이진분류
교차검증 (cross validation)
k-fold 교차 검증
- 훈련 세트를 k개로 나누고 , 평가 때 매번 다른 fold를 사용해 k번 훈련하는 검증 과정
StratifiedKFold
- 클래스별 비율이 유지되도록 fold를 생성 , 계층적 sampling을 수행
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, shuffle=True)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))Dummy Classifier
from sklearn.dummny import DummyClassifier
dummy_clf = DummyClassifier()
dummy_clf.fit(X_train, y_train_5)
print(any(dummy_clf.predict(X_train))) # False cross_val_score(): 모든 교차 검증 fold에 대해 평가지표(일반적으로 accuracy)의 점수를 반환
cross_val_score(dummy_clf, X_train, y_train_5, cv=3, scoring="accuracy")
## array([0.9065, 0.90965, 0.90965]) cross_val_predict(): 모든 교차 검증 fold에서 얻은 예측을 반환
y_train_pred= cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)-
결과 해석
- 숫자 5는 이미지의 10%이기 때문에 무조건 '5가 아님'으로 예측하면 정확도 90%
-
accuracy(정확도) : 불균형한 데이터를 다룰 때 (ex.어떤 클래스가 다른 것보다 월등히 많을 때) 좋은 성능지표가 될 수 없음
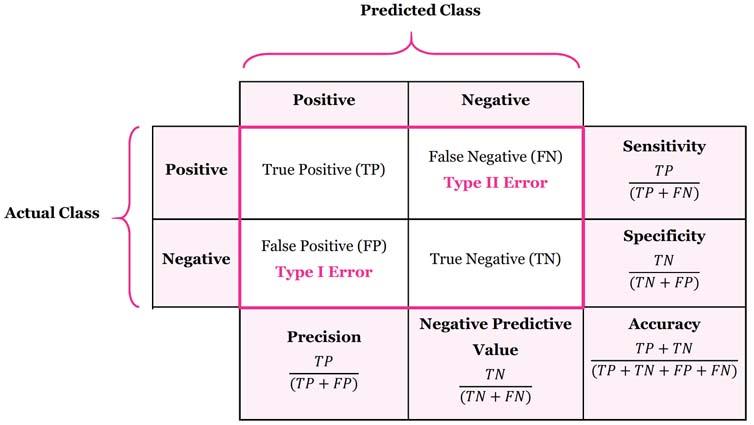
오차행렬 (confustion_matrix)
기본 아이디어 : 클래스 A의 sample이 클래스 B로 분류된 횟수를 셈
- 행은 실제 클래스, 열은 예측한 클래스를 나타냄
from sklearn met ics import confusion_mat
cm = confusion mat (y_t ain ain p ed)
cm
## array([[53892, 687], [1891, 3530]]) -
첫번째 행은 음성 클래스(5가 아님)를 의미
- 53,892개를 음성 클래스로 정확하게 분류했고 이를 True Negative 라고 함
- 나머지 687개는 양성 클래스로 잘못 분류했으므로 False Positive (1종 오류) 라고 함
-
두번째 행은 양성 클래스(5임)를 의미
- 1,891개는 음성 클래스로 잘못 분류했고 이를 False Negative (2종 오류) 라고 함
- 3,530개는 올바르게 양성 클래스로 분류했으므로 True Positive 라고 함
score
- 이외에, 요약된 지표로는 Precision, Recall 등이 있다.
