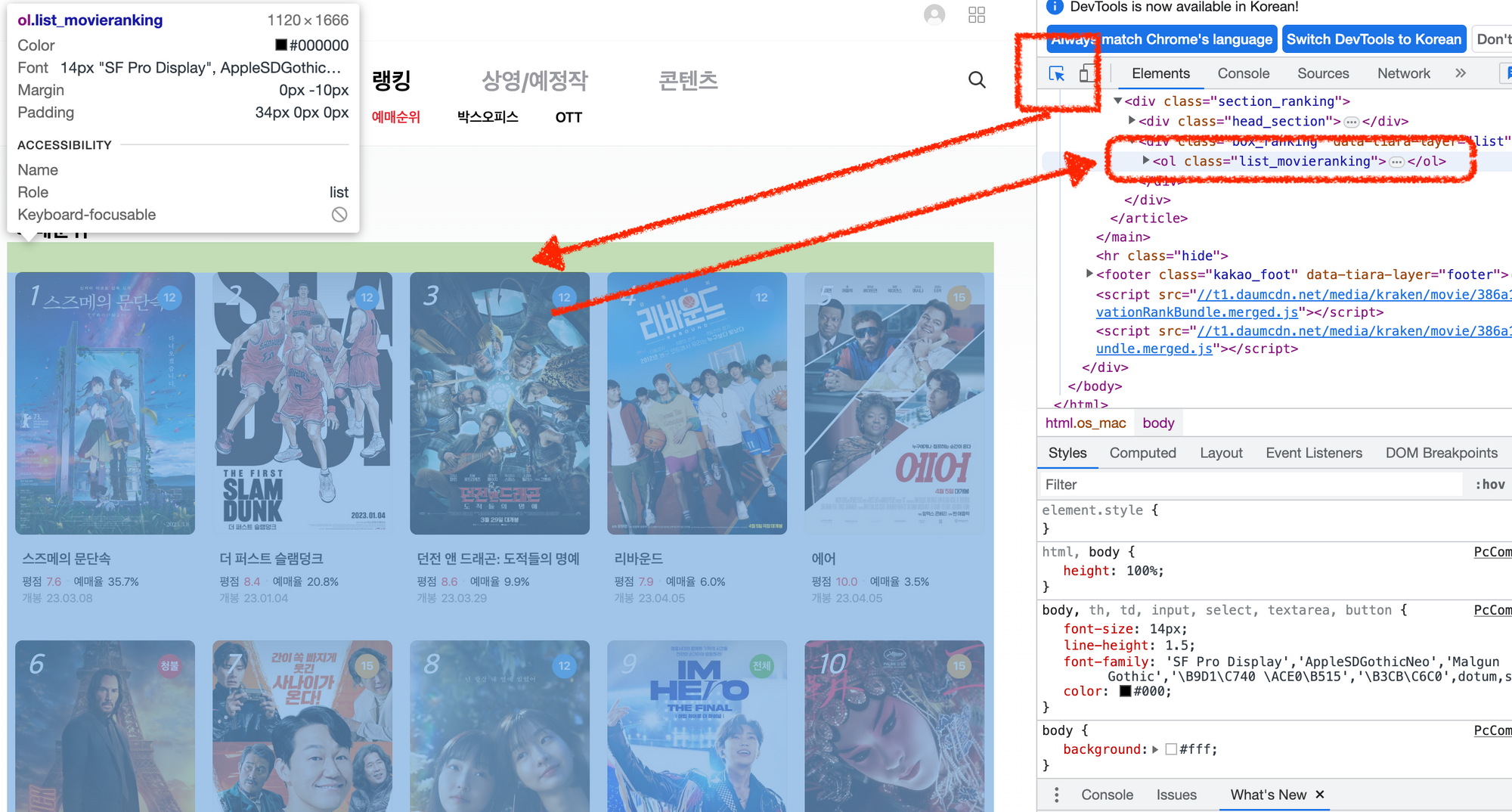
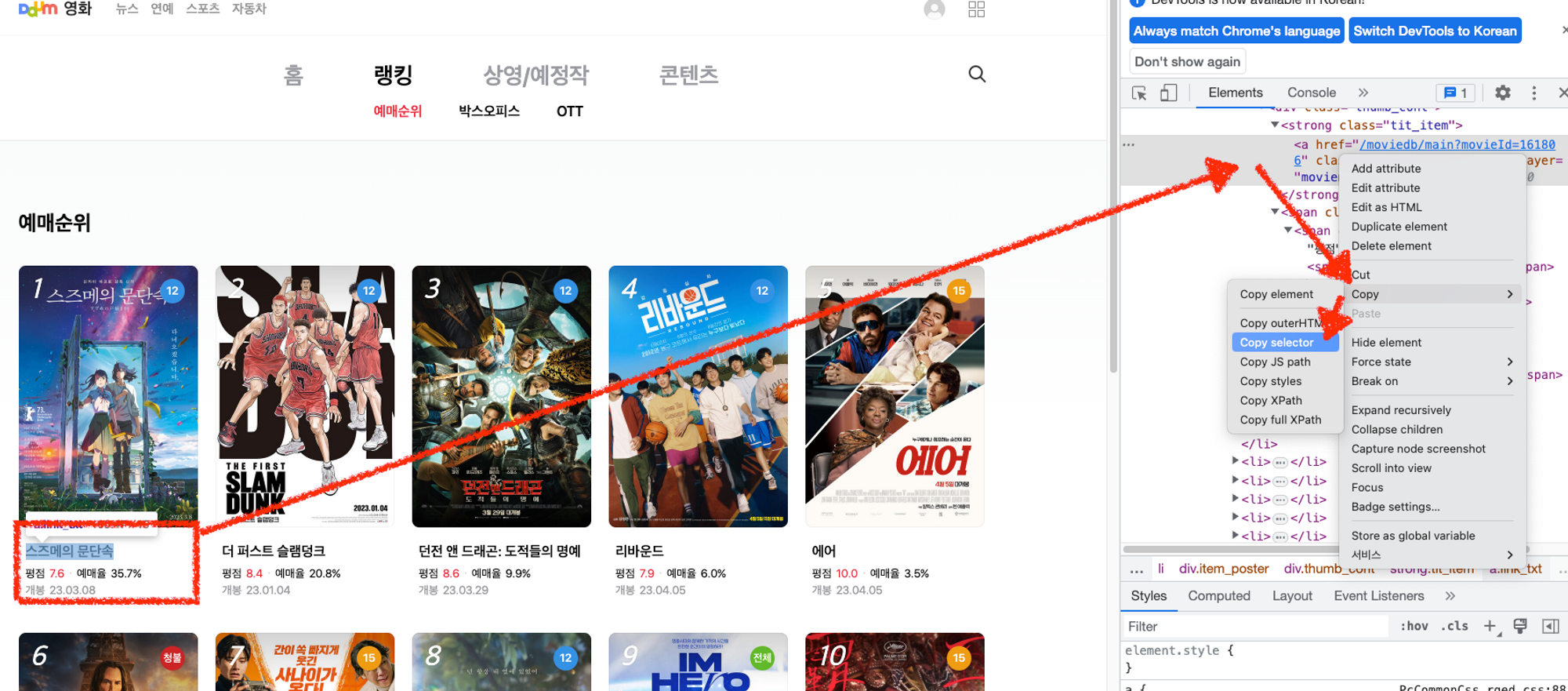
4-1) 개발자도구의 데이터에서 영화 제목 부분을 Copy → Copy selector로 선택자를 복사
'#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a'4-2) title이라는 변수에 select_one()을 이용해서 값을 담고 원하는 html(뼈대) 프린트해보기
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title)
# <a class="link_txt" data-tiara-layer="moviename" href="/moviedb/main?movieId=147080">밀수</a>
4-3) 가져온 데이터는 html의 뼈대이기 때문에 .text()를 text부분만 출력한다. (태그 안의 텍스트를 찍고 싶을 땐 → 태그.text)
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title.text)
# 밀수
4-4) 가져온 html의 특정 부분을 가져와서 프린트해보기(태그 안의 속성을 찍고 싶을 땐 → 태그['속성'])

title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title['data-tiara-layer'])
-> 가져오는 방법을 보면 이 라이브러리를 만든 사람은 딕셔너리를 이용했다는 것을 알 수 있다.
