스트림
-
데이터의 흐름을 가리켜 ‘스트림’이라고 한다. 그리고 데이터를 흘려보낼 연산의 종류는 다음 두가지로 나뉜다.
중간연산(Intermediate Operation) : 마지막이 아닌 위치에서 진행이 되어야 하는 연산
최종 연산(Terminal Operation) : 마지막에 진행이 되어야 하는 연산 -
스트림은 데이터의 복사본, 중간 연산과 최종 연산을 진행하기 좋은 구조로 배치된 복사본.

-
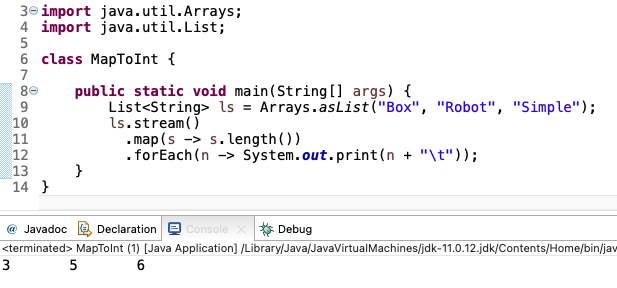
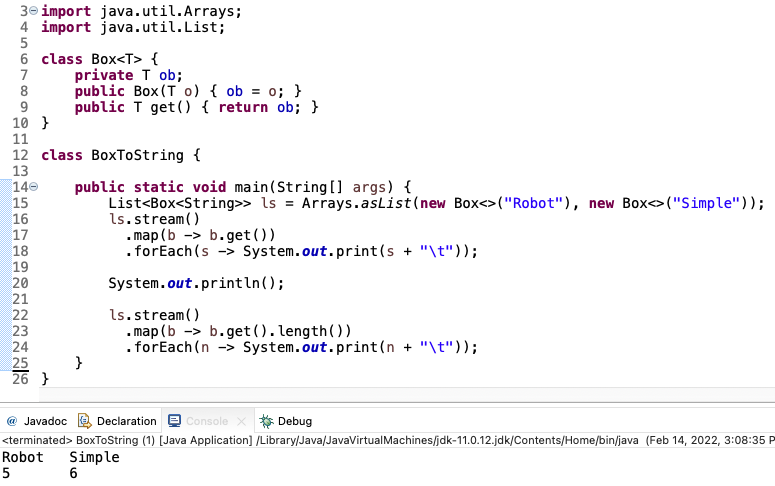
맵핑(Mapping)을 진행하면 스트림의 데이터 형이 달라지는 특징이 있다.
-
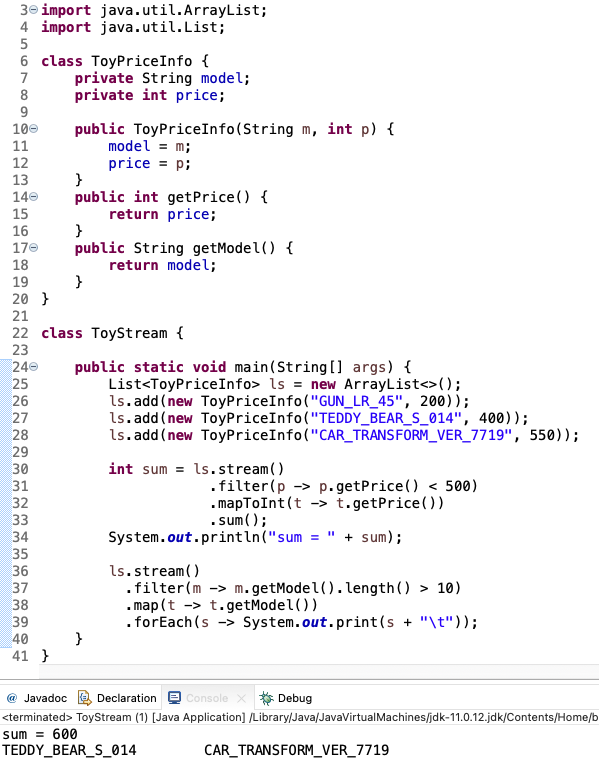
필터와 맵핑 사용, 중간 연산자를 함께 사용
-
리덕션, reduce 메소드 사용
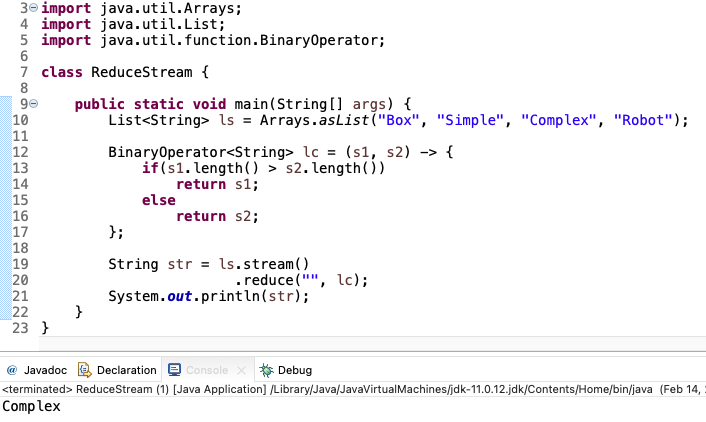
