Linked List의 유연한 insert의 장점을 살리면서 느린 search의 시간복잡도를 으로 보완한 자료구조인 SkipList를 소개한다.
SkipList
Node
Linked List는 각 Node당 next 포인터를 하나만 가진다.
반면, SkipList는 Level이 존재하며, 각 Node당 해당 노드의 최대 level만큼의 next 포인터를 가진다.
class Node {
public:
int value;
int level;
Node** next;
Node(int value, int level) : value(value), level(level) {
next = new Node*[level + 1](); // () 로 nullptr 초기화
}
~Node() {
delete[] next;
}
};Level
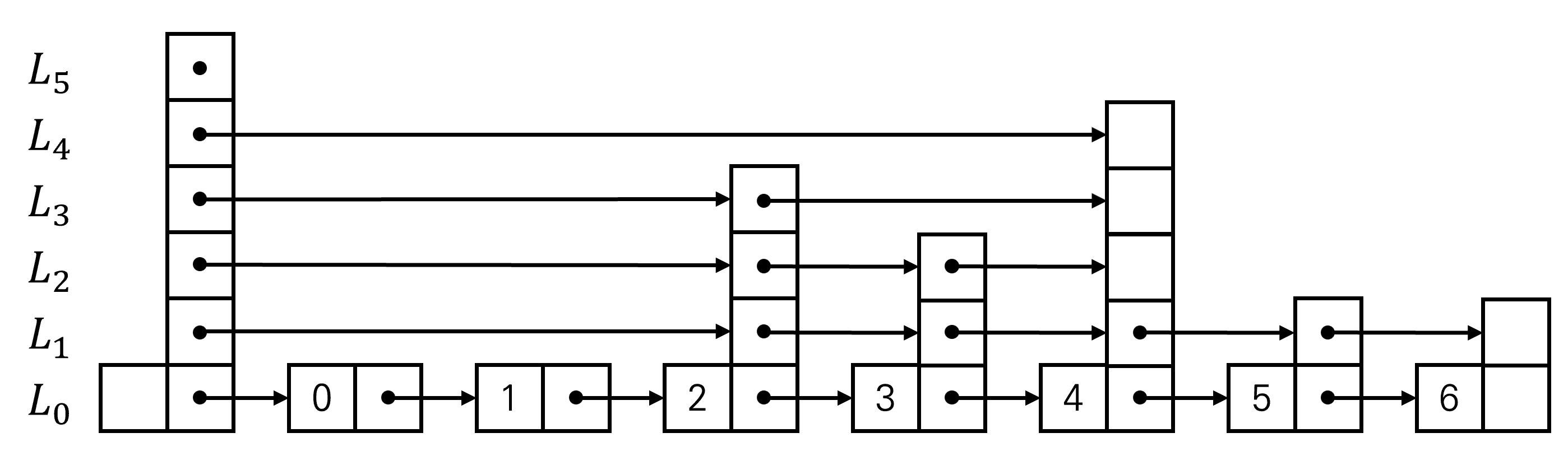
SkipList의 Level 0은 Linked List와 같은 구조로 되어있으며, 해당 노드가 각 상위 레벨에도 있을 확률은 에 의존한다. (일반적으로 )
이에 따라 상위 레벨로 갈수록 Node가 점차 줄어들며, Binary Search와 비슷한 형태로 Search가 진행되는 구조로 변하게 된다.
Head (Sentinel Node)
SkipList는 탐색의 시작점이 되는 head 노드를 별도로 유지한다.
head 노드는 유일하게 MAX_LEVEL만큼의 next 포인터를 전부 가지며, 초기에는 모두 nullptr로 초기화된다. 모든 탐색은 head의 최상위 레벨부터 시작한다.