# moviename
4-5) 가져온 데이터는 html의 뼈대를 보니 영화 제목에 해당하는 모든 html 태그에 class값이 지정되어 있으니 class 값으로 html을 출력해보자.
title = soup.select('.link_txt')
print(title)
-> 영화 제목이 있는 모든 html이 리스트 형태로 출력된다.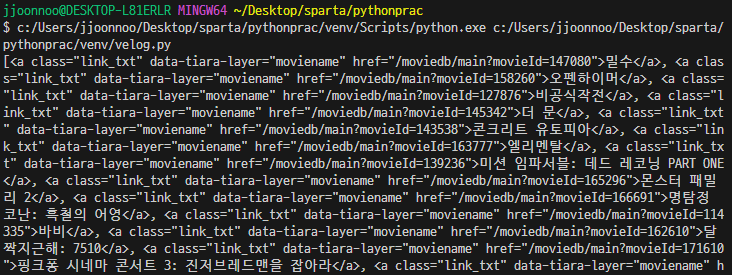
4-6) class값이 '.link_txt'로 지정되어 있는 영화 제목 html들에서 text 값만 출력해보자.
title = soup.select('.link_txt')
print(title.text)
# AttributeError: ResultSet object has no attribute 'text'. You're probably treating a list of elements like a single element. Did you call find_all() when you meant to call find()?
-> select로 가져온 리스트형의 전체 자료는 .text함수를 쓸 수 없다. 처음에는 리스트 안의 영화 제목에 해당하는 텍스트가 따옴표로 감싸져 있지 않아서 문자열로 정의되지 않는건가? 싶었지만 이는 .text함수가 리스트 안의 요소 하나하나를 보는 것이 아니라 리스트 전체로 보기 때문이다.
print(title[0].text) # 밀수
-> 리스트의 몇 번째 자료를 추출한 경우는 .text함수가 이 자료를 <a></a>태그로 인식하여 사용 가능하다.5) 모든 영화 제목들을 가져와서 프린트해보자.(-> 반복문을 통해서 각 태그를 .text함수를 통해 텍스트만 출력해보자.)
- 특정 영화 하나(select_one())
'#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a'title = soup.select_one("#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a")
print(title)
# <a class="link_txt" data-tiara-layer="moviename" href="/moviedb/main?movieId=147080">밀수</a>- 모든 영화(li의 하위 부분들을 다 지워준다. / select())
'#mainContent > div > div.box_ranking > ol > li'title_lis = soup.select('#mainContent > div > div.box_ranking > ol > li')
print(title_lis)
# -> li 태그 안의 모든 html이 출력- 반복문
for li in title_lis:
title = li.select_one('.link_txt') # link_txt라는 클래스가 담긴 값 = 제목
print(title.text)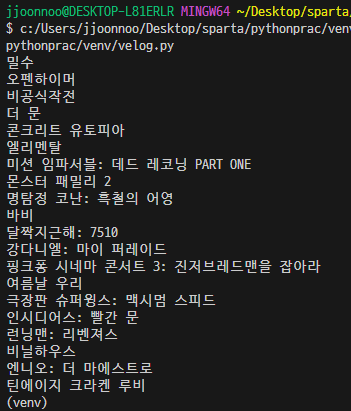
EXAMPLE) 웹스크래핑 해보기 (순위, 제목, 별점)
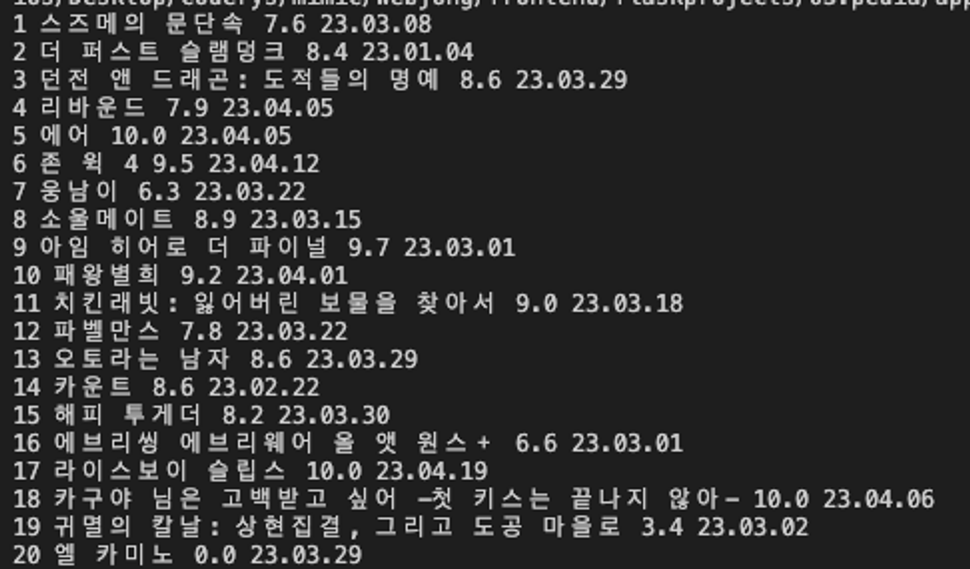
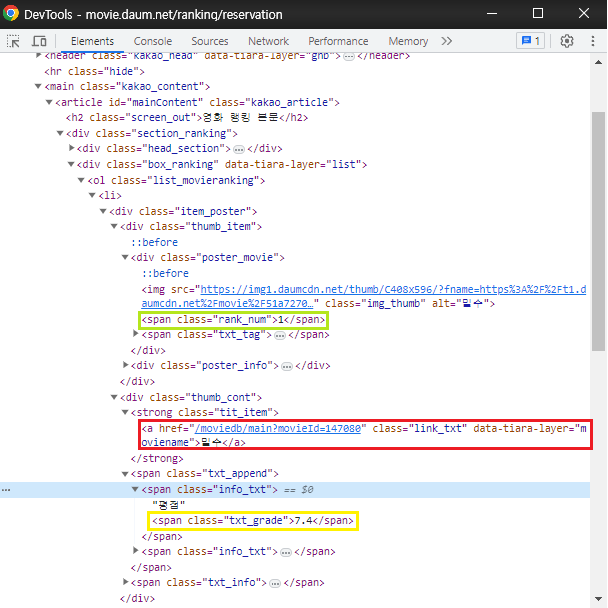
1) 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')2) select로 모든 영화 정보가 들어있는 li 태그까지의 선택자(copy selector)를 복사해와서 변수에 가져온 html을 넣는다.