reduce 메소드의 ‘첫 번째 인자로 전달된 값’을 스트림이 빈 경우에 반환을 한다. 뿐만 아니라 스트림이 비어 있지 않은 경우에는 이를 스트림의 첫 번째 데이터로 간주하고 리덕션을 진행한다. -
컬렉션 인스턴스도 그 자체로 스트림을 이루는 데이터가 되게 할 수 있다. Stream.of 메소드에 컬렉션 인스턴스를 전달하면 해당 인스턴스 하나로 이뤄진 스트림이 생성된다. 그런데 Stream.of 메소드에 배열을 전달하면 그때는 하나의 배열로 이뤄진 스트림이 생성되는 것이 아니라, 배열에 저장된 요소로 이뤄진 스트림이 생성된다.
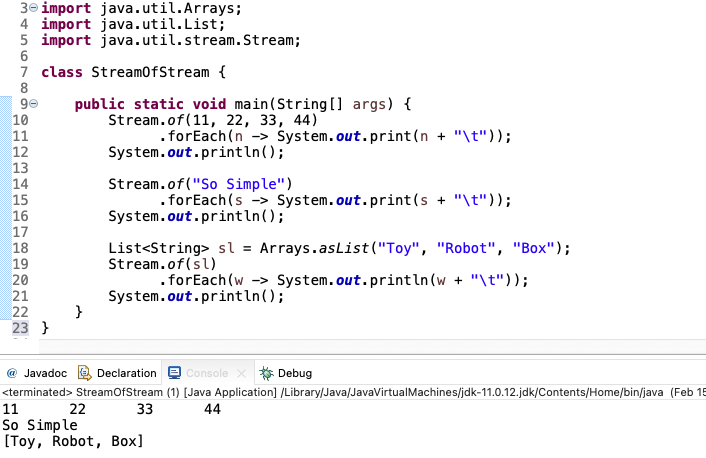
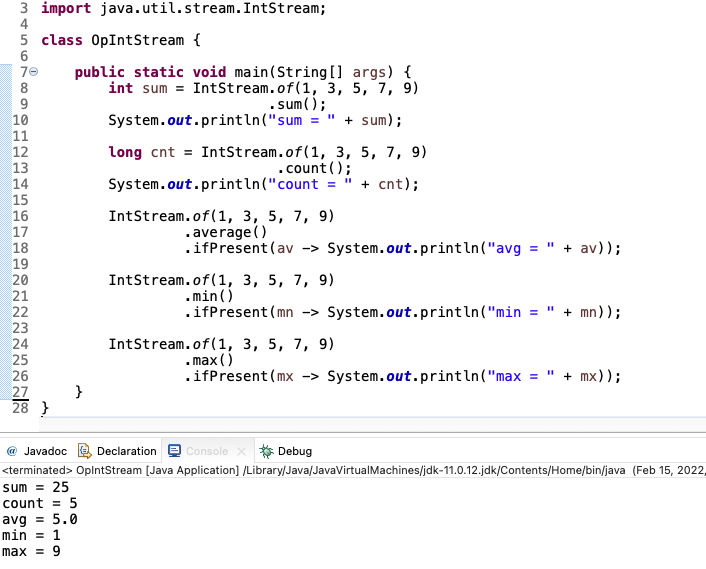
위의 예제를 보고 하나의 스트림을 생성해서 이름 기반으로 합도 계산하고 개수도 하는 등 필요한 모든 것을 계산하는 코드를 작성하면 어떨가 하는 생각을 할 수 있다.