Precision & Recall
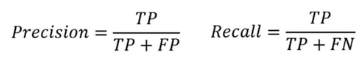
TP : 진짜 양성의 수
FP : 거짓 양성의 수
TN : 진짜 음성의 수
FN : 거짓 음성의 수
-
제일 확신이 높은 샘플을 양성 예측하고 나머지를 모두 음성 예측했을 때, 양성 예측이 맞다면 precision(정밀도)는 100%임
→ 그래서 재현율(recall) 을 같이 사용하는 것이 일반적임
- 높은 Precision이 중요한 경우
: 스팸 메일 필터링- 높은 Recall이 중요한 경우
: 암 진단 모델
Trade off (precision/recall)
- 결정 함수 (decision function)을 통해 각 sample의 점수를 결정하고, 점수가 임계값보다 크면 양성클래스 그렇지 않으면 음성 클래스로 분류
y_scores = sgd_clf .decision_function ([some_digit])
- 결정 임계값
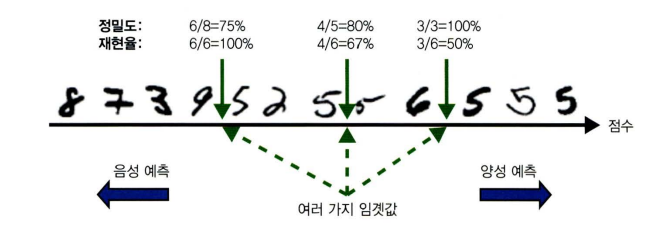
→ 임계값이 높아질수록 재현율(recall)은 낮아지고, 정밀도(precision)은 높아짐
→ recall과 precision은 trade-off 관계
precision_recall_curve() : 가능한 모든 threshold 값에 대해 precision과 recall을 계산
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
plt.plot(thresholds, precisions[:-1], "b--", label="정밀도", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="재현율", linewidth=2)
plt.vlines(threshold, 0, 1.0, "k", "dotted", label="임곗값")
plt.legend()
plt.show()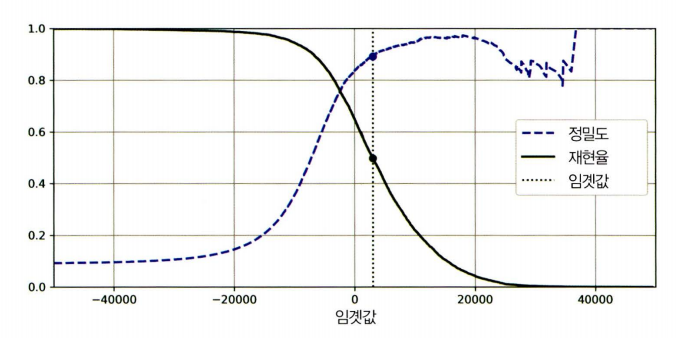
plt.plot(recalls, precisions, linewidth=2, label ”정밀도/재현율 곡선” )
[ ... ]
plt.show()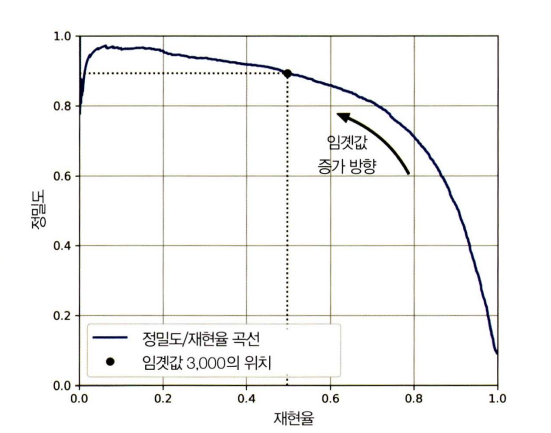
→ recall 80% 근처에서 precision이 급격하게 줄어들기 때문에 하강점 직전을 trade-off로 선택하는 것이 좋음
→ 선택은 프로젝트의 목표에 따라 다름 (어떤 재현율에서 precision % 달성하는지를 보는 것이 중요)
ROC Curve & AUC
TPR : 진짜 양성 비율
FPR : 거짓 양성 비율
TNR(특이도) : 진짜 음성 비율
recall(민감도) == 1-특이도
ROC Curve
threshold_for_90_precision = thresholds[np.argmax(precisions >= 0.90)]
fpr, tpr, roc_thresholds = roc_curve(y_true, y_scores)
idx_for_threshold_at_90 = (roc_thresholds <= threshold_for_90_precision).argmax()
tpr_90 = tpr[id_x_for_threshold_at_90]
fpr_90 = fpr[id_x_for_threshold_at_90]
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, linewidth=2, label="ROC 곡선")
plt.plot([0, 1], [0, 1], 'k--', label="랜덤 분류기의 ROC 곡선")
plt.plot(fpr_90, tpr_90, "ko", label="90% 정밀도 지점")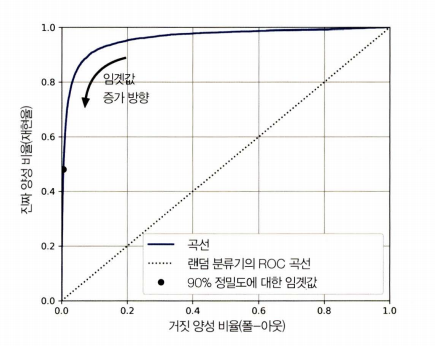
→ 좋은 분류기는 이 점선에서 최대한 멀리 떨어져 있어야 함