movies = soup.select("#mainContent > div > div.box_ranking > ol > li")3) 반복문을 통해 영화의 순위, 제목, 평점만 텍스트 형태로 print
movies = soup.select("#mainContent > div > div.box_ranking > ol > li")
for li in movies:
rank = li.select_one(".rank_num").text
title = li.select_one(".tit_item").text
rate = li.select_one(".txt_grade").text
print(rank, title, rate)
4) 공백을 없애주는 strip()
movies = soup.select("#mainContent > div > div.box_ranking > ol > li")
for li in movies:
rank = li.select_one(".rank_num").text
title = li.select_one(".tit_item").text.strip()
rate = li.select_one(".txt_grade").text
print(rank,'.',title,':',rate)
-> 그래도 공백이 많다면 .strip("\n")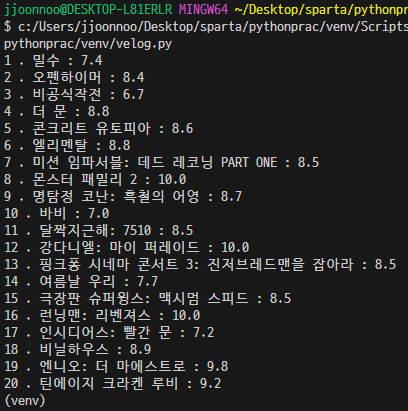
beautifoulsoup 사용법
1) select() / select_one()
select() : 모든 요소를 리스트에 담아 반환
select_one() : 가장 위에 나오는 요소를 반환2) copy selector 사용법
soup.select/select_one('태그명')
soup.select/select_one('.클래스명')
soup.select/select_one('#아이디명')
soup.select/select_one('상위태그명 > 하위태그명 > 하위태그명')
soup.select/select_one('상위태그명.클래스명 > 하위태그명.클래스명')3) 태그와 속성값으로 찾는 방법
soup.select/select_one('태그명[속성="값"]')mongoDB
- Database의 두 종류

1) RDBMS(SQL)
행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사하다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것이다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있다.
ex) MS-SQL, My-SQL 등
2) No-SQL
딕셔너리 형태로 데이터를 저장해두는 DB이다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 된다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있다.
ex) MongoDB
- MongoDB
다양한 플랫폼에서 사용할 수 있는 NoSQL 타입의 데이터베이스 프로그램
MongoDB의 자료는 JSON과 비슷한 형태로 정리되며 각각의 딕셔너리인 다큐먼트가 모여 컬렉션, 또 각각의 컬렉션이 모여 DB가 되는 형태이다.
위에서 크롤링했던 영화 정보를 예로 들면 제목, 순위, 별점이 있는 각각의 영화 정보가 다큐먼트이고, 이것들이 모인 컬렉션을 크롤링용 DB에 저장할 수 있다. 만약 멜론 차트의 노래 제목을 크롤링했다면 그 결과는 다른 컬렉션으로 같은 DB에 저장할 수 있다.