IntStream is = IntStream.of(1, 3, 5, 7, 9);
System.out.println(“sum = “ + is.sum);
System.out.println(“count = “ + is.count());
그러나 스트림은 최종 연산을 하는 순간 ‘파이프라인’의 마지막을 통과해버린다.
따라서 이미 흘러가버린 스트림을 대상으로는 그 어떤 연산도 추가로 진행할 수 없다.
때문에 위 예제에서 보이듯이 얻고자 하는 것이 있다면 그때마다 매번 스트림을 생성해야 한다.
그리고 이러한 스트림의 특성 때문에 실제 코드에서 Stream< T>형 참조변수나 IntStream형 참조변수를 선언할 일이 거의 없다.
I/O 스트림
-
스트림의 주제: 데이터를 어떻게 원하는 형태로 걸러내고 가공할 것인가?
-
I/O 스트림의 주제: 어떻게 데이터를 입력하고 출력할 것인가?
-> 다수의 문자열을 저장하고 있는 파일이 하나 있다고 가정하고, 이 파일에 저장된 문자열을 꺼내서 컬렉션 인스턴스에 저장하고, 이렇게 저장된 문자열 중에서 길이가 5 이상인 문자열만 출력을 하고자 한다. 이때 해야 할 일은 다음과 같이 두 가지로 나뉜다.
1) 파일에 저장된 문자열을 꺼내어 컬렉션 인스턴스에 저장 -> ‘I/O 스트림’으로 해결해야 할 부분,
2) 컬렉션 인스턴스에 저장된 문자열 중 길이가 5 이상인 문자열만 출력 -> ‘스트림’으로 해결해야 할 부분 -
데이터를 넣고 꺼내는 일도 스트림을(데이터의 흐름을) 형성해야 할 수 있는 일이고, 데이터의 가공도 스트림을 형성해야 할 수 있는 일이다. 스트림이라는 이름이 중복으로 사용이 되었지만 적용되는 영역은 다르다.
-
입력 스트림 (Input Stream) -> 실행 중인 자바 프로그램으로 데이터를 읽어 들이는 스트림
출력 스트림 (Output Stream) -> 실행 중인 자바 프로그램으로부터 데이터를 내보내는 스트림 -
int형 데이터 하나를 읽어 들이려면 다음의 단계를 거쳐야 한다.
단계 1: 파일로부터 1바이트 데이터를 4개를 읽어 들인다.
단계 2: 읽어 들인 1바이트 데이터 4개를 하나의 int형 데이터로 조합한다.
이 중 두 번째 단계의 일을 하는 스트림을 가리켜 ‘필터 스트림’이라 한다. 이러한 필터 스트림은 입력 또는 출력 스트림에 덧붙여서 데이터를 조합, 가공 및 분리하는 역할을 한다. -
문자만 저장되어 있는 파일을 복사하려고 한다. 이때 필요한 스트림은?
-> 문자 스트림을 통해서도 복사를 진행할 수 있지만 기본적으로 파일 복사는 파일의 내용에 상관없이 있는 그대로의 바이트 정보가 저장된 파일을 하나 더 만드는 일이다. 따라서 바이트 스트림을 생성해서 복사를 진행하는 것이 원칙이다. -
자바 프로그램에서 문자 하나를 파일에 저장했다가 다시 읽어 들이려 한다. 이때 필요한 스트림은?
-> 파일에 문자를 저장하는 주체도, 저장된 문자를 읽는 주체도 자바 프로그램이다. 따라서 문자를 유니코드로 저장하고 읽어 들이면 충분하므로 바이트 스트림을 생성하는 것이 옳다. 물론 문자 스트림을 생성해서 이 일을 처리할 수 있다. 그러나 그 과정에서 불필요하게 문자의 인코딩을 변경하는 일만 생기게 된다. -
운영체제상에서 만든 텍스트 파일의 내용을 자바 프로그램에서 읽어서 출력하려 한다. 이때 필요한 스트림은?