초기 상태:
level 3: head → NULL
level 2: head → NULL
level 1: head → NULL
level 0: head → NULLFunction
_Search
bool search_node(int value) {
Node* cur = head;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value <= value) {
cur = cur->next[c_level];
if (cur->value == value)
return true;
}
}
return false;
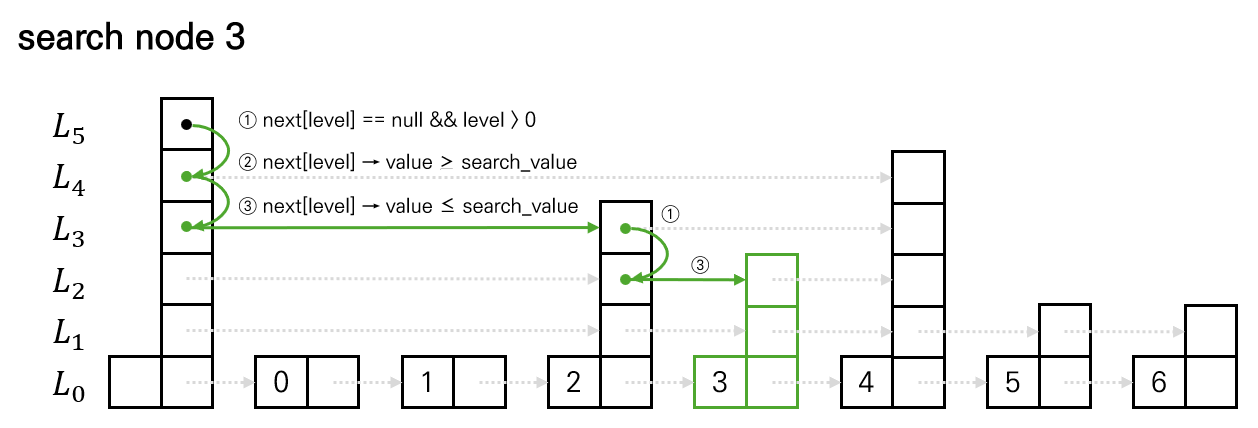
}Search 연산은 최상위 Level부터 시작하여 다음의 조건에 따라 진행된다.
node->next[level] is null && level > 0→ Go to Lower Levelnode->next[level]->value > search_value→ Go to Lower Levelnode->next[level]->value <= search_value→ Go to Nextnode->next[level] is null && level == 0→ return false- level 0까지 찾았으나, 찾고자 하는 node가 없음
_Insert
[decide_level]
int decide_level() {
uniform_int_distribution<uint32_t> dist(0, UINT32_MAX);
uint32_t random = dist(gen);
int level = 0;
while ((random & 1) && level < MAX_LEVEL - 1) {
random >>= 1;
level++;
}
return level;
}각 Node의 level은 insert 하는 시점에서 정해지며 확률 에 의존하도록 구성한다.
일반적으로 이므로 랜덤 정수 값을 기준으로 이진수의 연속된 1의 개수로 레벨을 정하여 구현한다. 이 방식은 레벨 결정에 필요한 랜덤 생성을 1회 호출로 처리할 수 있어 반복 호출 방식보다 효율적이다.
(물론 에 의존하는 랜덤 함수로 구현해도 된다)
[insert node]
void insert(int value) {
Node** update = new Node*[MAX_LEVEL];
Node* cur = head;
// 1. 정합성을 위해 insert할 위치 탐색
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value < value)
cur = cur->next[c_level];
// 중복 체크
if (cur->next[c_level] && cur->next[c_level]->value == value) {
delete[] update;
return;
}
update[c_level] = cur;
}
// 2. Node의 level 정한 뒤, 각 level에 해당하는 위치에 넣기
int level = decide_level();
Node* new_node = new Node(value, level);
for (int c_level = level; c_level >= 0; c_level--) {
new_node->next[c_level] = update[c_level]->next[c_level];
update[c_level]->next[c_level] = new_node;
}
delete[] update;
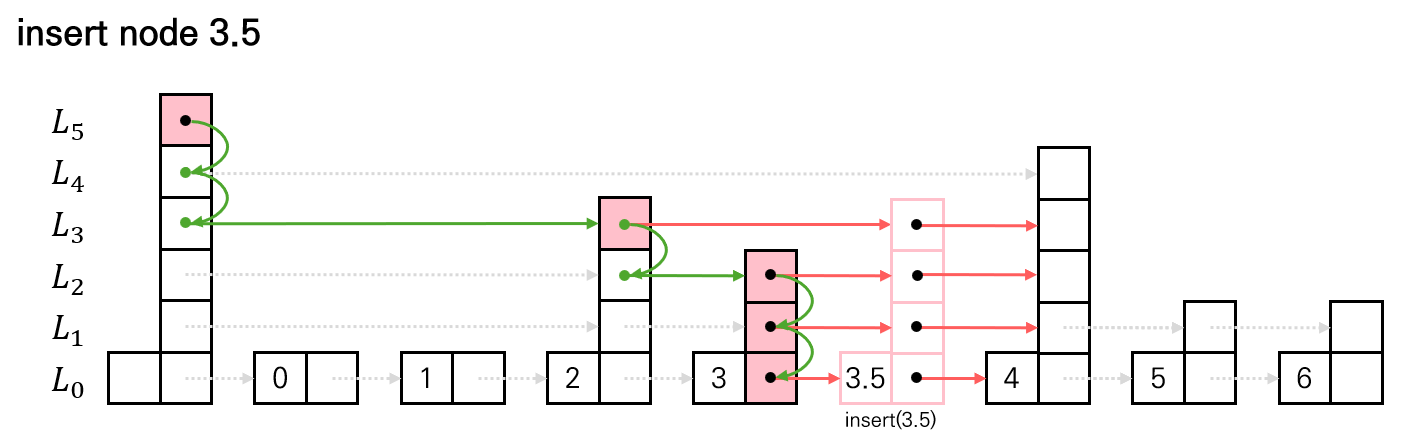
}Node의 insert는 정합성을 위해 각 level에 대해 먼저 insert할 위치를 탐색한다. (update 배열)
탐색과 동시에 삽입을 진행할 경우, 새로운 노드에 대해 일부 레벨만 연결시킨 불완전한 상태를 만들게 된다.