요즘 트렌드는 클라우드이기 때문에 최신 클라우드 서비스인 MongoDB Atlas를 사용할 것이다.
MongoDB Atlas
MongoDB 라는 프로그램을 조작하려면 따로 pymongo라는 특별한 라이브러리가 필요하다.
1) 패키지(라이브러리) 설치
(venv) 로 가상환경이 활성화 되었는지 확인하고 터미널에
pip install pymongo dnspython 입력2) pymongo 기본코드로 Python과 MongoDB 연결하기
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:test@cluster0.wop0dox.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta
-> 이것은 실행해도 아무 일도 안 일어난다. 라이브러리만 가져온 것이다.3) 잘 연결 되었는지 데이터(mongodb는 딕셔너리형)를 넣어 확인
doc = {
'name':'영수',
'age':24
}
db.users.insert_one(doc)
# DB의 'users'라는 컬렉션에 위의 doc이라는 다큐먼트를 추가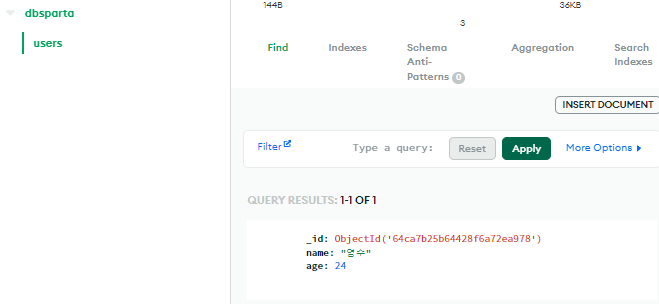
pymongo로 DB조작하기
- pymongo 사용법
1. 저장
doc = {'name':'영수','age':24}
db.users.insert_one(doc)
2. 특정 데이터 보기( _id 값은 제외하고 출력)
user = db.users.find_one({'조건'},{'_id':False})
user = db.users.find_one({'name':'영수'},{'_id':False})
-> {'_id':False}가 없으면 {'_id': ObjectId('64ca700c5f59ba0e35d935c2'), 'name':'영수','age':24} 이렇게 id값도 같이 보인다.
3. 데이터 모두 보기( _id 값은 제외하고 출력)
all_users = list(db.users.find({'조건'},{'_id':False}))
4. 데이터 값 바꾸기
db.users.update_one({'name':'영수'},{'$set':{'age':19}})
5. 데이터 지우기
db.users.delete_one({'name':'영수'})1-1) 'users'라는 컬렉션에 다른 딕셔너리 자료 넣어보기(.insert_one())
doc = {'name':'영희','age':30}
db.users.insert_one(doc)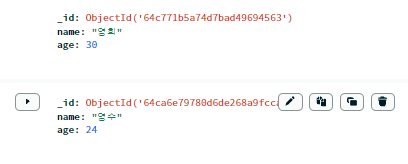
doc = {'name':'철수','age':20}
db.users.insert_one(doc)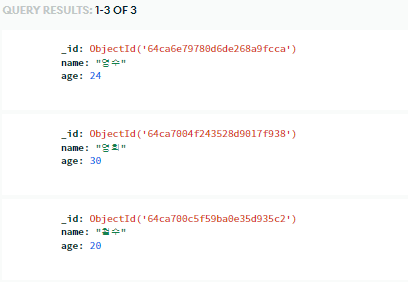
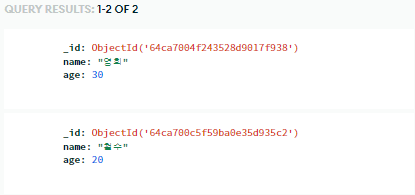
2-1) 특정 데이터 뽑아오기
user = db.users.find_one({'name':'철수'},{'_id':False})
print(user)
# {'name': '철수', 'age': 20}
3-1) 모든 데이터 뽑아보기
all_users = list(db.users.find({},{'_id':False}))
print(all_users)
# [{'name': '영수', 'age': 24}, {'name': '영희', 'age': 30}, {'name': '철수', 'age': 20}]
3-2) 모든 데이터 중 특정 데이터 뽑아보기
all_users = list(db.users.find({},{'_id':False}))
print(all_users[0])
# {'name': '영수', 'age': 24}
all_users = list(db.users.find({},{'_id':False}))
print(all_users[2]['name'])
# 철수
3-3) 반복문을 돌며 모든 결과값 보기
for a in all_users:
print(a)
#
{'name': '영수', 'age': 24}
{'name': '영희', 'age': 30}
{'name': '철수', 'age': 20}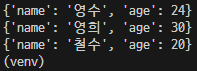
4-1) db의 데이터 조작(수정)하기