-> 운영체제상에서 만든 텍스트 파일은 메모장과 같은 프로그램을 실행해서 원하는 내용을 담은 파일을 의미한다. 그리고 이렇게 만들어진 파일에 저장된 문자들은 해당 운영체제의 기본 문자 인코딩 방식을 따른다. 따라서 이 문자들을 실행 중인 자바 프로그램에서 읽어 들이려면 유니코드로의 인코딩 변화가 필요하다. 그러므로 이 경우에는 문자 스트림을 생성해야 한다. -
바이트 스트림을 통해서 인스턴스를 통째로 저장하고 꺼내는 것도 가능하다. 인스턴스를 통째로 저장하는 것을 가리켜 ‘객체 직렬화(Object Serialization)’라 하고, 역으로 저장된 인스턴스를 꺼내는 것을 가리켜 ‘객체 역 직렬화(Object Deserialization)’이라 한다. “입출력의 대상이 되는 인스턴스의 클래스는 java.io.Serializable을 구현해야 한다.”
-
절대 경로는 루트 디렉토리부터 시작하는 파일의(디렉토리의) 위치 정보이다. 상대 경로는 ‘현재 디렉토리’를 기준으로 파일의(디렉토리의) 위치를 표현한다.
-
프로그램이 실행되면 그 프로그램의 작업 디렉토리가 하나 정해진다. 그리고 그 작업 디렉토리를 가리켜 ‘현재 디렉토리’라 한다. 예를 들어서, 실행 중인 프로그램에서 경로 정보 없이 파일을 생성하면 파일이 생성되는 디렉토리가 있는데 그곳이 바로 ‘현재 디렉토리’이다. 그리고 ‘절대 경로’는 그 이름처럼 파일 또는 디렉토리의 위치를 루트 디렉토리를 기준으로 표현한 경로이다. 따라서 절대 경로로 가리키는 파일은 그 대상이 변하지 않는다. 하지만 ‘상대 경로’는 현재 디렉토리가 어디냐에 따라서 가리키는 파일이 달라진다.
-
스트림도 채널도 데이터의 입력 및 출력을 위한 통로가 된다. 스트림은 한 방향으로만 데이터가 이동하지만 채널은 양방향으로 데이터 이동이 가능하다. 그러나 채널은 반드시 버퍼에 연결해서 사용해야 한다. 스트림 생성 후 성능향상을 위해 필터 스트림인 버퍼 스트림을 연결한다. 이때 버퍼 스트림의 연결은 선택이다. 그러나 NIO에서는 채널에 직접 데이터를 쓰고 읽는 것을 허용하지 않는다. 반드시 채널에 버퍼를 연결해서 버퍼를 대상으로 쓰고 읽을 것을 요구한다.
데이터 -> 버퍼 -> 채널 -> 파일
데이터 <- 버퍼 <- 채널 <- 파일
쓰레드
-
쓰레드는 실행 중인 프로그램 내에서 ‘또 다른 실행의 흐름을 형성하는 주체’를 의미한다.
-
쓰레드의 생성을 위해 제일 먼저 할 일은 java.lang.Runnable 인터페이스를 구현하는 클래스의 인스턴스를 생성하는 일이다. 그런데 Runnable은 ‘void run()’ 추상 메소드 하나만 존재하는 함수형 인터페이스이다. 따라서 람다식을 기반으로, 메소드의 구현과 인스턴스의 생성을 동시에 진행하면 구현된 메소드는 새로 생성되는 쓰레드에 의해 실행되는 메소드이다.
