Overview
- 왜 데이터를 preprocessing 하는가?
Accuracy, Completeness, Consistency, Timeliness, Believability, Interpretability - Preprocessing의 종류
Data cleaning, Data integration, Data reduction, Data transformation
Data cleaning
- 현실의 데이터는 더럽다 : Incomplete, Noisy, Inconsistent, Intentional
- 보통 Missing data는 most probable value로 채워넣는다.
- Noisy data는 Binning, regression, clustering 등을 사용해서 처리한다.
Binning: 먼저 정렬한 뒤, 데이터를 파티셔닝. 파티셔닝 된 데이터들을 smoothing 한다.
Data integration
- 서로 다른 곳에서 모인 데이터는 scheme integration, entity resolution, redundancy, inconsistency 등의 문제를 겪는다.
- redundancy는 Pearson product-moment coefficient로 찾아낼 수 있다.
두 데이터의 linear dependence를 찾아내는 것. Population, Sample에 따라서 서로 다른 공식이 사용된다. 1 혹은 -1에 가까울수록 상관관계가 강하게 나타난다.
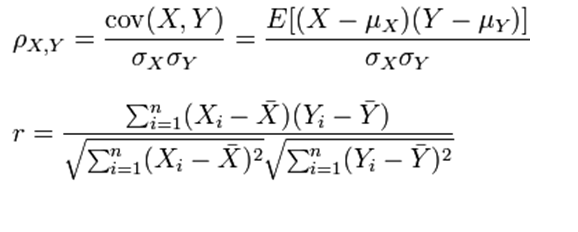
Data reduction
-
더 작은 볼륨의 데이터지만 여전히 분석적으로는 같은 데이터를 보여준다.
-
Dimensionality reduction, Numerosity reduction, Data compression
-
차원의 저주: 차원이 많아질수록 오히려 데이터의 경향성을 파악하기 어렵다. 다른 데이터와의 상관관계를 추론하는데 필요한 density, distance 등이 점점 의미가 없어짐.
-
어느 차원에 있는 하이퍼큐브의 부피는 , 하이퍼큐브에 내접하는 구의 부피는 로 주어진다.
그냥 어렵게 생각할 것 없이, 차원이 커질수록 내접한 구의 부피는 거의 안 변하는데 하이퍼큐브는 급격하게 커진다고 생각하면 된다. 구의 내부에 있는가, 밖에 있는가 여부에 따라서 데이터 간 거리는 크게 달라지게 되며, 결과적으로 거리라는 체계 자체가 신뢰할 수 없는 것이 된다.
예: 구 밖에 있는 두 점은 차원이 증가함에 따라 급격하게 멀어짐, 하지만 구 내부에 있는 두 점은 차원이 증가해도 급격하게 멀어지지 않음. -
이를 막기 위해 Dimensionality reduction이 사용된다.
1) PCA: 데이터를 가장 큰 variance를 갖는 축으로 reduction
2) Attribute subset selection: 중복 데이터나 불필요한 피처를 삭제
3) Discrete Wavelet Transform: 생략. 그렇게 간단한 방법은 아니다. -
Numerosity reduction
1) Regression: least sqaures method가 주로 사용됨
2) Sampling: 데이터를 대표하는 적절한 subset을 찾는 것.Stratified sampling: 데이터의 분포에 비례해서 적절하게 샘플링.
3) Data cube aggregation: 적은 수의 단위 데이터로 가져오는 것.
4) Data compression: 원래는 데이터 크기 줄이는데 사용되었으나, query의 성능을 늘리는데도 중요해졌다.- Run-length encoding: (value, start_pos, run_length)로 인코딩
- Dictionary encoding: 유니크한 값들을 그냥 비트로 하나하나 매핑하는 것
Data transforamtion
데이터의 형태를 변화 시키는 것.
- Min-max normalization
- Z-score normalization
- Data discretization: 연속된 데이터를 적절히 쪼개서 양자화 하는 것
- Concept hierarchy generation: 시-군-구 같은 개념의 계층화.