db.users.update_one({'name':'영수'},{'$set':{'age':19}})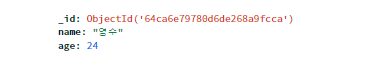
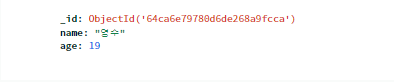
user = db.users.find_one({'name':'영수'},{'_id':False})
print(user)
# {'name': '영수', 'age': 19}
5-1) 데이터 삭제하기(거의 안씀)
db.users.delete_one({'name':'영수'})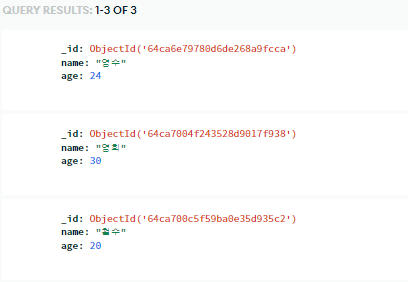
user = db.users.find_one({'name':'영수'})
print(user)
# None- 웹스크래핑 결과(영화 순위, 제목, 평점) 저장하기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('URL')
db = client.dbsparta
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select("#mainContent > div > div.box_ranking > ol > li")
for li in movies:
rank = li.select_one(".rank_num").text
title = li.select_one(".tit_item").text.strip()
rate = li.select_one(".txt_grade").text
print(rank,'.',title,':',rate)
doc = {
'title': title,
'rank': rank,
'rate': rate
}
db.movies.insert_one(doc)
# DB의 'movies'라는 컬렉션에 위의 doc이라는 다큐먼트를 추가
- 웹스크래핑 결과 이용하기
2010년 박스오피스 스크래핑 코드
from pymongo import MongoClient
import requests
from bs4 import BeautifulSoup
client = MongoClient('mongodb+srv://sparta:test@cluster0.wop0dox.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta
URL = "https://movie.daum.net/ranking/boxoffice/yearly?date=2010"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select(".list_movieranking > li")
for li in lis:
rank = li.select_one(".rank_num").text
age = li.select_one(".ico_see").text
title = li.select_one(".link_txt").text
print(rank, title, age)
doc = {
'rank': rank,
'title': title,
'age': age
}
db.movies2.insert_one(doc)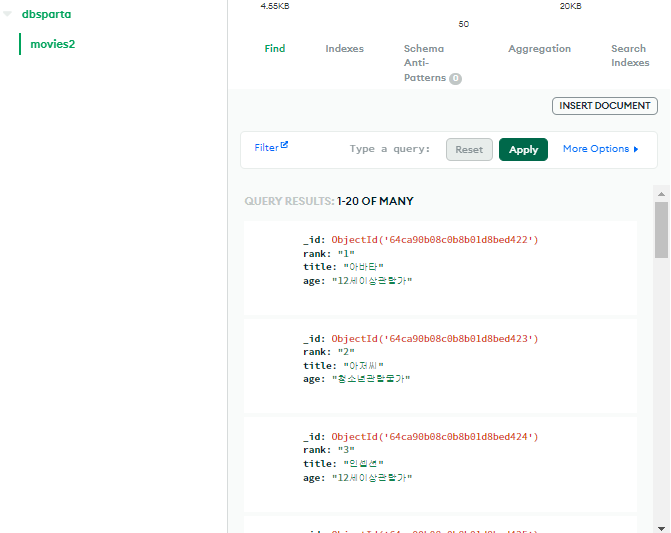
- 영화제목 '아저씨'의 순위를 가져오기
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:test@cluster0.wop0dox.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta1-1) pymongo로 db는 연결 되었으니 db의 class(movies2)에서 .find_one으로 'title' 값이 '아저씨'인 자료를 뽑아 아무 변수에 넣는다.
movie = db.movies2.find_one({'title':'아저씨'},{'_id':False})
print(movie)
# {'rank': '2', 'title': '아저씨', 'age': '청소년관람불가'}
1-2) 가져온 자료에서 'rank'값만 뽑아보자.
print(movie['rank'])
# 2
- '하모니'와 같은 관람가의 영화 제목들을 가져오기
2-1) pymongo로 db는 연결 되었으니 db의 class(movies2)에서 .find_one으로 'title' 값이 '하모니'인 자료를 뽑아 아무 변수에 넣는다.