이는 탐색 중 자기 자신을 다시 마주치거나, 멀티스레드 환경에서 불완전한 노드가 노출되는 문제로 이어질 수 있다.
따라서 탐색(update 배열 완성) → 연결(일괄 insert) 의 두 단계로 분리하여 구조 변경 시점을 최소화한다.
[큰 수의 법칙]
큰 수의 법칙에 의거하여 level k당 노드의 기대 개수는 이다.
이로 인해 대부분의 경우 의 시간복잡도를 보장할 수 있으나, 상위 레벨이 앞쪽에 쏠리는 경우 최악 이 걸릴 수 있다. (편향 이진 트리와 흡사)
_Delete
void delete_node(int value) {
Node** update = new Node*[MAX_LEVEL]();
Node* cur = head;
// 1. 각 level에서 삭제할 node의 직전 node 탐색
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value < value)
cur = cur->next[c_level];
if (cur->next[c_level] && cur->next[c_level]->value == value)
update[c_level] = cur;
}
// 2. 각 level에서 연결 해제 후 메모리 해제
Node* del_node = nullptr;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
if (update[c_level]) {
// del_node 확정
if (!del_node) del_node = update[c_level]->next[c_level];
// 연결 끊기
update[c_level]->next[c_level] = del_node->next[c_level];
}
}
delete[] update;
if (del_node) delete del_node;
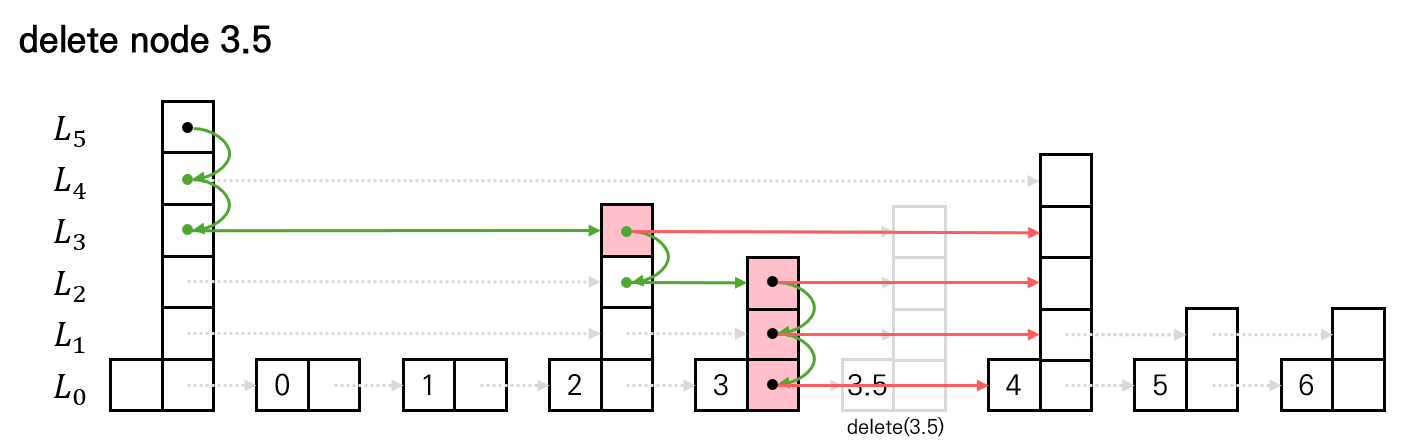
}Delete 연산도 insert와 동일하게 탐색 → 연결 해제 의 두 단계로 진행된다.
update 배열에 각 level에서 삭제할 노드의 직전 노드를 기록한 뒤,
del_node를 먼저 확정하고 del_node->next[c_level]로 연결을 끊는다.