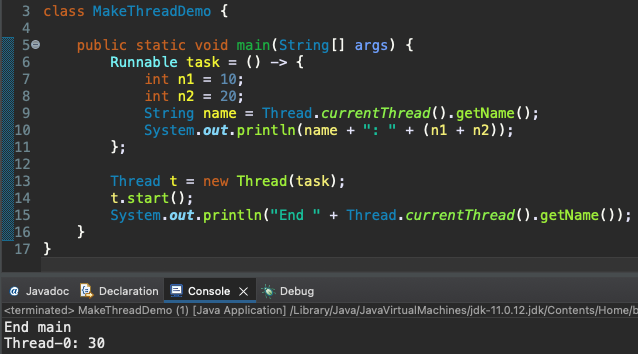
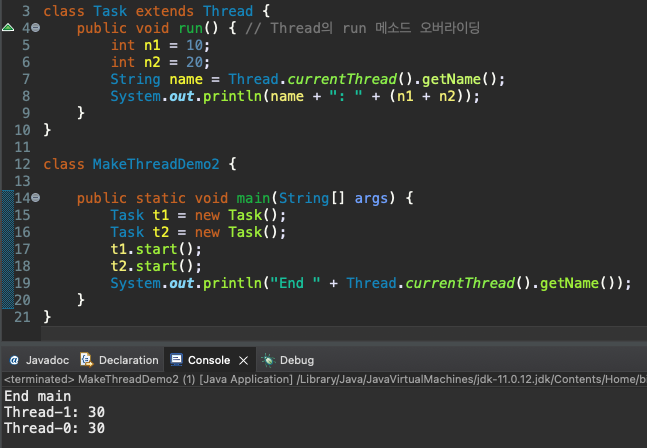
start 메소드 호출 -> 쓰레드의 생성 및 실행 위의 실행 결과에서는 main 쓰레드가 먼저 일을 마친 상황을 보이고 있다. 쓰레드의 생성에는 시간이 걸리므로 이러한 상황은 쉽게 연출이 된다. 그러나 main 쓰레드가 일을 마쳤다고 해서 프로그램이 종료되지는 않는다. 모든 쓰레드가 일을 마치고 소멸되어야 프로그램이 종료된다. 위와 같이 생성된 쓰레드는 자신의 일을 마치면(run 메소드의 실행을 완료하면) 자동으로 소멸된다. (여기서 말하는 쓰레드의 소멸은 쓰레드의 생성을 위해 할당했던 모든 자원의 해제를 의미한다.) -
쓰레드를 생성하는 두 가지 방법
- Runnable을 구현한 인스턴스 생성 -> Thread 인스턴스 생성 -> start 메소드 호출
- Thread를 상속하는 클래스의 정의와 인스턴스 생성 -> start 메소드 호출
-
둘 이상의 쓰레드가 동일한 변수에 동시에 접근해서 생기는 문제는, 한순간에 한 쓰레드만 변수에 접근하도록 제한하는 동기화(Synchronization) 선언이 필요하다. ‘한 클래스의 두 메소드’에 synchronized 선언이 되면, 두 메소드는 둘 이상의 쓰레드에 의해 동시에 실행될 수 없도록 동기화된다.
‘동기화 메소드’ 기반의 동기화는 사용하기는 편하지만 메소드 전체에 동기화를 걸어야 한다는 단점이 있다. 동기화가 불필요한 부분을 실행하는 동안에도 다른 쓰레드의 접근을 막는 일이 발생하게 된다. 따라서 이러한 경우 에는 ‘동기화 블록’이라는 것을 통해 문장 단위로 동기화 선언을 하는 것이 효율 적이다.
synchronized(this) { count++; }
-> this의 의미: “이 인스턴스의 다른 동기화 블록과 더불어 동기화하겠다.”
-> 클래스의 인스턴스 내에 위치한 두 동기화 블록은 둘 이상의 쓰레드의 의해 동시에 실행될 수 없도록 함께 동기화 된다.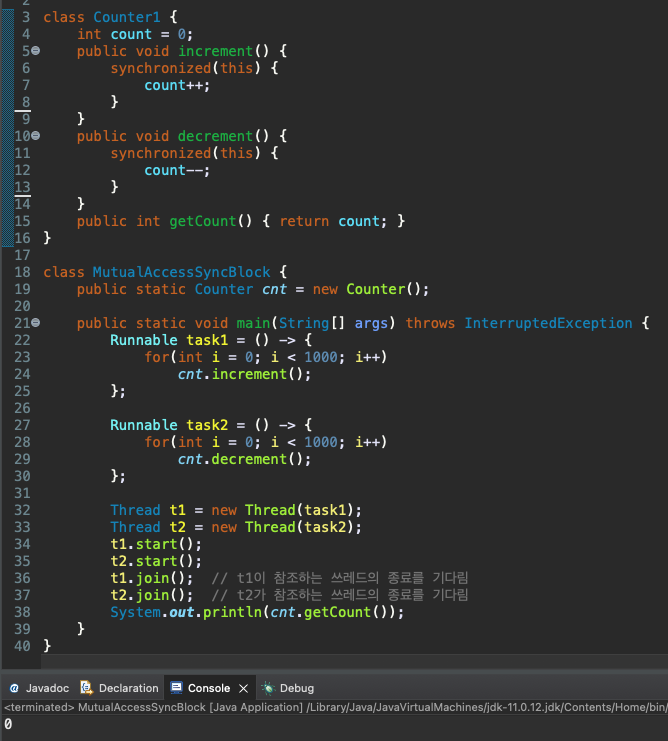
-
쓰레드의 생성과 소멸은 그 자체로 시스템에 부담을 주는 일이다. 따라서 처리해야 할 일이 있을 때마다 쓰레드를 생성하는 것은 성능의 저하로 이어질 수 있다. 그래서 ‘쓰레드 풀(Thread Pool)’이라는 것을 만들고 그 안에 미리 제한된 수의 쓰레드를 생성해 두고 이를 재활용하는 기술을 프로그래머들은 사용해 왔다.