movie = db.movies2.find_one({'title':'하모니'})
print(movie)
# {'rank': '9', 'title': '하모니', 'age': '12세이상관람가'}
2-2) .find_one()으로 가져온 'title'이 '하모니'인 자료에서 필요한 것은 'age' 값이기 때문에 변수 movie의 'age' 값을 아무 변수에 넣는다.
age = movie['age']2-3) 변수 movie의 'age' 값과 같은 모든 데이터를 list(db.movies2.find({'age':age},{'_id':False}))로 뽑아 아무 변수에 넣는다.
all_movies = list(db.movies2.find({'age':age},{'_id':False}))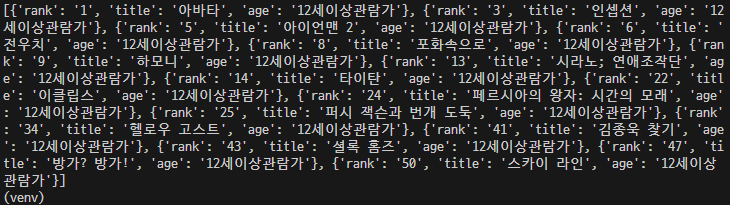
2-4) 반복문을 통해서 all_movies 안의 모든 영화 정보들을 돌면서 각 데이터의 'title'을 프린트한다.
movies = list(db.movies2.find({'age':age},'_id':False}))
for m in movies:
print(m['title'])
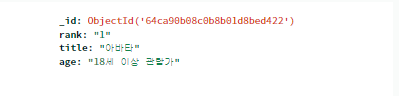
- '아바타' 영화의 관람가를 18세이상관람가로 만들기
db의 movies2에 'title'이 '아바타인 것을 찾아서 'age'를 .update_one()으로 18세이상관람과로 바꾼다.
db.movies2.update_one({'title':'아바타'},{'$set':{'age':'18세 이상 관람가'}})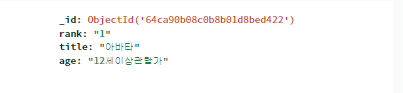
EXAMPLE) 지니뮤직의 1~50위 곡의 순위/곡 제목/가수 스크래핑하기
지니뮤직 사이트
https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101
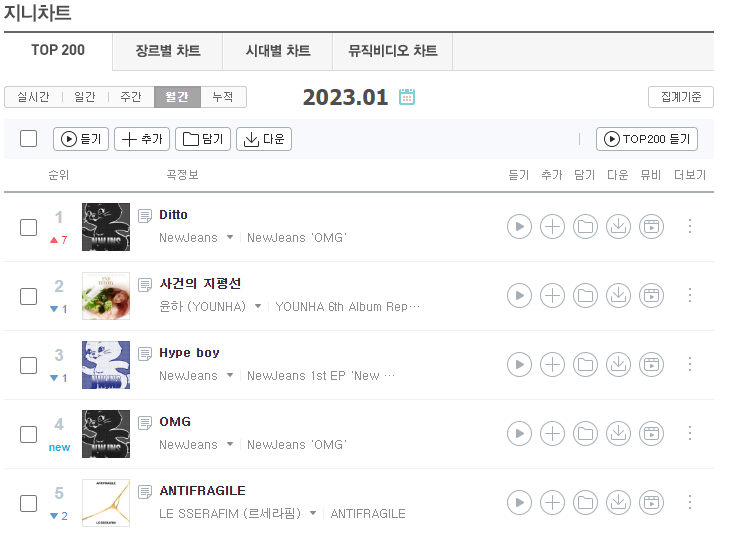
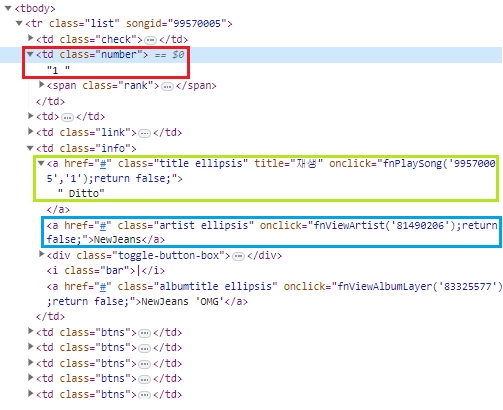
1) 개발자 도구에서 HTML 구조 파악
2) 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
URL = "https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')3) select로 모든 영화 정보가 들어있는 tr 태그까지의 선택자(copy selector)를 복사해와서 아무 변수에 가져온 html을 넣는다.