곡선 아래 면적(AUC)
- 완벽한 모델은 AUC의 값이 1, 랜덤 모델은 AUC가 0.5임
다중분류
- 둘 이상의 클래스를 구분하는 문제
- LogisticRegression, RandomForestClassifier, GaussianNB
: 여러개의 클래스를 처리- SGDClassifier, SVC
: 이진 분류기를 여러개 사용해 다중 클래스를 분류
여러개의 이진 분류기를 사용하는 방법
- OvR / OvA (One versus the Rest / One versus All)
: 𝐾개 class에 대해 K개의 이진 분류기를 학습하고, 각 분류기 예측을 비교해 score가 가장 높은 class로 예측함
- OvO (One versus One)
: 𝐾개 class에 대해, 가능한 모든 두 개 조합에 대해서의 클래스 Binary Classifier를 학습시키고 가장 많이 양성으로 분류된 클래스를 최종 예측으로 선택함
→ 총 N * (N-1) / 2개의 Classifier가 필요
다중 레이블 분류 (Multilabel classification)
- 하나의 sameple이 여러 개의 레이블에 동시에 속할 수 있는 분류 문제
Example
숫자가 7 이상인지 (large)
숫자가 홀수인지 (odd)
→ 이 두 가지 레이블을 동시에 예측1. y_multilabel 배열 생성
y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd]2. model 학습
knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel) knn_clf.predict([some_digit]) # → array([[False, True]])y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3) f1_score(y_multilabel, y_train_knn_pred, average='macro') # → 0.9764102655606053. 성능 평가
- 각 레이블에 대한 F1-Score를 계산한 후, 이들을 평균하여 성능을 나타냄
- average parameter
- macro : 클래스별 중요도 동일 (→ 단순평균)
- weighted : 각 레이블의 지지도(Support)에 따라 중요도를 다르게 부여
다중 출력 분류 (Multioutput classification)
-
다중 레이블 분류에서 한 레이블이 다중 class가 될 수 있도록 일반화한 것
ex) 이미지에 노이즈를 추가하고 복원 작업 진행
# 노이즈 생성
np.random.seed(42)
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
 left: input / right: target
left: input / right: target
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[0]])
plot_digit(clean_digit)
plt .show()
 output
output
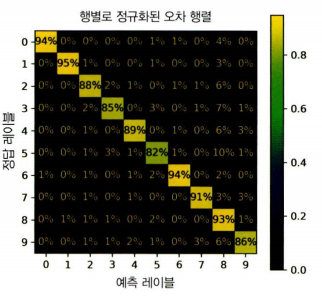
오류분석
→ 오차 행렬 분석
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
ConfusionMatrixDisplay.from_predictions(y_train, y_train_pred)
plt.show()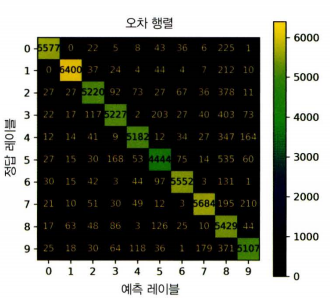
→ 정규화된 오차 행렬 분석
ConfusionMatrixDisplay.from_predictions(
y_train, y_train_pred,
normalize='true', # 각 행을 기준으로 정규화 (실제 클래스 기준)
values_format=".0%" # 퍼센트 표시
)
plt.show()