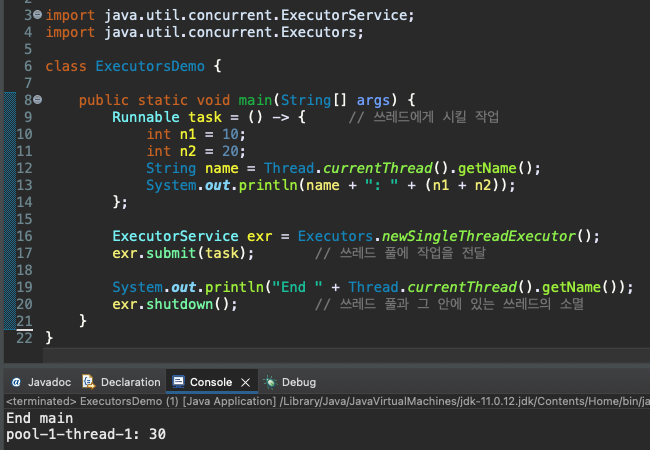
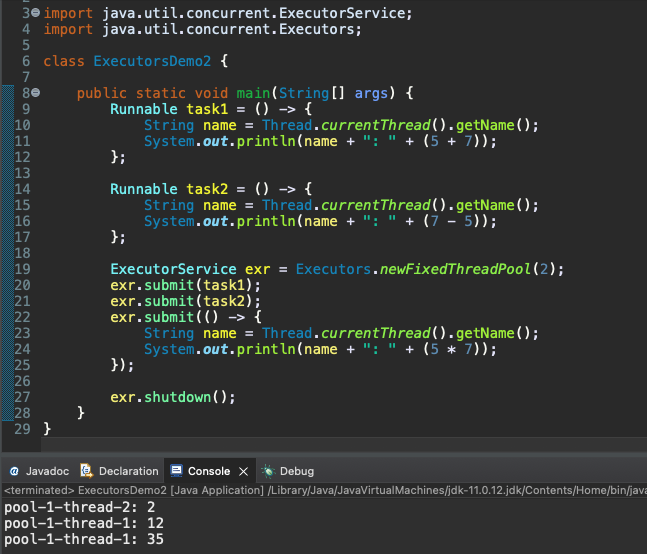
생성된 쓰레드 풀에 다음과 같이 submit 메소드 호출을 통해 작업을 전달하면, 풀에서 대기하고 있던 쓰레드가 이 일을 실행하게 된다. 그리고 작업이 끝나면 해당 쓰레드는 다시 쓰레드 풀로 돌아가서 다음 작업이 전달되기를 기다리게 된다. -
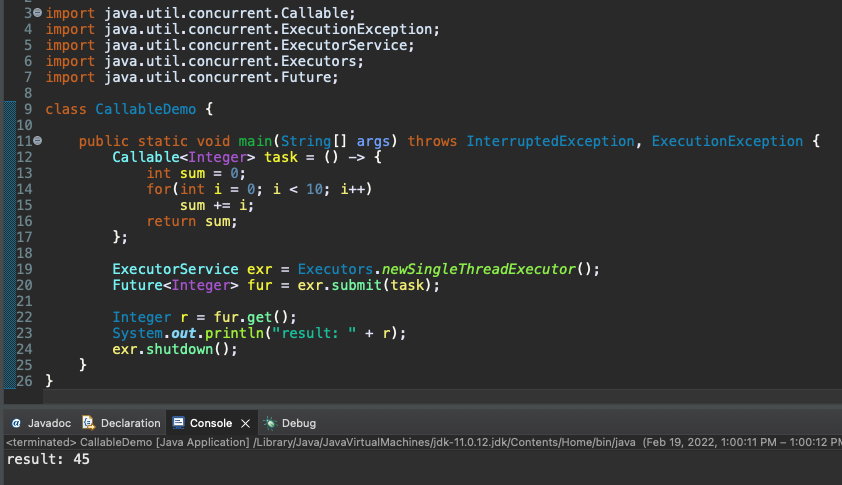
반환 값을 전달하는 쓰레드 생성시 Callabe, Future 사용