이는 update[c_level]->next[c_level]->next[c_level] 방식으로 접근하는 것보다 안전하다.
연결이 이미 끊긴 포인터를 다시 역참조하는 상황을 방지할 수 있기 때문이다.
마지막으로 del_node를 단 한 번만 delete하여 메모리를 해제한다.
(같은 노드 객체가 여러 레벨에 걸쳐 연결되어 있더라도, 노드 객체는 하나이기 때문이다.)
전체 코드
#include <iostream>
#include <random>
using namespace std;
class Node {
public:
int value;
int level;
Node** next;
Node(int value, int level) : value(value), level(level) {
next = new Node*[level + 1]();
}
~Node() {
delete[] next;
}
};
class SkipList {
int MAX_LEVEL;
Node* head;
std::mt19937 gen;
public:
SkipList(int MAX_LEVEL = 4) : MAX_LEVEL(MAX_LEVEL), gen(std::random_device{}()) {
head = new Node(-INT_MAX, MAX_LEVEL - 1);
}
~SkipList() {
Node* cur = head->next[0];
while (cur) {
Node* temp = cur->next[0];
delete cur;
cur = temp;
}
delete head;
}
int decide_level() {
uniform_int_distribution<uint32_t> dist(0, UINT32_MAX);
uint32_t random = dist(gen);
int level = 0;
while ((random & 1) && level < MAX_LEVEL - 1) {
random >>= 1;
level++;
}
return level;
}
void insert(int value) {
Node** update = new Node*[MAX_LEVEL];
Node* cur = head;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value < value)
cur = cur->next[c_level];
if (cur->next[c_level] && cur->next[c_level]->value == value) {
delete[] update;
return;
}
update[c_level] = cur;
}
int level = decide_level();
Node* new_node = new Node(value, level);
for (int c_level = level; c_level >= 0; c_level--) {
new_node->next[c_level] = update[c_level]->next[c_level];
update[c_level]->next[c_level] = new_node;
}
delete[] update;
}
bool search_node(int value) {
Node* cur = head;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value <= value) {
cur = cur->next[c_level];
if (cur->value == value)
return true;
}
}
return false;
}
void delete_node(int value) {
Node** update = new Node*[MAX_LEVEL]();
Node* cur = head;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
while (cur->next[c_level] && cur->next[c_level]->value < value)
cur = cur->next[c_level];
if (cur->next[c_level] && cur->next[c_level]->value == value)
update[c_level] = cur;
}
Node* del_node = nullptr;
for (int c_level = MAX_LEVEL - 1; c_level >= 0; c_level--) {
if (update[c_level]) {
if (!del_node) del_node = update[c_level]->next[c_level];
update[c_level]->next[c_level] = del_node->next[c_level];
}
}
delete[] update;
if (del_node) delete del_node;
}
void print_each_level() {
for (int level = MAX_LEVEL - 1; level >= 0; level--) {
Node* cur = head->next[level];
cout << "level (" << level << "): ";
while (cur) {
cout << cur->value << " ";
cur = cur->next[level];
}
cout << "\n";
}
}
};사용처
병렬 환경에서 B-Tree는 재균형이 일어날 때 관련된 Node들에 Lock을 걸어야 하기 때문에 동시성이 좋지 않다. 이러한 문제로 SingleStore의 rowstore (in-memory DB)에서는 Lock-free SkipList를 사용한다.
[Lock-free SkipList]
Lock-free SkipList는 Lock-free Linked List와 동일하게 CAS (Compare-And-Swap) 를 기반으로 동작한다.
삽입 과정에서는 level 0부터 CAS로 먼저 삽입하여 데이터 유실이 발생하지 않도록 진행하고, 각 상위 레벨도 하나씩 CAS를 진행해 나간다.
삭제 과정에서는 여러 레벨의 포인터를 동시에 수정할 수 없으므로 Tagged Pointer를 활용한 논리적 삭제를 먼저 진행한다. 삭제될 노드의 next 포인터 LSB에 마킹을 달아 다른 스레드가 해당 노드를 predecessor로 삼지 못하도록 하며, level 0 마킹 완료 시점을 논리적 삭제 완료로 본다.
Thread A: level 0 마킹 → level 1 마킹 → level 2 마킹 중...
Thread B: 탐색 중 마킹된 노드 발견
→ 기다리지 않고 직접 물리적 연결 해제 (helping)
→ 그 다음 자기 작업 계속 진행Lock-free SkipList 설명까지 모두 포함하면 너무 길어지므로 간략하게 설명했으나, 이후 게시할 예정입니다.