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')4) 가져온 데이터는 html의 뼈대를 보니 순위/곡 제목/가수에 해당하는 모든 html 태그에 class값이 지정되어 있으니 각 html을 .select_one('class 값')으로 가져와 아무 변수들에 넣고 반복문을 통해 가져온 html을 출력해보자.
for tr in trs:
title = tr.select_one('.title.ellipsis')
rank = tr.select_one('.number')
artist = tr.select_one('.artist.ellipsis')
print(rank, artist, title)
# 이상하게 나온다. -> class가 속해있는 상위 태그들을 구체적으로 적어야 되나보다.for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis')
rank = tr.select_one('td.number')
artist = tr.select_one('td.info > a.artist.ellipsis')
print(rank, artist, title)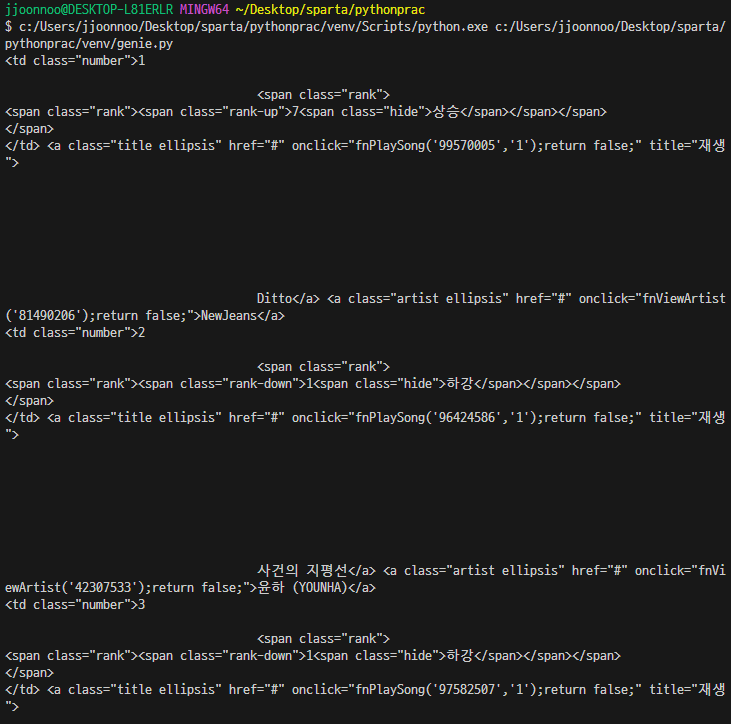
4-1) .select_one()으로 가져온 html을 .text를 이용해서 텍스트만 추출해보자.
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip() # 여백이 많아서 없애줌.
rank = tr.select_one('td.number').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)
4-2) 'rank'에 해당하는 text를 순위가 두 자리수가 최대니까 앞에서 두 글자만 끊어보자. ([시작 index : 끊을 글자 수])
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)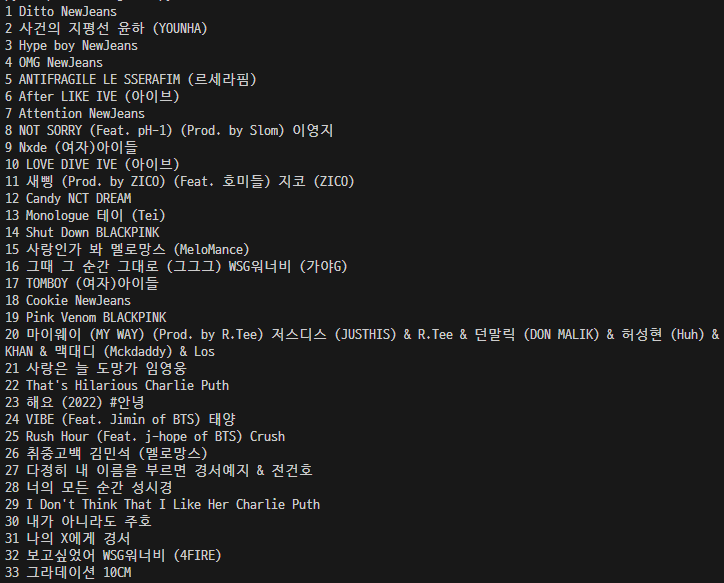
최대한 자세하게 보려고 노력은 해봤지만 아직 이론이 부족하다는 느낌이다..
